我Python采集了新榜热门内容,原来这就是别人能成为自媒体大佬的秘密!
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我Python采集了新榜热门内容,原来这就是别人能成为自媒体大佬的秘密!相关的知识,希望对你有一定的参考价值。
大家好,我是辣条,这是我爬虫系列的第25篇。
今天爬取的是一个自媒体人宝藏网站。
编辑区
编辑区包含了文章编辑的所有功能,重点是所有功能、素材都是免费的,像你写博客或者微信公众号都有用过这种类似的编辑器,但是免费的不多吧。
写作机器人
这个功能是很多自媒体小白的福利,想写作?但是自己没文字功底,这个神奇能帮助你描写文章,强烈推荐大家。
什么值得写
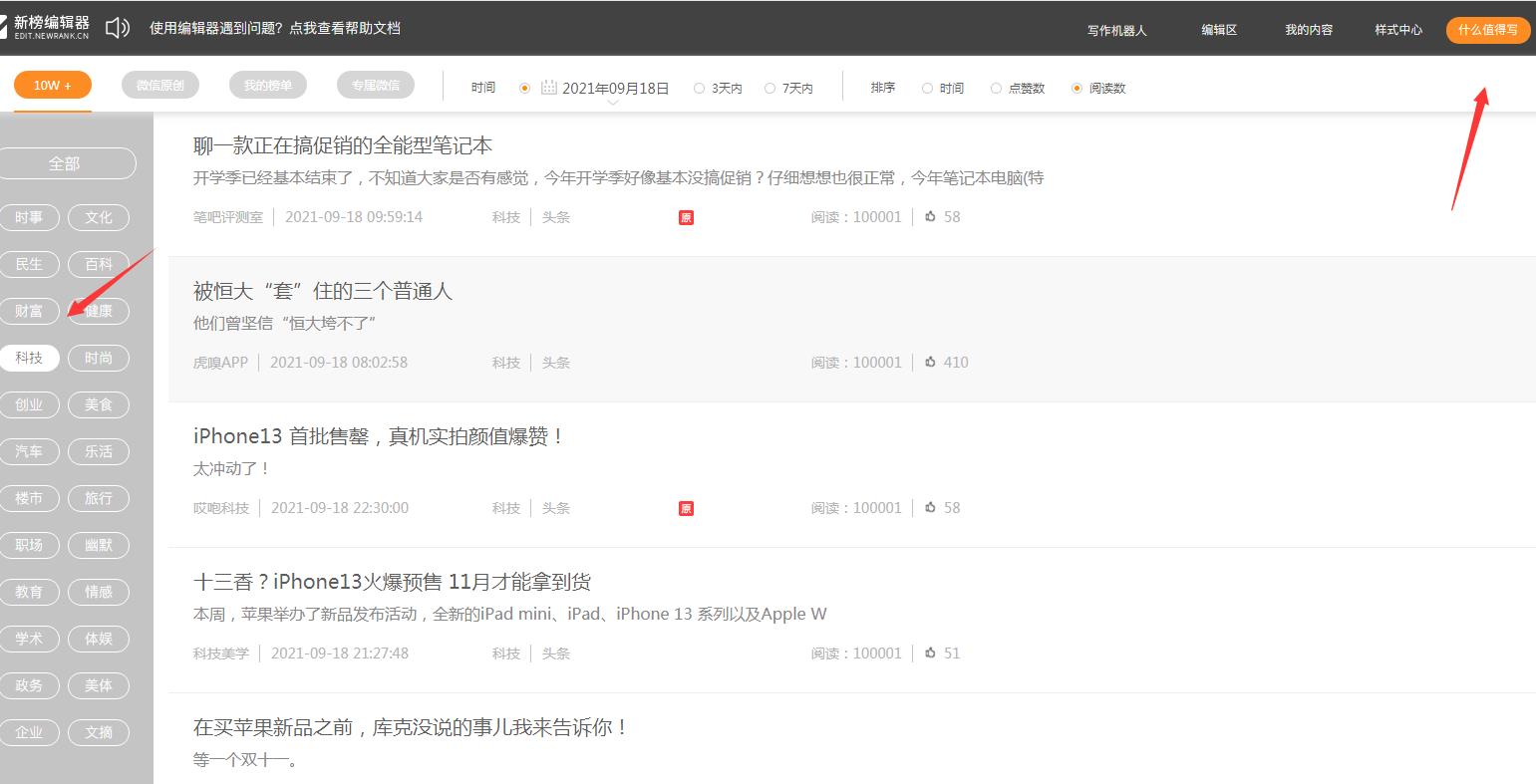
这个功能也非常强大,比如你想写科技领域的内容,这什么值得写功能就会推荐你最新该类型的热门文章。
这里只推荐三个功能,不写篇幅去介绍其他功能了,自己可以探索一下,直接进入今天的主题,爬取什么值得写推荐的热榜文章,学习一下从事自媒体别人是怎么写博客的。
采集目标
网址:新榜编辑
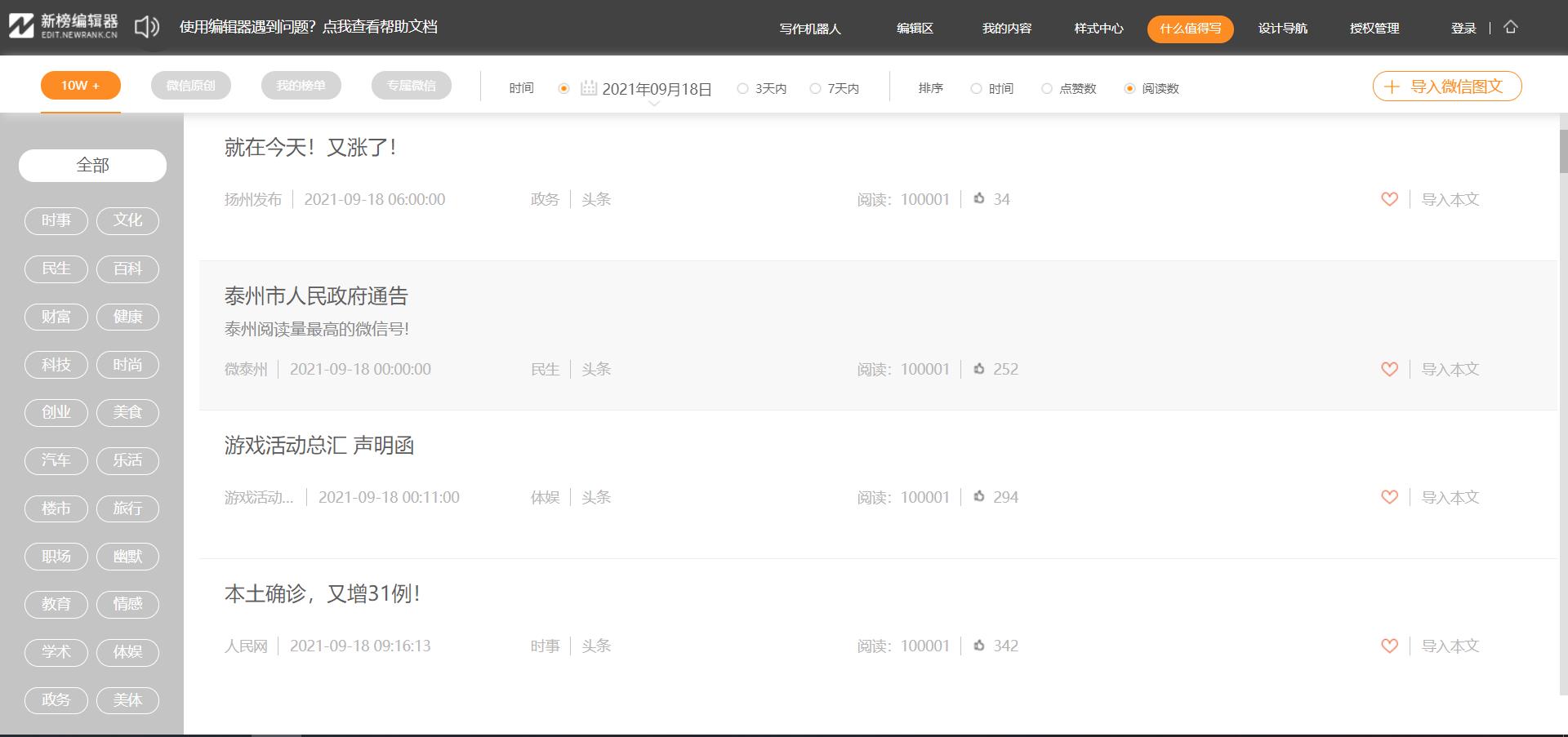
工具使用
开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,execjs
项目思路解析
今天这个网页虽然比较的实用,各位大大在之后也可以在当前网页挑选合适的文章内容进行书写,但是问题是啥呢,网页数据是加密的,辣条真的是夜不能寐。

首先爬虫常规操作找到目标数据的接口位置,打开抓包工具查看数据的加载方式,打开抓包工具的一瞬间数据没了
当前网页应该是做了开发者工具检测,把抓包工具以单独页面打开
单独打开就没有什么问题了,找到文件接口数据确定请求的url地址
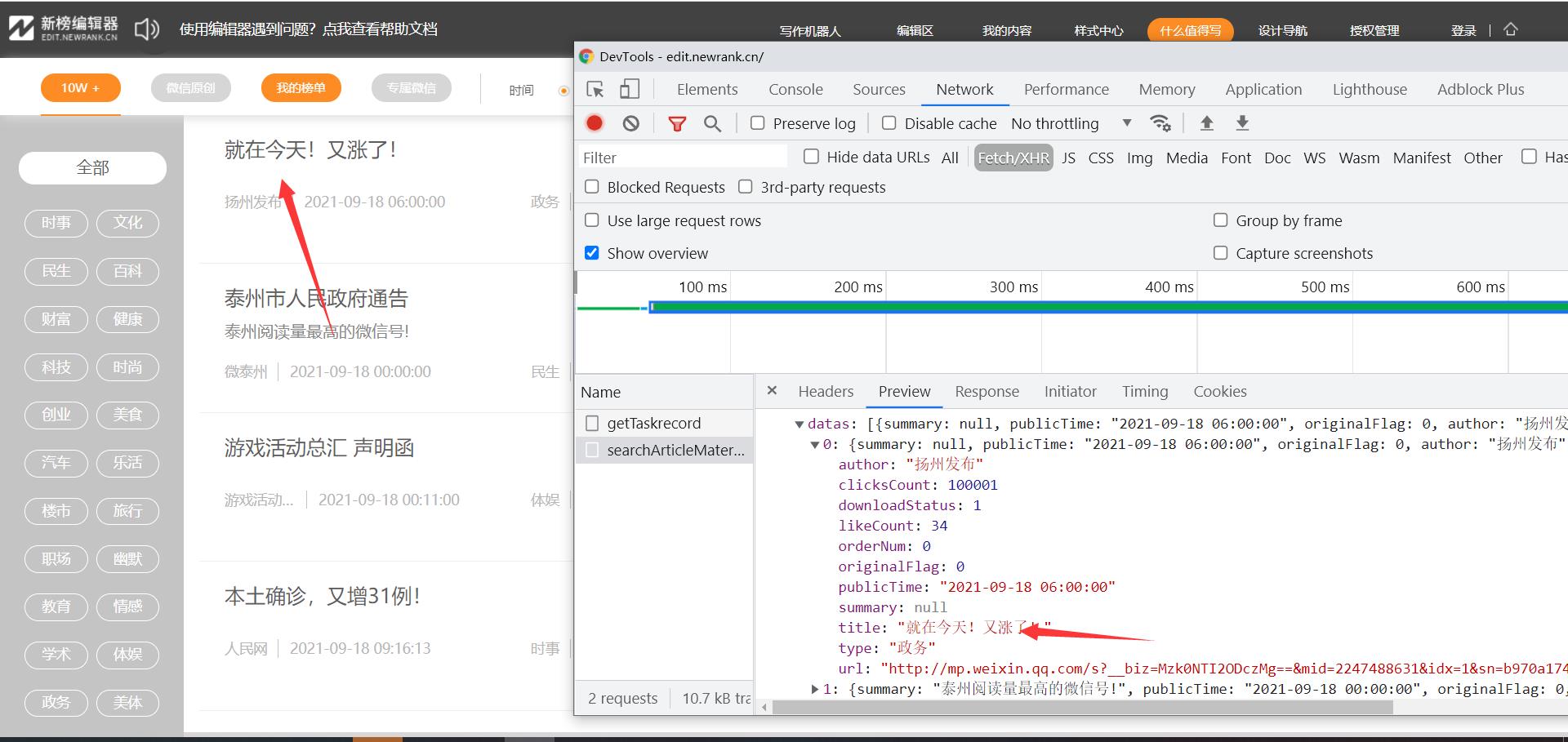
数据的接口 https://edit.newrank.cn/xdnphb/editor/articleMaterial/searchArticleMaterial
当前接口的请求方式为post,post请求就意味着需要传递数据

item能明显看出来数据数据加载的格式、日期、种类,数据的翻页就是通过日期来进行,nonece和xyz是加密数据,进行简单判断nonece、xyz应该都是md5加密 先找到nonece、xyz的加密位置,可以通过全局搜索也可以xhr断点调试的方法,只要能找到数据的加密位置就行,辣条这里就直接通过xhr断点找寻数据的发送位置
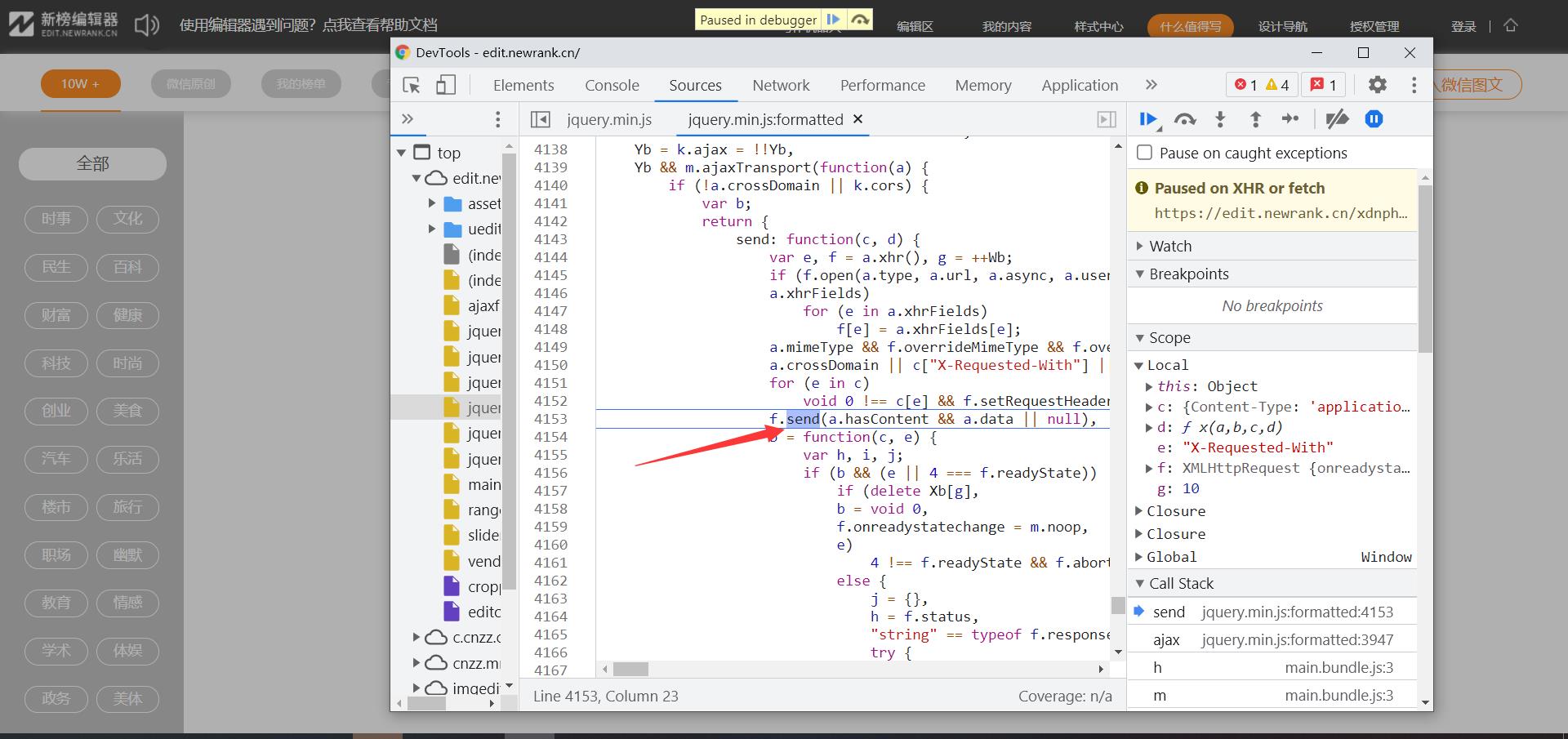
通过抓包工具右边的call stack找到后续的执行过程一个个点击查看找到发送数据的是在哪里生成的 传递的data数据为h 现在我们只需要找到h的生成位置就好了,h是由u得来的u是c函数生成的,nonece,zyz就是是在c函数生成
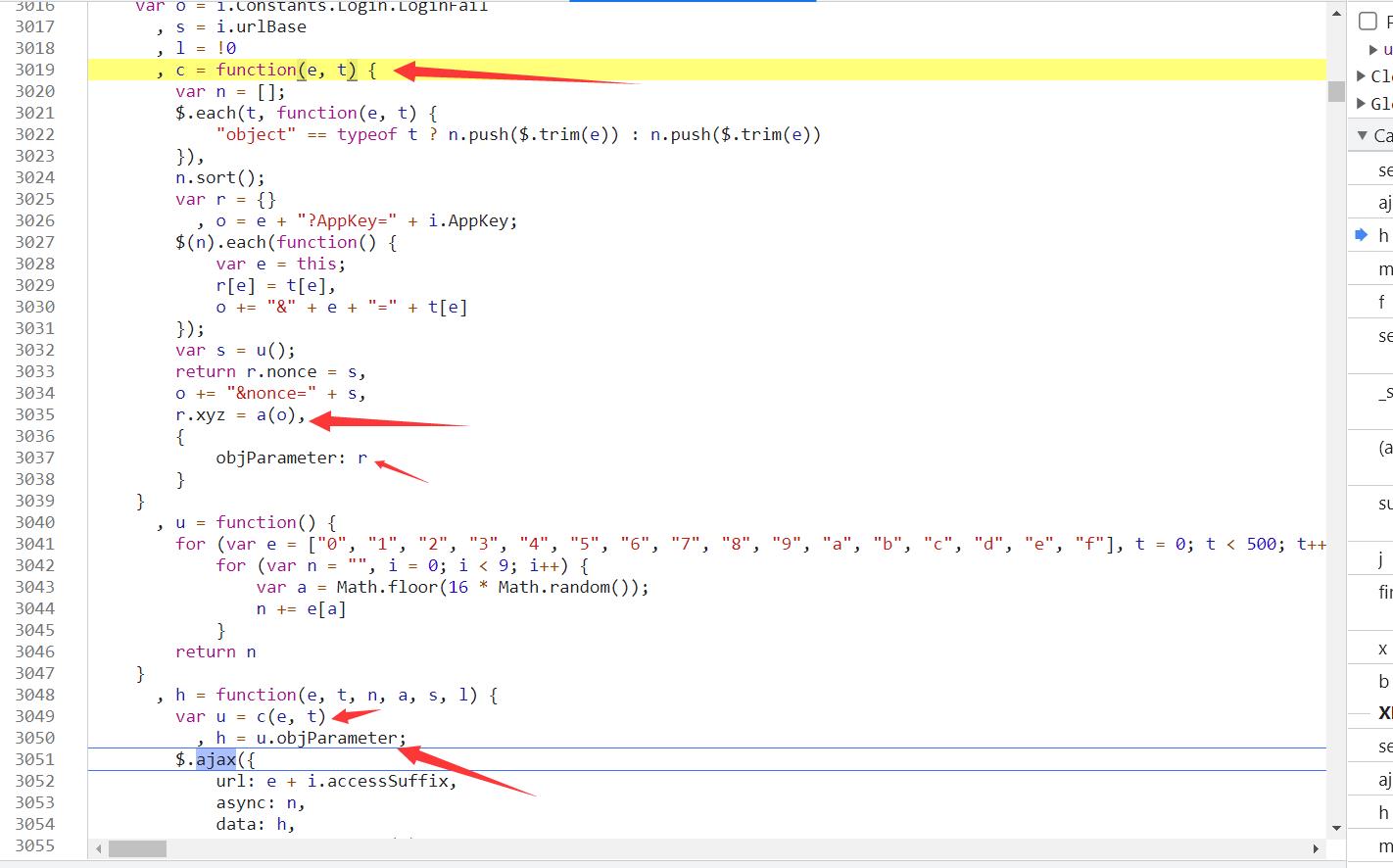
给位置数据打上断点,查看数据的加载规律,nonece为u方法生成的9个参数里的随机值

xyz加密的数据是o加上&nonece和nonece的值,o的参数是网址加上appkey在加上item的值
"/xdnphb/editor/articleMaterial/searchArticleMaterial?AppKey=joker&item={"type":"lakh","period":"1#2021-09-18","order":"2","extra":"全部","ranklist_id":"","weixin_id":"","start_time":"2021-09-18"}&nonce=6a65cad87"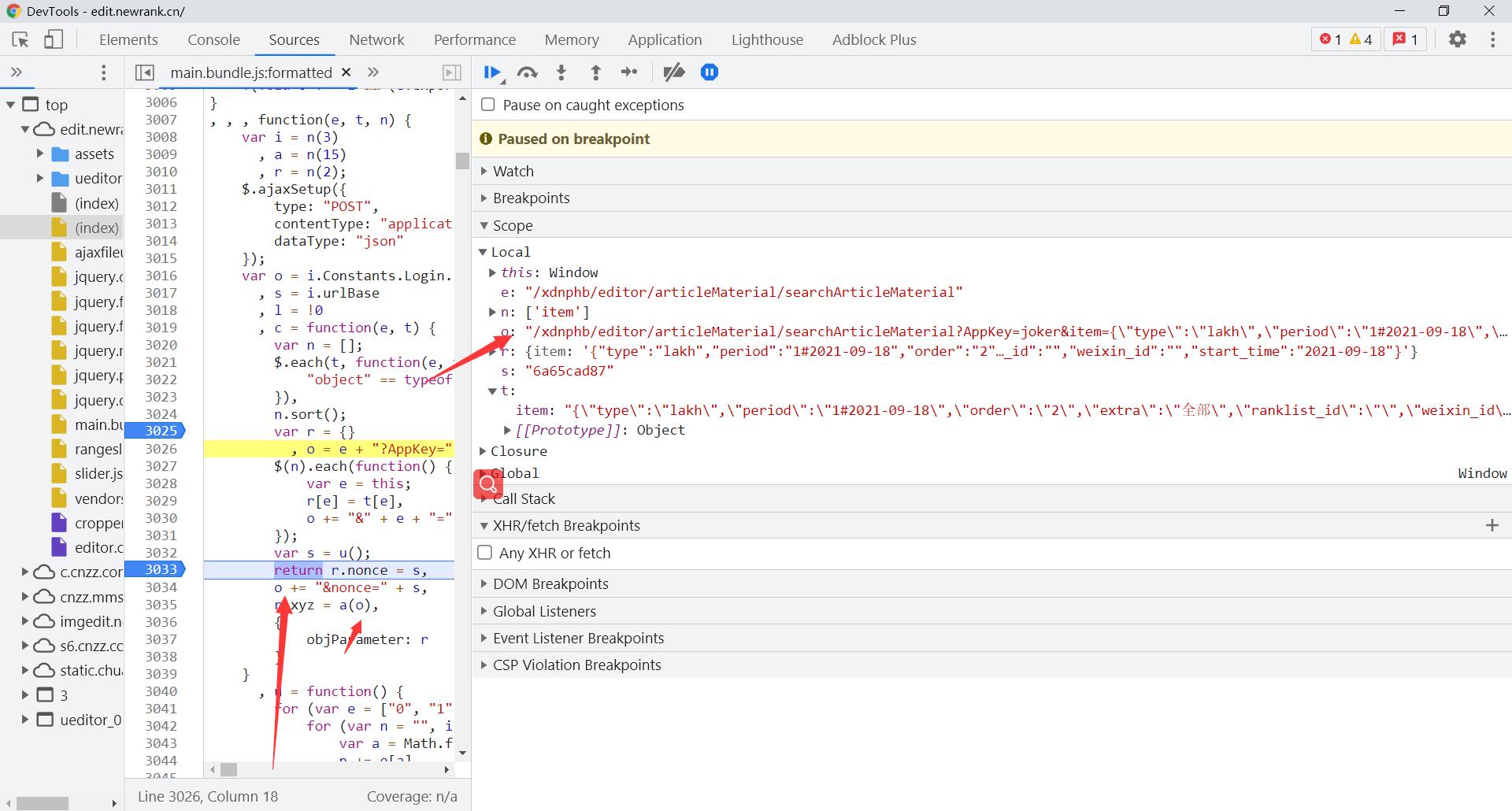
xyz加密的代码有点多,这是何等的卧槽

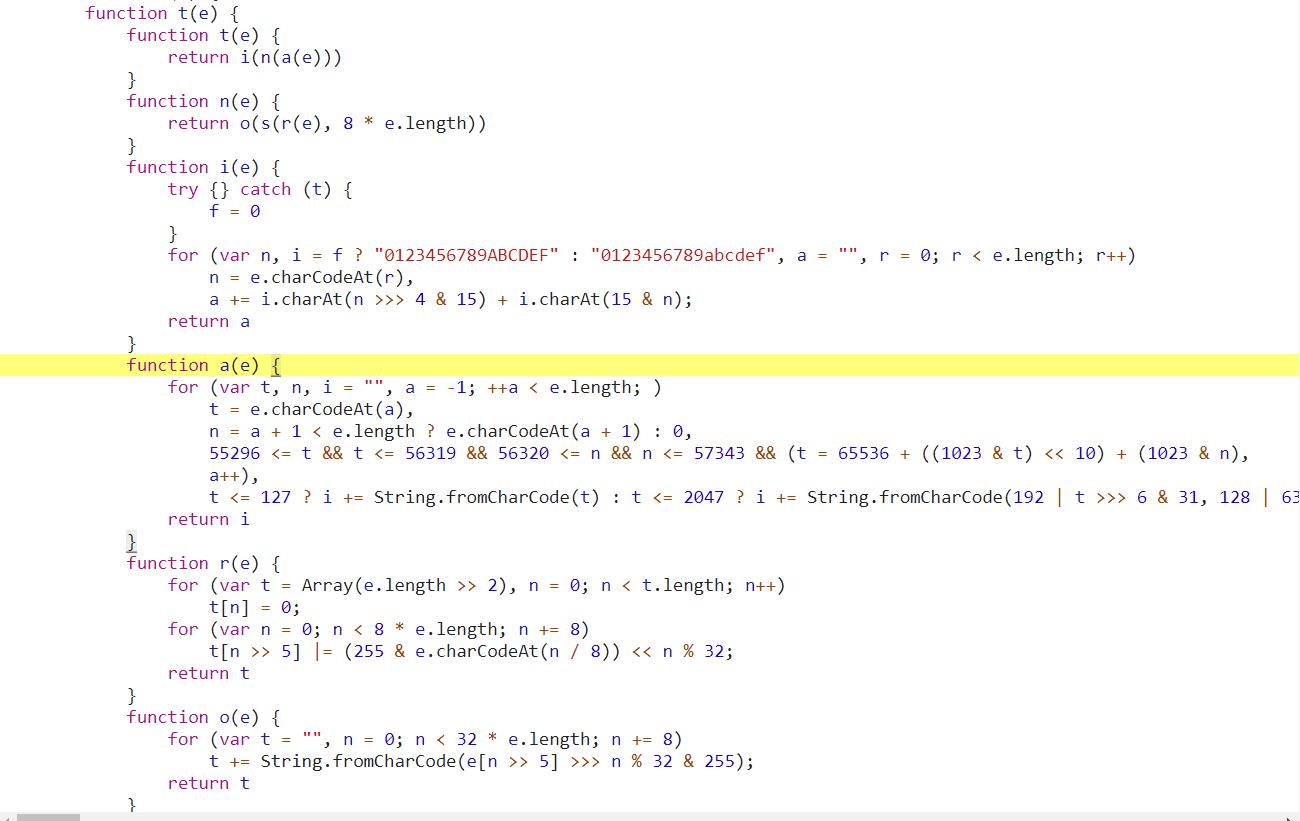
直接补环境好了,不去硬扣js代码了复制js代码到本地,先把加密函数给拿过来,把整个t函数拿到本地,自己运行尝试一下
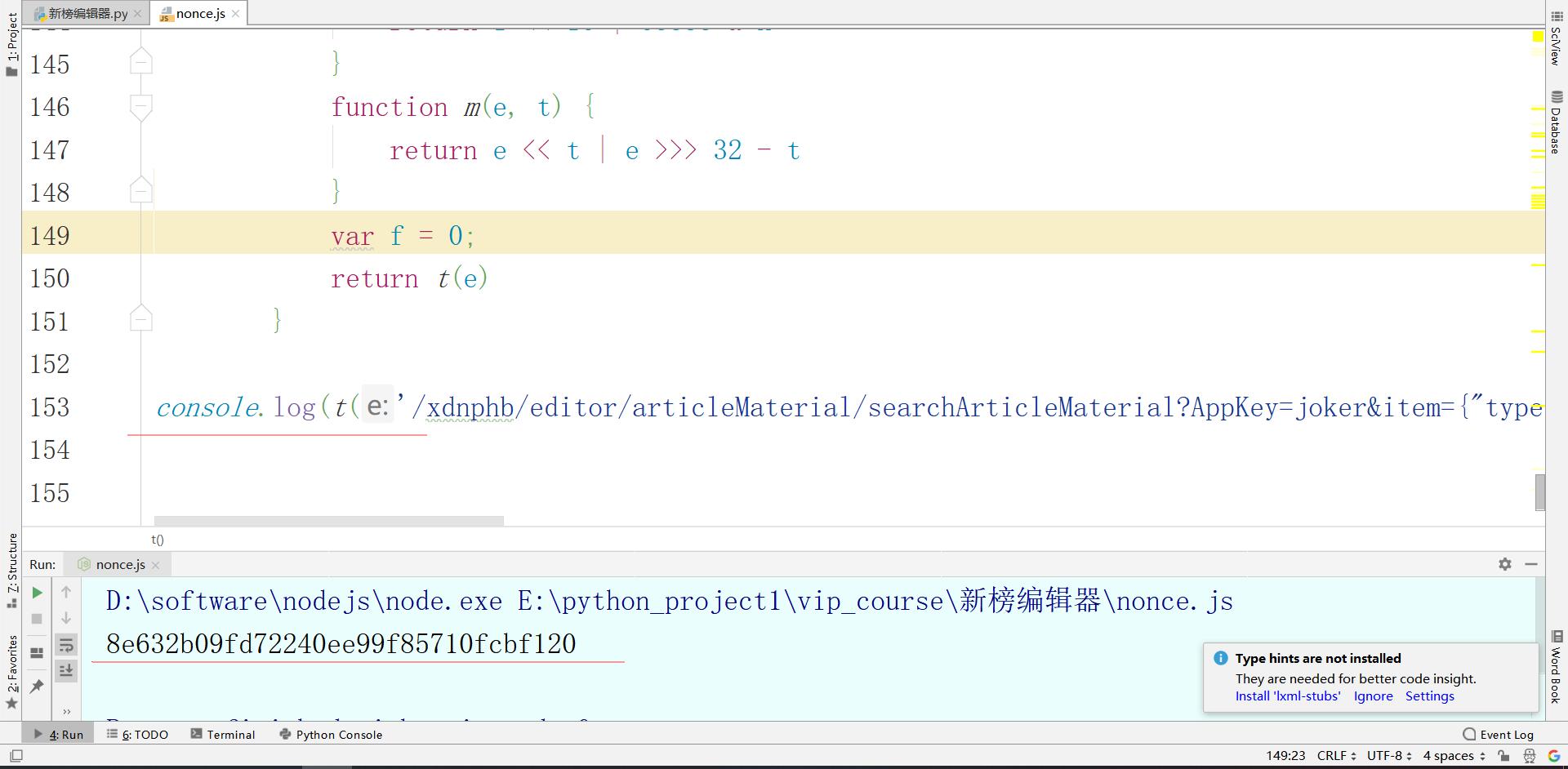
大功告成,数据的加密方式,加密规则都解决了,现在用Python整合,对目标网址发送请求,获取数据进行保存,各位大佬js源码可以自行扣取,只要t函数就可以了。
效果展示
简易源码分享
import execjs
import requests
import csv
nonce = execjs.compile(open('nonce.js').read()).call('u')
date = input('请输入你需要的日期(2021-07-19):')
xyz_code = '/xdnphb/editor/articleMaterial/searchArticleMaterial?AppKey=joker&item={"type":"lakh","period":"1#%s","order":"2","extra":"全部","ranklist_id":"","weixin_id":"","start_time":"2021-09-04"}&nonce=%s' % (date, nonce)
print(xyz_code)
xyz = execjs.compile(open('nonce.js').read()).call('t', xyz_code)
print(xyz)
url = "https://edit.newrank.cn/xdnphb/editor/articleMaterial/searchArticleMaterial"
data = {
'item': '{"type":"lakh","period":"1#%s","order":"2","extra":"全部","ranklist_id":"","weixin_id":"","start_time":"2021-09-04"}' % date,
'nonce': nonce,
'xyz': xyz
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
'referer': 'https://edit.newrank.cn/?module=article',
}
response = requests.post(url, headers=headers, data=data).json()
datas = response['value']['datas']
# print(response)
with open('新榜编辑器.csv', 'a', newline='', encoding='utf-8')as f:
for data in datas:
# print(data)
csv_data = csv.DictWriter(f, fieldnames=['summary', 'publicTime', 'originalFlag', 'author', 'orderNum', 'likeCount', 'clicksCount', 'downloadStatus', 'title', 'type', 'url'])
csv_data.writerow(data)行业资料:添加即可领取PPT模板、简历模板、行业经典书籍PDF。
面试题库:历年经典,热乎的大厂面试真题,持续更新中,添加获取。
学习资料:含Python、爬虫、数据分析、算法等学习视频和文档,添加获取
交流加群:大佬指点迷津,你的问题往往有人遇到过,技术互助交流。
领取

以上是关于我Python采集了新榜热门内容,原来这就是别人能成为自媒体大佬的秘密!的主要内容,如果未能解决你的问题,请参考以下文章
7月8日是个大日子没人反对吧?于是我用python采集了一下微博热门评论~