学习笔记Hadoop—— Hadoop基础操作
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Hadoop—— Hadoop基础操作相关的知识,希望对你有一定的参考价值。
文章目录
一、Hadoop安全模式
在分布式文件HDFS系统启动的时候,会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。
安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。
运行期通过命令也可以进入 安全模式。
实际操作中,可以通过命令进入安全模式,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
Master配置Hadoop环境变量
vi /etc/profile
添加:
export HADOOP_HOME=/opt/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin
是环境使生效
source /etc/profile
1.1、HDFS启动日志分析
工作流程:
-
启动NameNode,NameNode加载fsimage。
-
加载edits log。
-
NameNode等待DataNode上传block列表信息,直到副本数量满足最小副本条件。(最小副本条件指整个文件系统中有99.9%的block达到了最小副本数)
-
当满足了最小副本条件,再等待一段时间,NameNode就会自动退出安全模式。
启动HDFS
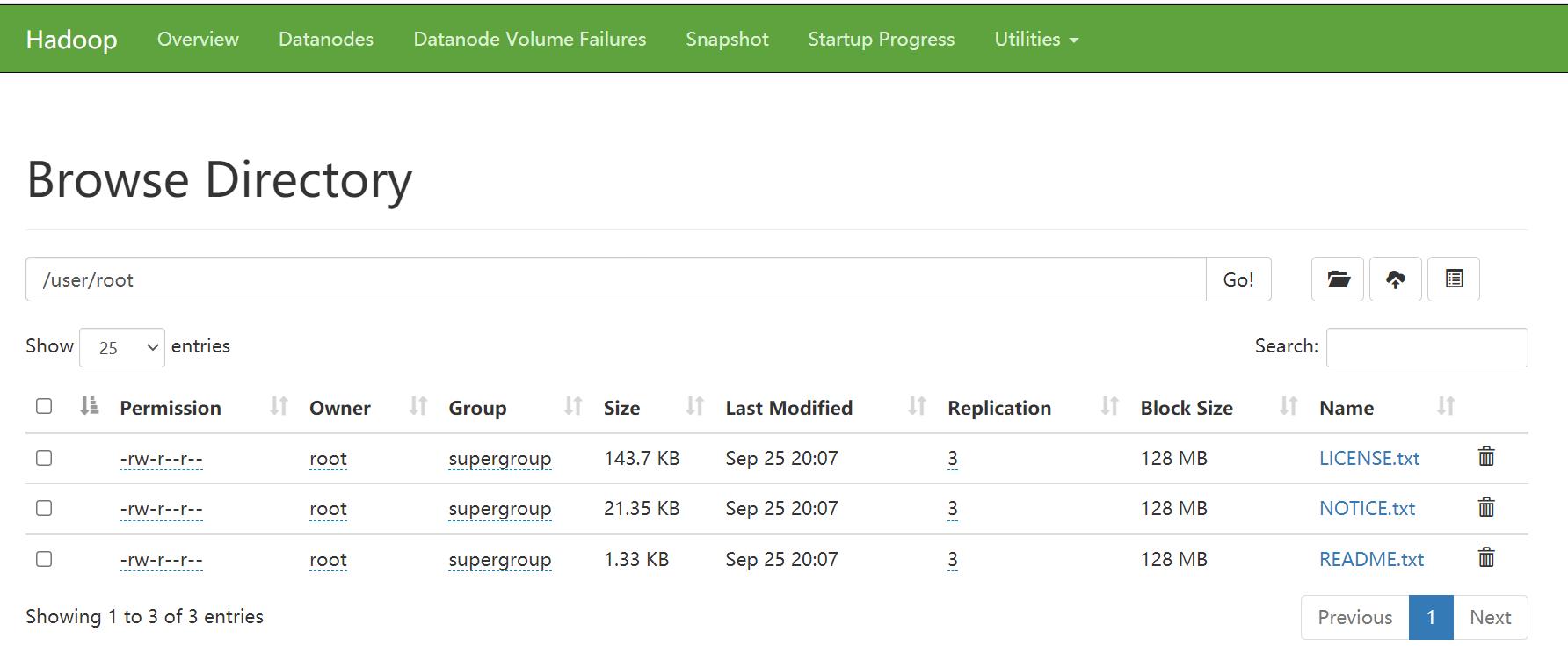
我们来尝试添加一个文件:
进入hadoop安装位置/opt/hadoop-3.1.3
hdfs dfs -mkdir -p /user/root
hdfs dfs -put LICENSE.txt NOTICE.txt README.txt .
执行上面两条语句,文件就上传成功了
1.2、Safemode进入方式
只启动Namenode

只启动Namenode & 一个Datanode

通过命令查看namenode是否处于安全模式:
hdfs dfsadmin -safemode get
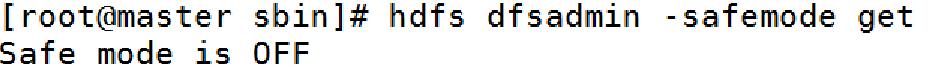
进入安全模式:
hdfs dfsadmin -safemode enter

注意:
- 对文件系统元数据进行只读操作。
- 当文件的所有block信息具备的情况下,对文件进行只读操作。
- 不允许进行文件修改(写,删除或者重命名文件)。
二、Hadoop集群基本信息
在Hadoop中集群的基本信息主要包含分布式文件系统HDFS和分布式资源管理YARN。
分布式文件系统HDFS主要包含文件系统的状态,是否有块丢失、备份丢失等等。同时,包含集群节点状态等。
分布式资源管理YARN主要包含集群节点状态,节点资源(内存,CPU等),队列状态等。
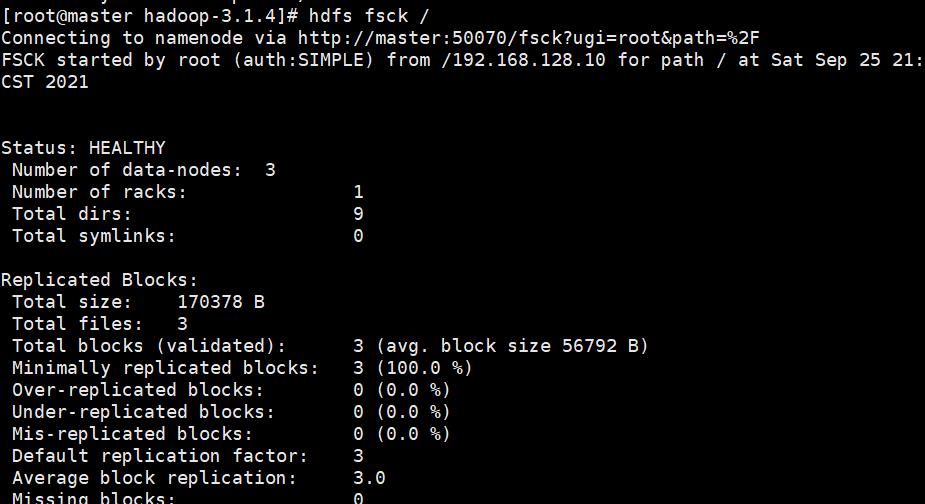
查看HDFS集群基本信息的指令:
hdfs fsck /
三、HDFS常用Shell操作
3.1、HDFS文件系统
HDFS Shell 指的是可以使用类似shell的命令来直接和Hadoop分布式文件系统(HDFS)进行交互。
使用命令:
bin/hadoop fs <args>
bin/hdfs dfs <args>
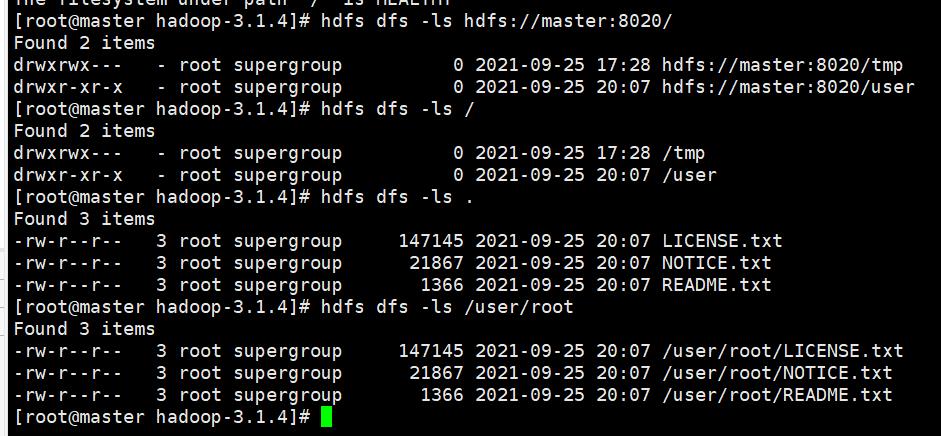
参数中的路径使用scheme://authority/path 的格式,如默认配置的是hdfs,那么路径如: hdfs://namenodehost:port/parent/child 。
如果使用相对路径,那么当前的工作目录就是/user/{username}, 比如当前是root账号,那么工作目录就是/user/root。
示例:
3.2、常用Shell命令-appendToFile
用法:
hadoop fs -appendToFile <localsrc> ... <dst>
示例:
hadoop fs -appendToFile localfile /user/hadoop/hadoopfile
hadoop fs -appendToFile localfile1 localfile2 /user/hadoop/hadoopfile
hadoop fs -appendToFile localfile hdfs://nn.example.com/hadoop/hadoopfile
hadoop fs -appendToFile - hdfs://nn.example.com/hadoop/hadoopfile
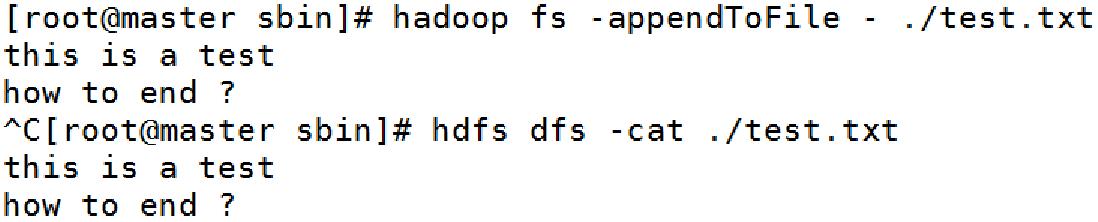
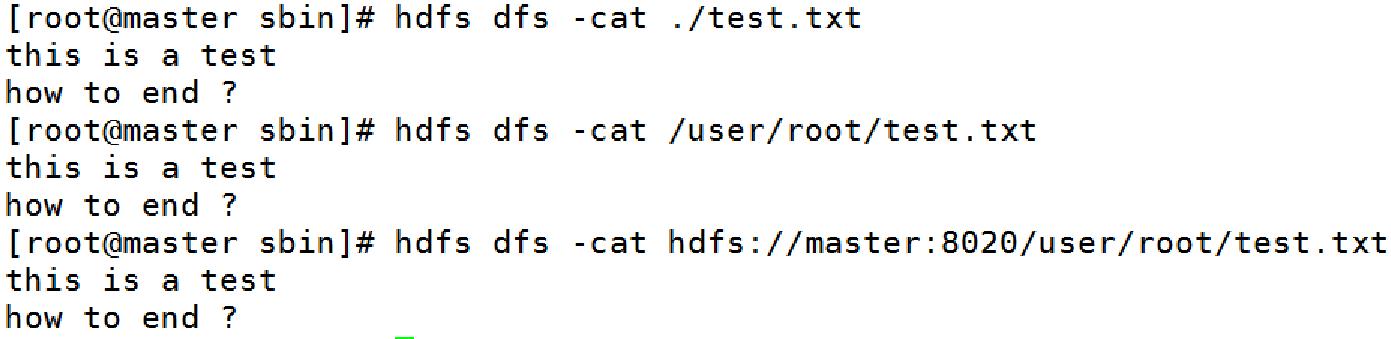
3.3、常用Shell命令-cat
用法:
hadoop fs -cat [-ignoreCrc] URI [URI ...]
示例:
hadoop fs -cat hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
hadoop fs -cat file:///file3 /user/hadoop/file4
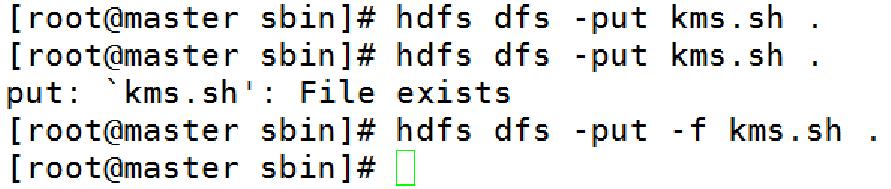
3.4、常用Shell命令-copyFromLocal | put
用法:
hadoop fs -put [-f] [-p] [-l] [-d] [-t <thread count>] [ - | <localsrc1> .. ]. <dst>
示例:
hadoop fs -put localfile /user/hadoop/hadoopfile
hadoop fs -put -f localfile1 localfile2 /user/hadoop/hadoopdir
hadoop fs -put -d localfile hdfs://nn.example.com/hadoop/hadoopfile
hadoop fs -put - hdfs://nn.example.com/hadoop/hadoopfile
3.5、常用Shell命令-cp
用法:
hadoop fs -cp [-f] [-p | -p[topax]] URI [URI ...] <dest>
示例:
hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
可选项:
-f : 如果目标文件存在,则覆写目标文件;
-p : 保存文件的属性,[topx] (timestamps, ownership, permission, ACL, XAttr).

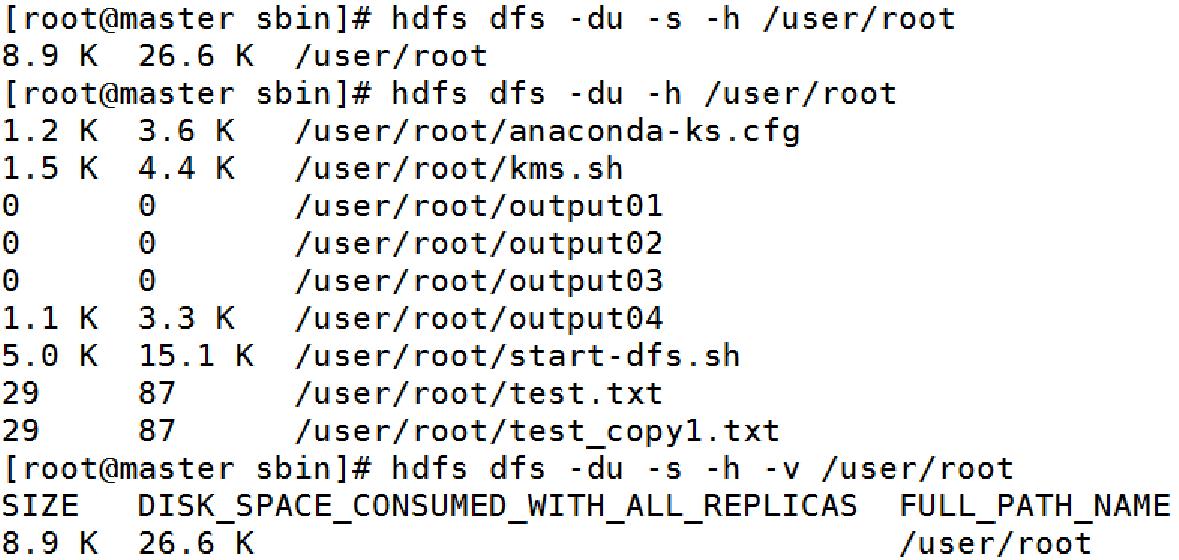
3.6、常用Shell命令-du
用法:
hadoop fs -du [-s] [-h] [-v] [-x] URI [URI ...]
可选项:
-s : 统计文件夹;
-h : 格式化友好输出;
-v : 显示列名;
-x : 去除snapshots 进行计算;
3.7、常用Shell命令-copyToLocal | get
用法:
hadoop fs -get [-ignorecrc] [-crc] [-p] [-f] <src> <localdst>
示例:
hadoop fs -get /user/hadoop/file localfile
hadoop fs -get hdfs://nn.example.com/user/hadoop/file localfile
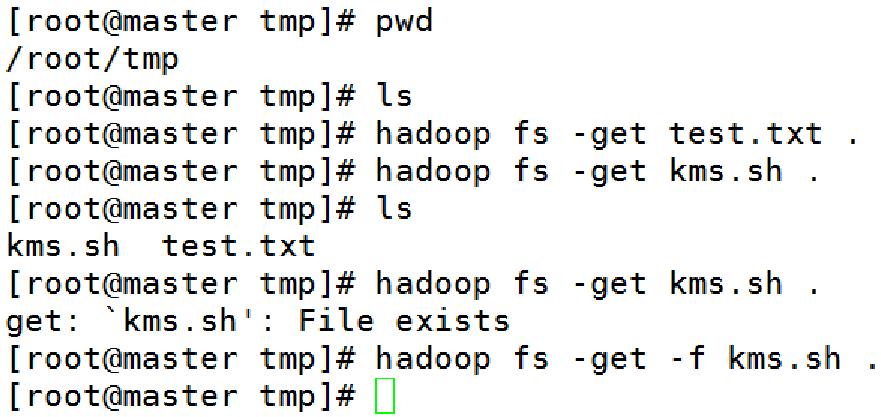
3.8、常用Shell命令-ls
用法:
hadoop fs -ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] <args>
可选项:
-C : 只显示文件及文件夹 ; -d : 只显示给定文件夹 ; -h : 格式化文件大小显示
-q : 使用?替代不可打印字符 ; -R : 递归显示 ;-t : 按照最近修改文件排序
-S : 按照文件大小排序 ; -r : 翻转排序规则 ; -u : 使用创建时间进行排序

3.9、常用Shell命令-mkdir
用法:
hadoop fs -mkdir [-p] <paths>
示例:
hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
hadoop fs -mkdir hdfs://nn1.example.com/user/hadoop/dir hdfs://nn2.example.com/user/hadoop/dir

3.10、常用Shell命令-rm
用法:
hadoop fs -rm [-f] [-r |-R] [-skipTrash] [-safely] URI [URI ...]
可选项:
-f : 忽略错误信息 ; -R : 递归删除 ; -r : -R
-skipTrash : 不放回收站,直接删除 ; -safely : 强制确认是否需要删除

3.11、HDFS UI交互
开启方法:
① 终端开启HDFS:hadoop的sbin目录下执行./start-dfs.sh
② 浏览器网址输入:master:50070

文件基本信息:

四、MapReduce常用Shell操作
4.1、MapReduce常用Shell
MapReduce Shell 此处指的是可以使用类似shell的命令来直接和MapReduce任务进行交互(这里不严格区分MapReduce shell及Yarn shell)。
提交任务命令:
yarn jar <jar> [mainClass] args...
查看及修改任务命令:
yarn application [options] Usage: yarn app [options]
可选项:
- appId : 指定APPlication id
- changeQueue : 改变队列
- kill : 停止任务
- status : 查看任务状态
4.2、常用Shell-任务实例
查看MapReduce可以命令
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar

使用pi计算实例
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi
设置参数
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 100 10
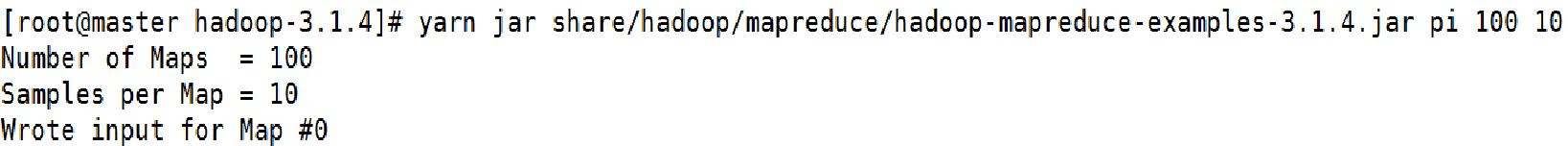
然后我们可以获得application的id

通过这个id查看状态
yarn application -status application_1619841871021_0001
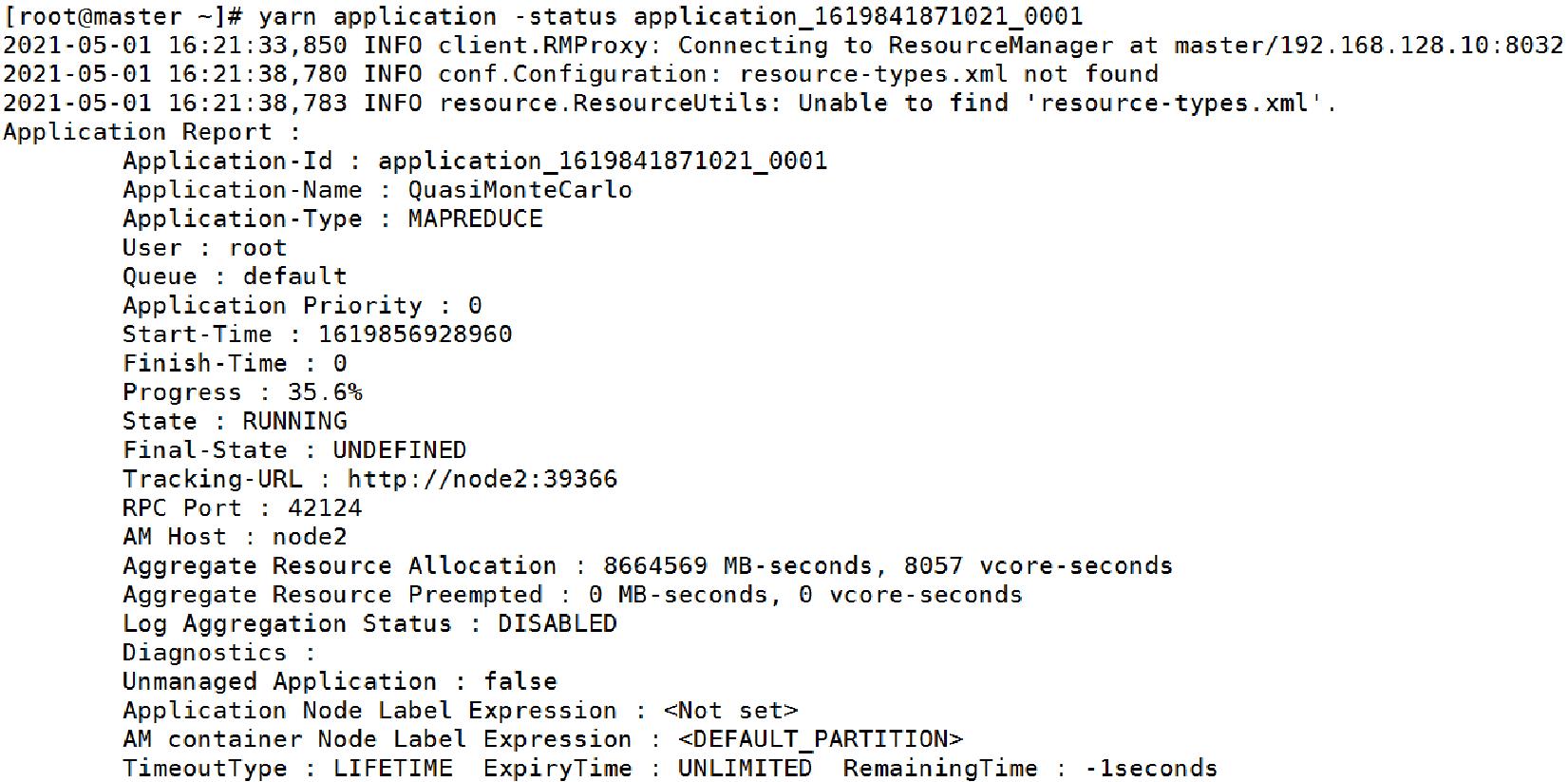
我们也可以在浏览器查看这个信息,浏览器端口:master:8088
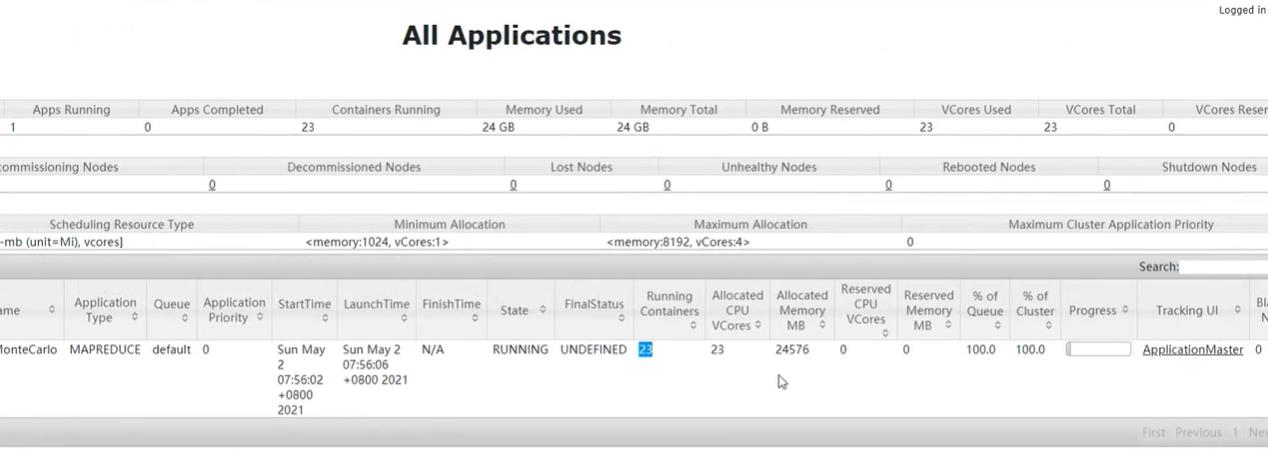
关闭这个任务:
yarn application -kill application_1619841871021_0001


五、MapReduce任务管理
MapReduce任务日志查看:

5.1、多任务竞争
我们可以通过修改/opt/hadoop-3.1.4/etc/hadoop/下的capacity-scheduler.xml,来同时运行两个任务
cd /opt/hadoop-3.1.4/etc/hadoop/
vi capacity-scheduler.xml
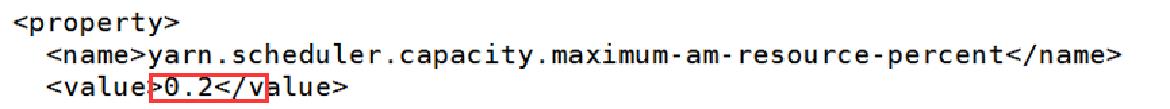
改完后拷贝到其他结点
scp capacity-scheduler.xml node1:/opt/hadoop-3.1.4/etc/hadoop/
scp capacity-scheduler.xml node2:/opt/hadoop-3.1.4/etc/hadoop/
scp capacity-scheduler.xml node3:/opt/hadoop-3.1.4/etc/hadoop/

最后使配置生效
yarn rmadmin -refreshQueues

六、YARN资源管理与调度策略
6.1、YARN资源管理
MapReduce任务/资源流程:
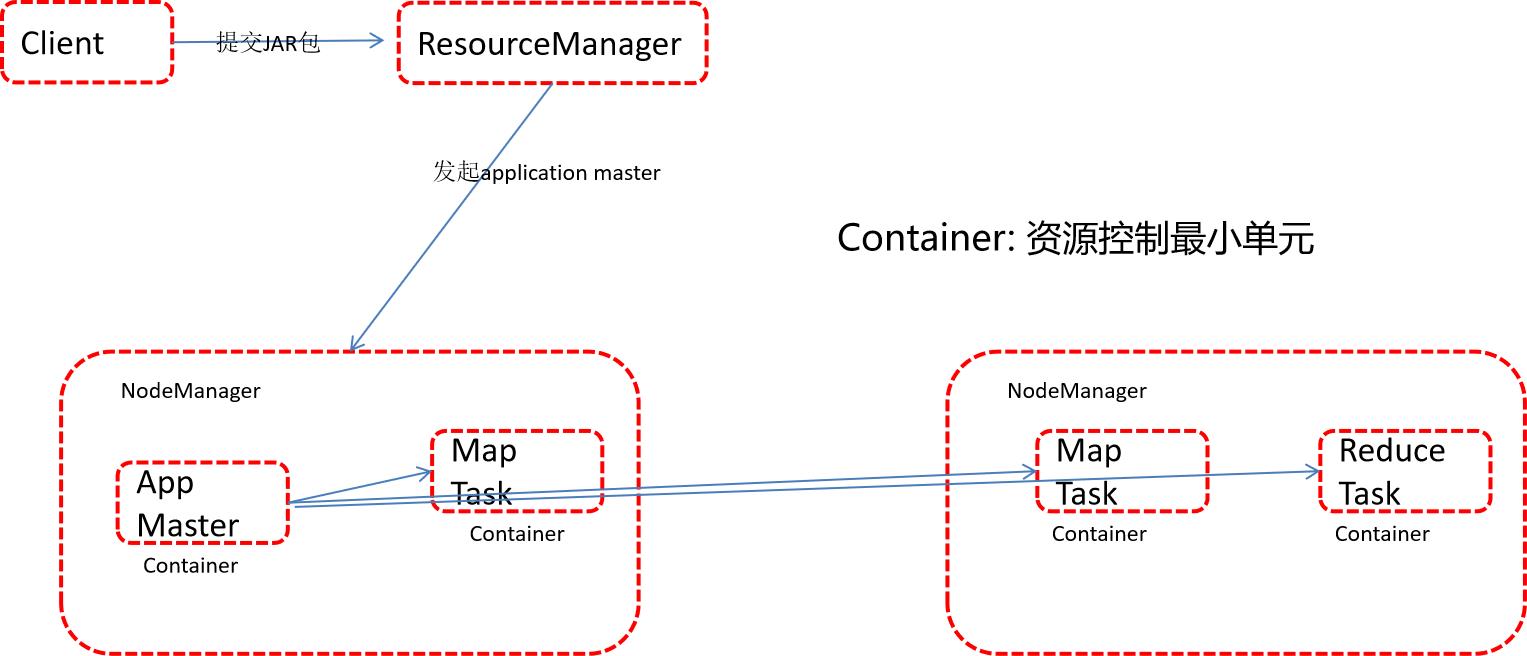
由5.1章节我们可知,当把yarn.scheduler.capacity.maximum-am-resource-percent参数调整为0.2 时,我们可以同时运行2个任务,此时Application Master最大资源为5120M(每个任务启动的AppMaster资源为2048M)

当参数调整为0.3时,可同时运行4个任务

6.2、YARN调度策略
Yarn的资源调度器是可配置的,Yarn定义了一套接口规范(接口ResourceScheduler),用户可以按照自己的需求实现这个接口中的方法。
Yarn自身自带了三种调度器,分别是:FIFO Scheduler、Capacity Scheduler和Fair Scheduler。
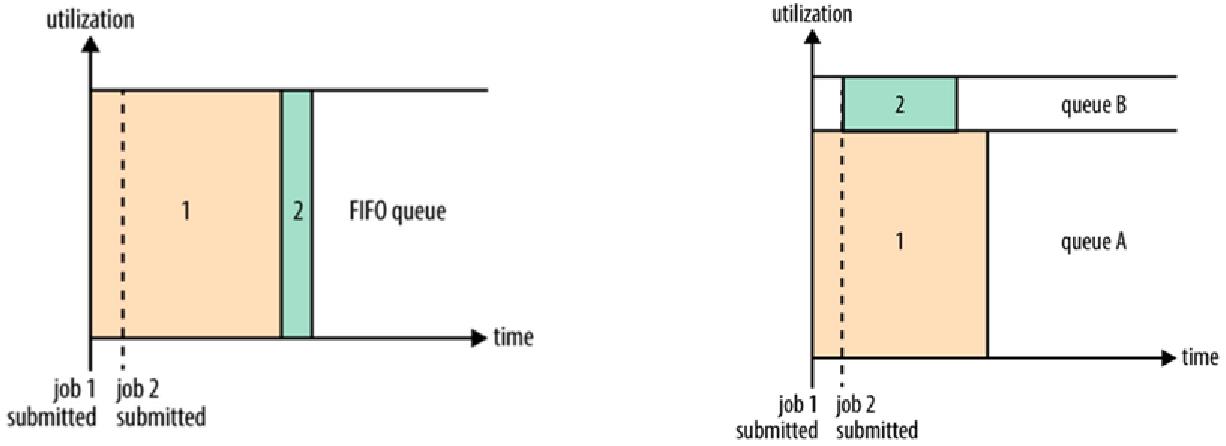
Yarn的资源调度器默认使用Capacity Scheduler,但是默认只有一个root.default队列。

调整Yarn资源队列:
- 添加dev,prod 队列,删除default队列;
- 修改default队列配置为dev队列,并修改其capacity为40 , maxium-capacity 为60 ;
- 复制dev队列属性,并修改为prod队列,修改其capacity为60 , maxium-capacity 为80 ;
- 重启YARN集群;
cd /opt/hadoop-3.1.4/etc/hadoop
vi capacity-scheduler.xml
修改如下:










修改完后,配置prod,在dev末尾添加:

<!-- config prod queue -->
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>60</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.maximum-capacity</name>
<value>80</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.acl_application_max_priority</name>
<value>*</value>
<description>
The ACL of who can submit applications with configured priority.
For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}]
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.maximum-application-lifetime
</name>
<value>-1</value>
<description>
Maximum lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
This will be a hard time limit for all applications in this
queue. If positive value is configured then any application submitted
to this queue will be killed after exceeds the configured lifetime.
User can also specify lifetime per application basis in
application submission context. But user lifetime will be
overridden if it exceeds queue maximum lifetime. It is point-in-time
configuration.
Note : Configuring too low value will result in killing application
sooner. This feature is applicable only for leaf queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.default-application-lifetime
</name>
<value>-1</value>
<description>
Default lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
If the user has not submitted application with lifetime value then this
value will be taken. It is point-in-time configuration.
Note : Default lifetime can't exceed maximum lifetime. This feature is
applicable only for leaf queue.
</description>
</property>
配置prod完后,保存、退出,拷贝到node1、node2、node3下:
scp capacity-scheduler.xml node1:/opt/hadoop-3.1.4/etc/hadoop/
scp capacity-scheduler.xml node2:/opt/hadoop-3.1.4/etc/hadoop/
scp capacity-scheduler.xml node3:/opt/hadoop-3.1.4/etc/hadoop/
最后,重启下集群(进入sbin目录)
./stop-yarn.sh
./start-yarn.sh
启动成功

最后,我们查看下网页的情况,浏览器网址输入:
master:8088
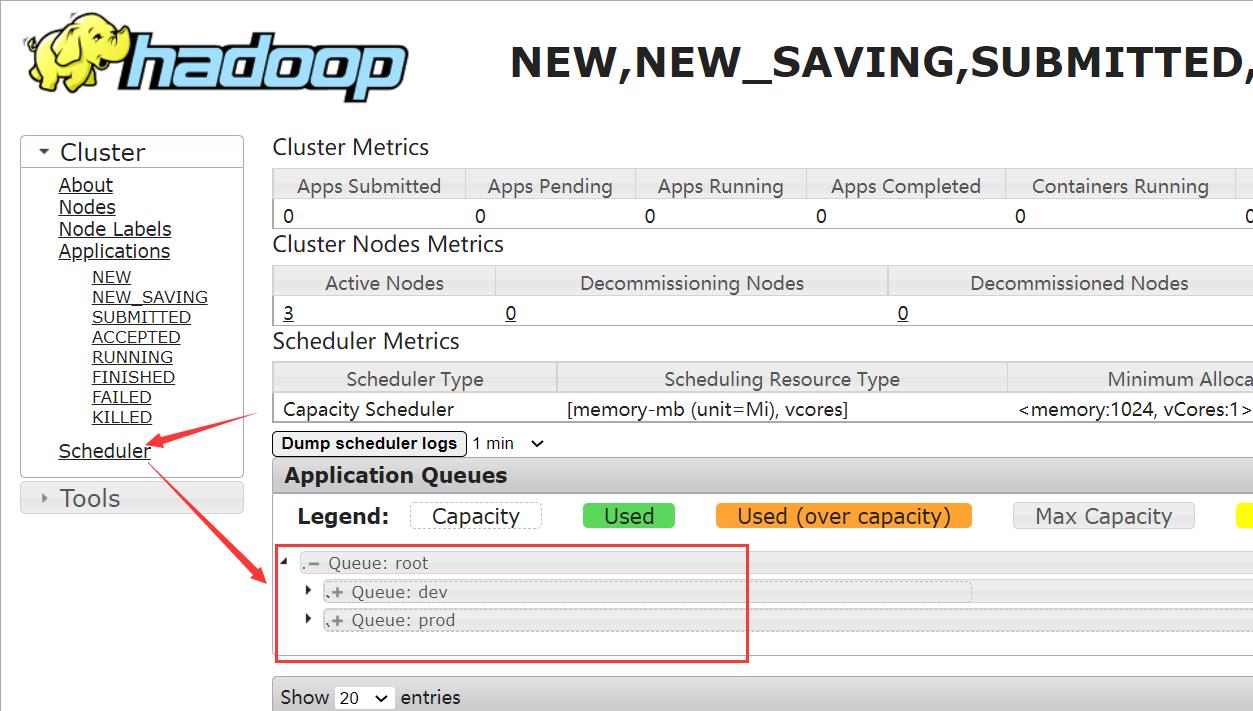
OK,我们配置成功了!
测试:
接下来,我们来测试一下:
① 我们提交到dev队列
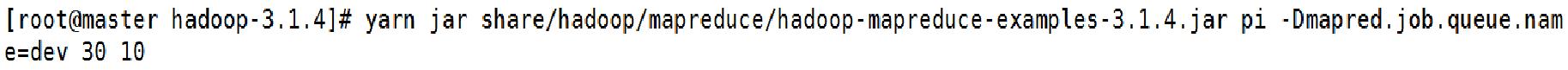
在网页上我们可以看到任务已经提交了

在网页上,我们可以看占用资源查看:

② 提交到prod队列

通过提交到dev和prod ,我们可以得出:不管是dev还是prod queue都不会占用Max_Capacity
以上是关于学习笔记Hadoop—— Hadoop基础操作的主要内容,如果未能解决你的问题,请参考以下文章
学习笔记Hadoop—— Hadoop基础操作—— Hadoop安全模式Hadoop集群基本信息
学习笔记Hadoop—— Hadoop基础操作—— MapReduce常用Shell操作MapReduce任务管理