❤️Java高级ShardingSphere分库分表保姆式教程❤️,升职加薪就靠你了(建议收藏)
Posted 哪 吒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️Java高级ShardingSphere分库分表保姆式教程❤️,升职加薪就靠你了(建议收藏)相关的知识,希望对你有一定的参考价值。
🍅 Java学习路线:搬砖工逆袭Java架构师
🍅 简介:Java领域优质创作者🏆、CSDN哪吒公众号作者✌ 、Java架构师奋斗者💪
🍅 扫描主页左侧二维码,加入群聊,一起学习、一起进步
🍅 欢迎点赞 👍 收藏 ⭐留言 📝
目录
4、跨节点的count、order by、group by以及聚合函数问题
五、分库分表第三方解决方案 -- Apache ShardingSphere
六、Apache ShardingSphere的三个核心概念
一、分库分表
1、随着时间和业务发展,数据库数据量不可控,造成表中数据越来越多,此时再进行CRUD操作的话,会造成很大的性能问题,比如查询实时数据,表数据达到了千万级别,要求一分钟查询一次,但你一个select就要耗时2两分钟才能执行完,这岂不是很尴尬。
2、分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
3、性能解决方案
方案1
通过提升服务器硬件能力来提高数据处理能力,比如增加存储容量 、CPU等,这种方案成本很高,并且如果瓶颈在mysql本身那么提高硬件也是有很的。
方案2
把数据分散到不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
二、分库分表的方式
垂直分表、垂直分库、水平分表、水平分库。
1、垂直分表
(1)基本概念
将一个表按照字段分成多个表,每个表存储其中一部分字段。
(2)性能提升
- 为了避免IO争抢并减少锁表的几率;
- 充分发挥热门数据的操作效率,热门字段和冷门字段分开存储,比如一个产品基本信息表、一个产品详细信息表,大字段一定要放在冷门字段的表中。
(3)为什么大字段IO效率低?
- 数据本身长度过长,需要更长的读取时间;
- 跨页,页是数据库存储基本单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页存储数据少,因此IO效率低;
- 数据以行为单位将数据加载到内存中,如果字段长度短,内存就可以加载更多的数据,减少磁盘IO,从而提高数据库性能;
2、垂直分库
(1)基本概念
垂直分表只解决了单一表数据量大的问题,但没有将表分布到不同的服务器上,因此每张表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
垂直分库的意思就是将表进行分类,分别部署在不同的数据库上面,每个库放到不同的服务器上,它的核心理念就是专库专用。
每个微服务使用单独的数据库。
(2)性能提升
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程序上提升IO、减少数据库连接数、降低单机硬件资源的瓶颈
3、水平分表
(1)基本概念
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
(2)性能提升
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
单一数据库内的水平分表,解决了单一表数据量过大的问题,分出来的小表只包含一部分数据,从而使单表查询的速度更快,效率更好。
(3)水平分表的方式
① Hash取模分表
数据库分表一般都是采用这种方式,比如一个position表,根据positionId%4,并按照结果分成4张表。
优点:
数据分片较为平均,不容易出现热点和并发访问的瓶颈。
缺点:
容易产生跨分片查询的复杂问题。
② 数值Range分表
按照时间区间或ID区间进行切分。
优点:
- 单表大小可控
- 易于扩展
- 有效避免跨分片查询的问题
缺点:
热点数据成为性能瓶颈。
例如按时间分片,有些分片存储在最近时间段的表内,可能被频繁的读写操作,而历史数据表则访问较少。
③ 一致性Hash算法
较为复杂,小编暂时不做介绍,有兴趣的可以自行百度。
4、水平分库
(1)基本概念
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
(2)性能提升
- 解决了单库数据量大,高并发的瓶颈
- 提高了系统的稳定性和可用性
(3)何时使用
当一个应用难以再进行垂直切分,或垂直切分后数据量行数巨大,存在单库读写存储的性能瓶颈,这时候就可以考虑使用水平分库了。
(4)使用弊端
但水平分库的弊端也很明显,需要确定你所需要的数据在哪一个库中,因此大大提高了系统的复杂度。
5、小总结
- 垂直分表:热门数据、冷门数据分开存储,大字段放在冷门数据表中。
- 垂直分库:按业务拆分,放到不同的库中,这些库分别部署在不同的服务器,解决单一服务器性能的瓶颈,同时提升整体架构的业务清晰度。
- 水平分表:解决单一表数据量过大的问题
- 水平分库:把一个表的数据分别分到不同的库中,这些库分别部署在不同的服务器,解决单一服务器数据量过大的问题
三、分库分表带来的问题
1、学习成本问题
大多数初级开发者都不会分库分表,如果使用不得到,还不如直接使用单一数据库了。

2、事务问题
(1)解决方案1:使用分布式事务
① 优点
由数据库管理,简单有效。
② 缺点
性能代价高,特别是shard越来越多时。
(2)解决方案2:由应用程序和数据库共同控制
① 原理
将一个分布式的大事务分解成单个数据库的小事务,并通过应用程序来控制各个小事务。
② 优点
性能更佳
③ 缺点
需要应用程序在事务控制上做灵活设计,如果使用Spring的事务管理机制,改动起来面临一定困难。
3、跨节点join问题
解决方式是分两次查询。
4、跨节点的count、order by、group by以及聚合函数问题
与join的解决方案类似,分别在各个节点得到结果然后再合并。和join的差别在于,各节点的查询可以并行执行,因此很多时候它的速度会比单一大表快很多。但是,如果结果集很大,对应用程序内存的消耗也是一个问题。
5、数据迁移、容量规划、扩容问题
6、主键ID问题
因为分表的原因,主键自增策略wufa实现。
解决方案1:UUID
使用UUID作为主键是最简单的方案,但是缺点是UUID非常的长,会占用大量存储空间,在进行连表查询的问题上也存在性能问题。
解决方案2:多维护一个Sequence表
建立一个新表,字段包含table_name和next_id。
看见表结构之后,秒懂吧?
大概意思就是记录分表后的每张表的下一个ID是多少,缺点很明显,就是每次插入数据都要访问这张表获取插入数据的id,该表很容易称为系统性能的瓶颈,同时它也存在单点问题,一旦该表数据库失效,整个系统都无法正常工作。此时可能通过主备机同步机制,解决单点问题。
解决方案3:Twitter的分布式自增ID算法Snowflake
snowflake的结构如下(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
第一位为未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年),然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点) ,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
一共加起来刚好64位,为一个Long型。(转换成字符串后长度最多19)
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。经测试snowflake每秒能够产生26万个ID。
7、跨分片的排序分页
在不同的分片节点中将数据进行排序,并将结果机型汇总,再次排序。
四、分库数量
分库数量首先和单库处理能力息息相关,比如MySQL单库超过5000万记录,Oracle单库超过1亿条记录,数据库压力就很大了。
在满足上述前提下,如果分库数量少,达不到分散存储和减轻DB性能压力的目的;如果分库数量多,跨库访问也是个问题,如果是并发模式,要消耗宝贵的线程资源,如果是串行,偶数,执行时间急剧增加。
分库数量还会直接影响硬件的投入,所以要分多少个库,要进行综合评估,一般初次分库建议分为4-8个库。
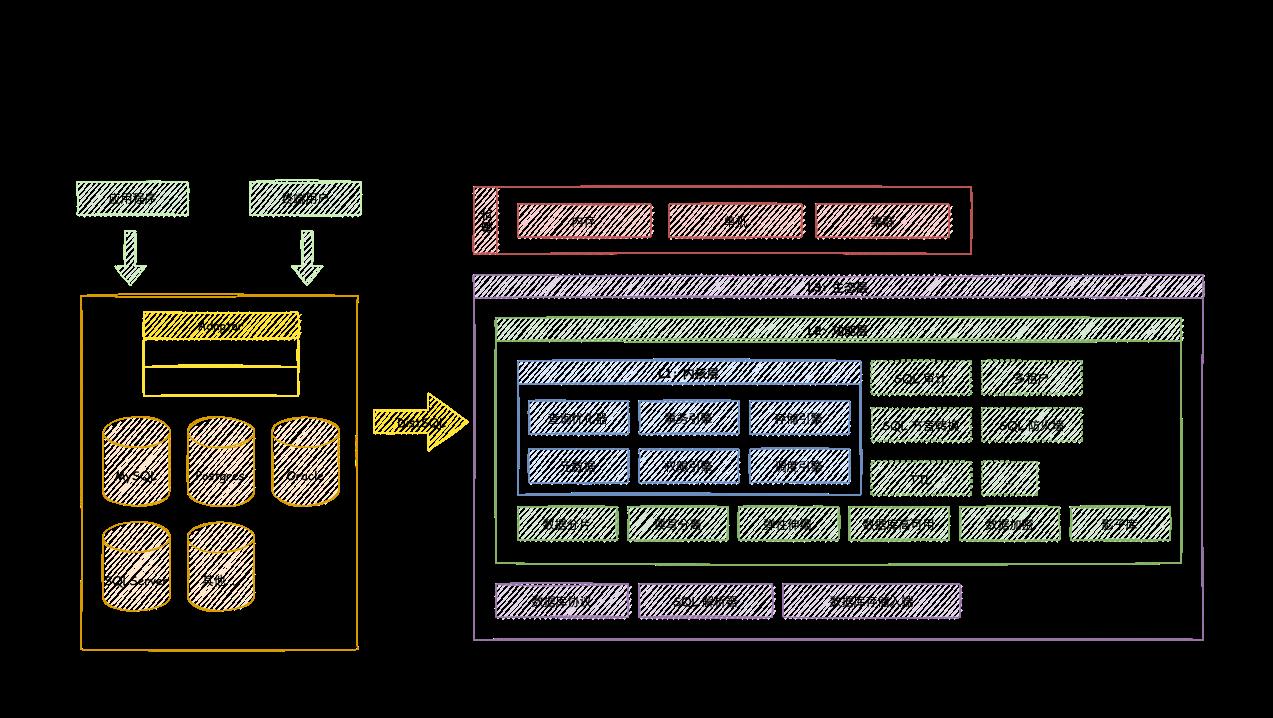
五、分库分表第三方解决方案 -- Apache ShardingSphere
Apache ShardingSphere是一套来源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(规划中)这三款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
ShardingShpere定位为关系型数据库中间件,旨在充分合理地在分布式场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它通过关注不变,进而抓住事物本质。
Apache ShardingSphere 5.x版本开始致力于可插拔式架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。目前,数据分片、读写分离、数据加密、影子库压测等功能,以及MySQL、postgresql、SQLServer、Oracle等SQL与协议的支持,均通过插件的方式织入项目。开发者能够像使用积木一样定制数据自己的独特系统。Apache ShardingSphere 目前已提供数十个SPI作为系统的扩展点,仍在不断增加中。
Apache ShardingSphere 产品定位为Database Plus,旨在构建多模数据库上层的标准和生态。它关注如何充分合理地利用数据库的计算和存储能力,而非实现一个全新的数据库。Apache ShardingSphere站在数据库的上层视角,关注它们之间的协作多于数据库本身。
六、Apache ShardingSphere的三个核心概念
1、连接
通过对数据库协议、SQL方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库。
2、增量
获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能。
3、可插拔
项目采用微内核 + 3层可插拔模式,使内核、功能组件以及生态对接完全能够灵活的方式进行可插拔式扩展,开发者能够像使用积木一样定制数据自己的独特系统。
七、Apache ShardingSphere的三款产品
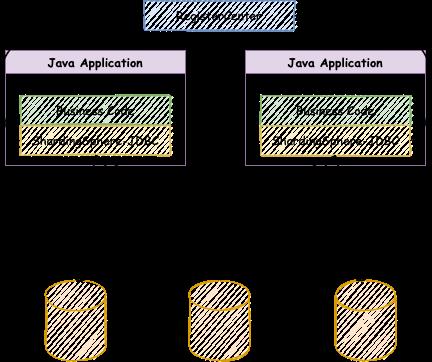
1、ShardingSphere-JDBC
定位为轻量级Java框架,在java的JDBC层提供额外服务。它使用客户端直接连接数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强型的JDBC驱动,完全兼容JDBC和各种ORM框架。
适用于任何基于JDBC的ORM框架,如mybatis、hibernate、JPA、Spring JDBC Template或直接使用JDBC。
支持任意实现JDBC规范的数据库,目前支持MySQL、Oracle、SQLServer、PostgreSQL。
支持任何第三方的数据库连接池,如Druid、DBCP、C3P0、BoneCP、HikariCP等。
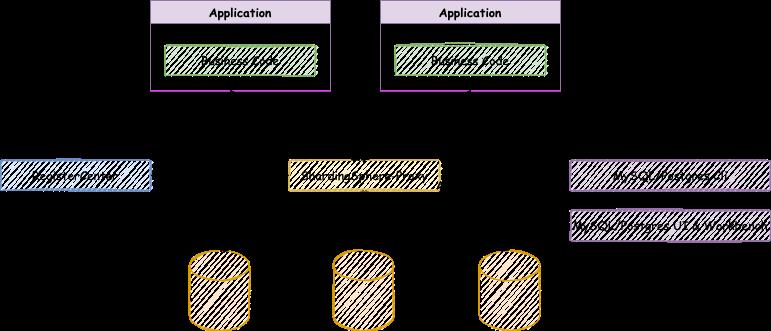
2、Sharding-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。目前支持MySQL和PostgreSQL,它可以兼容Navicat、DBeaver等数据库第三方客户端。
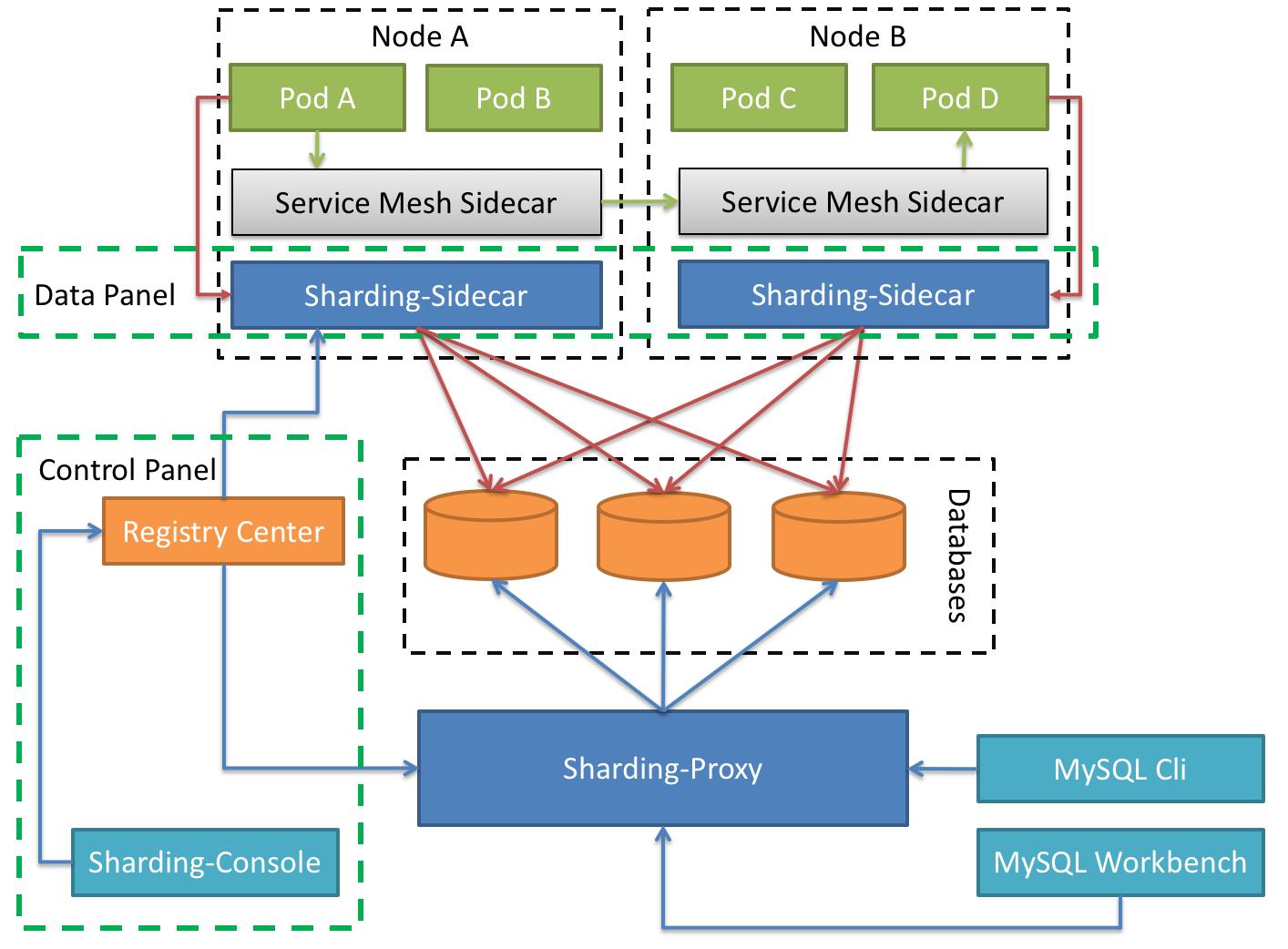
3、ShardingSphere-Sidecar
定位为kubernetes的云原生数据库代理,以sidecar的形式代理所有对数据库的访问。通过无中心、零侵入的方案提供与数据库交互的啮合层,即Database Mesh,又可称数据库网格。
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互进行有效地梳理。 使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
八、ShardingSphere-JDBC代码实例
1、ShardingSphere-JDBC 实现水平分表
(1)pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.guor</groupId>
<artifactId>shardingjdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>shardingjdbc</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
(2)application.properties
ShardingSphere-JDBC 的简单配置,参照ShardingSphere官方文档即可。
# shardingjdbc分片策略
# 配置数据源,给数据源起名称,
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=g1
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.g1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.g1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.g1.url=jdbc:mysql://localhost:3306/guor?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.g1.username=root
spring.shardingsphere.datasource.g1.password=root
#指定数据库分布情况,数据库里面表分布情况
spring.shardingsphere.sharding.tables.course.actual-data-nodes=g1.student_$->{1..2}
# 指定student表里面主键id 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.student.key-generator.column=id
spring.shardingsphere.sharding.tables.student.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定id值偶数添加到student_1表,如果cid是奇数添加到student_2表
spring.shardingsphere.sharding.tables.student.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.student.table-strategy.inline.algorithm-expression=student_$->{id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true(3)student
package com.guor.shardingjdbc.bean;
import lombok.Data;
import java.util.Date;
@Data
public class Student {
private Long id;
private String name;
private Integer age;
private Integer sex;
private String address;
private String phone;
private Date create_time;
private Date update_time;
private String deleted;
private String teacher_id;
}
(4)mapper
由于使用的是mybatis_plus,所以单表的CRUD继承BaseMapper即可。
package com.guor.shardingjdbc.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.guor.shardingjdbc.bean.Student;
import org.springframework.stereotype.Repository;
@Repository
public interface StudentMapper extends BaseMapper<Student> {
}
(5)启动类
package com.guor.shardingjdbc;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.guor.shardingjdbc.mapper")
public class ShardingjdbcApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingjdbcApplication.class, args);
}
}
(6)test
package com.guor.shardingjdbc;
import com.guor.shardingjdbc.bean.Student;
import com.guor.shardingjdbc.mapper.StudentMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
@SpringBootTest
class ShardingjdbcApplicationTests {
@Autowired
private StudentMapper studentMapper;
@Test
void addStudent() {
Student student = new Student();
student.setName("哪吒");
student.setAge(18);
student.setCreate_time(new Date());
student.setPhone("10086");
studentMapper.insert(student);
}
}
(7)sql建表语句
-- guor.student_1 definition
CREATE TABLE `student_1` (
`id` bigint(20) DEFAULT NULL,
`name` varchar(100) NOT NULL,
`age` int(10) NOT NULL,
`sex` int(11) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`phone` varchar(100) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
`update_time` timestamp NULL DEFAULT NULL,
`deleted` int(11) DEFAULT NULL,
`teacher_id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;(8)水平分表 -> 插入数据库

2、ShardingSphere-JDBC 实现水平分库
首先要建一个新库,guor1库,然后建两个与上述一样的student_1和student_2表。
(1)添加application.properties
# shardingjdbc分片策略
# 配置数据源,给数据源起名称,
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=ds1,ds2
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/guor?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
#配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/guor1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=root
#指定数据库分布情况,数据库里面表分布情况
spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds$->{1..2}.course_$->{1..2}
# 指定student表里面主键id 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.student.key-generator.column=id
spring.shardingsphere.sharding.tables.student.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定id值偶数添加到student_1表,如果cid是奇数添加到student_2表
spring.shardingsphere.sharding.tables.student.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.student.table-strategy.inline.algorithm-expression=student_$->{id % 2 + 1}
# 指定数据库分片策略 约定user_id是偶数添加ds1,是奇数添加ds2
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=teacher_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{teacher_id % 2 + 1}
spring.shardingsphere.sharding.tables.student.database-strategy.inline..sharding-column=teacher_id
spring.shardingsphere.sharding.tables.student.database-strategy.inline.algorithm-expression=ds$->{teacher_id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true(2)测试
package com.guor.shardingjdbc;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.guor.shardingjdbc.bean.Student;
import com.guor.shardingjdbc.mapper.StudentMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
@SpringBootTest
class ShardingjdbcApplicationTests {
@Autowired
private StudentMapper studentMapper;
//测试水平分库
@Test
void addStudentDb() {
Student student = new Student();
student.setName("哪吒");
student.setAge(28);
student.setCreate_time(new Date());
student.setPhone("110");
student.setTeacher_id(101);
studentMapper.insert(student);
}
@Test
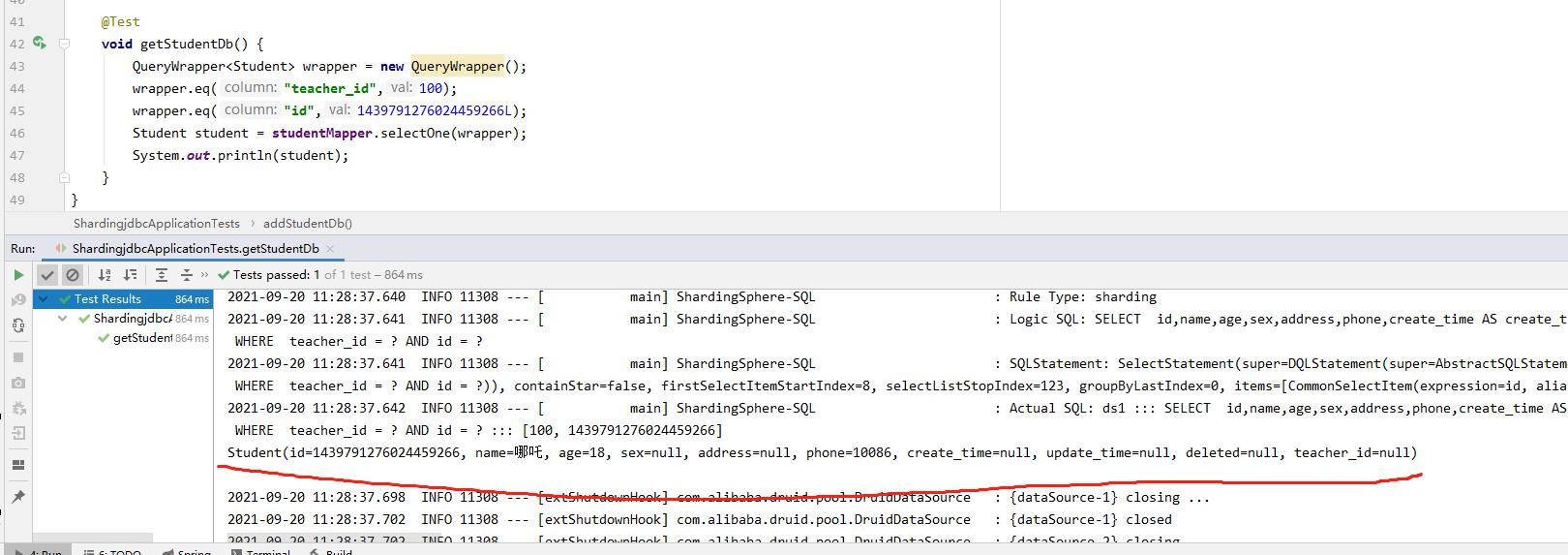
void getStudentDb() {
QueryWrapper<Student> wrapper = new QueryWrapper();
wrapper.eq("teacher_id",100);
wrapper.eq("id",1439791276024459266L);
Student student = studentMapper.selectOne(wrapper);
System.out.println(student);
}
}
(3)执行结果
水平分库 -> 插入数据库

水平分库 -> 查询数据库
3、配置公共表
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=t_udict
spring.shardingsphere.sharding.tables.t_udict.key-generator.column=dictid
spring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE九、 什么是读写分离
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。
第一台数据库服务器对外提供增删改业务的生产数据;
第二台数据库服务器,主要进行读的操作;
Sharding-JDBC通过sql语句语义分析,实现读写分离过程,不会做数据同步。
十、配置MySQL主从服务器
1、新增MySQL实例
复制原有 mysql 如: D:\\mysql-5.7.25( 作为主库 ) -> D:\\mysql-5.7.25-s1( 作为从库 ) ,并修改以 下从库的 my.ini:
[mysqld]
# 设置 3307 端口
port = 3307
# 设置 mysql 的安装目录
basedir = D : \\mysql‐5.7.25‐s1
# 设置 mysql 数据库的数据的存放目录
datadir = D : \\mysql‐5.7.25‐s1\\data
然后将从库安装为 windows 服务,注意配置文件位置:
D:\\mysql‐5.7.25‐s1\\b in >mysqld install mysqls1
‐‐defaults‐file = "D:\\mysql‐5.7.25‐s1\\my.ini"
删除服务命令
sc delete 服务名称
由于从库是从主库复制过来的,因此里面的数据完全一致,可使用原来的账号、密码登录。
2、修改主、从库的配置文件
新增内容如下:
主库 my,ini
[mysqld]
# 开启日志
log‐bin = mysql‐bin
# 设置服务 id ,主从不能一致
server‐id = 1
# 设置需要同步的数据库
binlog‐do‐db = user_db
# 屏蔽系统库同步
binlog‐ignore‐db = mysql
binlog‐ignore‐db = information_schema
binlog‐ignore‐db = performance_schema
从库 my.ini
[mysqld]
# 开启日志
log‐bin = mysql‐bin
# 设置服务 id ,主从不能一致
server‐id = 2
# 设置需要同步的数据库
replicate_wild_do_table = user_db.%
# 屏蔽系统库同步
replicate_wild_ignore_table = mysql.%
replicate_wild_ignore_table = information_schema.%
replicate_wild_ignore_table = performance_schema.%
重启主库和从库
3、创建用于主从复制的账号
# 切换至主库 bin 目录,登录主库
mysql ‐h localhost ‐uroot ‐p
# 授权主备复制专用账号
GRANT REPLICATION SLAVE ON *.* TO 'db_sync' @ '%' IDENTIFIED BY 'db_sync' ;
# 刷新权限
FLUSH PRIVILEGES;
# 确认位点 记录下文件名以及位点
show master status;
4、设置从库向主库同步数据
#切换至从库bin目录,登录从库
mysql ‐h localhost ‐P3307 ‐uroot ‐p
# 先停止同步
STOP SLAVE;
# 修改从库指向到主库,使用上一步记录的文件名以及位点
CHANGE MASTER TO
master_host = 'localhost' ,
master_user = 'db_sync' ,
master_password = 'db_sync' ,
master_log_file = 'mysql‐bin.000002' ,
master_log_pos = 154 ;
# 启动同步
START SLAVE;
# 查看从库状态 Slave_IO_Runing 和 Slave_SQL_Runing 都为 Yes 说明同步成功,如果不为 Yes ,请检查
error_log ,然后
排查相关异常。
show slave status
# 注意 如果之前此从库已有主库指向 需要先执行以下命令清空
STOP SLAVE IO_THREAD FOR CHANNEL '' ;
reset slave all;
十一、Sharding-JDBC实现读写分离
Sharding-JDBC无法实现主从数据库同步,主从数据库同步是由MySQL数据库实现的,而Sharding-JDBC实现的是增删改时选择操作主库,查数据时操作从库。
# 增加数据源s0,使用上面主从同步配置的从库。
spring.shardingsphere.datasource.names = m0,m1,m2,s0
...
spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver‐class‐name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s0.url =jdbc:mysql://localhost:3307/user_db?useUnicode=true
spring.shardingsphere.datasource.s0.username = root
spring.shardingsphere.datasource.s0.password = root
....
# 主库从库逻辑数据源定义 ds0为user_db
spring.shardingsphere.sharding.master‐slave‐rules.ds0.master‐data‐source‐name=m0
spring.shardingsphere.sharding.master‐slave‐rules.ds0.slave‐data‐source‐names=s0
# t_user分表策略,固定分配至ds0的t_user真实表
spring.shardingsphere.sharding.tables.t_user.actual‐data‐nodes = ds0.t_user🍅 Java学习路线:搬砖工逆袭Java架构师
🍅 简介:Java领域优质创作者🏆、CSDN哪吒公众号作者✌ 、Java架构师奋斗者💪
🍅 扫描主页左侧二维码,加入群聊,一起学习、一起进步
🍅 欢迎点赞 👍 收藏 ⭐留言 📝
往期精彩内容
❤️连续面试失败后,我总结了57道面试真题❤️,如果时光可以倒流...(附答案,建议收藏)
【搬砖工逆袭Java架构师 1】MySql基础知识总结(2021版)
【搬砖工逆袭Java架构师 2】MySql基础知识总结(SQL优化篇)
【搬砖工逆袭Java架构师 3】Linux基础知识总结(2021版)
【搬砖工逆袭Java架构师 4】Redis基础知识总结(2021版)
以上是关于❤️Java高级ShardingSphere分库分表保姆式教程❤️,升职加薪就靠你了(建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章
ShardingSphere分库分表schema名称导致NPE问题排查记录