shardingsphere
Posted 丶落幕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shardingsphere相关的知识,希望对你有一定的参考价值。
shardingsphere
1 基本概念
1.1 什么是shardingsphere
- 一套开源的分布式数据库中间件解决方案
- 有三个产品: sharding-jdbc,sharding-proxy,sharding-sidecar(规划中)
- 定位为关系型数据库中间件,合理在分布式环境下使用关系型数据库操作
1.2 分库分表
数据库数据量是不可控的,随着时间和业务发展,造成表里面数据越来越多,如果再去对数据库表CRUD操作时,造成性能问题
方案1: 从硬件上
方案2 : 分库分表
为了解决由于数据量过大而造成数据库性能降低问题
1.2.1 分库分表的方式
分库分表有两种方式: 垂直切分和水平切分
- 垂直切分: 垂直分表和垂直分库
- 水平切分: 水平分表和水平分库
垂直分表:
操作数据库中某张表,把这张表中一部分字段数据存到一张新表里,再把这张表另一部分字段数据存到另外一张表里面
垂直分库:
把单一数据库按照业务进行划分,专库专表
水平分表
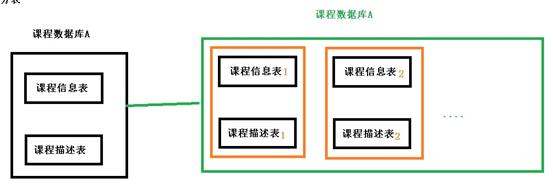
水平分库
1.2.2 分库分表应用和问题
应用
- 在数据库设计时候考虑垂直分库和垂直分表
- 随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使用索引,如果这些方式不能根本解决问题了,再考虑水平分库和水平分表
分库分表问题
- 跨节点连接查询问题(分页,排序)
- 多数据源管理问题
2 sharding-jdbc
2.1 sharding-jdbc简介
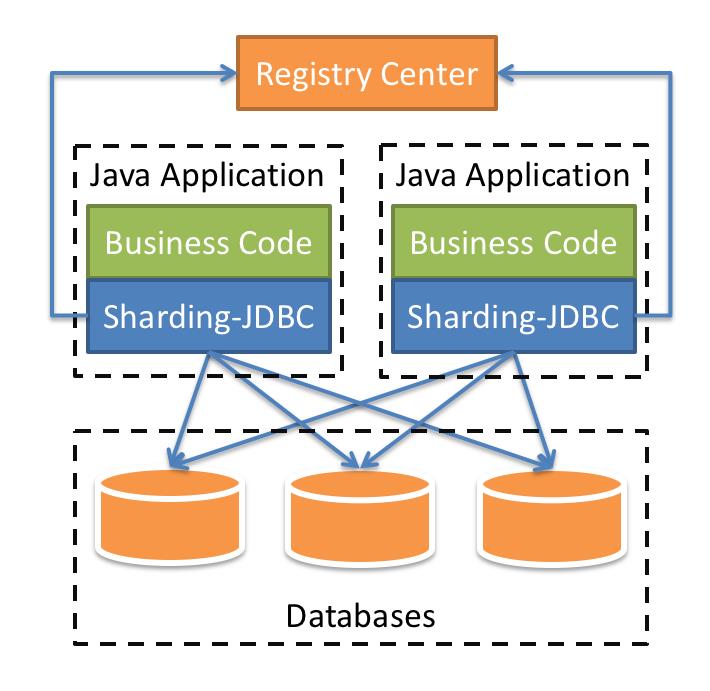
- 是轻量级的java框架,是增强版的jdbc驱动
- 主要目的是:简化对分库分表之后数据相关操作
2.2 sharding-jdbc实现(java操作)
2.2.1 环境搭建
核心依赖
<!-- sharding-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.6</version>
</dependency>
<!-- mybatis -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
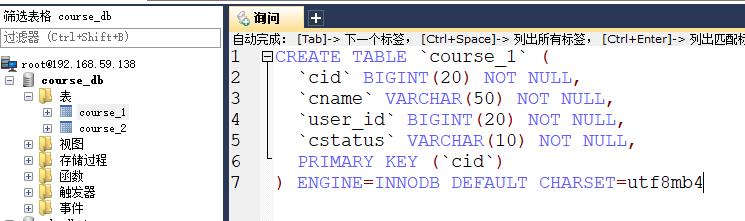
按照水平分表的方式,创建数据库和数据表
- 创建数据库course_db
- 在数据库创建两张表course_1和course_2
- 约定规则: 如果添加课程id是偶数把数据添加course_1,如果奇数添加到course_2
- 编写代码实现对分库分表数据的操作
也就是编写dao层(dao继承BaseMapper),实体层,mybatis的基本环境
2.2.2 水平分表
application.properties配置
#需要加入下面的配值允许重载bean名称,主要用于后面sql对表的操作,MybatisPlus是根据类名作为表名的
spring.main.allow-bean-definition-overriding=true
#分片策略,多个数据源则用逗号隔开,例如: ds0,ds1
spring.shardingsphere.datasource.names=ds0
#配置数据源内容,下面的ds0 是上面设置的,因此需要同名
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://192.168.59.138:3306/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root
#表的位置 在那个数据源(数据库),那个表。 下面的tables.course中的course是表名以什么开头
spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds0.course_$->{1..2}
#指定course表里面主键cid的生成策略 SNOWFLAKE是雪花算法
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#表的分片策略
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
#表示加入到course_1或者course_2表中
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
#mybatis配置
mybatis-plus.type-aliases-package=com.entity
编写测试代码
@SpringBootTest
class ShardingJdbcDemoApplicationTests {
@Autowired
CourseDao courseDao;
@Test
void contextLoads() {
Course course=new Course();
course.setCname("java");
course.setUserId(1001L);
course.setCstatus("已上架");
int insert = courseDao.insert(course);
}
}
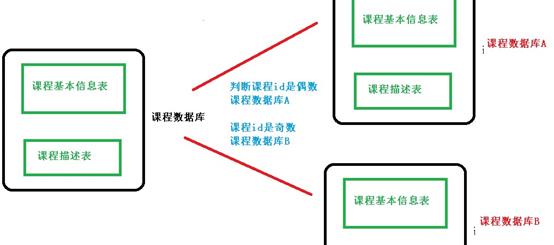
2.2.3 水平分库
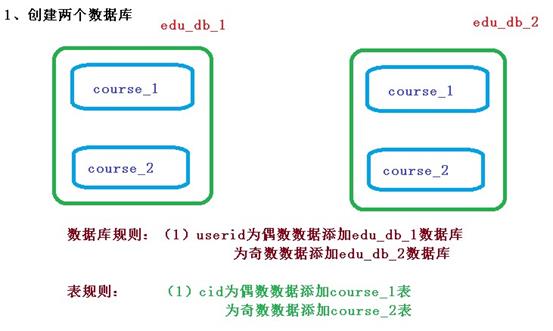

在application.properties配置文件中配置数据库的分片规则
#需要加入下面的配值允许重载bean名称,主要用于后面sql对表的操作,MybatisPlus是根据类名作为表名的
spring.main.allow-bean-definition-overriding=true
#分片策略,多个数据源则用逗号隔开,例如: ds0,ds1
spring.shardingsphere.datasource.names=ds0,ds1
#下面的ds0
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://192.168.59.138:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root
#下面的ds1
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://192.168.59.138:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
#指定数据库的分布情况,表的分布情况
# ds0,ds1 course_1,course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds$->{0..1}.course_$->{1..2}
#指定course表里面主键cid的生成策略 SNOWFLAKE是雪花算法
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#数据库分片策略 user_id偶数添加到ds0,奇数添加到ds1
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
#更细粒度的,只有course表中的user_id才会触发分库
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
#表的分片策略
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
#打开sql输出日志
spring.shardingsphere.props.sql.show=true
#mybatis配置
mybatis-plus.type-aliases-package=com.entity
编写测试代码
这里如果使用主键策略,好像有问题,可以自行测试
@Test
void addCourse() {
for (int i = 0; i < 10; i++) {
int rand = new Random().nextInt(999);
Course course=new Course();
course.setCid((long) rand);
course.setCname("java"+i);
course.setUserId((long) i);
course.setCstatus("已上架");
int insert = courseDao.insert(course);
}
}
//测试查找,随便找个
@Test
void getCourse(){
QueryWrapper<Course> queryWrapper=new QueryWrapper<>();
queryWrapper.eq("user_id", 18).eq("cid", 36);
Course course = courseDao.selectOne(queryWrapper);
System.out.println(course);
}
2.2.4 垂直分库
建库建表
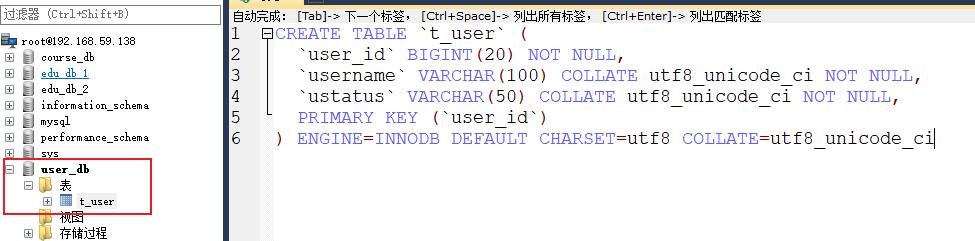
编写dao层,实体层(省略)
在原有配置上新增
spring.shardingsphere.datasource.names=ds1,ds2,ds0
#下面的ds0
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://192.168.59.138:3306/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root
#配置user_db数据库里面的t_user专库专表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds0.t_user
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user
注意: 实体类需要指定表名,不然会报错,data source name = null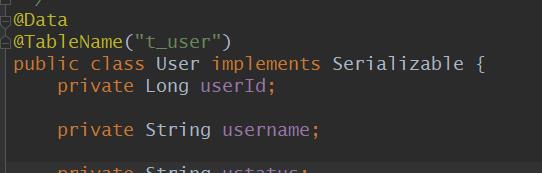
编写测试
@Test
void addUser(){
User user=new User();
user.setUsername("张三");
user.setUstatus("已付款");
int i = userDao.insert(user);
System.out.println(i>0?"新增成功":"新增失败");
}
2.2.5 公共表
- 存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
- 在每个数据库中创建出相同结构公共表
在多个数据库都创建相同结构公共表
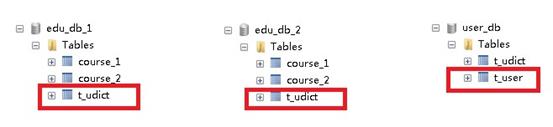
在项目配置文件application.properties进行公共表配置
#配置公共表(核心配置)
spring.shardingsphere.sharding.broadcast-tables=t_udict
spring.shardingsphere.sharding.tables.t_udict.key-generator.column=dictid
spring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE
编写dao层,实体层(跳过)
编写测试代码
@Test
void addUdict(){
Udict udict=new Udict();
udict.setUstatus("a");
udict.setUvalue("已启用");
int i = udictDao.insert(udict);
System.out.println(i>0?"新增成功":"新增失败");
}
注意: 实体类需要指定表名,不然会报错,data source name = null
当新增时会向所有数据源的公共表中都添加数据,当然删除也是一样的
2.2.6 实现读写分离
读写分离概念
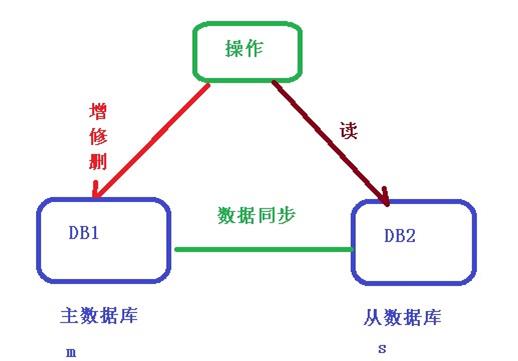
主从复制概念
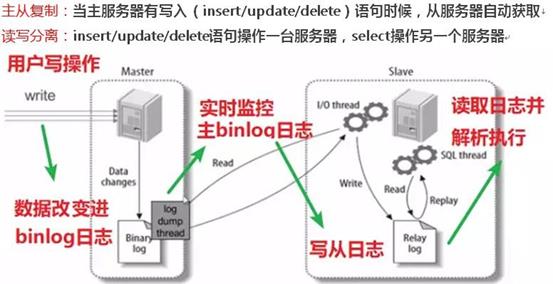
sharding-jdbc通过sql语句语义分析,实现读写分离过程,不会做数据同步
环境配置-docker启动
注意: 因为主从需要通信所以不能用docker0网络,新建网络mynet
#启动mysql01
docker run -d -p 3306:3306 --name mysql01 --net mynet -v /mydata/mysql01/log:/var/log/mysql -v /mydata/mysql01/data:/var/lib/mysql -v /mydata/mysql01/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root mysql:5.7
#启动mysql02
docker run -d -p 3307:3306 --name mysql02 --net mynet -v /mydata/mysql02/log:/var/log/mysql -v /mydata/mysql02/data:/var/lib/mysql -v /mydata/mysql02/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root mysql:5.7
修改mysql01配置
vi /mydata/mysql01/conf/my.cnf
#修改内容
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
#开启日志
log-bin=mysql-bin
#选择row模式
binlog-format=ROW
#设置服务id,主从不能一致
server-id=1
#设置需要复制的数据库(不设置则代表同步除屏蔽外的所有数据库)
#binlog-do-db=需要复制的主数据库名字
#屏蔽系统库同步
binlog_ignore_db=mysql
binlog_ignore_db=information_schema
binlog_ignore_db=performance_schema
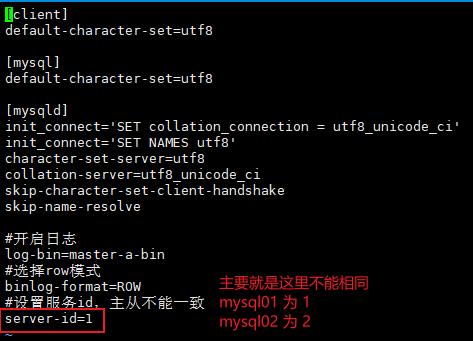
修改mysql02配置
vi /mydata/mysql02/conf/my.cnf
#修改内容
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
#启用中继日志
relay-log=mysql-relay
#设置服务id,主从不能一致
server-id=2
#设置需要复制的数据库(不设置则代表同步除屏蔽外的所有数据库)
#binlog-do-db=需要复制的主数据库名字
重启服务
docker restart $(docker ps -aq)
使用sqlyog连接mysql01数据库(master)
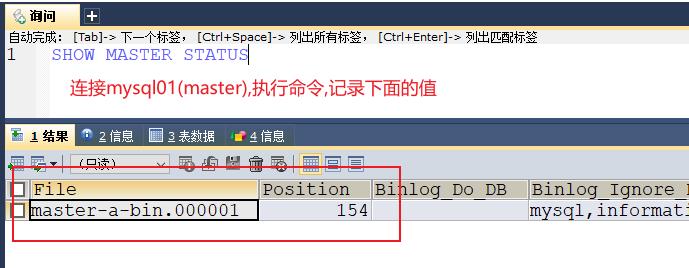
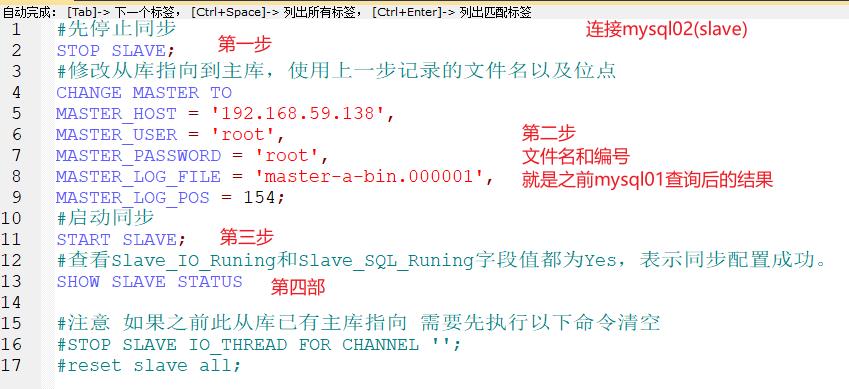
切换到mysql02(slave)
#先停止同步
STOP SLAVE;
#修改从库指向到主库,使用上一步记录的文件名以及位点
CHANGE MASTER TO
MASTER_HOST = '192.168.59.138',
MASTER_PORT=3306,
MASTER_USER = 'root',
MASTER_PASSWORD = 'root',
MASTER_LOG_FILE = 'master-a-bin.000001',
MASTER_LOG_POS = 154;
#启动同步
START SLAVE;
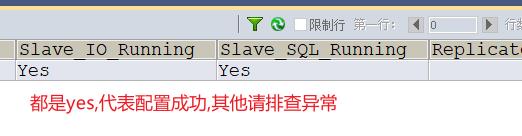
#Slave_SQL_Runing字段值为Yes,Slave_IO_Running字段值为Connecting,表示同步配置成功。
SHOW SLAVE STATUS
#注意 如果之前此从库已有主库指向 需要先执行以下命令清空
#STOP SLAVE IO_THREAD FOR CHANNEL '';
#reset slave all;
修改application.properties配置文件
因为配置主从复制环境,前面数据库数据丢失,就不在原有的配置上修改了,直接替换
#允许重载bean名称
spring.main.allow-bean-definition-overriding=true
spring.shardingsphere.datasource.names=m0,s0
#m0-master
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://192.168.59.138:3306/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
#s0-slave
spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.s0.url=jdbc:mysql://192.168.59.138:3307/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.s0.username=root
spring.shardingsphere.datasource.s0.password=root
# 主从配置
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names.=s0
# t_user 分表策略,固定分配至 ds0 的 t_user 真实表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds0.t_user
# 主键策略
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
# mybatis配置
mybatis-plus.type-aliases-package=com.entity
通过控制台打印可以发现,增删改走的是m0数据源,查询走的是s0数据源
3 sharding-proxy
3.1 sharding-proxy简介
- 定位为透明化的数据库代理端
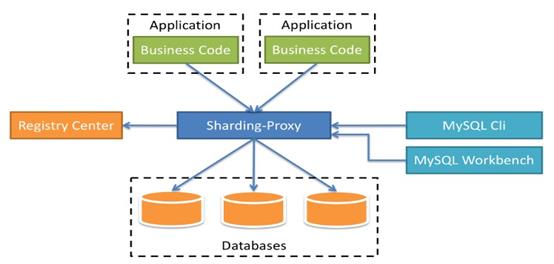
- sharding-proxy独立应用,使用安装服务,进行分库分表或读写分离配置,启动
3.2 sharding-proxy配置(分表)
文章用的4.0.1版本
解压打开,进入lib目录,目录里面文件的后缀名有好些有问题,都改成.jar结尾
- 进入conf目录,修改server.yaml目录

- 复制mysql驱动到lib目录下
- 创建数据库edu_1
- 修改config-sharding.yaml文件(mysql那段)
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://192.168.59.138:3306/edu_1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
bindingTables:
- t_order
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${0}
defaultTableStrategy:
none:
- 启动服务,默认的端口号为3307

- 创建表,并插入数据测试
CREATE TABLE `t_order` (
`order_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
`status` varchar(255) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
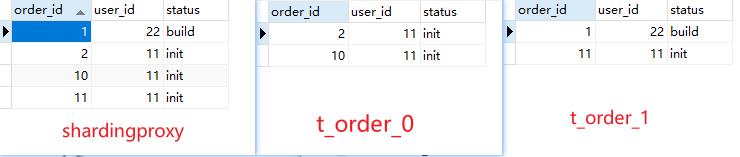
在sharding_db创建表(t_order),在代理mysql上就会生产t_order_0和t_order_1
往t_order里面插入数据,就会被水平拆分策略插入到不同的表中
注意: 因为sqlyog连不上sharding-proxy,这里用了Navicat
逻辑库,只能用sql语句CRUD,直接可视化修改数据会报错的
3.3 sharding-proxy配置(分库)
- 现在代理mysql上创建数据库edu_db_1和edu_db_2
- 修改配置文件config-sharding.yaml
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://192.168.59.138:3306/edu_db_1?serverTimezone=UTC&useSSL=false
username: root
password: Bmw.123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://192.168.59.138:3306/edu_db_2?serverTimezone=UTC&useSSL=false
username: root
password: Bmw.123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
bindingTables:
- t_order
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
defaultTableStrategy:
none:
- 启动服务
- 创建表(因为更改了配置,之前创建的表已经消失)
CREATE TABLE `t_order` (
`order_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
`status` varchar(255) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;

可以看到,当表一旦创建,在edu_db_1和edu_db_2数据库中都会创建
3.4 sharding-proxy配置(读写分离)
- 在前面环境基础上,再做修改
- 创建三个数据库demo_ds_master,demo_ds_slave_0,demo_ds_slave_1,
模拟3台mysql - 修改config-master_slave.yaml配置文件
schemaName: master_slave_db
dataSources:
master_ds:
url: jdbc:mysql://192.168.59.138:3306/demo_ds_master?serverTimezone=UTC&useSSL=false
username: root
password: Bmw.123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_0:
url: jdbc:mysql://192.168.59.138:3306/demo_ds_slave_0?serverTimezone=UTC&useSSL=false
username: root
password: Bmw.123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_1:
url: jdbc:mysql://192.168.59.138:3306/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
username: root
password: Bmw.123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
master以上是关于shardingsphere的主要内容,如果未能解决你的问题,请参考以下文章