Mysql 优化器内部JOIN算法hash join On-Disk Hash Join Grace Hash Join Hybrid hash join过程详解
Posted ShenLiang2025
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql 优化器内部JOIN算法hash join On-Disk Hash Join Grace Hash Join Hybrid hash join过程详解相关的知识,希望对你有一定的参考价值。
mysql 各种hash join算法讲解
hash join的概述
提到hash join之前自然得说Nest loop join,以两个表的关联为例,它其实是个双层循环,先遍历外层的表(n条),再拿每次对应的值去匹配、循环遍历内部的表(M条)。这样显然会有M*n的计算复杂度。如果能将外部表先装载到内存,然后再做内部表的匹配、遍历,计算的复杂度就会大大降低,这就是hash join的思想。
本文继续介绍hash join的其它几个算法On-Disk Hash Join、Grace Hash Join、Hybrid hash join。其中In Memory Join classic hash join的介绍见:
 https://shenliang.blog.csdn.net/article/details/120498088
https://shenliang.blog.csdn.net/article/details/120498088On-Disk Hash Join
CHJ算法在构建表时的内存大小可通过参数join_buffer_size来设置,但因为需要把整个表都装到内存里,所以这种方法遇到比较大的表时就显得捉襟见肘。不过也不是没有方法去规避,我们按照如下的策略方向做改进(分批执行的思想,记作):
1 在构建哈希表时读取尽量多的内容到内存。
2 运行探测过程时读取整个探测的输入(即对应1里的内容)。
3 擦除(清空)内存里的哈希表。
4 循环步骤1里执行直至遍历完构建过程里的数据。
不过因为需要多次读取构建的输入(即构建表)还是有风险且有成本的,假设构建表被分成了n份,那么在匹配探测表时将会扫描n次。这时借助磁盘分区执行的方法on-Disk Hash Join就应运而生了。详细步骤见下:
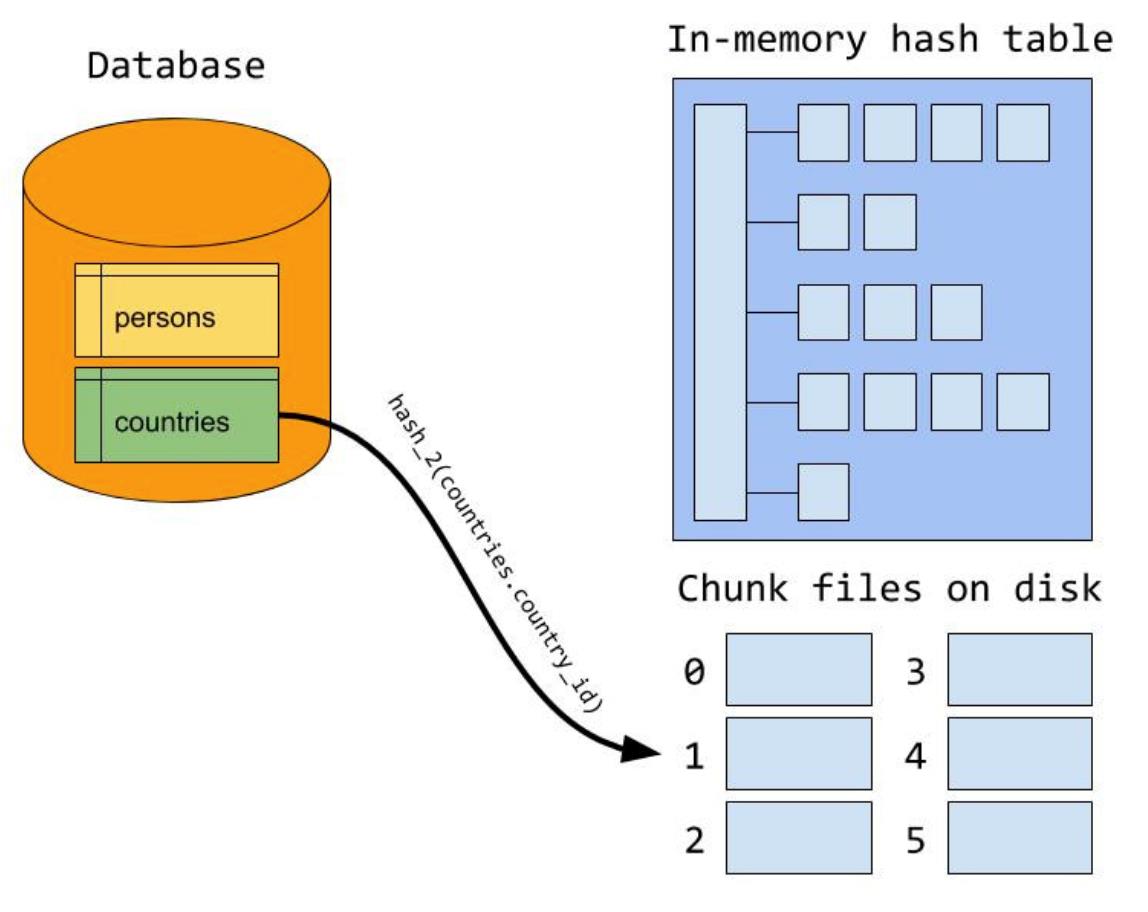
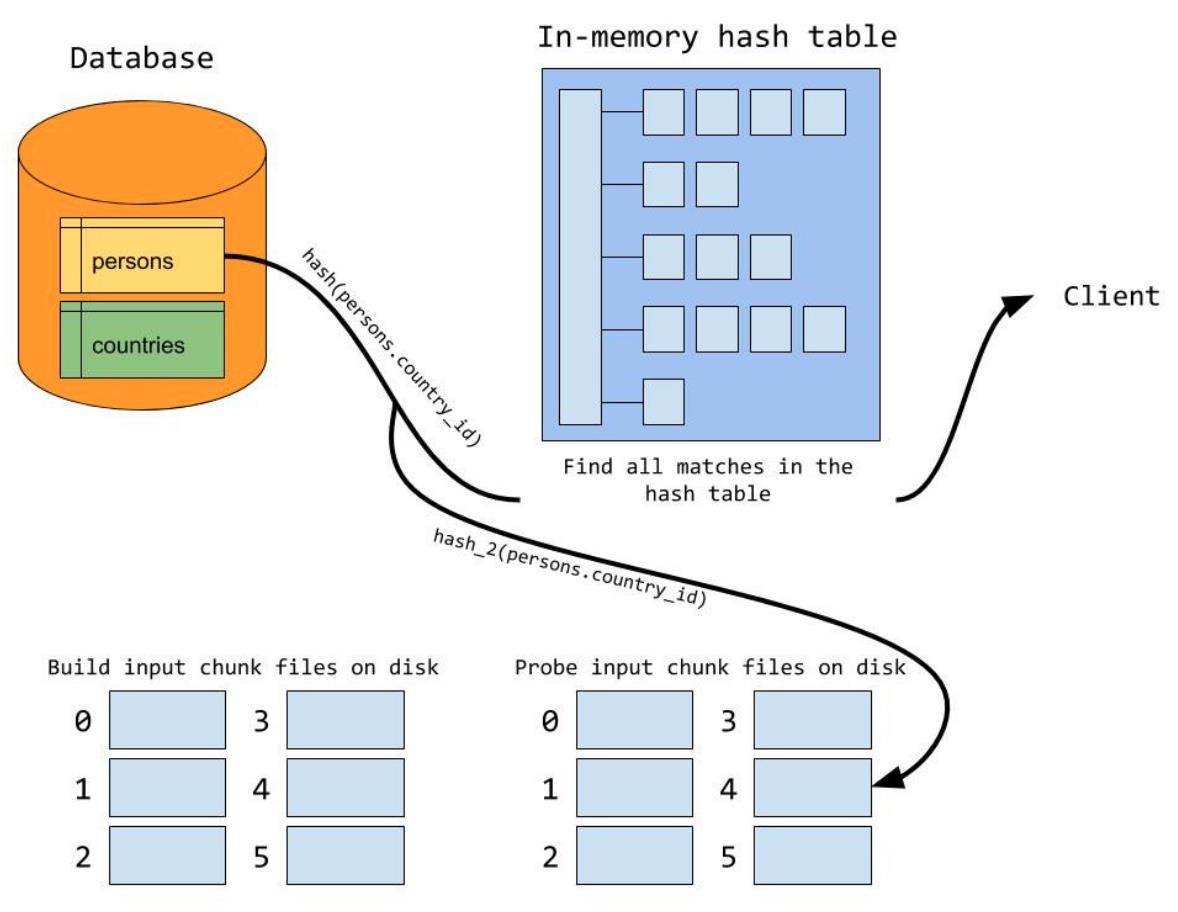
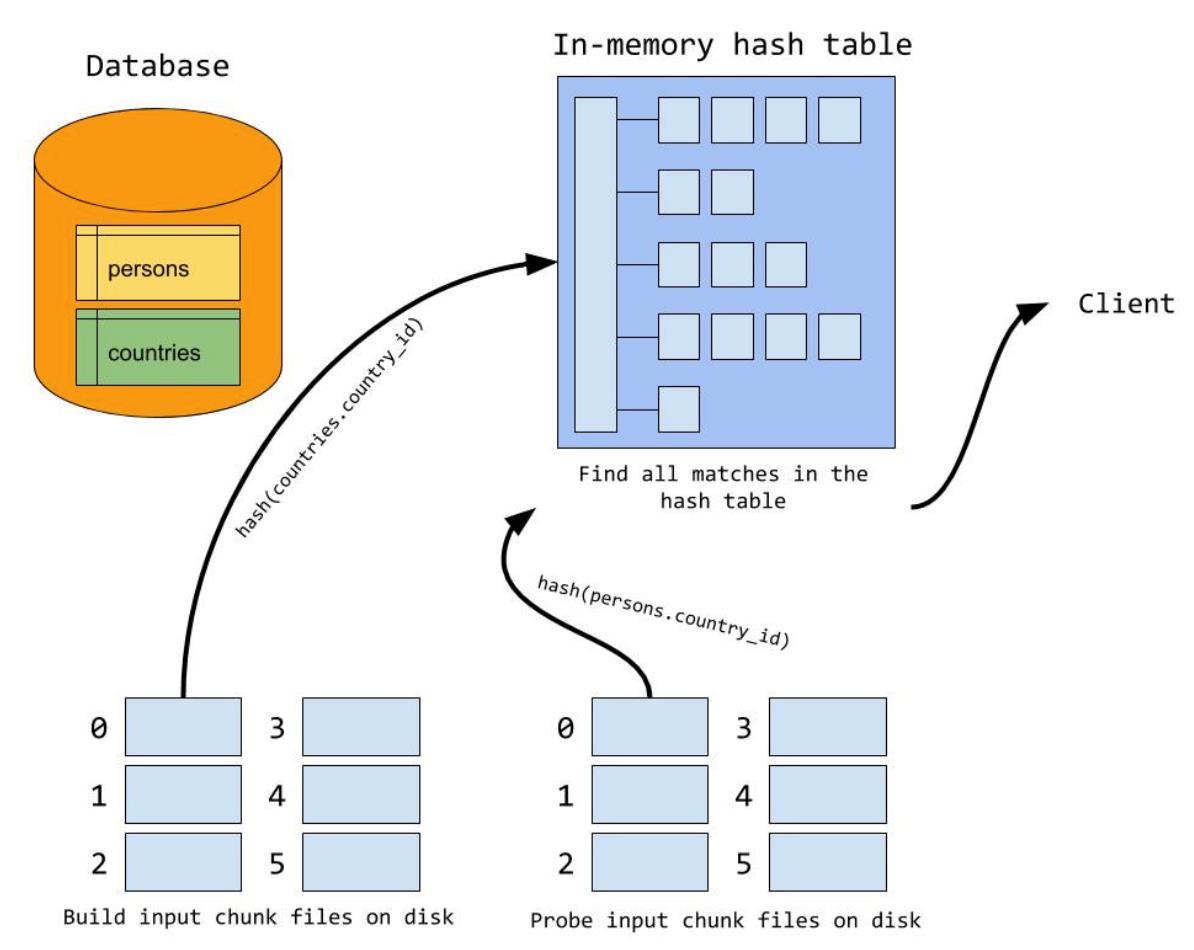
Step1:把构建表和探测表在磁盘上分成若干小区(块),这里分配的原则是每个小区(块)能全部装载到内存里,而构建表的确定和classic hash join算法类似(一般优先选择小表)。
Step2:当所有的记录都已经分区(块)到磁盘上的小文件后,开始遍历分区(块),进入构建阶段即将第一个分区通过函数函数装载到内存里形成哈希表,然后在探测阶段扫描第一个分区(块),该分区(块)对应构建阶段里分区。因为在生成分区信息时构建表和探测表用相同的哈希函数,所以在探测阶段进行匹配时很容易找到对应的分区信息。
Step3:当第一个分区(块)处理完了之后清空内存里的哈希表,然后把第二个分区文件装载到构建表,在探测过程用第二个分区的信息匹配探测表,依次类推直至所有的分区(块)都遍历完。
通过对On-Disk Hash Join的执行过程进行分析,我们不难发现该算法会在构建过程读取IO两次、探测过程写一次IO。这与开头里介绍的hash join改善算法(n次IO扫描探测表)已经有较大的进步。
注:
1 in-memory hash join和on-disk hash join算法都是用的msxxHash64作为哈希函数,它是在提供高质量的哈希值的同时又能保证快速(减少哈希冲突的数量)。
2 如果有一个数据集倾斜的结果集会导致构建表里的一个分区(块)不能填入内存,那么hash join算法会按照如下的逻辑处理:
1 读取尽量多的分区(块)到内存。
2 在整个探测阶段读取探测分区。
3 清空内存里的哈希表。
4 调转到步骤1直至构建分区里没有数据。
Grace Hash Join
当连接缓存大小(join buffer size)不足时,mysql会先分片再按照classic hash join的方式处理(见On-Disk Hash Join里的注2)。但在极端情况,如果数据分布不均匀,有大量数据经过哈希后分布到一个桶内,这将导致分片后的连接缓存大小仍然不足。碰到这种情况oracle的grace hash join算法则会继续拆分直至有足够的内存可以存放哈希表,当然如果在关联条件相同的情况下不论再怎么哈希还是不能拆分时grace hash join也退化为和像mysql一样先分片再classic hash join的方式处理方式。
Hybrid hash join
如果缓存足够多的分片数据会尽量缓存,那么就不必像GraceHash那样将所有分片都先读进内存,再写到外存,最后再读进内存进行build过程,这就是Grace Hash Join算法的核心,即在内存相对于分片比较充裕的情况下可以减少磁盘的读写IO。目前Oceanbase的HashJoin采用的是这种join方式。
hash join的伪代码
result = []
join_buffer = []
partitions = 0
on_disk = False
for country_row in country:
if country_row.Continent == 'Asia':
hash = xxHash64(country_row.Code)
if not on_disk:
join_buffer.append(hash)
if is_full(join_buffer):
# Create partitions on disk
on_disk = True
partitions = write_buffer_to_disk(join_buffer)
join_buffer = []
else
write_hash_to_disk(hash)
if not on_disk:
for city_row in city:
hash = xxHash64(city_row.CountryCode)
if hash in join_buffer:
country_row = get_row(hash)
city_row = get_row(hash)
result.append(join_rows(country_row, city_row))
else:
for city_row in city:
hash = xxHash64(city_row.CountryCode)
write_hash_to_disk(hash)
for partition in range(partitions):
join_buffer = load_build_from_disk(partition)
for hash in load_hash_from_disk(partition):
if hash in join_buffer:
country_row = get_row(hash)
city_row = get_row(hash)
result.append(join_rows(country_row, city_row))
join_buffer = []
代码简介
从country表里读取每一行并计算code字段对应的哈希值并存储在连接缓存内(join buffer)。如果连接缓存满了则走on-disk算法并哈希后的缓存写到外部磁盘。也正是在此时分区的个数确定,然后对country表剩下的数据继续哈希。
对于in-memory的算法只需要通过循环比较city和缓存里的哈希值即可,而对于on-disk算法哈希的city表会被首先计算并存放在磁盘然后再通过分区一个个的匹配。
参考:
以上是关于Mysql 优化器内部JOIN算法hash join On-Disk Hash Join Grace Hash Join Hybrid hash join过程详解的主要内容,如果未能解决你的问题,请参考以下文章