大数据学习笔记~Hadoop基础篇
Posted 南城、每天都要学习呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习笔记~Hadoop基础篇相关的知识,希望对你有一定的参考价值。
前言
记录我在学习大数据技术中的学习笔记
目录
一、Hadoop介绍
Hadoop适合海量数据分布式存储和分布式计算
Hadoop的作者是Doug Cutting ,Hadoop这个作者的孩子给他的毛绒象玩具起的名字
二、Hadoop发行版介绍
Apache Hadoop:官方版本,开源
Cloudera Hadoop(CDH):商业版本,对官方版本做了一些优化,提供收费的技术支持,提供界面操作,方便集群运维管理
HortonWorks(HDP):开源,提供界面操作,方便运维管理
建议在实际工作中搭建大数据平台时选择CDH或者HDP,方便运维管理
三、Hadoop核心架构发展历史
Hadoop1.x
MapReduce(分布式计算),HDFS(分布式存储)
Hadoop2.x
MapReduce,Others,YARN(资源管理),HDFS
Hadoop3.x
MapReduce,Others,YARN,HDFS
四、Hadoop三大核心组件介绍
Hadoop主要包含三大组件:HDFS+MapReduce+YARN
HDFS负责海量数据的分布式存储
MapReduce是一个计算模型,负责海量数据的分布式计算
YARN主要负责集群资源的管理和调度
五、Hadoop集群安装部署
a、伪分布式集群安装部署
伪分布式集群安装:使用一台Linux机器【建议在后续学习阶段使用伪分布式集群】
1.下载hadoop安装包
这里我使用的是hadoop3.2.0这个版本,下面是官网下载链接
 https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz2.设置静态ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33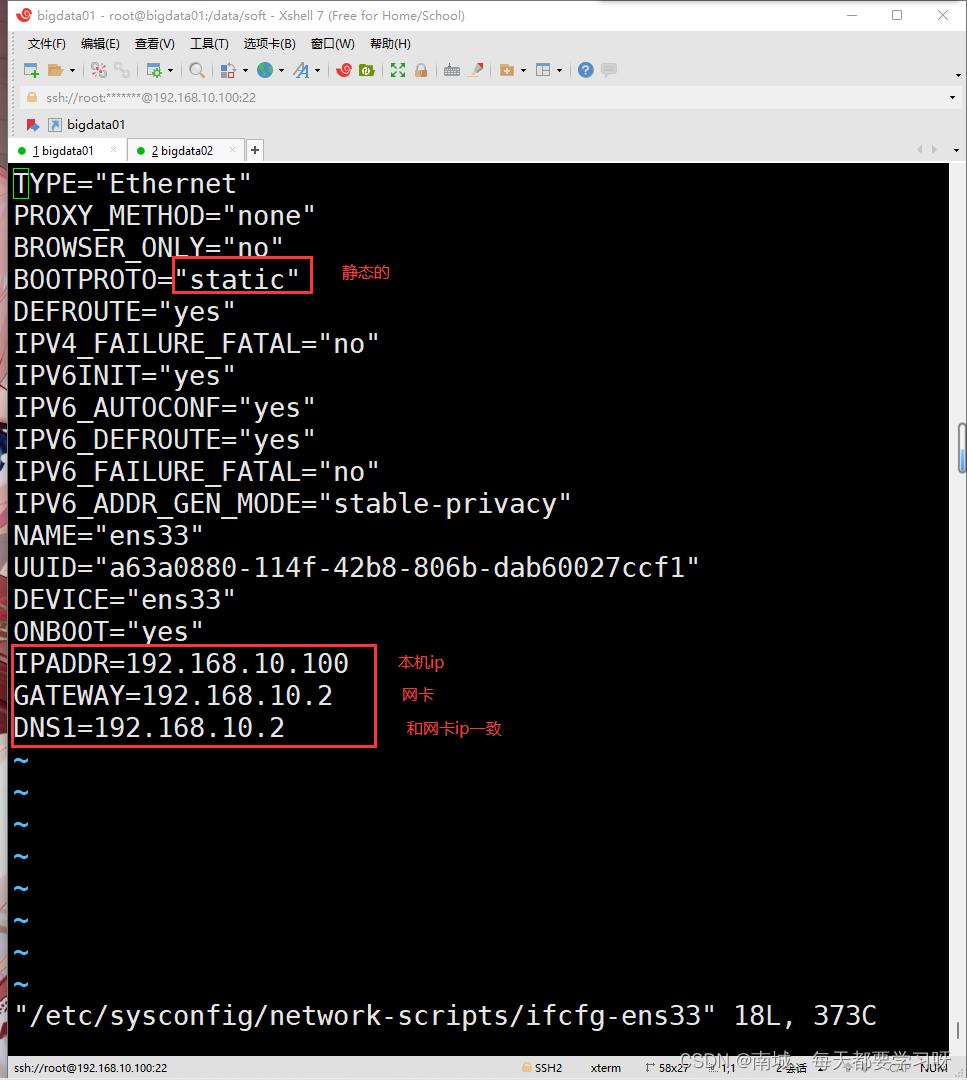
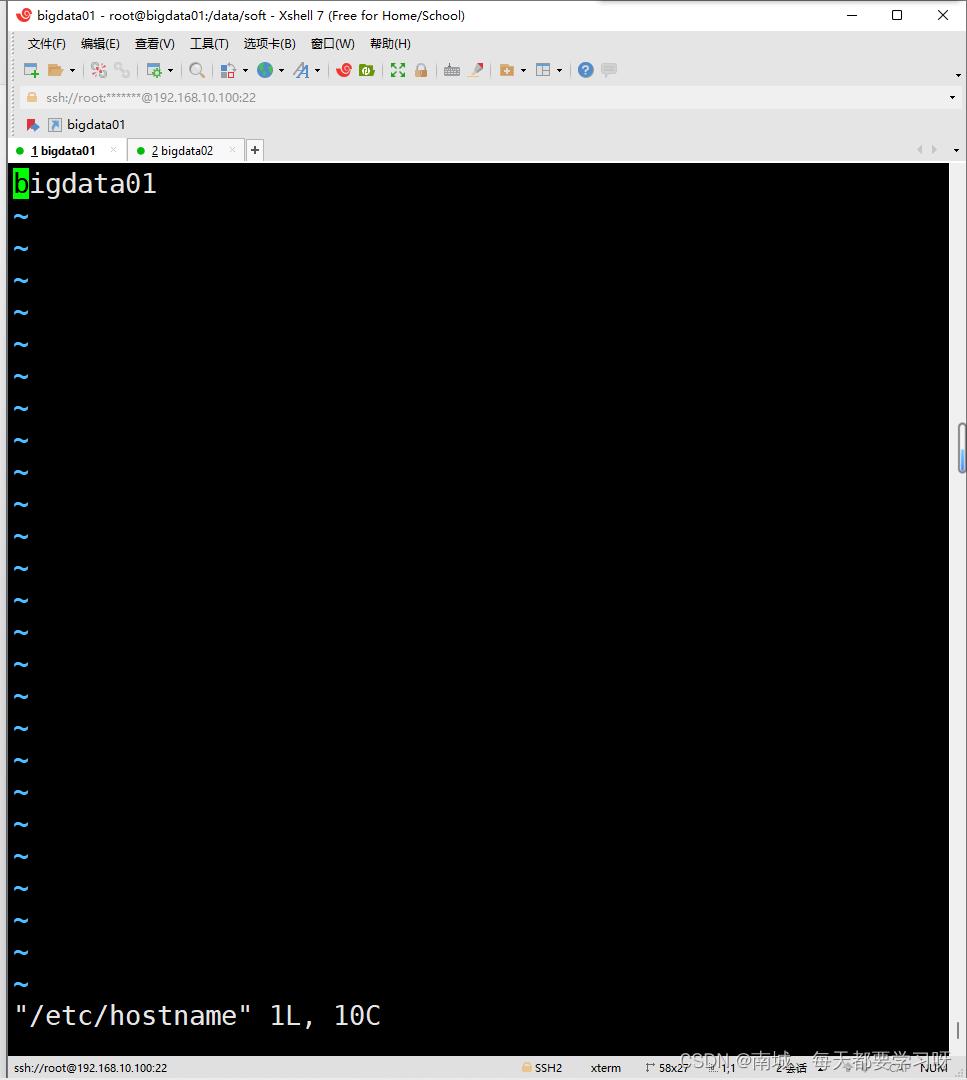
3、修改主机名
零时设置
hostname 主机名
永久设置
vi /etc/hostname
4.关闭防火墙
零时关闭
systemctl stop firewalld
查看防火墙状态
systemctl status firewalld
永久关闭
systemctl disable firewalld5.ssh 免密登录
ssh-keygen -t rsa一直回车就行

cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys登录时就不需要密码了

6.安装jdk
找到自己下载的jdk安装包,并通过Xshell上传至Linux中,解压jdk安装包
tar -zxvf jdk-8u202-linux-x64.tar.gz重命名一下
mv jdk-8u202-linux-x64.tar.gz jdk1.8配置环境
vi /etc/profile在文件最后添加(后面的路径根据自己jdk所在位置)
xport JAVA_HOME=/data/soft/jdk1.8
export PATH=.:$JAVA_HOME/bin:$PATH重新加载一下,使环境变量生效
source /etc/profile测试是否配置成功
java -version7. 上传Hadoop安装包
8.解压Hadoop安装包
tar -zxvf hadoop-3.2.0.tar.gz9.配置环境变量
vi /etc/profile在文件最后面添加

10.修改配置文件
cd /data/soft/hadoop-3.2.0/etc/hadoopvi hadoop-env.sh在文件末尾添加
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoopvi core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机名:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>存放日志的路径</value>
</property>
</configuration>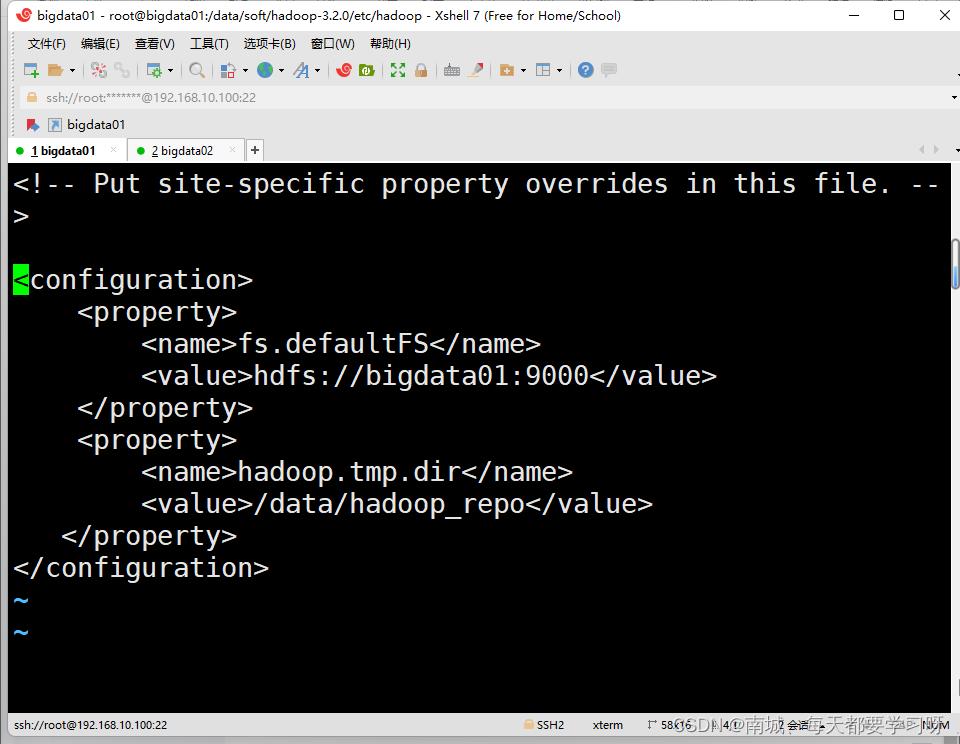
vi hedf-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>副本数</value>
</property>
</configuration> 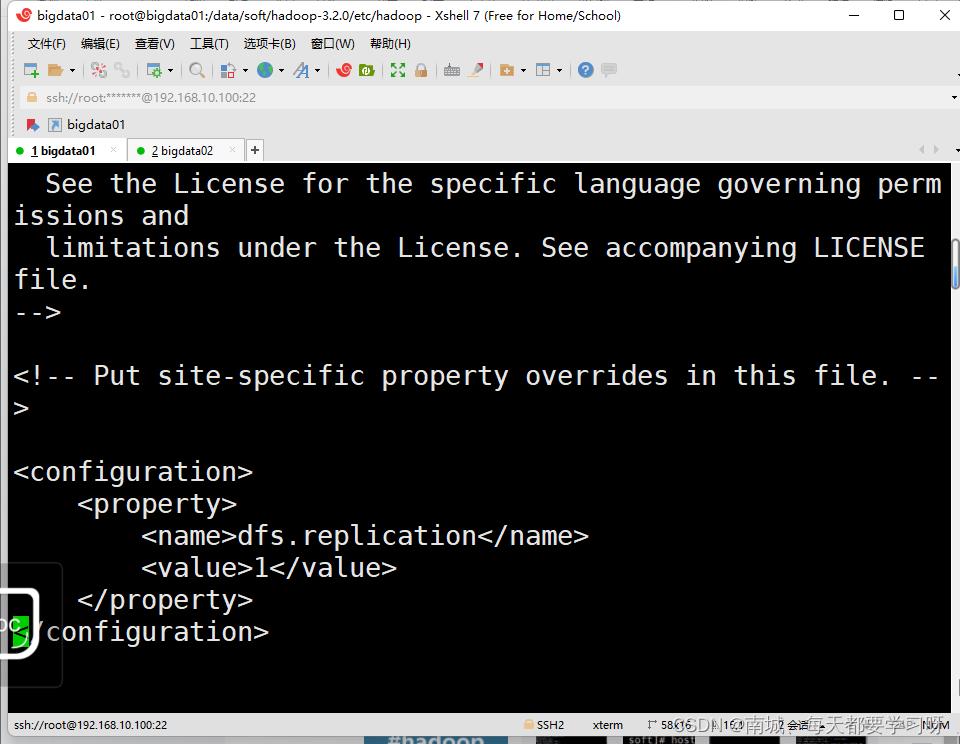
vi mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>指定执行引擎</value>
</property>
</configuration> 
vi yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>指定mapreduce计算框架</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration> 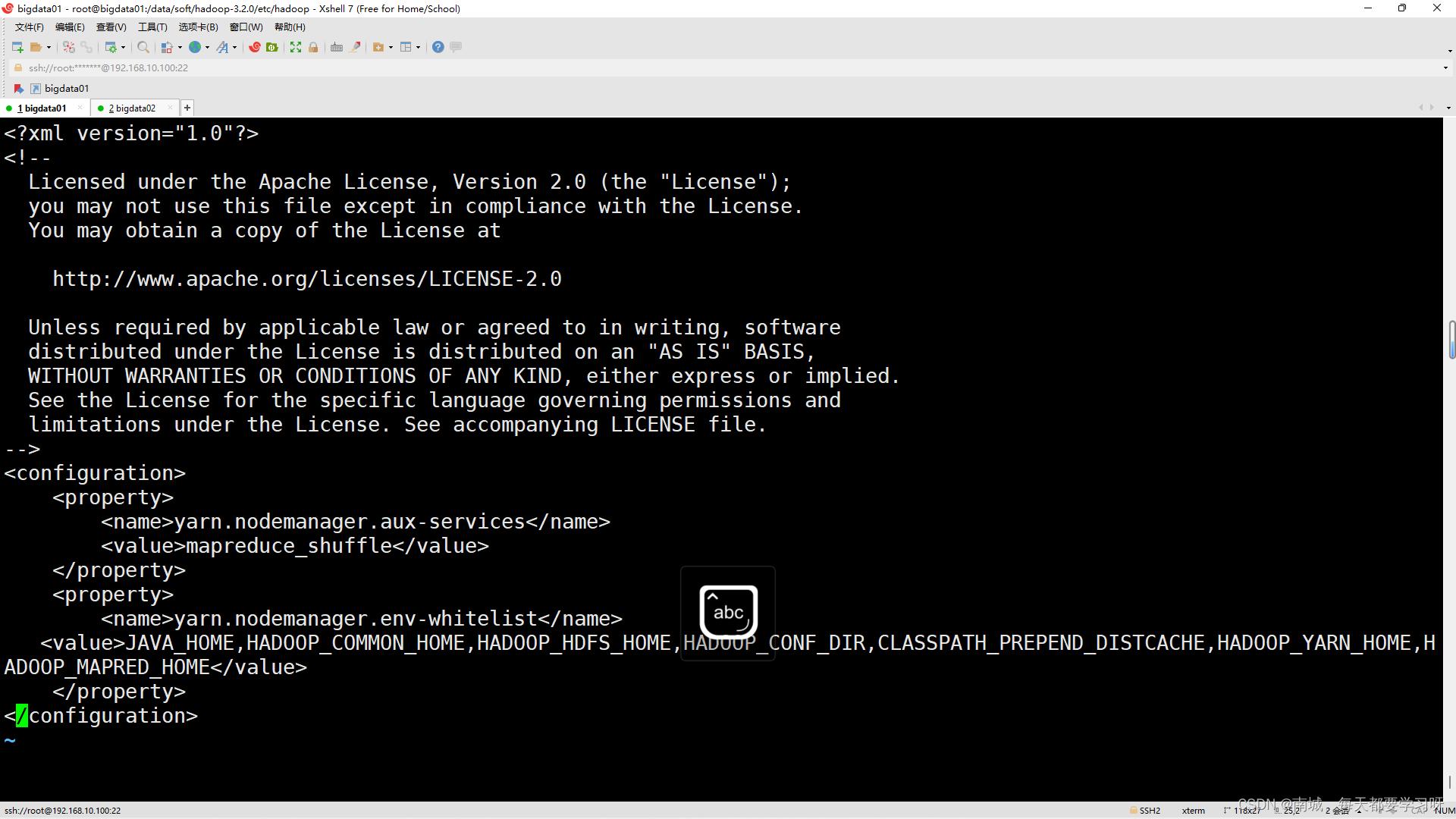
vi workers将所有内容删除,改成自己的主机名

11.格式化hdfs
bin/hdfs namenode -format12.修改启动脚本,添加用户信息
cd /data/soft/hadoop-3.2.0/sbinvi start-dfs.sh尽量加在文件上面点,因为后面的代码会使用到这些
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootvi stop-dfs.shHDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootvi start-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=rootvi stop-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root13.启动集群
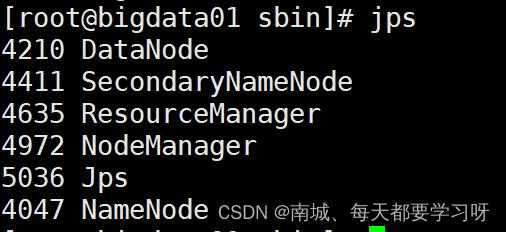
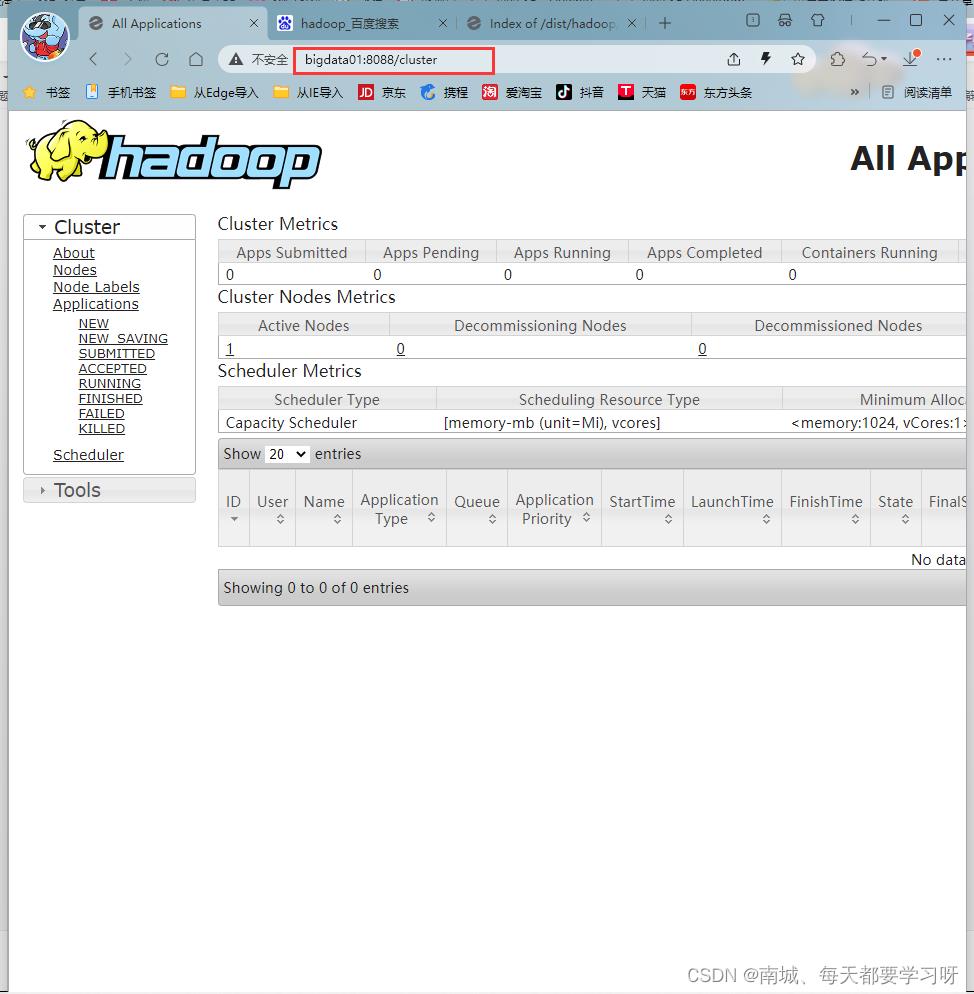
start-all.sh14.查看集群是否启动成功
jps看到这6个进程则为启动成功
hdfs 服务 端口号 : 9870
可以通过浏览器来进行访问
主机IP:9870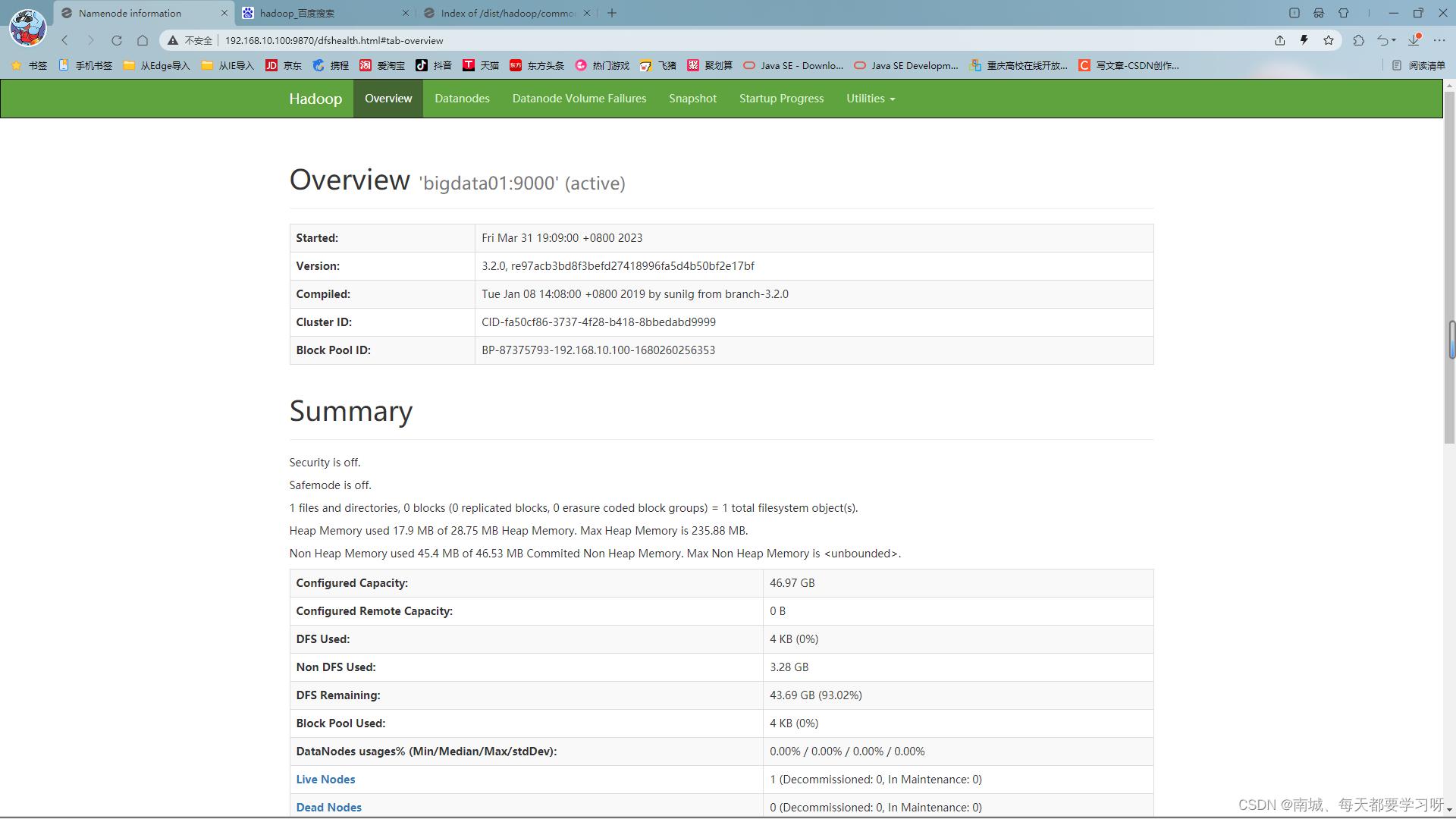
yarn 服务 端口号:8088
可以通过浏览器来访问
主机IP:8088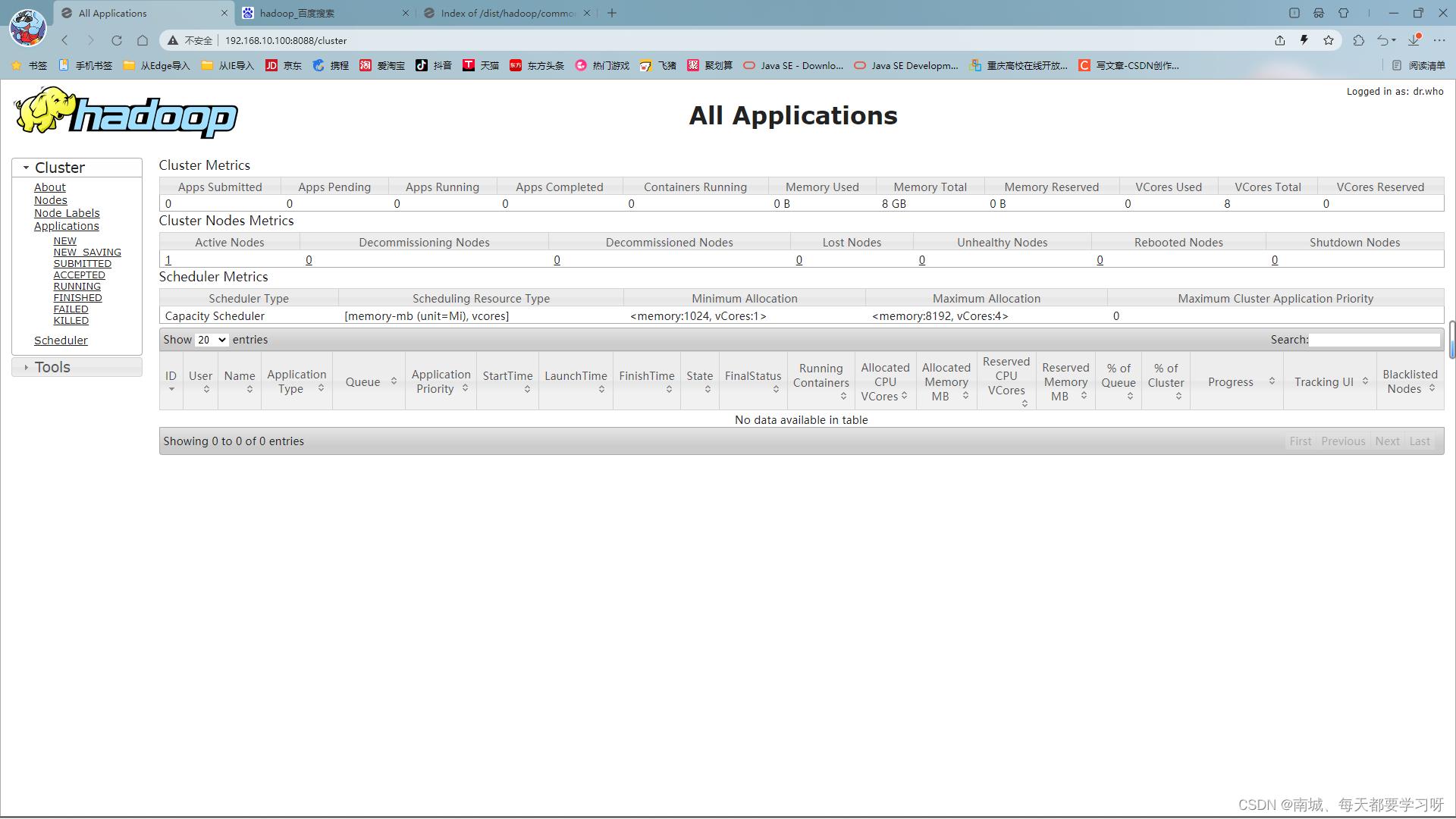 15. 配置windos中ip映射
15. 配置windos中ip映射

在最后添加

 16.停止集群
16.停止集群
stop-all.shb、分布式集群安装
使用三台Linux机器
master(主节点)
NamNode ,Secondary namenode ,Resource Manager
slave(从节点1)
DataNode ,NodeManage
slave(从节点2)
DataNode ,NodeManager
1.准备三台机器
通过克隆之前的bigdatao2,来创建第三台机器
更改第三台机器的ip地址
第二台机器的配置
更改ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33更改主机名
零时设置
hostname 主机名
永久设置
vi /etc/hostname
主机名防火墙
零时关闭
systemctl stop firewalld
查看防火墙状态
systemctl status firewalld
永久关闭
systemctl disable firewalld免密登录
ssh-keygen -t rsa一直回车
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys解压jdk
tar -zxvf jdk安装包名配置环境变量
vi /etc/profileexport JAVA_HOME=/data/soft/jdk1.8
export .:$JAVA_HOME/bin:$PATH第三台机器的配置和第二台机器的配置是一样的
2.修改三台机器中的hosts文件
vi /etc/hosts192.168.10.100 bigdata01
192.168.10.101 bigdata02
192.168.10.102 bigdata03
192.168.10.103 bigdata04
192.168.10.104 bigdata05三台机器都要修改,内容都是一样的
3.同步三台机器的时间
yum install -y netdatentpdata -u ntp.sjtu.edu.cn添加到定时任务中
vi /etc/crontab* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn三台机器都要执行
4.主节点实现免密登录其他从节点
先拷贝到家目录下
到主节点
scp ~/.ssh/authorized_keys bigdata02:~/
scp ~/.ssh/authorized_keys bigdata03:~/到从节点1
cat ~/authorized_keys >> ~/.ssh/authorized_keys到从节点2
cat ~/authorized_keys >> ~/.ssh/authorized_keys5.解压Hadoop安装包
tar -zxvf hadoop安装包名6.修改Hadoop配置信息
/data/soft/hadoop-3.2.0/etc/hadoopvi hadoop-env.shexport JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoopvi core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://主节点主机名:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>日志目录</value>
</property>
</configuration> 
vi hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>副本数</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
</configuration>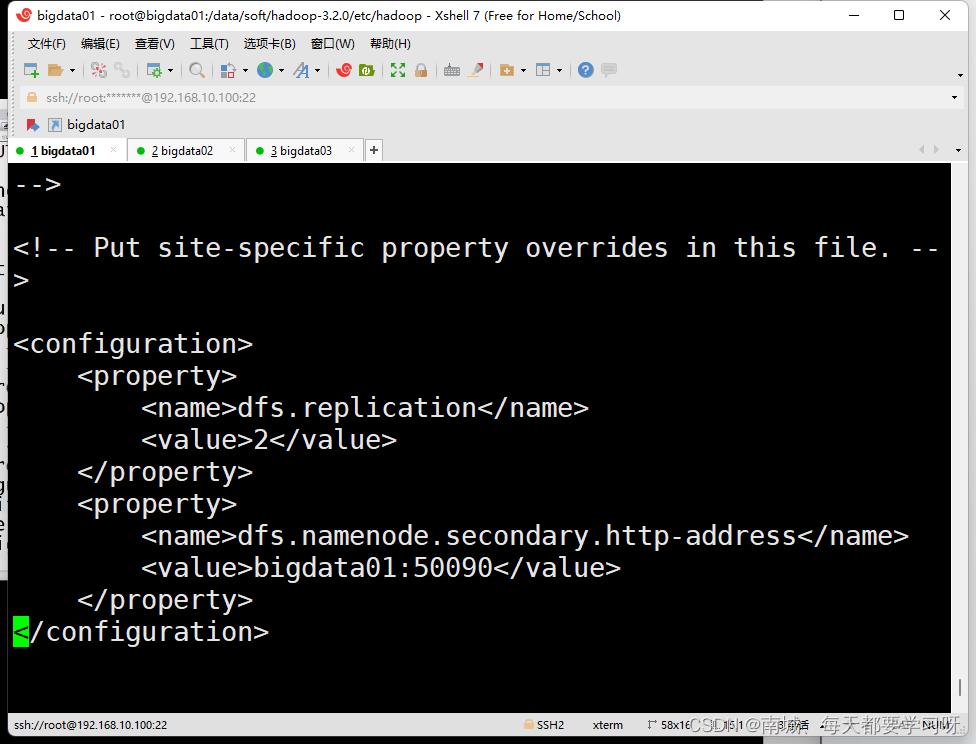
vi mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>vi yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>指定resourcemanager节点在那个机器上执行</value>
</property>
</configuration>
vi workers
bigdata02
bigdata03修改启动脚本
vi start-dfs.shHDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootstop-dfs.shHDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootstart-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=rootstop-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root7.纷发Hadoop文件夹
scp -rq Hadoop文件名 bigdat02:/data/soft
scp -rq hadoop-3.2.0 bigdata03:/data/soft8、格式化hdfs
hdfs namenode -format9.启动集群
start-all.sh10.关闭集群
stop-all.shc、Hadoop的客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的
建议在业务机器上安装Hadoop,这样就可以在业务机器上操作Hadoop机器了,此机器就称为Hadoop的客户端节点
大数据系统架构师学习笔记
0. 大数据相关预备课程
0.1 Java语言基础
0.1.1 Java OOP入门
0.1.2 Java核心编程
0.1.3 Java性能调优
0.2 Linux基础
0.2.1 Linux基础
0.3 MySQL基础
0.3.1 MySQL基础
1. Hadoop开发技术基础
1.1. LInux基础
1.2 大数据基础Hadoop 2.X
1.3 大数据仓库Hive
1.4 大数据协作框架
1.5 分布式数据库HBase
2. Hadoop大数据开发高级技术
2.1 Storm流计算入门到精通之技术篇
2.2 Scala语言从入门到精通
2.3 内存计算框架Spark
2.4 Spark深入剖析
2.5 企业大数据平台
3. 项目实战及项目剖析
3.1 驴妈妈旅游网大型离线数据电商分析平台
3.2 Storm流计算之项目篇
3.3 大数据面试
4. Java企业级核心应用
4.1 深入Java性能调优
4.2 Jav企业级开发必备高级技术
5. 分布式集群、PB级别网站性能优化
5.1 大数据高并发系统架构实战方案
5.2 大数据高并发服务器实战教程
6. 数据挖掘、分析&机器学习
6.1 深入浅出大数据挖掘技术
6.2 Lucene4.X实战类百度搜索的大型文档海量搜索
6.3 快速上手数据挖掘之solr搜索引擎高级教程
6.4 SPSS Modeler数据挖掘项目实战培训
6.5 数据层交换和高性能并发处理
6.6 数据分析与挖掘技术之R语言实战
6.7 深入浅出Hadoop Mahout数据挖掘实战
6.8 数据分析与挖掘技术之Python开发
6.9 大数据挖掘/分析师之硬技能——基于金融行业的大数据
6.10 云计算处理大数据深度、智能挖掘技术之地震数据
7. 机器学习
7.1 人工智能之机器学习
7.2 人工智能之深度学习+推荐系统
8. 大数据运维&云计算技术篇
8.1 Zookeeper从入门到精通
8.2 云计算Docker从零基础到专家实战教程
8.3 云计算Docker全面项目实战
8.4 深入浅出OpenStack云计算平台管理
9. 人工智能
以上是关于大数据学习笔记~Hadoop基础篇的主要内容,如果未能解决你的问题,请参考以下文章