python爬虫之模拟登录将cookie保存到代码中
Posted 坚持是一种习惯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之模拟登录将cookie保存到代码中相关的知识,希望对你有一定的参考价值。
#!/usr/local/bin/python3.7 """ @File : cookiejar_login.py @Time : 2020/04/05 @Author : Mozili """ import urllib.request import urllib.parse # cookiejar用来保存cookie import http.cookiejar # 创建一个cookiejar对象 cj = http.cookiejar.CookieJar() # 创建一个haddler对象 haddler = urllib.request.HTTPCookieProcessor(cj) # 创建一个opener对象 opener = urllib.request.build_opener(haddler) # post请求url post_url = \'http://team.speedtest.cn/login\' # post请求参数 data = { \'account\':\'mozili\', \'password\':\'xxx\' } # 创建请求头部 headers = { \'User-Agent\':\'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1 Safari/605.1.15\' } # 对参数进行处理 data = urllib.parse.urlencode(data).encode() # 创建一个request request = urllib.request.Request(url=post_url, headers=headers) # 发送请求,注意使用opener response = opener.open(request, data=data) # 打印请求结果 print(response.read().decode()) print(\'------我是分界线-------\') # 登录成功后,进行get请求 get_url = \'http://team.speedtest.cn/?type=my\' request = urllib.request.Request(url=get_url, headers=headers) response = opener.open(request) print(response.read().decode())
说明:
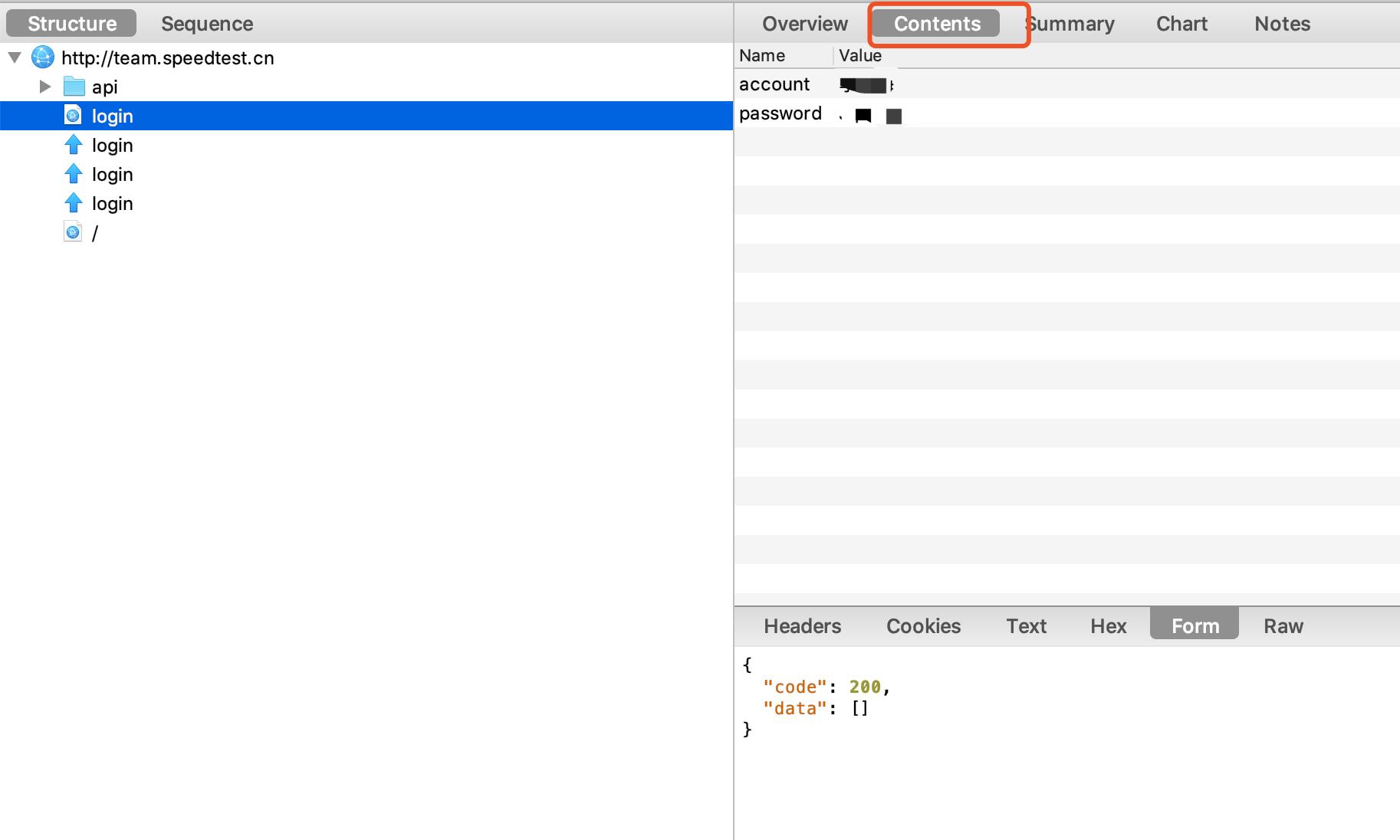
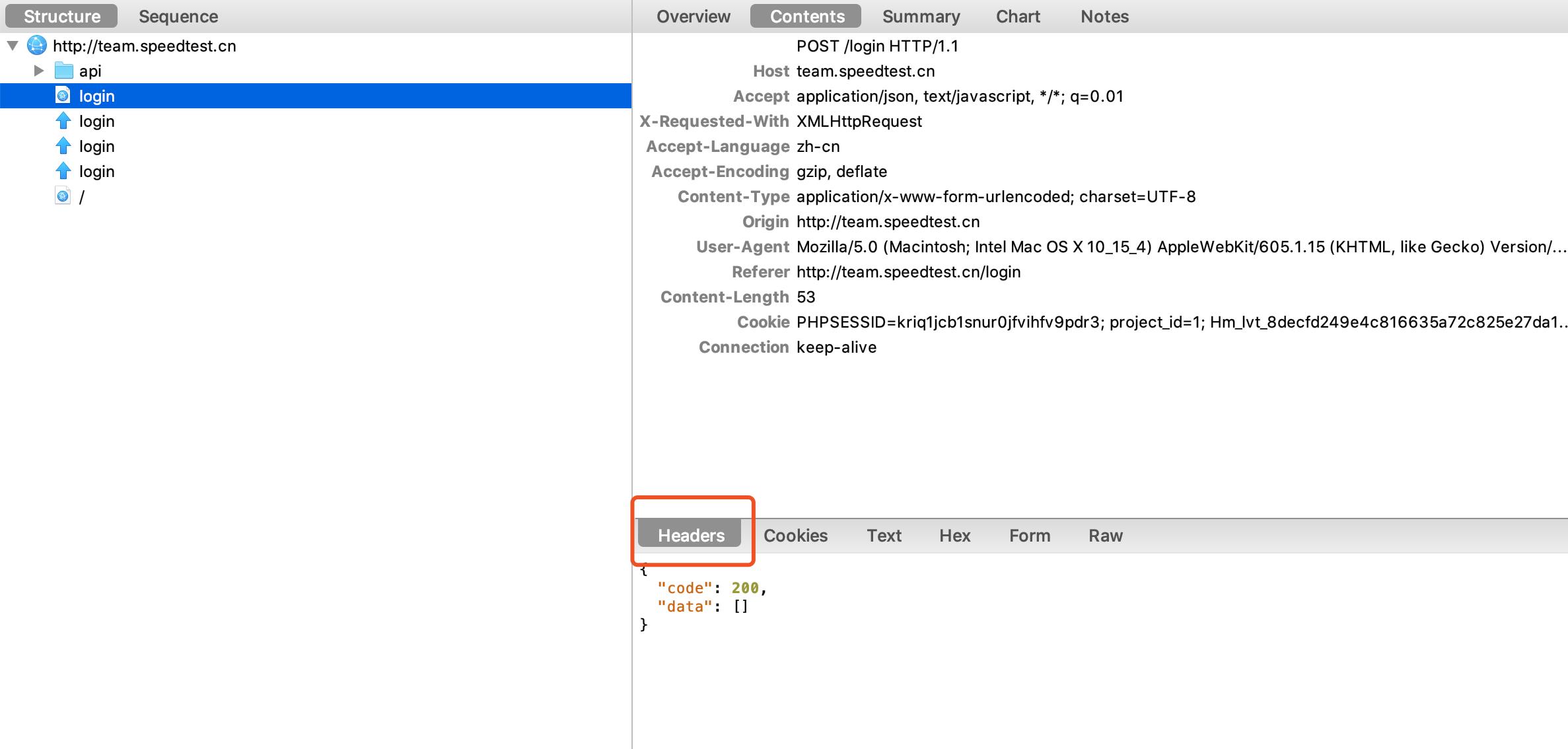
1、post请求url、请求数据以及请求头都痛过抓包工具获得(get请求也一样),如下图
(1)获取请求url

(2)获取data
(3)获取headers
以上是关于python爬虫之模拟登录将cookie保存到代码中的主要内容,如果未能解决你的问题,请参考以下文章