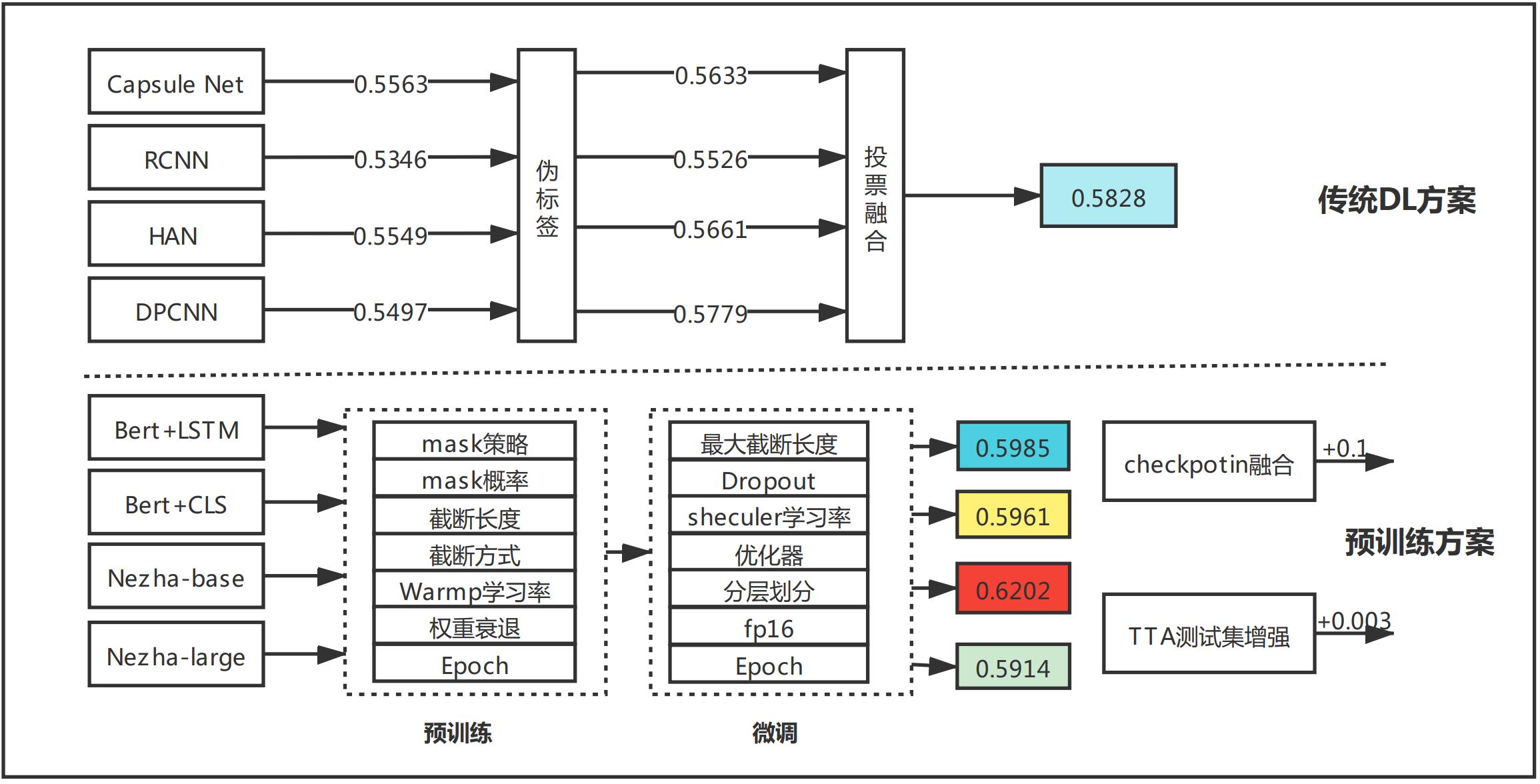
2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别2 DPCNNHANRCNN等传统深度学习方案
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别2 DPCNNHANRCNN等传统深度学习方案相关的知识,希望对你有一定的参考价值。
文章目录
相关链接
【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】1 初赛Rank12的总结与分析
【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】2 DPCNN、HAN、RCNN等传统深度学习方案
【2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别】3 Bert和Nezha方案
1 引言
(1)环境
python 3.6+
pytorch 1.7.1+
(2)重要方法
- 词向量: word2vec (300维度)+fasttext(100维度)进行拼接,并未对此进行调参
- 数据预处理:无。没有来得及去对比,数据预处理标点符号是否能带来更好的效果
- 句子截断最大长度:100,这是按照词的个数进行截断,不够的补0
- label编码:One-hot编码
- 损失函数:BCEWithLogitsLoss
- 除了HAN模型,其他模型在训练时固定embedding层,不训练
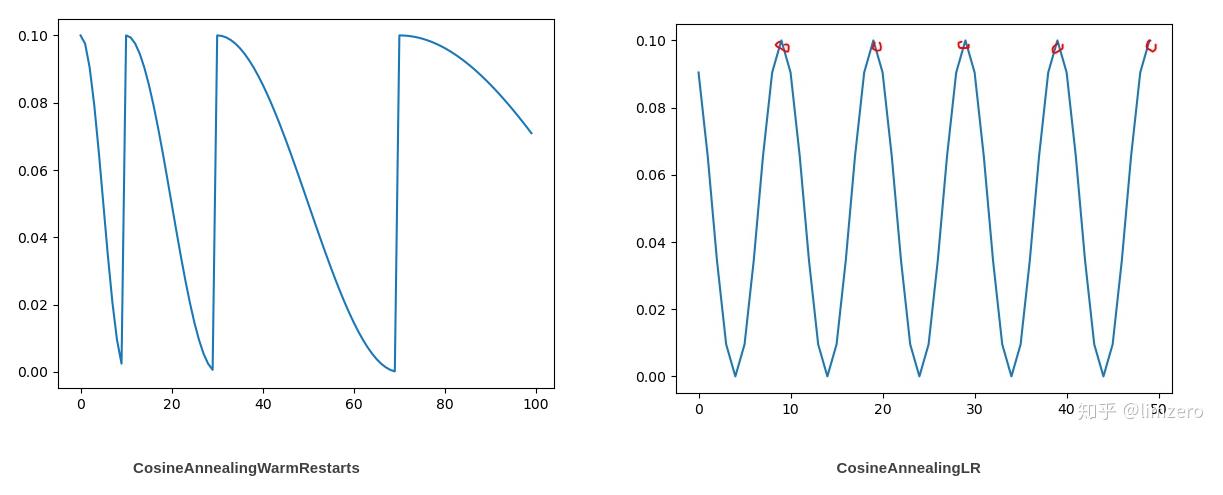
- 使用了余弦退火scheduler学习率
- CosineAnnealingWarmRestarts
- CosineAnnealingLR
-
对比了两种优化器,在改任务中AdamW更佳
- AdamW
- Lookahead
-
K折划分,对比了StratifiedKFold和Kfold,前者分层划分的效果更佳。
-
早停法来控制过拟合,具体实现看代码
-
Epoch = 40,太高容易过拟合,大部分部模型到了25Epoch以上几乎不在提升。在代码中用f1_score来控制模型的存储,每个fold中存储最佳f1_score的模型。
-
EDA数据增广:效果不佳
-
对抗训练:FGM和PGD 效果都不佳
(3)有待实现
- 数据预处理
- word2vec词向量、fastext词向量维度调参
- 训练深度,epoch 调参
- 数据增广
- 词级别的倒叙文本
- 句子级别的shuffle,按逗号和句号去shuffle语句顺序
- AEDA:插入符号的数据增强
2 方案实现
由于代码比较多,以下只给出了网络模型,完整代码见github
2.1 DPCNN
导入包
import gensim
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
import torch
from utils.spatial_dropout import SpatialDropout
class DPCNN(nn.Module):
def __init__(self, args, vocab_size, embedding_dim, embeddings=None):
super(DPCNN, self).__init__()
# self.dropout = 0.1 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = 35 # 类别数
self.learning_rate = 1e-3 # 学习率
self.num_filters = 250 # 卷积核数量(channels数)
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
hidden_size = 128
# 字向量维度
self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim)
if embeddings:
w2v_model = gensim.models.word2vec.Word2Vec.load(
"./embedding/w2v.model").wv
fasttext_model = gensim.models.word2vec.Word2Vec.load(
"./embedding/fasttext.model"
).wv
w2v_embed_matrix = w2v_model.vectors
fasttext_embed_matrix = fasttext_model.vectors
# embed_matrix = w2v_embed_matrix
embed_matrix = np.concatenate(
[w2v_embed_matrix, fasttext_embed_matrix], axis=1
)
oov_embed = np.zeros((1, embed_matrix.shape[1]))
embed_matrix = torch.from_numpy(
np.vstack((oov_embed, embed_matrix)))
self.embedding.weight.data.copy_(embed_matrix)
self.embedding.weight.requires_grad = False
self.spatial_dropout = SpatialDropout(drop_prob=0.5)
self.conv_region = nn.Conv2d(
1, self.num_filters, (3, self.embedding_dim))
self.conv = nn.Conv2d(self.num_filters, self.num_filters, (3, 1))
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1))
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1))
self.relu = nn.ReLU()
self.fc = nn.Linear(self.num_filters, self.num_classes)
def forward(self, x, label=None):
x = self.embedding(x)
x = self.spatial_dropout(x)
x = x.unsqueeze(1)
x = self.conv_region(x)
x = self.padding1(x)
x = self.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = self.relu(x)
x = self.conv(x)
while x.size()[2] > 2:
x = self._block(x)
x = x.squeeze(-1)
x = x.squeeze(-1)
out = self.fc(x)
if label is not None:
loss_fct = nn.BCEWithLogitsLoss()
loss = loss_fct(out.view(-1, self.num_classes).float(),
label.view(-1, self.num_classes).float())
return loss
else:
return out
def _block(self, x):
x = self.padding2(x)
px = self.max_pool(x)
x = self.padding1(px)
x = F.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = F.relu(x)
x = self.conv(x)
x = x + px
return x
2.2 HAN
class Attention(nn.Module):
def __init__(self, feature_dim, step_dim, bias=True, **kwargs):
super(Attention, self).__init__(**kwargs)
self.supports_masking = True
self.bias = bias
self.feature_dim = feature_dim
self.step_dim = step_dim
self.features_dim = 0
weight = nn.zeros(feature_dim, 1)
nn.init.xavier_uniform_(weight)
self.weight = nn.Parameter(weight)
if bias:
self.b = nn.Parameter(nn.zeros(step_dim))
def forward(self, x, mask=None):
feature_dim = self.feature_dim
step_dim = self.step_dim
eij = nn.mm(
x.contiguous().view(-1, feature_dim),
self.weight
).view(-1, step_dim)
if self.bias:
eij = eij + self.b
eij = nn.tanh(eij)
a = nn.exp(eij)
if mask is not None:
a = a * mask
a = a / nn.sum(a, 1, keepdim=True) + 1e-10
weighted_input = x * nn.unsqueeze(a, -1) # [16, 100, 256]
return nn.sum(weighted_input, 1)
#定义模型
class SelfAttention(nn.Module):
def __init__(self, input_size, hidden_size):
super(SelfAttention, self).__init__()
self.W = nn.Linear(input_size, hidden_size, True)
self.u = nn.Linear(hidden_size, 1)
def forward(self, x):
u = torch.tanh(self.W(x))
a = F.softmax(self.u(u), dim=1)
x = a.mul(x).sum(1)
return x
class HAN(nn.Module):
def __init__(self, args, vocab_size, embedding_dim, embeddings=None):
super(HAN, self).__init__()
self.num_classes = 35
hidden_size_gru = 256
hidden_size_att = 512
hidden_size = 128
self.num_words = args.MAX_LEN
self.embedding = nn.Embedding(vocab_size, embedding_dim)
if embeddings:
w2v_model = gensim.models.word2vec.Word2Vec.load(
"./embedding/w2v.model").wv
fasttext_model = gensim.models.word2vec.Word2Vec.load(
"./embedding/fasttext.model").wv
w2v_embed_matrix = w2v_model.vectors
fasttext_embed_matrix = fasttext_model.vectors
# embed_matrix = w2v_embed_matrix
embed_matrix = np.concatenate(
[w2v_embed_matrix, fasttext_embed_matrix], axis=1)
oov_embed = np.zeros((1, embed_matrix.shape[1]))
embed_matrix = torch.from_numpy(
np.vstack((oov_embed, embed_matrix)))
self.embedding.weight.data.copy_(embed_matrix)
self.embedding.weight.requires_grad = False
self.gru1 = nn.GRU(embedding_dim, hidden_size_gru,
bidirectional=True, batch_first=True)
self.att1 = SelfAttention(hidden_size_gru * 2, hidden_size_att)
self.gru2 = nn.GRU(hidden_size_att, hidden_size_gru,
bidirectional=True, batch_first=True)
self.att2 = SelfAttention(hidden_size_gru * 2, hidden_size_att)
self.tdfc = nn.Linear(embedding_dim, embedding_dim)
self.tdbn = nn.BatchNorm2d(1)
self.fc = nn.Sequential(
nn.Linear(hidden_size_att, hidden_size),
nn.BatchNorm1d(hidden_size),
nn.ReLU(inplace=True),
nn.Linear(hidden_size, self.num_classes)
)
self.dropout = nn.Dropout(0.5)
# self._init_parameters()
def forward(self, x, label=None):
# 64 512 200
x = x.view(x.size(0) * self.num_words, -1).contiguous()
x = self.dropout(self.embedding(x))
x = self.tdfc(x).unsqueeze(1)
x = self.tdbn(x).squeeze(1)
x, _ = self.gru1(x)
x = self.att1(x)
x = x.view(x.size(0) // self.num_words,
self.num_words, -1).contiguous()
x, _ = self.gru2(x)
x = self.att2(x)
out = self.dropout(self.fc(x))
if label is not None:
loss_fct = nn.BCEWithLogitsLoss()
loss = loss_fct(out.view(-1, self.num_classes).float(),
label.view(-1, self.num_classes).float())
return loss
else:
return out
2.3 TextRCNN
class TextRCNN(nn.Module):
def __init__(self, args, vocab_size, embedding_dim, embeddings=None):
super(TextRCNN, self).__init__()
self.hidden_size = 128
self.num_layers = 2
self.dropout = 0.4
self.learning_rate = 5e-4
self.freeze = True # 训练过程中是否冻结对词向量的更新
self.seq_len = 100
self.num_classes = 35
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
# 字向量维度
self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim)
if embeddings:
w2v_model = gensim.models.word2vec.Word2Vec.load(
"./embedding/w2v.model").wv
fasttext_model = gensim.models.word2vec.Word2Vec.load(
"./embedding/fasttext.model"
).wv
w2v_embed_matrix = w2v_model.vectors
fasttext_embed_matrix = fasttext_model.vectors
# embed_matrix = w2v_embed_matrix
embed_matrix = np.concatenate(
[w2v_embed_matrix, fasttext_embed_matrix], axis=1
)
oov_embed = np.zeros((1, embed_matrix.shape[1]))
embed_matrix = torch.from_numpy(
np.vstack((oov_embed, embed_matrix)))
self.embedding.weight.data.copy_(embed_matrix)
self.embedding.weight.requires_grad = False
self.spatial_dropout = SpatialDropout(drop_prob=0.3)
self.lstm = nn.GRU(
input_size=self.embedding_dim, hidden_size=self.hidden_size,
num_layers=self.num_layers, bidirectional=True,
batch_first=True, dropout=self.dropout
)
self.maxpool = nn.MaxPool1d(self.seq_len)
self.fc = nn.Linear(self.hidden_size * 2 + self.embedding_dim, 35)
# self._init_parameters()
def forward(self, x, label=None):
embed = self.embedding(x)
spatial_embed = self.spatial_dropout(embed)
out, _ = self.lstm(spatial_embed)
out = torch.cat((embed, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out).squeeze(-1)
out = self.fc(out)
if label is not None:
loss_fct = nn.BCEWithLogitsLoss()
loss = loss_fct(out.view(-1, self.num_classes).float(),
label.view(-1, self.num_classes).float())
return loss
else:
return out
2.4 CapsuleNet
class CapsuleNet(nn.Module):
def __init__(self, args, vocab_size, embedding_dim, embeddings=None, num_capsule=5, dim_capsule=5,):
super(CapsuleNet, self).__init__()
self.num_classes = 35
fc_layer = 256
hidden_size = 128
self.embedding = nn.Embedding(vocab_size, embedding_dim)
if embeddings:
w2v_model = gensim.models.word2vec.Word2Vec.load(
"./embedding/w2v.model").wv
fasttext_model = gensim.models.word2vec.Word2Vec.load(
"./embedding/fasttext.model").wv
w2v_embed_matrix = w2v_model.vectors
fasttext_embed_matrix = fasttext_model.vectors
# embed_matrix = w2v_embed_matrix
embed_matrix = np.concatenate(
[w2v_embed_matrix, fasttext_embed_matrix], axis=1)
oov_embed = np.zeros((1, embed_matrix.shape[1]))
embed_matrix = nn.from_numpy(
np.vstack((oov_embed, embed_matrix)))
self.embedding.weight.data.copy_(embed_matrix)
self以上是关于2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别2 DPCNNHANRCNN等传统深度学习方案的主要内容,如果未能解决你的问题,请参考以下文章
2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别1 初赛Rank12的总结与分析
2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别1 初赛Rank12的总结与分析
2021 第五届“达观杯” 基于大规模预训练模型的风险事件标签识别2 DPCNNHANRCNN等传统深度学习方案