33张图解flink sql应用提交(建议收藏!)
Posted 在IT中穿梭旅行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了33张图解flink sql应用提交(建议收藏!)相关的知识,希望对你有一定的参考价值。
前言
大家好,我是土哥。
这已经是我为读者写的第21篇 Flink系列文章了。
上周有粉丝在群里问,在流计算平台编写完Flink sql后,为什么通过一键提交按钮,就可以将sql提交到yarn集群上面了?
由于现在各大厂对业务分层特别清晰,平台方向和底层技术开发会被单独划分,所以好多大数据同学编写完 Flink Sql 后,只需通过提交按钮将其提交到集群上,对背后的提交原理些许不太清楚。
下面土哥将为大家揭开这层神秘的面纱,挖掘 Flink Sql 背后的提交原理和源码设计。(硬核文章,建议收藏!)
熟悉平台
故事
小笨猪阿土刚入职某大数据公司担任实习生,然后主管交给阿土一个任务,让其熟悉公司的 Flink 流计算平台。

阿土登录流计算平台后,看到平台上面可以编写 Sql 语法,于是就写了一个简单的 sql
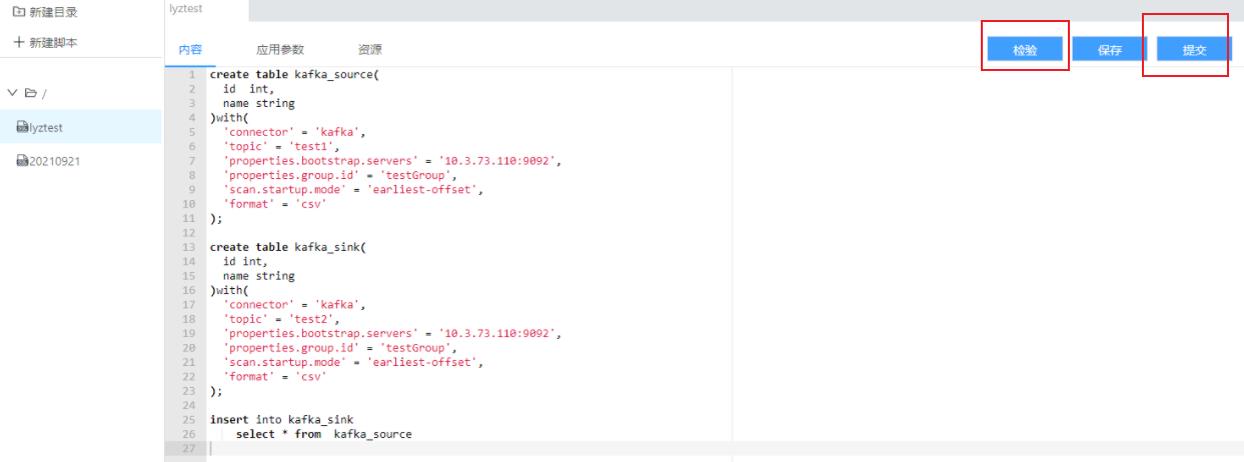
他发现旁边有个效验功能、于是就点击了一下,这时平台弹出 SQL 语法效验正确。阿土心中暗暗自喜,看来我的 sql 功底还是不错嘛。
SQL 语法效验完成后,阿土点击提交按钮,流计算平台提示,SQl 语法效验正确,已成功提交集群。
Flink sql 代码居然提交到yarn集群上了???
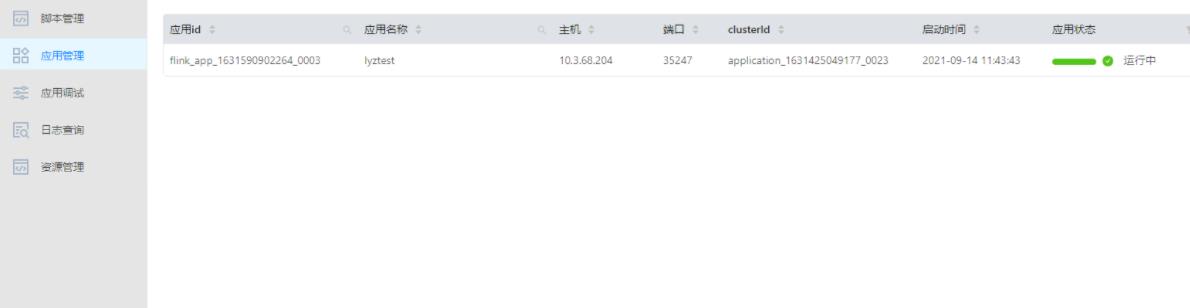
小笨猪阿土感到很惊讶,sql 就这样直接提交到集群了哇,这时候小笨猪的导师猴哥过来了,看到小笨猪的操作后,表扬了几句。

阿土,完成的不错啊,已经可以提交 sql 代码啦。但是你可别小看这简单的提交,这背后的门路可不浅呦。
这样吧,你好好探索一下这个sql提交的原理,然后写一篇分析报告,在咱们组分享一下。
啊......啊......
小笨猪阿土听到猴哥的要求后,一下就蔫了。从此之后,阿土就和 Flink sql 走在了一起。
刚开始阿土很懵,于是就开始搜查 Flink sql 相关文章,过了几天,终于理清了一些思路。 小笨猪将其流程总结为以下几个点:
-
Flink Sql解析器
-
Flink Planner 和 Blink Planner
-
Blink Sql提交流程

1.1、了解Calcite
为方便用户使用 Flink 流计算组件,Flink 社区设计了四种抽象,在这些抽象中,Sql API 属于Flink的最上层抽象,是 Flink 的一等公民,这就方便用户或者开发者直接通过 Sql 编写来提交任务。
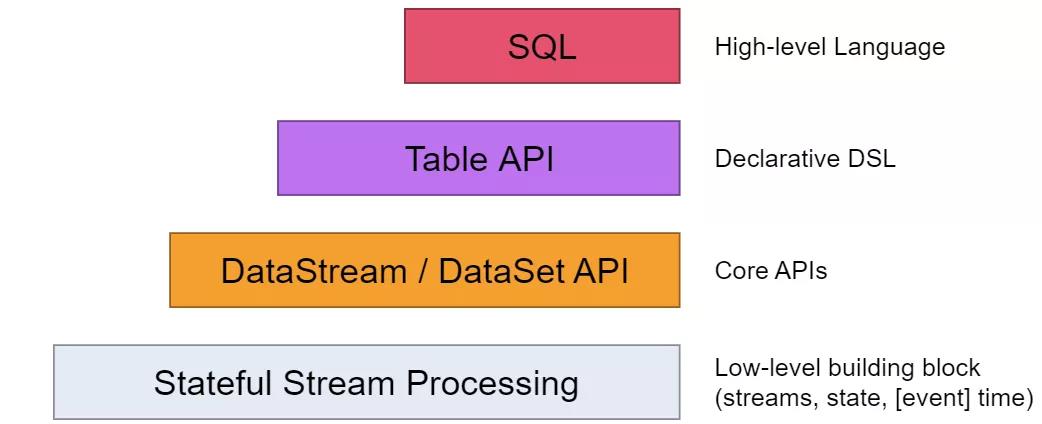
但经过阿土的调查后 发现,Flink sql 在提交任务时,并不是向 DataStream API 那样,直接被转为 StreamGraph,经过优化生成 JobGraph 提交到集群的,而是需要对编写的 Sql 进行解析、验证、优化等操作,在这中间,社区引入了一个强大的解析器,那就是Calcite。
阿土好好调研了一番Calcite
Calcite属于Apache旗下的一个动态数据管理框架,具备很多数据库管理系统的功能,它可以对SQL进行 SQL 解析,SQL 校验,SQL 查询优化,SQL 生成以及数据连接查询等操作,它不存储元数据和基本数据,不包含处理数据的算法。而是作为一个中介的角色,将上层SQL和底层处理引擎打通,将其SQL转为底层处理引擎需要的数据格式。
它不受上层编程语言的限制,前端可以使用 SQL、Pig、Cascading 等语言,只要通过 Calcite 提供的 SQL Api 将它们转化成关系代数的抽象语法树即可,并根据一定的规则和成本对抽象语法树进行优化,最后推给各个数据处理引擎来执行。
所以 Calcite 不涉及物理规划层,它通过扩展适配器来连接多种后端的数据源和数据处理引擎,如 Hive,Drill,Flink,Phoenix等。
1.2、Calcite执行步骤
小笨猪阿土简单画了一下Calcite的执行流程,主要涉及5个部分 SQL解析、SQL校验、SQL查询优化、SQL生成、执行等。
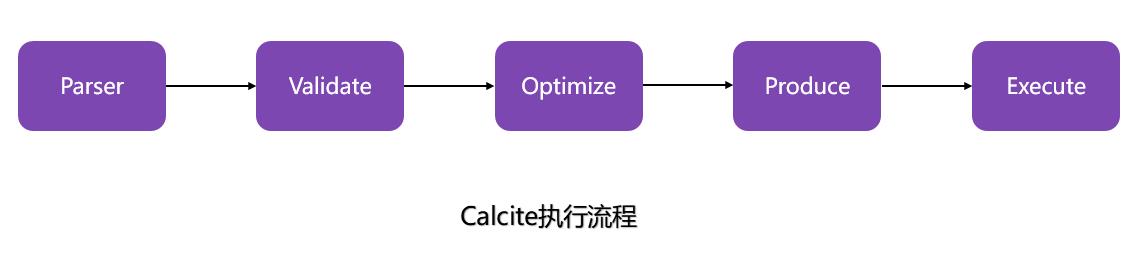
在这个流程中,Calcite各阶段扮演的角色如下:
-
SQL解析。通过
JavaCC实现,使用 JavaCC 编写 SQL 语法描述文件,将 SQL 解析成未经校验的AST 语法树。 -
SQL校验。通过与元数据结合
验证SQL 中的 Schema、Field、 Function 是否存在,输入输出类型是否匹配等。 -
SQL优化。
对上个步骤的输出( RelNode ,逻辑计划树)进行优化,使用两种规则:基于规则优化 和 基于代价优化,得到优化后的物理执行计划。 -
SQL生成。
将物理执行计划生成为在特定平台/引擎的可执行程序,如生成符合 mysql 或 Oracle 等不同平台规则的 SQL 查询语句等。 -
执行。执行是通过各个执行平台执行查询,得到输出结果。
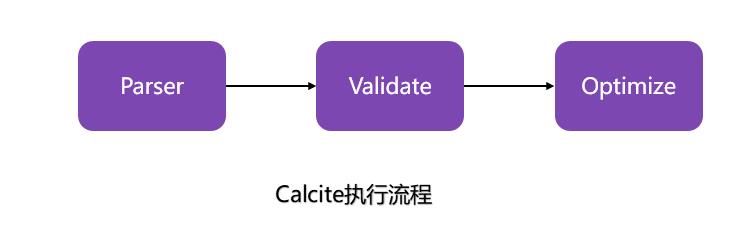
其中,Calcite再与其他处理引擎结合时,到SQL优化阶段就已经结束。所以流程图简化为:

阿土看完Calcite的原理后,开始想,那Calcite是怎么在Flink中扮演的角色呢?
这时猴哥过来给阿土说,单纯的看一些理论文章,是搞不清楚底层设计实现的,阿土啊,你可以看看源码。
听了猴哥的一番话后,阿土开始啃起了Flink1.13.2的Flink Sql源码
2.1 Flink Planner和Blink Planner
在1.9.0版本以前,社区使用Flink Planner作为查询处理器,通过与Calcite进行连接,为Table/SQL API提供完整的解析、优化和执行环境,使其SQL被转为DataStream API的 Transformation,然后再经过StreamJraph -> JobGraph -> ExecutionGraph等一系列流程,最终被提交到集群。
在1.9.0版本,社区引入阿里巴巴的Blink,对FIink TabIe & SQL模块做了重大的重构,保留了 Flink Planner 的同时,引入了 Blink PIanner,没引入以前,Flink 没考虑流批作业统一,针对流批作业,底层实现两套代码,引入后,基于流批一体理念,重新设计算子,以流为核心,流作业和批作业最终都会被转为transformation。
2.2 Blink Planner与Calcite关系
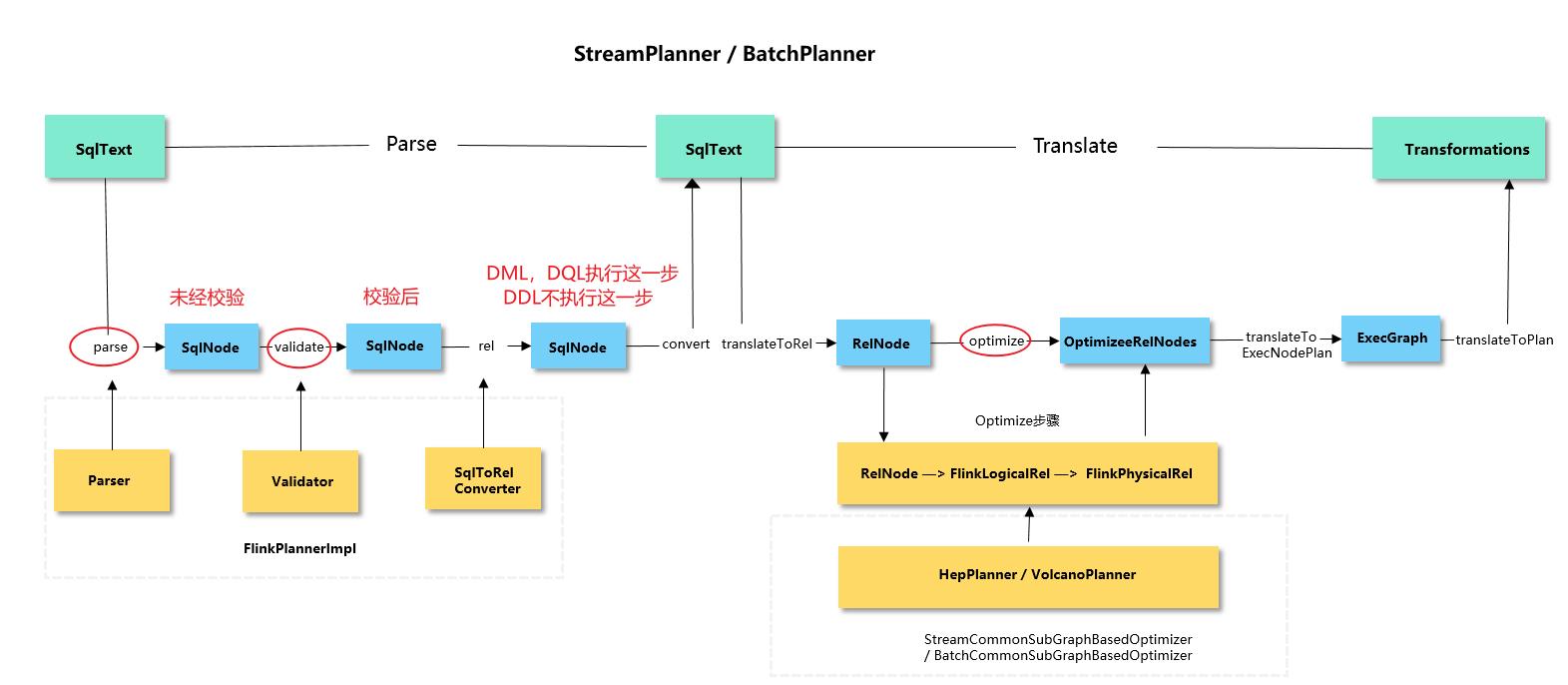
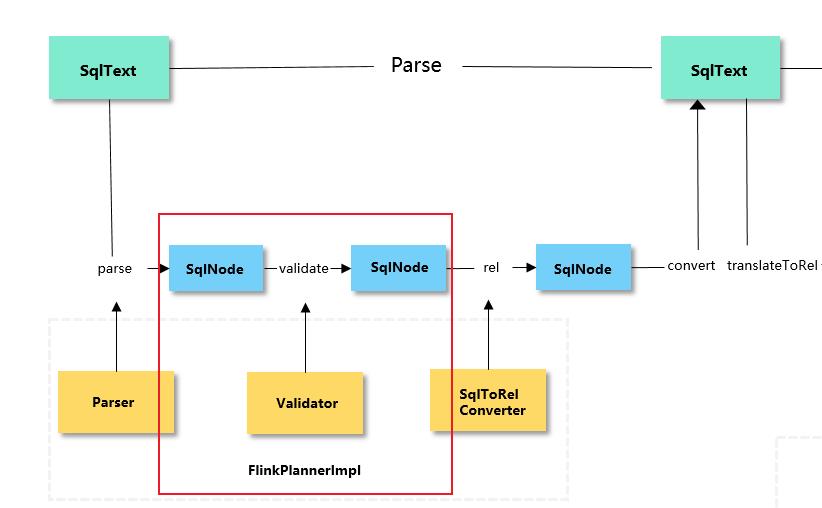
在之后的版本,为了实现Flink流批一体的愿景,通过Blink Planner与Calcite进行对接,对接流程如下:
-
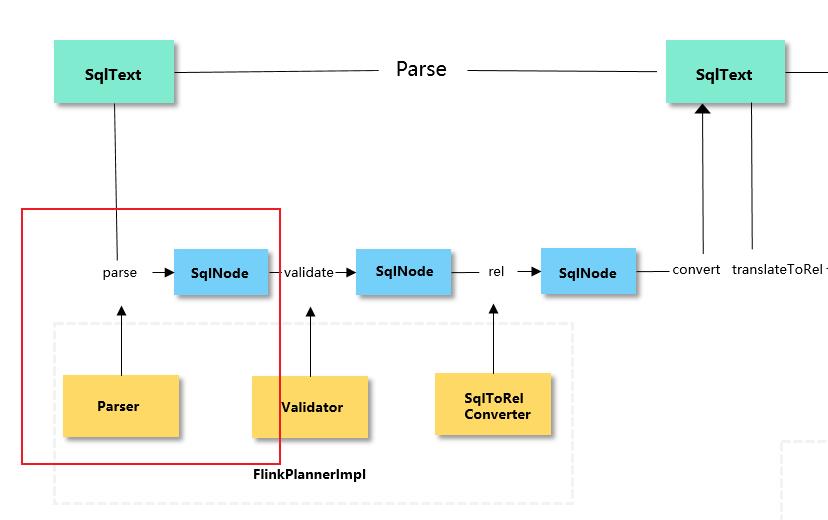
在Table/SQL 编写完成后,通过Calcite 中的parse、validate、rel阶段,以及Blink额外添加的convert阶段,将其先转为Operation;
-
通过Blink Planner 的
translateToRel、optimize、translateToExecNodeGraph和translateToPlan四个阶段,将Operation转换成DataStream API的 Transformation; -
再经过StreamJraph -> JobGraph -> ExecutionGraph等一系列流程,SQL最终被提交到集群。
小笨猪根据查询后的资料以及查看Flink 1.13.2版本源码后,画出如下SQL执行流程图。

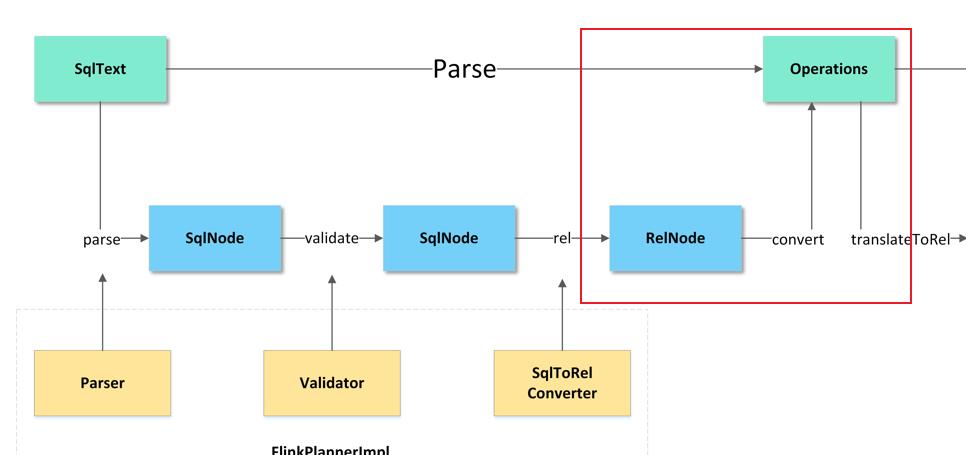
阿土根据对源码的分析后,发现无论是Flink SQL执行DDL操作、还是DQL操作或者DML操作、最终都可以将其总结为两个阶段:
-
SQL 语句到 Operation 过程,即Parse阶段;
-
Operation 到 Transformations 过程,即Translate阶段。
3.1、Parse阶段
在Parse阶段一共包含parse、validate、rel、convert部分

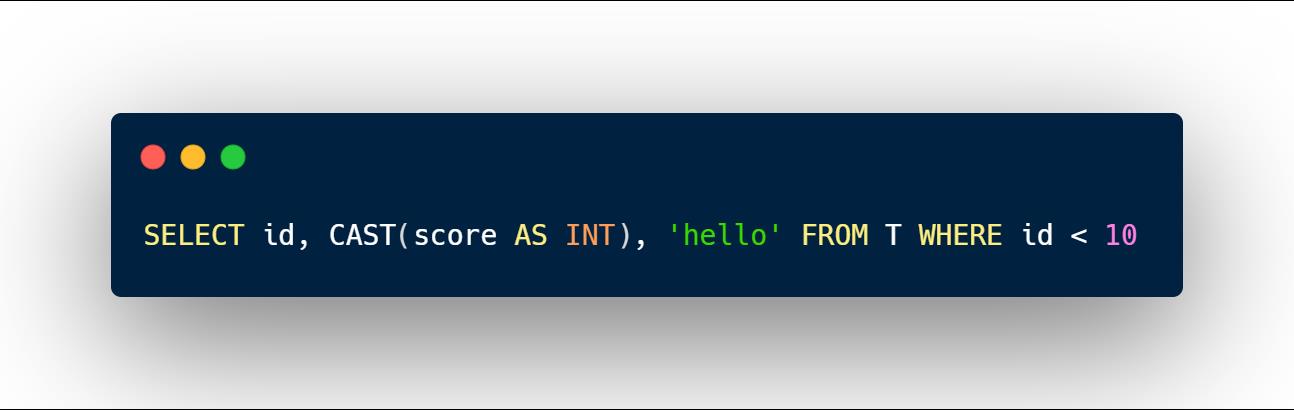
Calcite的 parse 解析模块是基于javacc实现的。javacc是一个词法分析生成器和语法分析生成器。词法分析器于将输入字符流解析成一个一个的token,以下面这段SQL语句为例:
示例1 :
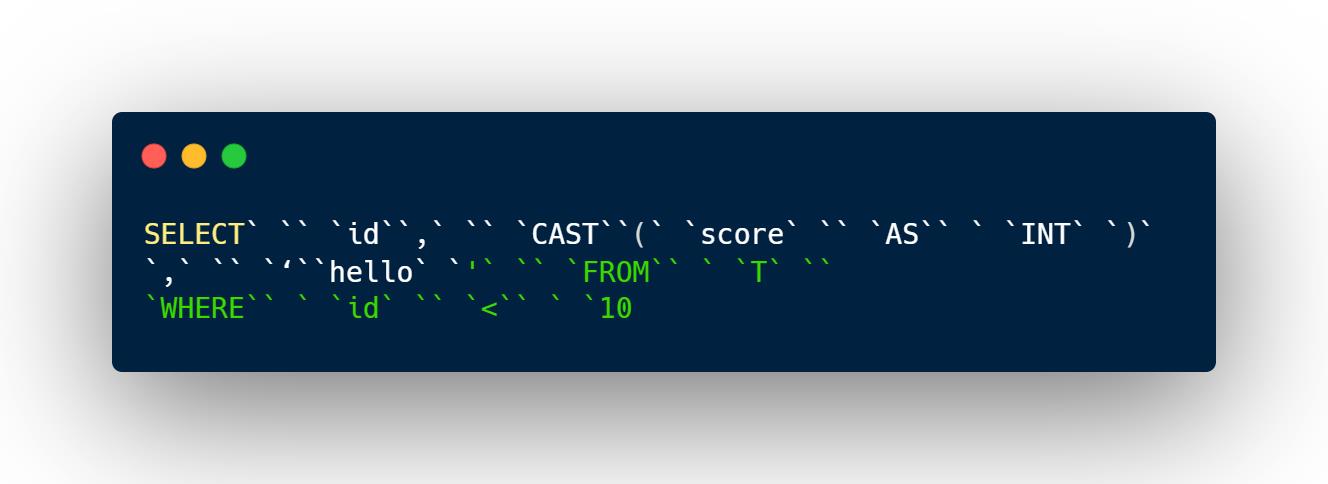
在 parse 部分,上面的SQL语句最后会被解析为如下一组token:
接下来语法分析器会以词法分析器解析出来的token序列作为输入来进行语法分析。分析过程使用递归下降语法解析,LL(k)。
其中,第一个L表示从左到右扫描输入;第二个L表示每次都进行最左推导(在推导语法树的过程中每次都替换句型中最左的非终结符为终结符。类似还有最右推导);
k表示的是每次向前探索(lookahead)k 个终结符。
分析所依赖的的词法法则定义在一个parser.jj文件中。
在经过词法分析和语法分析后,一段 SQL 语句会被解析成一颗抽象语法树(Abstract Syntax Tree,AST),树的节点类型在 Calcite 中以 SqlNode 来表示,不同节点以不同子类型的SqlNode来表示。
同样以上面的SQL为例,在这段SQL中:
-
id, score, T 等为 SqlIdentifier,表示一个字段名或表名的标识符;
-
select和cast()为
SqlCall,表示一个行为或动作,其中cast()为一个SqlBasicCall,表示一个函数调用,具体调用的是什么函数,由其内部的SqlOperator决定,比如这里是一个二元操作符“<”,对应SqlBinaryOperator,operator的名字是“<”,类别是SqlKind.LESS_THAN; -
int 为
SqlDataTypeSpec,表示一个类型定义; -
'hello'和 10 为
SqlLiteral,表示一个常量;
在Calcite中,所有的操作都是一个SqlCall, 如查询是一个 SqlSelect, 删除是一个 SqlDelete 等,它们都是 SqlCall 的子类型。select的查询条件等为 SqlCall 中的参数。示例1 的 SQL 语句最终生成的语法树形式如下:
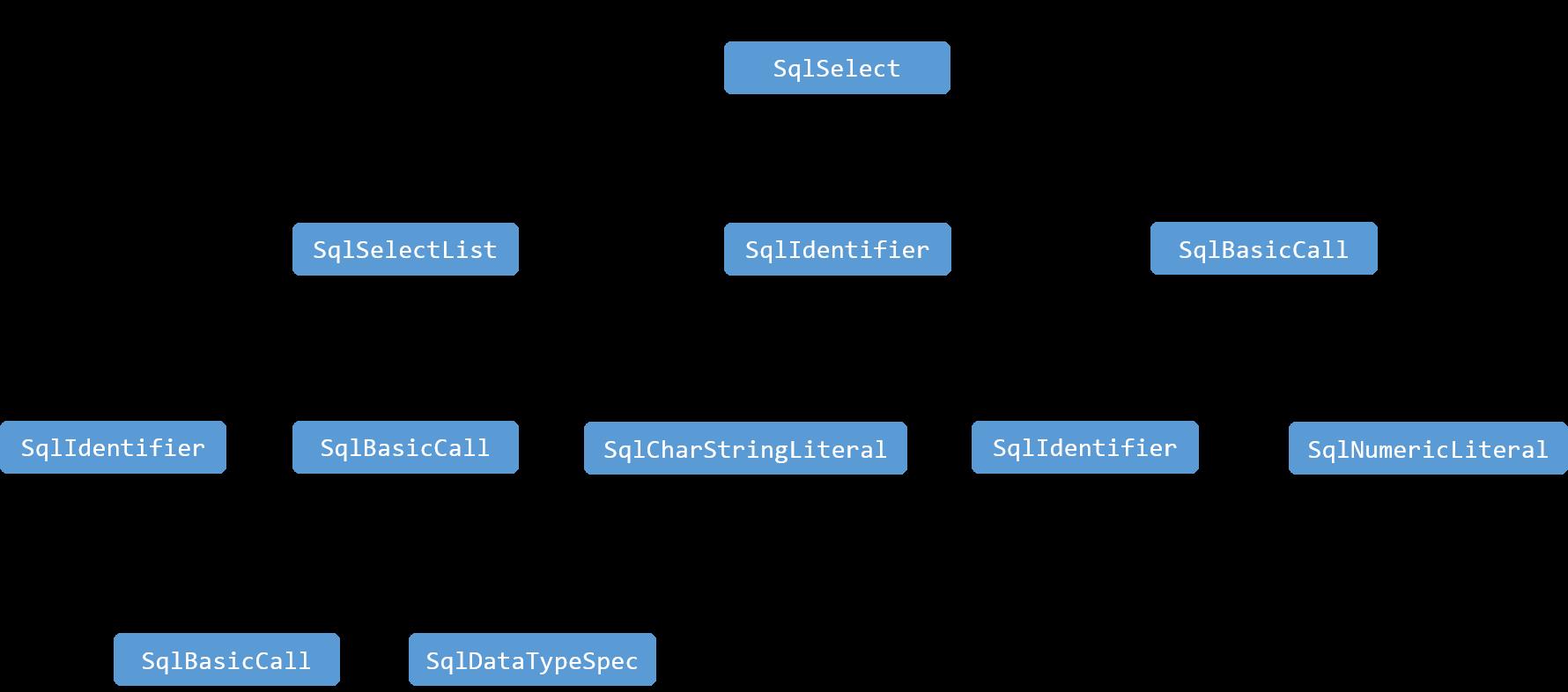
如果把示例1中的直接从一个表查询数据,改为从两张表的关联结果中查询数据,例如:
示例2:
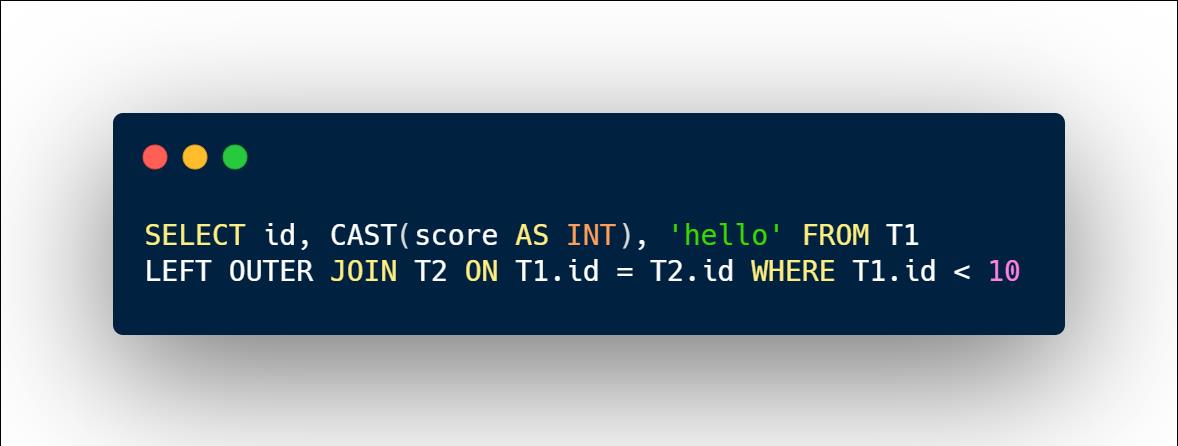
则相应的AST形式如下:
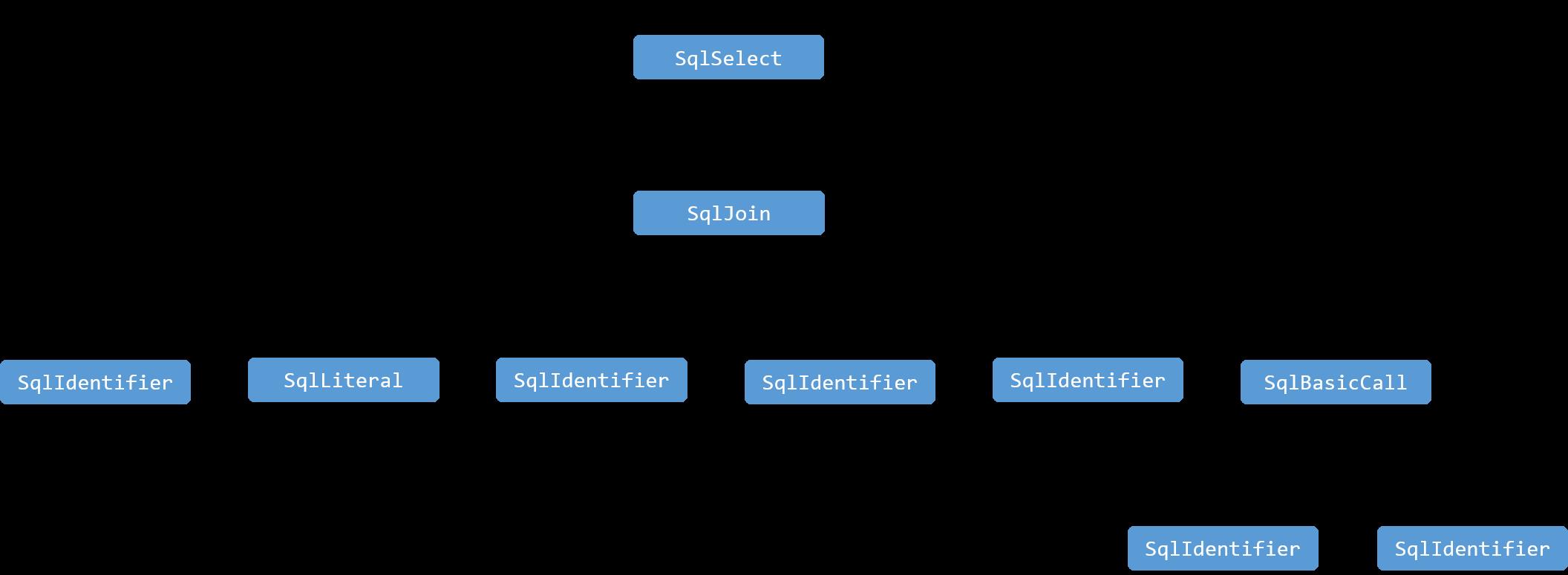
其中只有FROM子树部分由原来的SqlIdentifier节点变成了一棵SqlJoin子树,其他部分与示例1相同所以在图中省略了。

校验(validate)阶段
对经过parser解析出的AST进行有效性验证,验证的方面主要包括以下两方面:
-
表名、字段名、函数名是否正确,如在某个查询的字段在当前
SQL位置上是否存在或有歧义(当前可见的多个数据源中同时存在该名称的字段) -
特定类型操作自身的合法性,如
group by聚合中的聚合函数是否存在嵌套调用,使用AS重命名时,新名字是否是x.y的形式等
针对上面的第一种情况,在校验过程中首先需要明确两个最重要的概念:NameSpace和Scope。
NameSpace代表一个逻辑上的数据源,可以是一张表,也可以是一个子查询,而Scope则代表了在 SQL 的某个位置,表和字段的可见范围。
从概念中可以看出,在某个 SQL位置上,某个字段所对应的 scope 可能包含多个 namespace。在 validate 阶段解析出来的 scope 和 namespace 信息会被保存下来,在后面转换成逻辑执行计划的时候还会用到。
通过一个示例来看什么是 NameSpace 和 scope
示例3

在上面这样一段SQL语句中包含四个namespace:
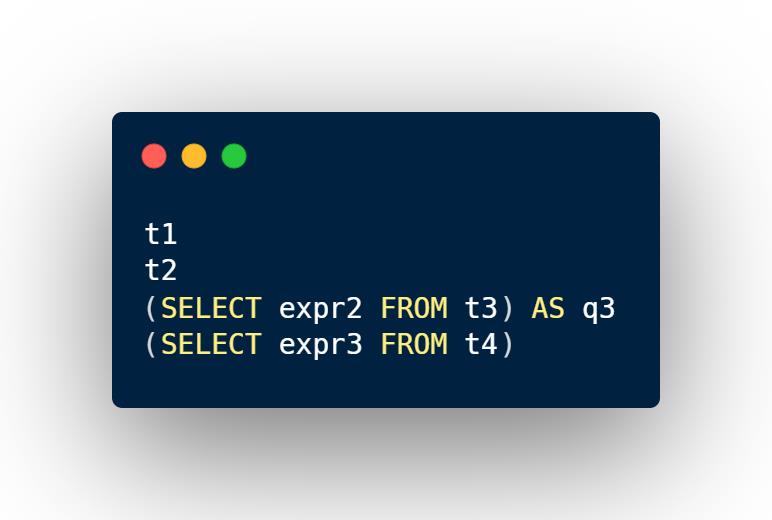
对于SQL中的不同表达式,根据它们所在的位置,它们所对应的scope如下:
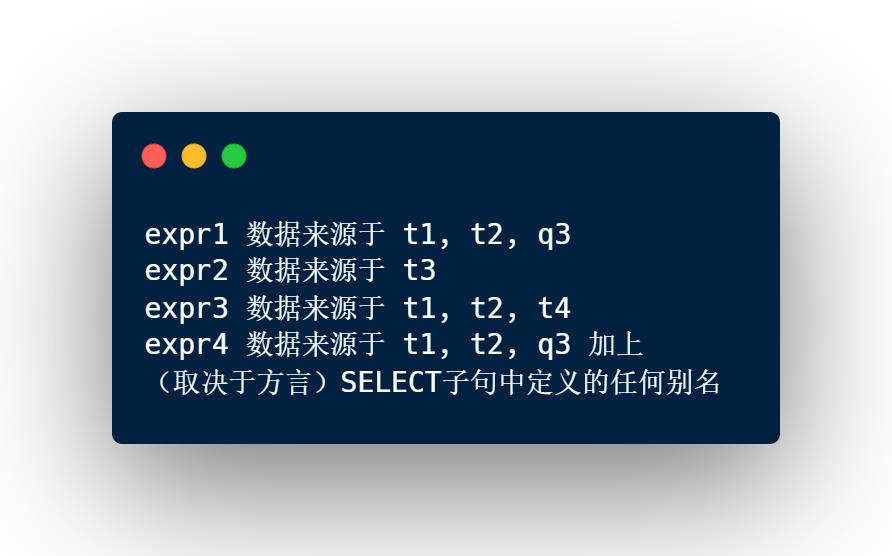
那么在校验第一种情况的时候,整个校验过程的核心就在于为不同的SqlNode节点生成其对应的namespace和scope,然后对该SqlNode涉及的字段和namespace与scope的对应关系进行校验。
对于第二种情况的校验,则需要根据具体的节点类型分别实现了。
在Calcite中,validator的具体实现类是SqlValidatorImpl,namespace和scope分别由接口SqlValidatorNamespace和SqlValidatorScope表示,图中涉及到的xxxNamespace和xxxScope分别是这两个类的子类。
下图是从调用validator.validate(sqlNode)开始,对一段查询语句的表名和字段名进行校验的时序图。
大体过程都已经在图中的注解里进行了说明,需要补充的一点是,在通过 emptyScope.resolve解析表名时,表信息是通过具体的catalogReader从catalog的schema中查找出来的。
具体使用什么catalog和catalogReader,是在validator创建之初决定的。
在flink中,根据用户的配置,catalog可能是 GenericInMemoryCatalog(基于内存的catalog)或HiveCatalog(基于hive metastore的catalog)。
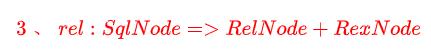
如下图所示:
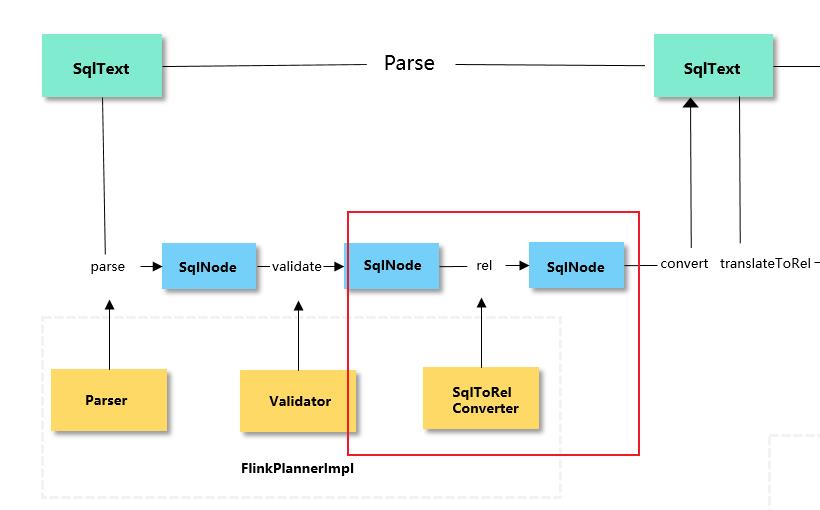
rel阶段是将SqlNode组成的一棵抽象语法树转化为一棵由RelNode和RexNode组成的关系代数树,或者称为执行计划。RelNode表示关系表达式,如投影(Project),即SELECT,和连接(JOIN)等;
RexNode表示行表达式,如示例中的 CAST(score AS INT)、T1.id < 10。
以示例2的语法树为例,在经过rel阶段转换后会生成下图所示的执行计划:
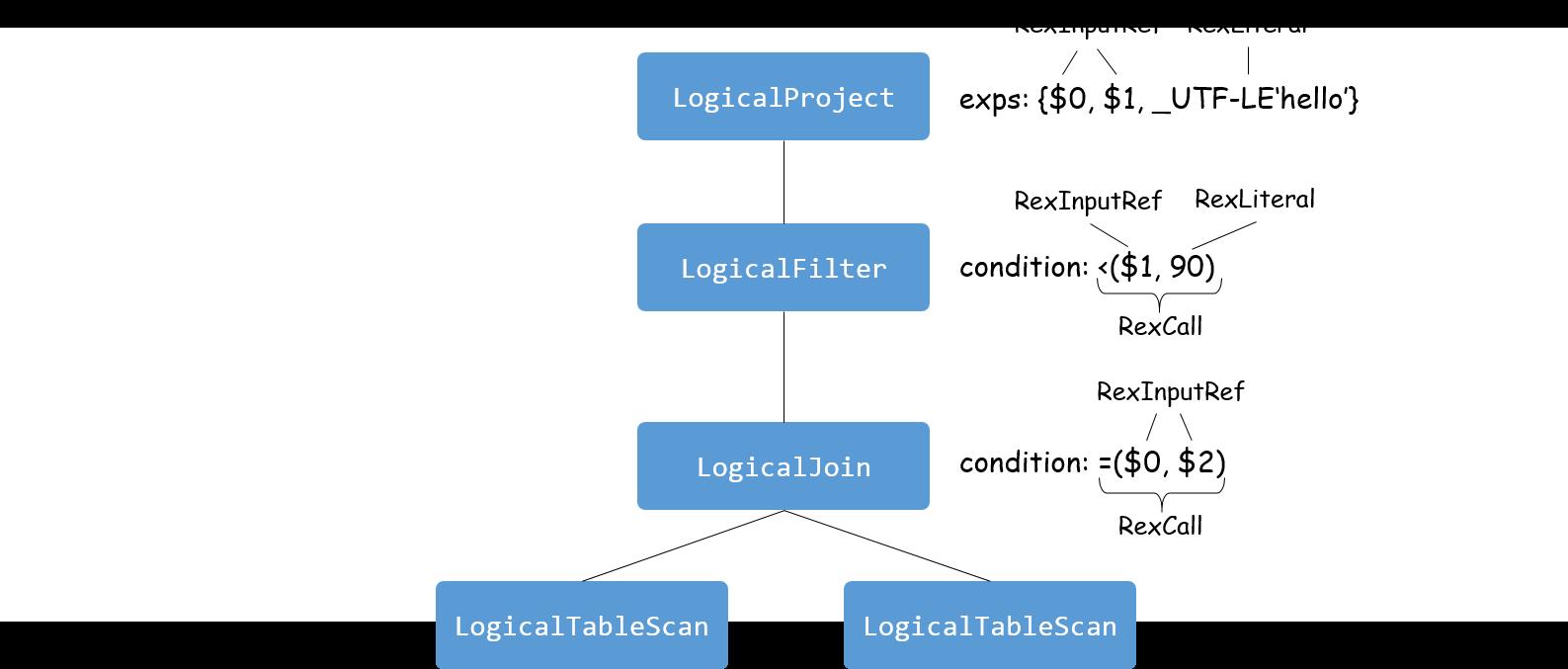
rel阶段只处理DML和DQL
因为DDL实际上可以认为是对元数据的修改,不涉及复杂关系查询,也就不用进行关系代数转换来优化执行, 所以也无需转换为表示,根据对应的SqlNode中保存的信息已经可以直接执行了。
在calcite中,SqlToRelConverter用于对关系表达式进行转换。Flink中通过如下方式使用calcite将AST转换成逻辑执行计划,如下图源码所示。
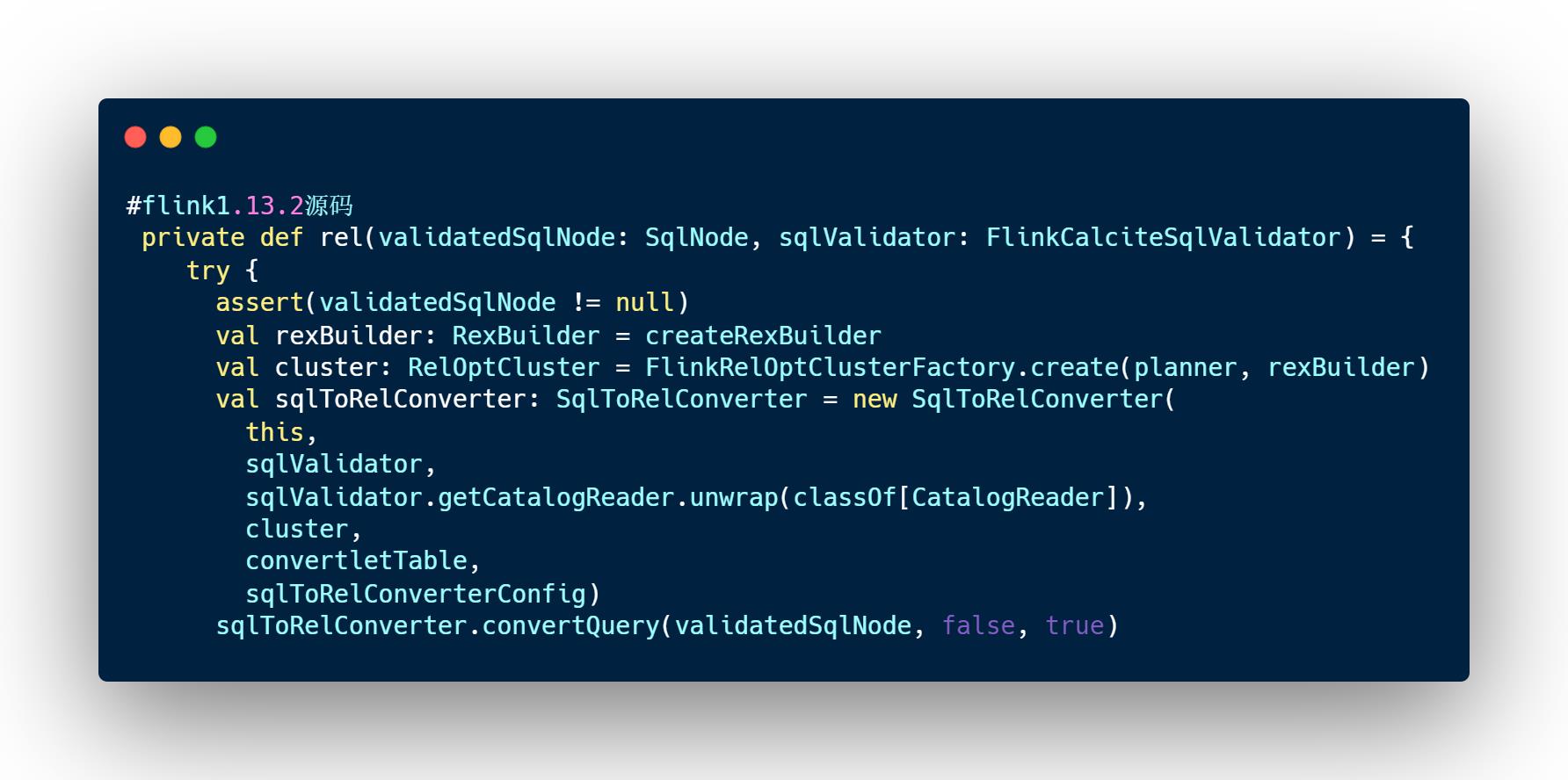
从Flink1.13.2源码中可以看到转换的入口是convertQuery方法。
SqlToRelConverter中的简单的转换流程如下图所示:
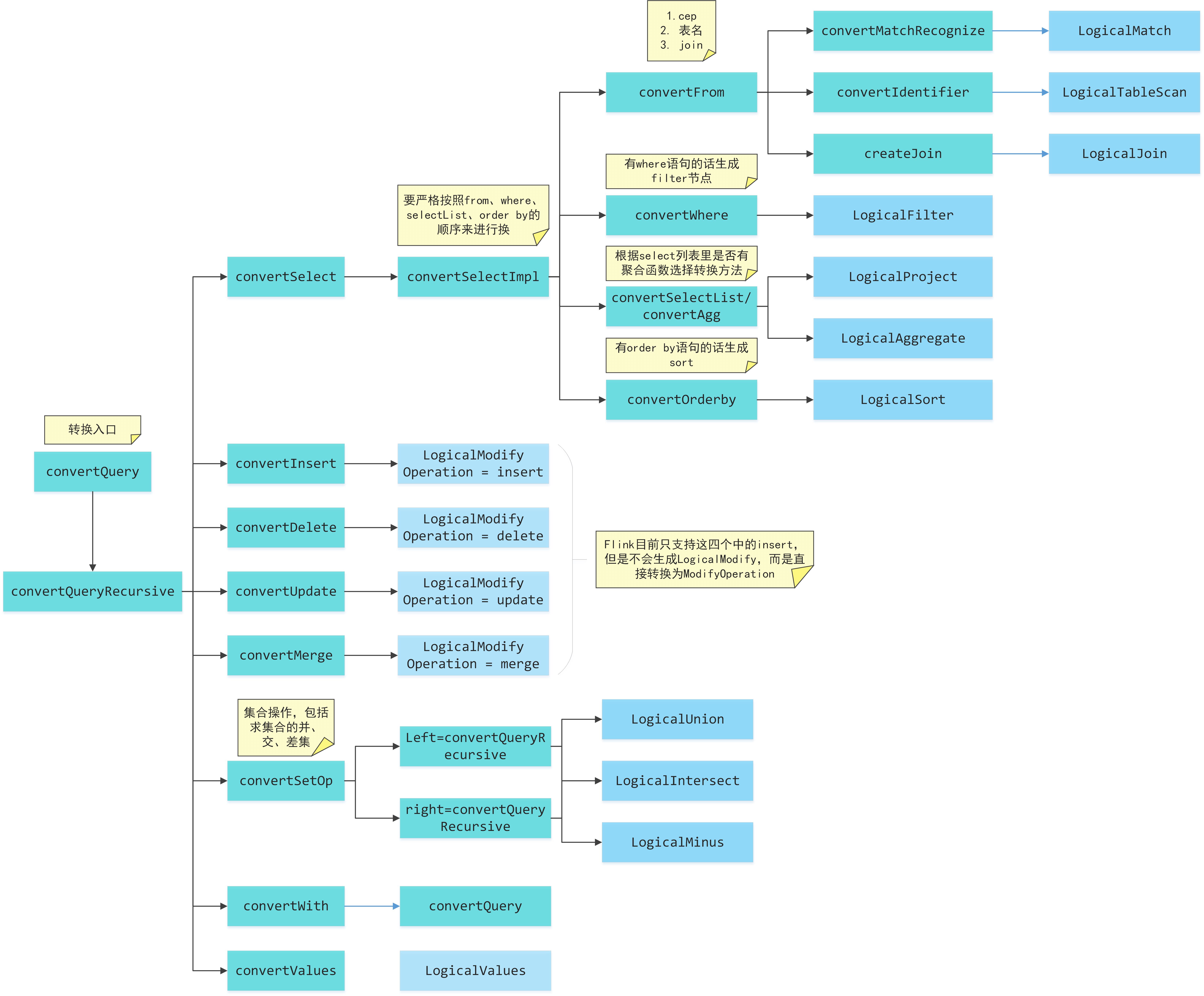
针对每种可能的根节点类型都有对应的转换方法。其中DELETE、UPDATE、MERGE、WITH和VALUES这几种语法在flink流式SQL中还不支持,并且其转换过程也比较简单,后文不再详细分析。
对于一棵转换后得到的逻辑执行计划树中的节点,其实在AST中都是可以一一对应的找到对应的节点的,所以转换过程本身并不涉及很复杂的算法,大部分过程是提取已有SqlNode节点中记录的信息,然后生成对应的RelNode和RexNode,并设置RelNode间的父子关系。
从图中也可以看出在calcite里最终都会生成一个LogicalModify节点,通过节点内的operation属性来标识不同的含义。但是目前flink支持的DML只有insert语句,而且并不会生成LogicalModify节点,而是直接转换成了ModifyOperation,并在需要的时候转换成flink内部自己定义的节点类型LogicalSink。也因为这个原因,对于DML的转换流程图中是略有简化的,insert、delete、update和merge本身都可以带查询语句,因此实际转换的时候都会递归地先对查询部分进行转换。
上图所示流程中只展示了对关系表达式的转换,但是每个关系节点(RelNode)中的行表达式同样需要经过转换得来。
Calcite中行表达式的转换依赖于两个对象:BlackBoard和SqlNodeToRexConverter。
BlackBoard是对select进行转换时的一个临时工作空间,它就像一块“黑板”一样,可以临时记录下转换过程中需要的信息,比如select依赖的scope、当前的root节点、当前节点是否是top节点等。
BlackBoard本身还是一个shuttle,针对不同类型的SqlNode,其内部都有对应的visit方法。其中除SqlCall、SqlLiteral、SqlIntervalQualifier外,都可由BlackBoard和SqlToRelConverter中定义的各种convertXXX方法进行转换,这三种类型的SqlNode则需要借助SqlNodeToRexConverter来进行转换。
SqlLiteral、SqlIntervalQualifier的转换比较简单,就是从原来的SqlNode中提取信息进行简单的处理和转换,然后生成对应的RexNode。

重点:这一步负责将RelNode tree转换成operation
这里只有以及的查询子句会首先通过转换为
RelNode转换成Operation的过程很简单,针对四种类型的操作,其各自的转换过程如下:·
-
CreateTable @convertCreateTable
如果AST的根节点是SqlCreateTable,提取节点中记录的
schema、properties、comment、primarykeys、if not exists信息,创建CatalogTable对象,然后创建CreateTableOperation -
DropTable @convertDropTable
如果AST的根节点是SqlDropTable,提取节点中记录的
full table name、if exists信息,创建DropTableOperation对象 -
Insert @convertInsert
如果AST的根节点是RichSqlInsert,提取节点中记录的目标表的完整路径和查询表达式,先将查询表达式通过
convertSqlQuery转换成QueryOperation,然后以转换后的QueryOperation为子节点创建ModifyOperation对象。
这里分两种情况:
(1)使用SQL API执行了 insert into 语句,将数据写入已经通过 TableEnvironment注册过的表中,此时创建的是CatalogSinkModifyOperation
(2)使用Table API的toXXXStream将table对象转换成了DataStream,创建的是OutputConversionModifyOperation
-
Query @convertSqlQuery
如果根节点的SqlKind是SqlKind.Query,先通过FlinkPlannerImpl.rel将SqlNode转换成RelNode,然后创建PlannerQueryOperation对象
3.2、Translate阶段
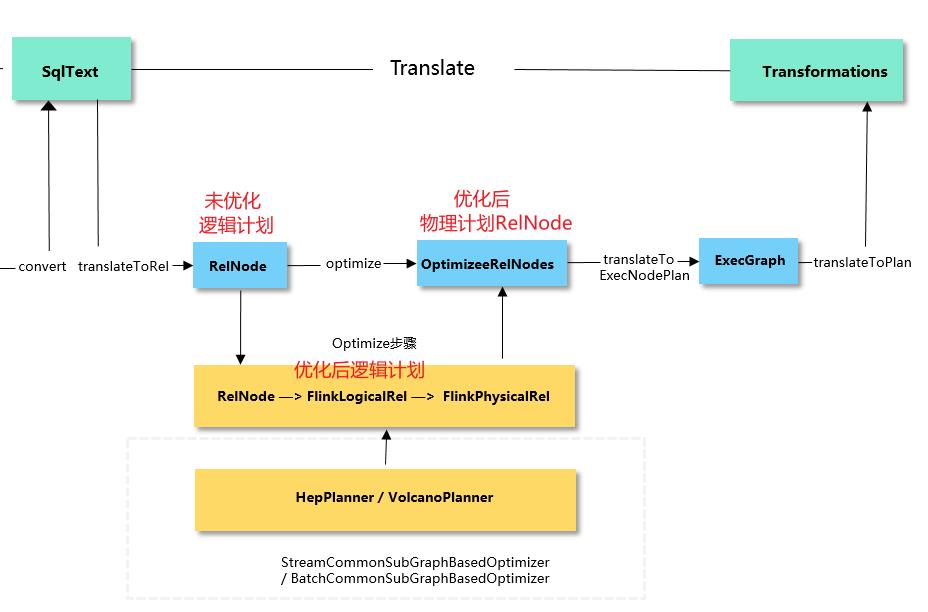
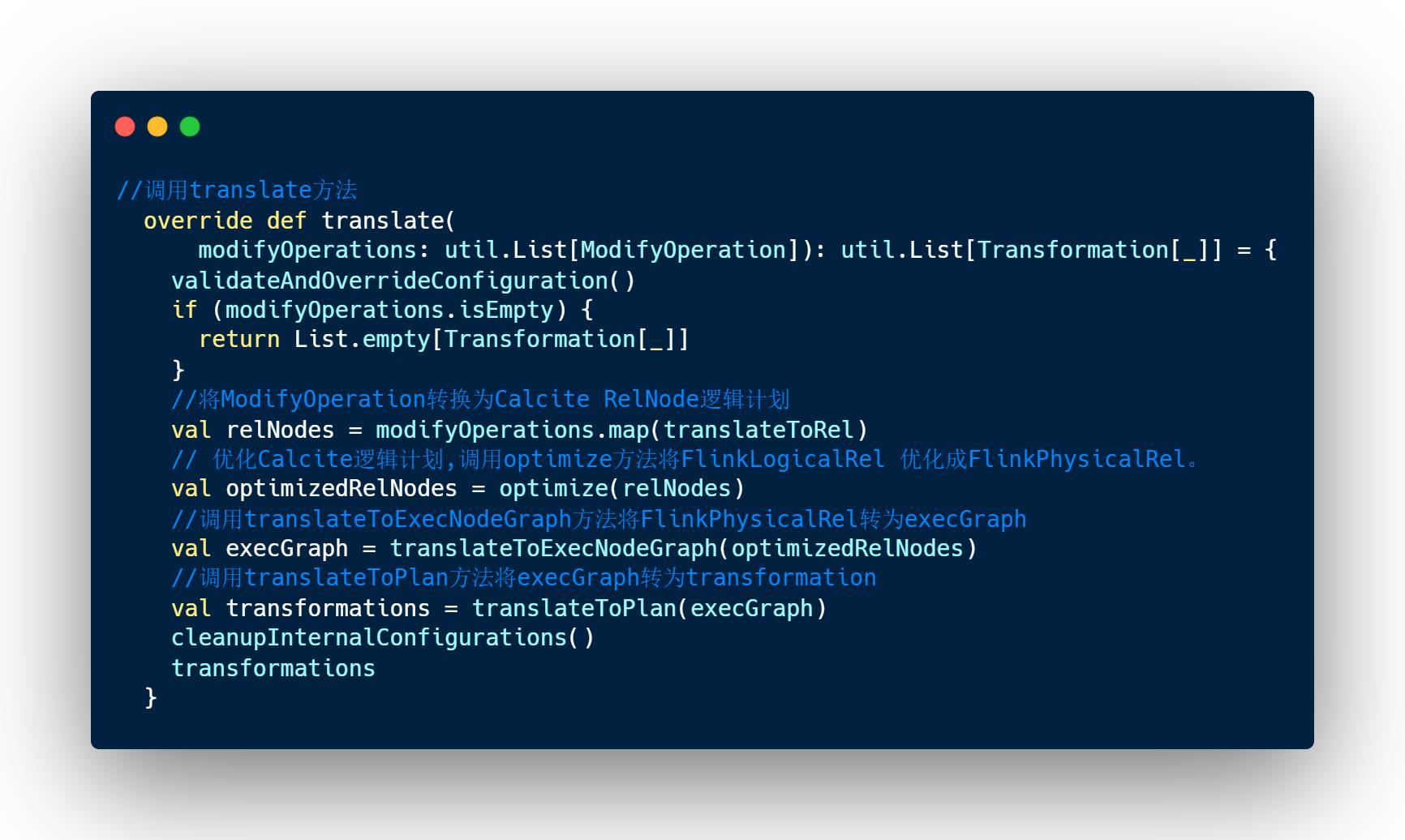
在Translate阶段,通过Blink Planner 的translateToRel、optimize、translateToExecNodeGraph和translateToPlan四个阶段:将Operation转换成 Transformations。
重点:
-
从operation开始,先将ModifyOperation通过translateToRel方法转换成Calcite RelNode逻辑计划树,在对应转换成FlinkLogicalRel(RelNode逻辑计划树);
-
然后经过 调用optimize方法将FlinkLogicalRel 优化成FlinkPhysicalRel。
-
再调用translateToExecNodeGraph方法将FlinkPhysicalRel转为execGraph
-
最后调用translateToPlan方法将execGraph转为transformations
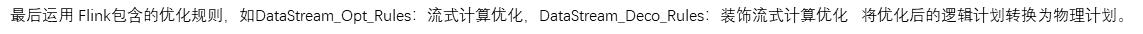
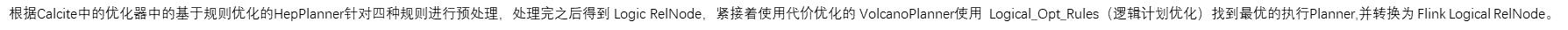
从逻辑计划变成物理计划(RelNode),
Flink1.13.2源码如下:
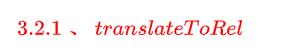
这个过程可以看成是convert: RelNode => Operation的逆过程。
逻辑也很简单,无论是使用SQL API还是Table API,最终生成的operation的根节点一定是ModifyOperation,因为只有insert语句或者将Table转换成DataStream后,在DataStream结果上面写入sink才能触发执行。
前文提到过ModifyOperation最终都会被转换成flink内自定义的LogicalSink节点,该节点主要记录数据输出信息,核心在于需要创建出表示数据输出的sink。所以针对三种ModifyOperation类型分别创建sink的过程如下:
-
UnregisteredSinkModifyOperation:这个operation中直接记录了sink信息,因此直接提取出来创建LogicalSink即可。 -
CatalogSinkModifyOperation:根据operation中记录的table path找到对应的table,然后根据table创建出table sink,最后使用table sink创建出LogicalSink节点。这个过程中涉及到了在catalog中解析table和使用ServiceLoader根据table信息在classpath中查找并用于创建table sink的TableSinkFactory的过程,具体如下图所示。

会使用两个优化器:RBO(基于规则的优化器) 和 CBO(基于代价的优化器)
-
RBO(基于规则的优化器)会将原有表达式裁剪掉,遍历一系列规则(Rule),只要满足条件就转换,生成最终的执行计划。一些常见的规则包括分区裁剪(Partition Prune)、列裁剪、谓词下推(Predicate Pushdown)、投影下推(Projection Pushdown)、聚合下推、limit下推、sort下推、常量折叠(Constant Folding)、子查询内联转join等。
2.CBO(基于代价的优化器)会将原有表达式保留,基于统计信息和代价模型,尝试探索生成等价关系表达式,最终取代价最小的执行计划。CBO的实现有两种模型,Volcano模型,Cascades模型。这两种模型思想很是相似,不同点在于Cascades模型一边遍历SQL逻辑树,一边优化,从而进一步裁剪掉一些执行计划。
源码如下:
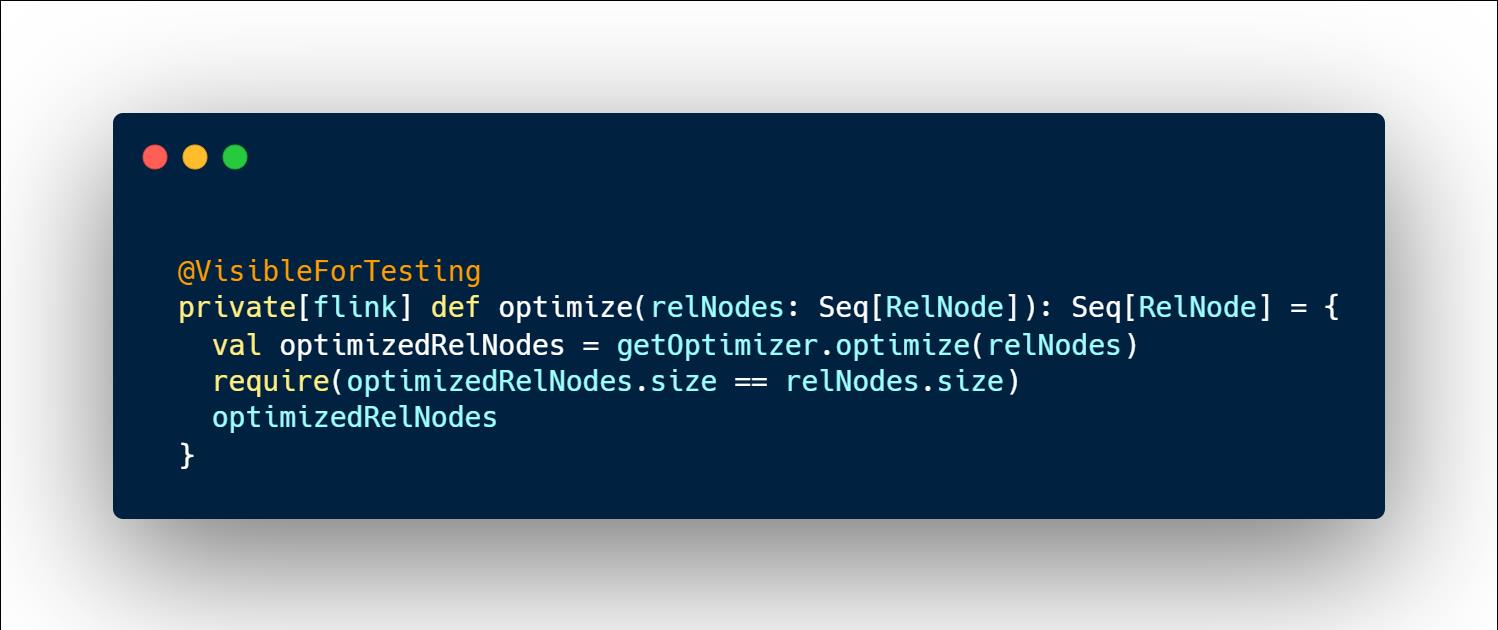

调用translateToExecNodeGraph方法将FlinkPhysicalRel转为execGraph
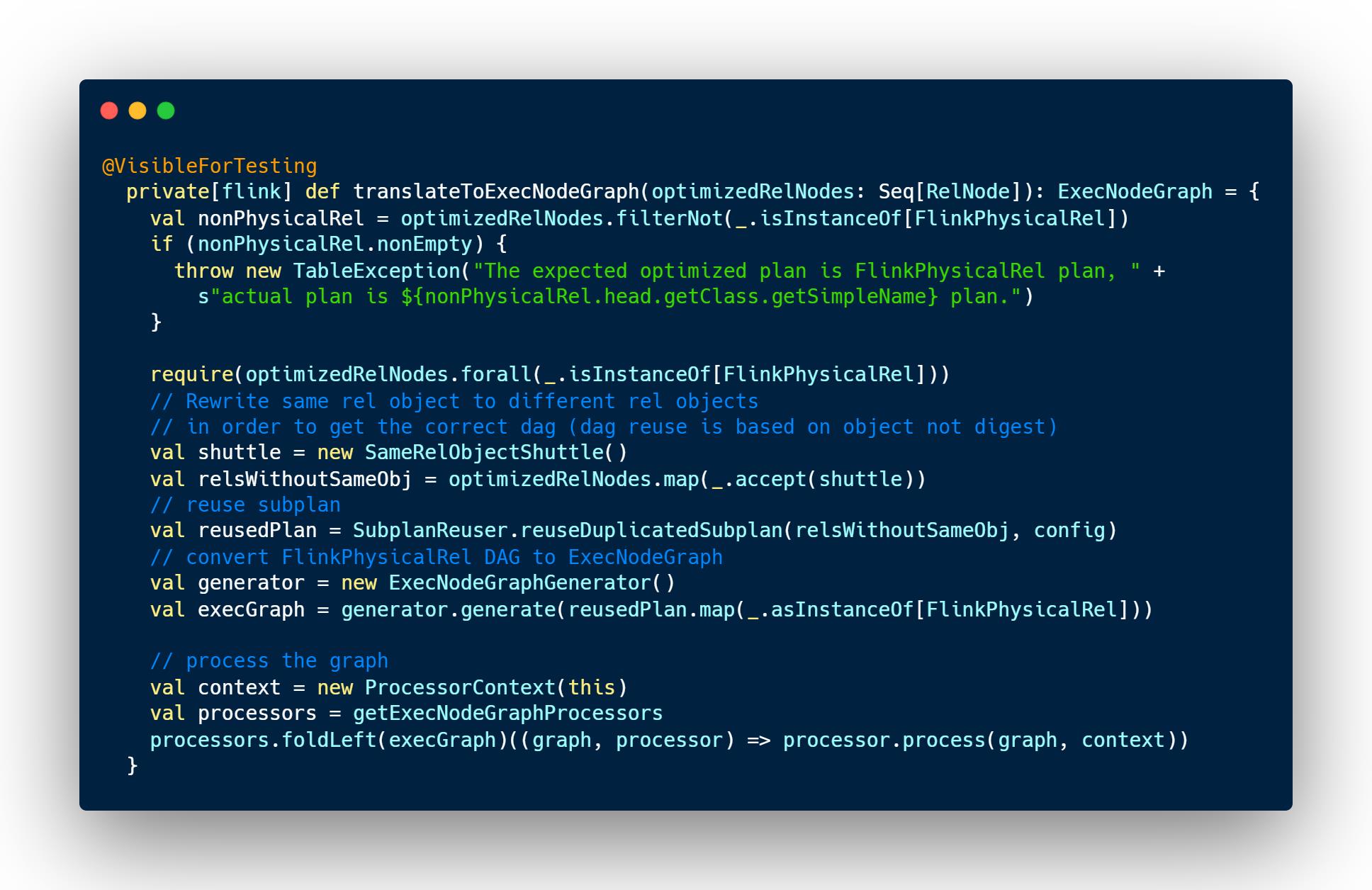

调用translateToPlan方法将execGraph转为transformations
通过上述四个步骤,实现将Operation转换成 Transformations。
小笨猪通过完整的流程分析后,终于搞懂了Flink sql的解析和转换过程,最终SQL被转为Transformations,后面的步骤就变成了Flink DataStream的提交流程,小笨猪还是比较了解的。
分享
时间一眨眼就到了分享的那天,小笨猪在讲台上对Flink sql应用提交做了深入讲解,得到了导师猴哥和主管的一致认可。


以上是关于33张图解flink sql应用提交(建议收藏!)的主要内容,如果未能解决你的问题,请参考以下文章
33张Java高级进阶技术思维导图,白嫖大佬梳理的技术要点!只需看重点,学习效率提升300%(建议收藏)
33张Java高级进阶技术思维导图,白嫖大佬梳理的技术要点!只需看重点,学习效率提升300%(建议收藏)