Mysql 优化器内部JOIN算法hash join Nestloopjoin及classic hash join CHJ过程详解
Posted ShenLiang2025
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql 优化器内部JOIN算法hash join Nestloopjoin及classic hash join CHJ过程详解相关的知识,希望对你有一定的参考价值。
Mysql hash join之classic hash join CHJ过程详解
hash join的历史
优化器里的hash join算法在SQL Server、Oracle、postgress等数据库早已实现,而mysql在8.0.18之后才支持。在8.0.18之前mysql只支持嵌套循环关联(nested loop join),这其中最简单就是简易嵌套循环关联simple nestloop join,随后mysql做了改进进而支持block nestloop join, index nestloop join and batched key access等算法,这也是hash join算法被推迟实现的部分原因。
hash join的概述
提到hash join之前自然得说Nestloopjoin,以两个表的关联为例,它其实是个双层循环,先遍历外层的表(n条),再拿每次对应的值去匹配、循环遍历内部的表(M条)。这样显然会有M*n的计算复杂度。如果能将外部表先装载到内存,然后再做内部表的匹配、遍历,计算的复杂度就会大大降低,这就是hash join的思想。
hash join的类型
hash join 从具体实现上又分为:
1经典hash join(In-Memory Join或classic hash join或CHJ)
2 磁盘分区hash join (On-Disk Hash Join)
3 Grace Hash Join
4 混合hash join(hybrid hash join)
hash join应用场景
hash join主要应用在以下条件:
1两个或多个表至少包含一个等值条件关联时。
2 关联的字段上没有索引。
3 关联条件可以是原始字段或者表达式(如 T1.col1+T1.col2 = T2.col3+T2.col4).
4 关联条件等号的两表只能出现一张表。
5 补充,可能使用到hash join的SQL写法示例:
CREATE TABLE t1 (t1_1 INT, t1_2 INT);
CREATE TABLE t2 (t2_1 INT, t2_2 INT)
SELECT * FROM t1 JOIN t2 ON (t1.t1_1 = t2.t2_1);
SELECT * FROM t1 JOIN t2 ON (t1.t1_1 = t2.t2_1 AND t1.t1_2 = t2.t2_2);
SELECT * FROM t1 JOIN t2 ON (t1.t1_1 = t2.t2_1 AND t2.t2_2 > 43);
SELECT * FROM t1 JOIN t2 ON (t1.t1_1 + t1.t1_2 = t2.t2_1);
SELECT * FROM t1 JOIN t2 ON (FLOOR(t1.t1_1 + t1.t1_2) = CEIL(t2.t2_1 = t2.t2_2));In-Memory Join classic hash join
经典hash join(classic hash join)简称CHJ,该算法由两部分构成,一是构建哈希表(hash table)过程,二是探测、匹配(probe)过程。
以有如下查询和表格结构为例:
CREATE TABLE t1 (foo INT);
CREATE TABLE t2 (bar INT);
insert into t1 values(12);
insert into t2 values(34);
… ... -- 插入数据省略
SELECT * FROM t1 JOIN t2 on (t1.foo = t2.bar);
构建哈希表:
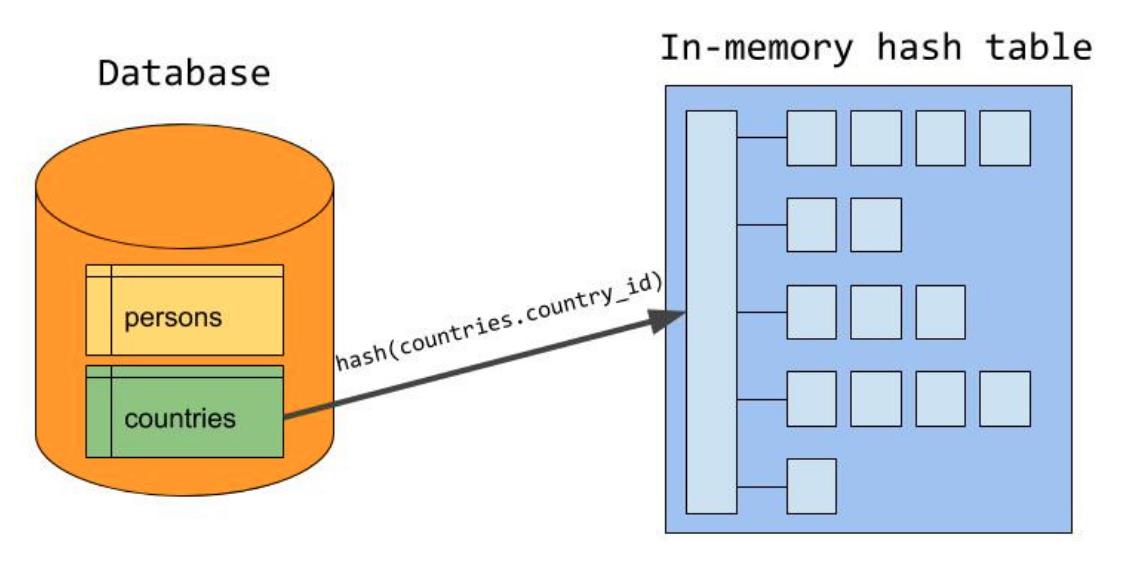
1 当两个表以含等值条件方式关联时其中一个表会被指定为构建表,该表会以哈希表(哈希的值来自于等值条件里的字段)的形式读入内存。
2 假设这里t1表被指定为构建表,那么将会通过哈希函数产生哈希表,这里t1的foo字段是是哈希函数里的键。
探测阶段:
此时join里的另外个表即t2作为探测表,在构建完成后,开始从t2探测表作为输入。这时以t2的bar (t1、t2两表关联时t2的字段)作为哈希的键,同时该键是用来匹配内存里的t1生成的哈希表。一旦匹配到记录则意味着找到目标,这个按照每一行匹配的过程就做探测过程。
In-Memory Join过程示意

执行计划查看In-Memory Join
EXPLAIN ANALYZE
SELECT CountryCode, country.Name AS Country,
city.Name AS City, city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
-- 数据库来自mysql官网示例数据库world
-- 结果
EXPLAIN
-> Inner hash join (world.city.CountryCode = world.country.`Code`) (cost=13870.82 rows=595) (actual time=58.807..134.662 rows=1766 loops=1)
-> Table scan on city (cost=0.80 rows=4046) (actual time=30.193..95.386 rows=4079 loops=1)
-> Hash
-> Filter: (world.country.Continent = 'Asia') (cost=30.90 rows=34) (actual time=21.446..28.489 rows=51 loops=1)
-> Table scan on country (cost=30.90 rows=239) (actual time=21.435..28.338 rows=239 loops=1)
执行示例
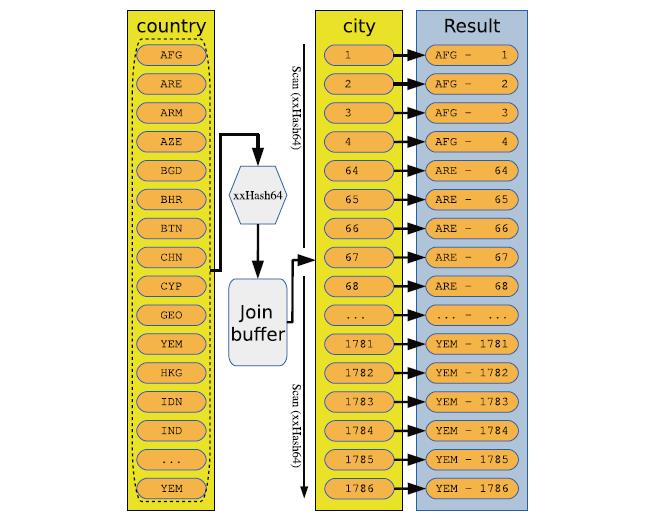
过程介绍
Step1:Country的Code字段会被哈希函数哈希并保存在关联缓存(即哈希表)内(join buffer)。
Step2:然后通过和step1里一样的哈希函数哈希的字段CountryCode进行表扫描(table scan)遍历city表里的每一行。
以上是关于Mysql 优化器内部JOIN算法hash join Nestloopjoin及classic hash join CHJ过程详解的主要内容,如果未能解决你的问题,请参考以下文章