Python爬虫--人人网模拟登录cookie
Posted 胜天半月子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫--人人网模拟登录cookie相关的知识,希望对你有一定的参考价值。
模拟登录
- 爬取基于某些用户的用户信息
需求: 对人人网进行模拟登录
- 点击登录按钮后,会发起POST请求
- POST请求会携带登陆之前录入的相关的登录信息(用户名、密码,验证码。。。)
- 验证码:每次请求都会动态变换(保证验证码与POST请求是一一对应的)
为什么叫模拟?
我们并不是在浏览器中实现真正的登录,而是通过我们的request模块,通过爬虫工具去模拟当前的浏览器进行登录
- 点击登录按钮会发起一个post请求
post请求中会携带登陆之前的相关的登录信息(用户名,密码,验证码…)- 验证码:每次请求,都会动态变化【每次需要把验证码和登录这两个操作的post请求放在同一个文件中进行操作,这是为了保证验证码和POST请求一一对应】
重点是验证码是动态变化的,将验证码中的文字识别出后放入post请求中

一、人人网模拟登录
注意:在学习这个小节的时候,由于人人网无法注册,因此没有办法在此演示,但继续创作这篇文章的目的是希望自己能够对以前的知识进行巩固,加深request模块请求步骤的熟悉!
- 编码流程⭐
- 验证码的识别,获取验证码图片的文字数据
- 对post请求进行发送(处理请求参数)
- 对响应数据进行持久化存储

1.1 验证码识别
到这里,只是网页中的验证码下载到了本地,但是需要使用超级鹰云平台进行识别:(Python爬虫之网站验证码识别(三)),不同的是需要更换验证码类型为2004

1.2 发送post请求


通过持久化存储进行验证

通用的操作是使用响应状态码

1.3 模拟登录cooki操作
需求:爬取当前用户的相关用户信息(个人主页中显示的用户信息)


- 爬取当前用户的个人主页的页面数据

- 效果展示
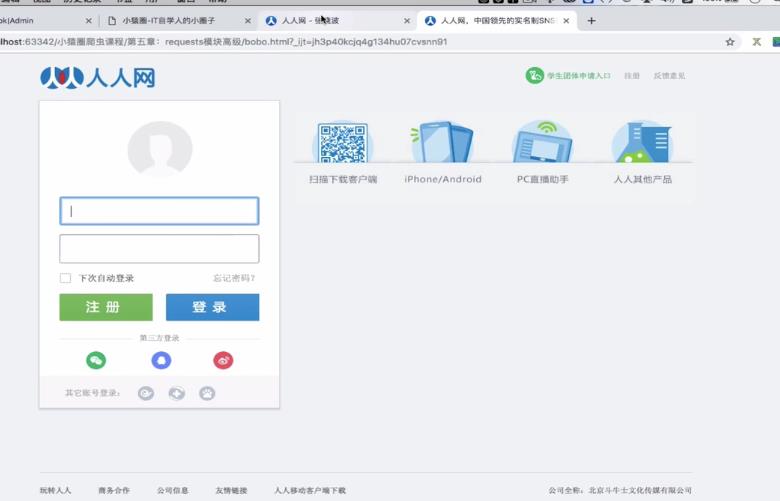
发现爬取下来的用户个人信息界面是空的,没有显示个人主页界面,而是登录界面
- 解释上述现象
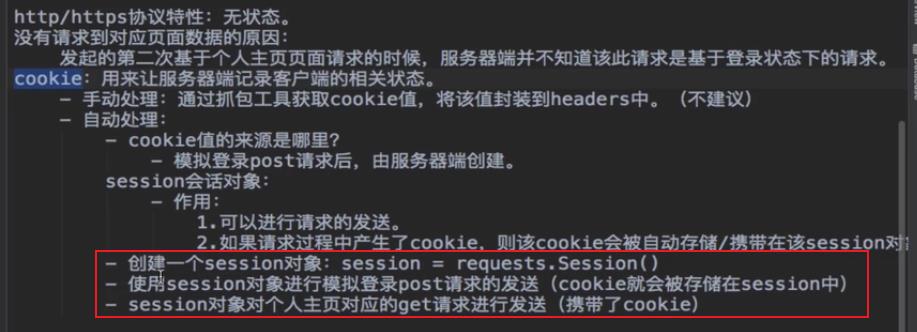
http/https协议特性:无状态
无状态:当用户向当前服务器发起请求,服务器并不会记住当前用户相关的状态
对于本例,当前想要爬取人人网个人主页的用户数据,那整个的编码中,我们一共向人人网发起了两次请求,在我们发第二次请求,想要请求人人网个人主页源码数据的时候,其实我们是想要服务器知道我们在发第二次请求的时候,我们已经经过登录了。即我的第二次请求应该是让服务器端知道我是在登录之后才发起的第二次请求,但是服务器是不会保留用户的用户状态的。【服务器不会记录第一模拟登录成功的状态】,因此,这就导致第二次请求出现失败
没有请求到对应页面数据的原因:
发起的第二次基于个人主页页面请求的时候,服务器端并不知道该此请求是基于登录状态下的请求
1.4 cookie
用来让服务器端保留或者记录客户端的相关状态
在这里插入代码片
为什么在浏览器中就可以对个人主页的url发起get请求拿到数据,而使用request模块中就不可以?


因此只需携带cookie就可以
1. 手动cookie处理
通过抓包工具获取cookie值,将该值封装到headers中。(不建议使用)

不建议,有的网站cookie值可能是存在有效时常的,过了该时间段,cookie可能无法使用;有的网站也是动态变换的
2. 自动处理
cookie值的来源是哪里?
模拟登录post请求后,由服务器端创建

- session会话对象⭐
作用:
- 可以进行请求发送
- 如果请求过程中产生了cookie,则该cookie会被自动存储/携带在该session对象中
- 步骤⭐⭐
- 创建一个session对象:
session = requests.Session()- 使用session对象进行模拟登录post请求的发送(cookie就会被自动存储在session中)
- session对象对个人主页对应的get请求进行发送(携带了cookie)
- 代码
# 创建一个session对象
session = requests.Session()
# 对验证码图片进行捕获和识别
。。。
。。。
。。。
# 使用超级鹰云平台进行图片识别
。。。
# 使用session进行post请求发送
response = session.post(url = login_url,headers = headers, data = data)
# 使用携带cookie的session进行get请求的发送
detail_page_text = session.get(url = detail_url,headers=headers).text
with open('bobo.html','w',encoding = 'utf-8') as fp:
fp.write(detail_page_text)
- 结果展示

二、代理讲解
在requests模块中如何使用代理IP的操作
首先,我们在做爬虫的过程中,可能一开始会正常的运行和正常的抓取数据,然而一杯茶之后可能出现相关的错误:403,这个时候,打开对应的网页可能会出现:您的IP访问频率过高的提示,出现这种现象的原因就是因为你爬取的相关网站所采取的某种反爬措施。服务器可能会检查某个IP单位时间发起请求的次数。
如果采取某种方式可以伪装本机IP,让服务器识别不出本机IP 发出的请求,就会防止封IP的服务器端行为,这也是一种反反爬机制
- 代理
破解封IP这种反爬机制
什么是代理?
代理服务器:网络信息中的中转站
代理的作用是什么?⭐
- 突破自身IP访问的限制。
- 隐藏真实的IP,免受攻击
代理相关的网站:
- 快代理
- 西祠代理
- www.goubanjia.com 【× 无法打开】
- 福利 | 这些网站有免费代理IP!
代理ip的类型:
- http:应用带http协议对应的url中
- https:应用带http协议对应的url中
代理ip的匿名度:
- 透明:服务器知道该次请求使用了代理,也知道请求对应的真实ip
- 匿名:知道使用了代理,不知道真实ip
- 高匿:不知道使用了代理,也不知道真实ip
- 代理应用实例

如上,如果应用代理,则上面不会显示本机IP;
# 没有使用代理时
import requests
url = 'https://www.baidu.com/s?wd=ip' # 类型 https
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
page_text = requests.get(url=url,headers=headers).text
with open('ip.html','w',encoding='utf-8') as fp:
fp.write(page_text)

# 使用代理 proxies
page_text = requests.get(url=url,headers=headers,proxies={"https":'139.196.196.74'}).text
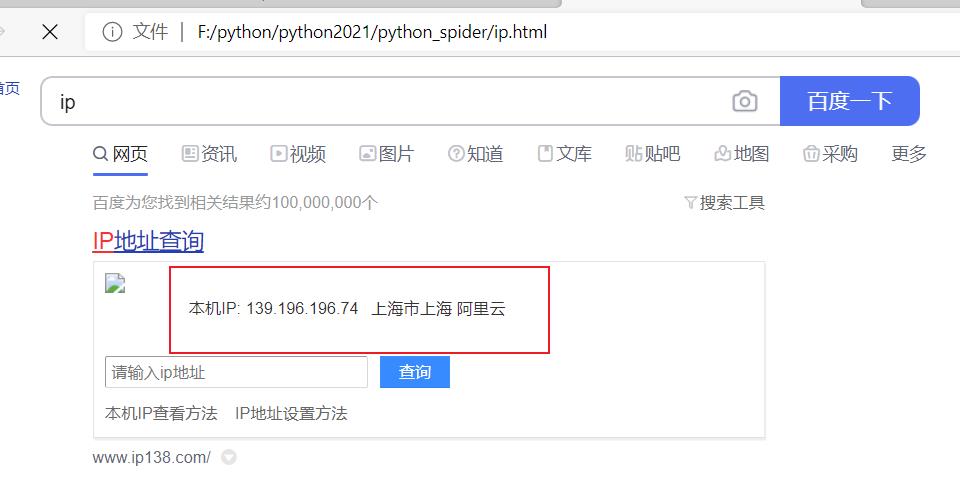
- ip代理实图

总结
- http/https协议特性:无状态
- session对象自动记录cookie值,和requests功能类似,都可以对url进行请求
- 模拟登录一般都需要进行cookie处理
以上是关于Python爬虫--人人网模拟登录cookie的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫之urllib模拟登录及cookie的那点事