Hadoop完全分布式配置
Posted 盈秋君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop完全分布式配置相关的知识,希望对你有一定的参考价值。
- 由于之前已经做了伪分布式配置,在做完全分布式配置之前,需要首先删除master主机hadoop安装路径下的tmp和logs文件夹中的文件:

- 重新配置core-site.xml和hdfs-site.xml,以及mapred-site.xml和yarn-site.xml。
(1)首先编辑core-site.xml
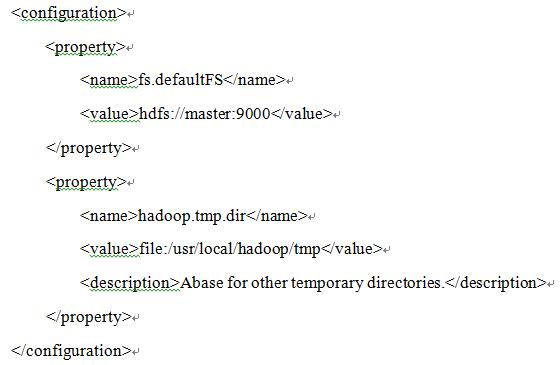
(2)然后编辑hdfs-site.xml

(3)编辑mapred-site.xml


(4)编辑yarn-site.xml

- 修改slaves文件
文件内容(没有slave03的不要最后一行):
slave01
slave02
slave03 - 压缩hadoop安装文件夹,然后分发到slave主机:

- 将master的环境变量配置文件及jdk文件夹传给slave:

拷贝之后,在每个slave主机上利用source命令,是环境变量生效:
source ~/.bashrc
source /etc/profile - 在slave节点以root账户登录,在各个slave节点解压:(注意需要在hadoop账户的主目录下切换到root账户)

- 在master节点格式化namenode,只执行一次,以后启动Hadoop时不需要再次格式化。
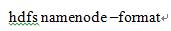
注意:重复格式化会造成namenode和datanode的clusterID不一致,出现此种情况,需要删除各个节点hadoop下的tmp文件夹和logs文件夹的内容,然后,重新格式化namenode。 - 格式化完成后,在master节点启动Hadoop和Yarn(slave主机不用执行)。
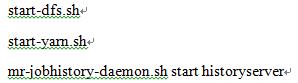
- 通过jps命令查看各个节点的进程:
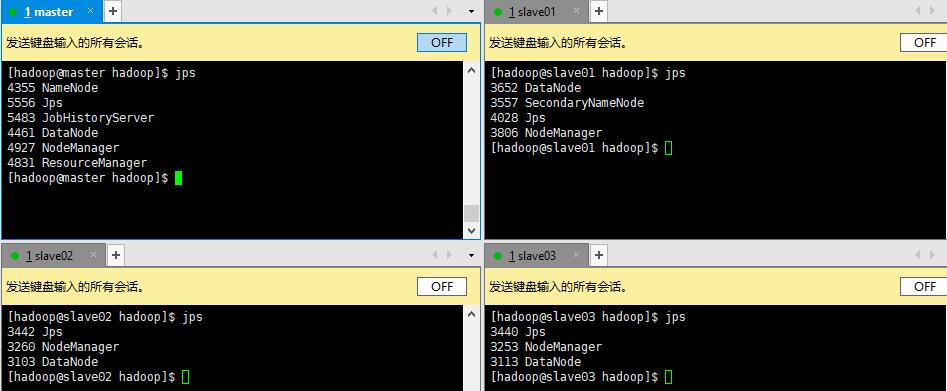
如果有个别进程没有启动,可以在相应主机上单独启动守护进程,例如通过hdfs --daemon start datanode启动数据节点。 - 在master节点通过hdfs dfsadmin –report命令可以查看集群状态,其中,Live datanodes (4)表明集群启动成功。(如果Live datanodes (1),则需要关闭slave主机的防火墙)
- 还可以通过web界面查看集群状态,在linux浏览器输入http://master:9870/
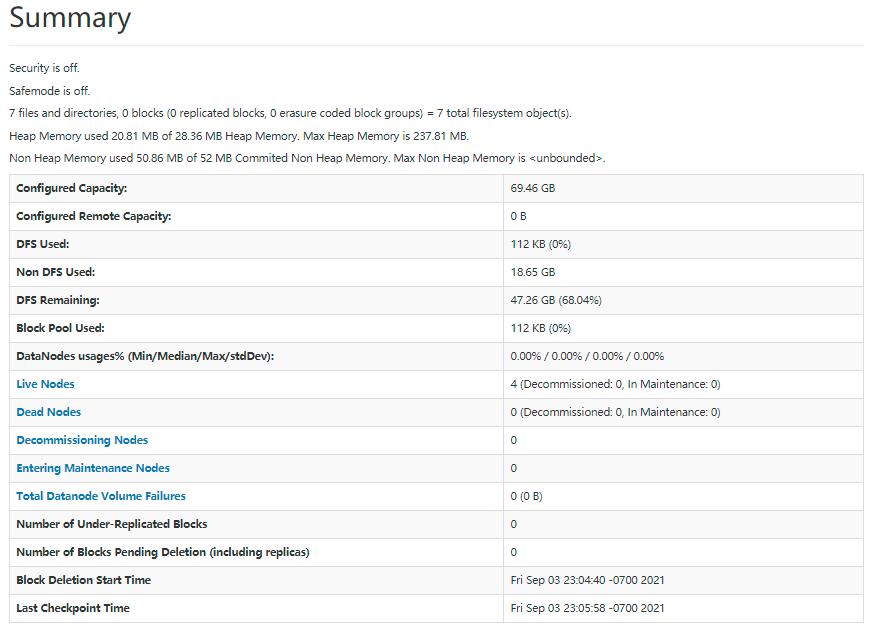
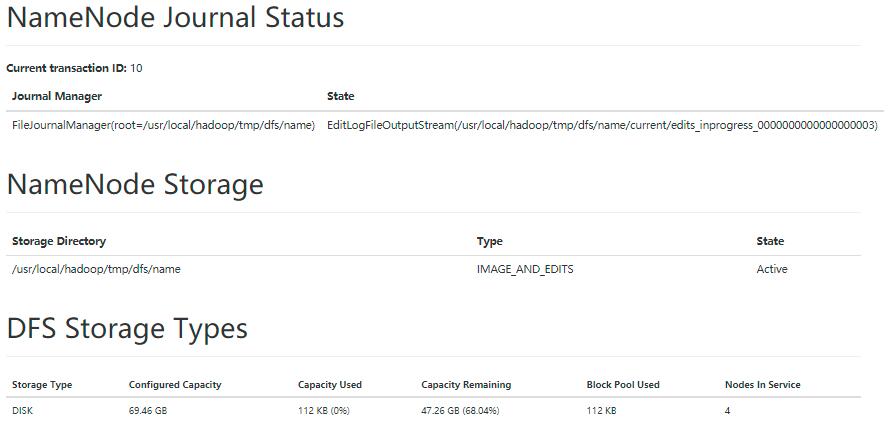
- 最后,关闭Hadoop集群,在master节点执行如下命令:
以上是关于Hadoop完全分布式配置的主要内容,如果未能解决你的问题,请参考以下文章