PostgreSQL常用索引
Posted PostgreSQLChina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgreSQL常用索引相关的知识,希望对你有一定的参考价值。
作者:阎书利
索引其实就是一种数据结构,将数据库中的数据以一定的数据结构算法进行存储。当表数据量越来越大时查询速度会下降,建立合适的索引能够帮助我们快速的检索数据库中的数据,快速定位到可能满足条件的记录,不需要遍历所有记录。
索引自身也占用存储空间、消耗计算资源,创建过多的索引将对数据库性能造成负面影响(尤其影响数据导入的性能,建议在数据导入后再建索引)。因此,仅在必要时创建索引。postgresql里的所有索引都是“从属索引”,也就是索引在物理上与它描述的表文件分离。索引是一种数据库对象,每个索引在pg_class里都有记录。不同种类的索引有着不同的访问方法和内部构造。PG里所有的索引访问方法都通过页面来组织索引的内部结构。从本质来讲,索引是一些数据的键值和元组标识符(TID)之间的映射。在查询数据时如果一个page中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。(想了解索引页内容的话,可以通过pageinspect插件)。
PostgreSQL拥有众多开放特性,例如开放的数据类型接口,除了传统数据库支持的类型,还支持GIS,JSON,RANGE,IP,ISBN,图像特征值,化学,DNA等等扩展的类型,用户还可以根据实际业务扩展更多的类型。不同的索引接口针对的数据类型、业务场景是不一样的,接下来针对常用索引,介绍一下它的原理和应用场景。
索引类型
pg_am存储关于关系访问方法的信息。系统支持的每种访问方法在这个目录中都有一行
postgres=# SELECT * FROM pg_am where amtype=‘i’;
oid | amname | amhandler | amtype
------+--------+-------------+--------
403 | btree | bthandler | i
405 | hash | hashhandler | i
783 | gist | gisthandler | i
2742 | gin | ginhandler | i
4000 | spgist | spghandler | i
3580 | brin | brinhandler | i
pg_am为每一种索引方法都包含一行(内部被称为访问方法)。PostgreSQL中内建了对表 常规访问的支持,但是所有的索引方法则是在pg_am中描述。可以通过编写必要的代码并且 在pg_am中创建一项来增加一种新的索引访问方法. 一个索引方法的例程并不直接了解它将要操作的数据类型。而是由一个操作符类标识索引方 法用来操作一种特定数据类型的一组操作。
PostgreSQL提供了多种索引类型: B-tree、Hash、GiST、SP-GiST 、GIN 和 BRIN等。
每一种索引类型使用了 一种不同的算法来适应不同类型的查询。默认情况下, CREATE INDEX命令 创建适合于大部分情况的B-tree 索引。
一、B-tree
B-tree可以在可排序数据上的处理等值和范围查询。特别地,PostgreSQL的查询规划器会 在任何一种涉及到以下操作符的已索引列上考虑使用B-tree索引: < <= = >= > 将这些操作符组合起来,例如BETWEEN和IN,也可以用B-tree索引搜索实现。同样,在索引 列上的IS NULL或IS NOT NULL条件也可以在B-tree索引中使用。
B树是平衡的,也就是说,每个叶页面与根都由相同数量的内部页面分隔开。因此,搜索任何值都需要花费相同的时间。
B树是多分支的,即每个页面(通常为8 KB)包含许多(数百个)ctid。因此,B树的深度很小,对于非常大的表,实际上可以达到4–5的深度。 当字段超过单个索引页的1/4时,不适合b-tree索引。
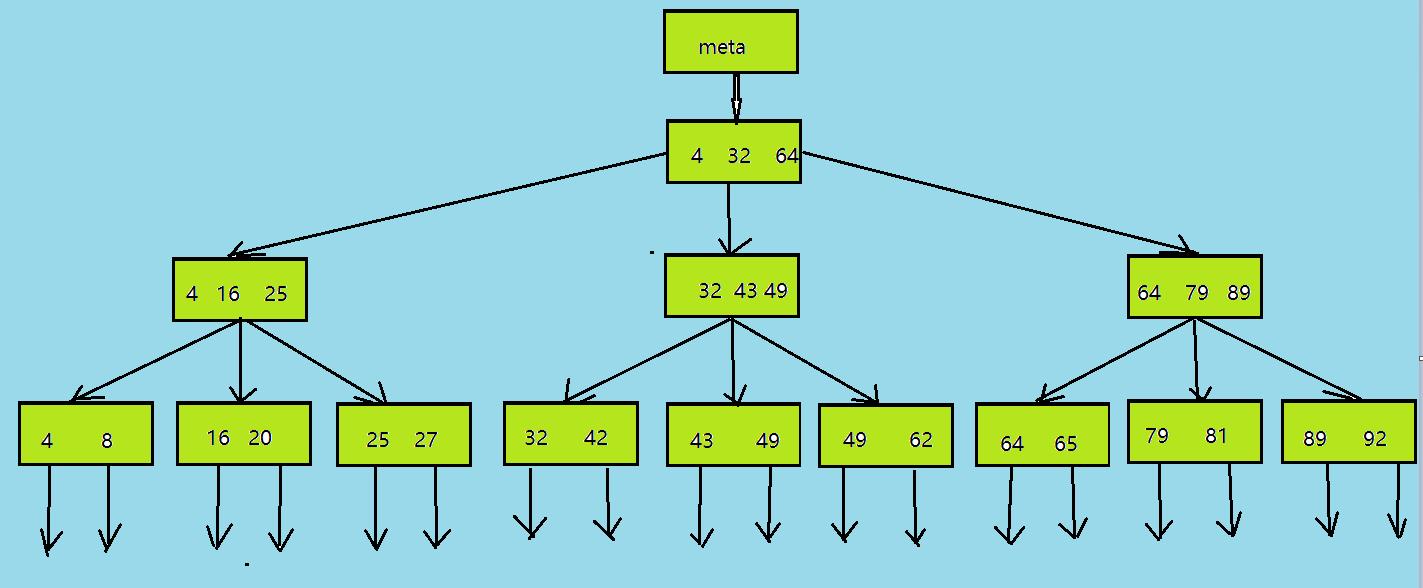
一个简单的单字段的btree索引大致如上图所示,索引的第一页是一个元页,它引用索引根。内部节点位于根下方,叶子页面位于最底行。向下箭头表示从叶节点到表行(ctid)的引用。PostgreSQL的btree索引是可以存储null值的(oracle中不可以)。并支持按条件IS NULL和IS NOT NULL进行搜索。在索引中null值存储在索引的一端,取决于创建索引时指定nulls first还是nulls last。
如果查询包括排序,则这一点很重要:如果SELECT命令在其ORDER BY子句中指定的NULL顺序与构建索引指定的顺序相同(NULLS FIRST或NULLS LAST),则可以使用索引,否则将无法使用索引。不过在数据库中null是无法和其它值进行比较的,例如:
ysla@ysla=>select null < 10;
?column?
---------- (1 row)
PostgreSQL的B-tree索引与Oracle的B-tree索引区别比较大,主要是以下4点:
- PostgreSQL中索引会存储NULL,而Oracle不会;
- PostgreSQL中建立索引时,可以使用where来建立部分索引,而Oracle不能;
- PostgreSQL中可以对同一列建立两个相同的索引,而Oracle不能;
- PostgreSQL中可以使用concurrently关键字达到创建索引时不阻塞表的DML的功能,Oracle也有online参数实现类似的功能。
使用concurrently关键字创建索引的各阶段如下:
- 开启事务1,拿到当前snapshot1。
- 扫描B表前,等待所有修改过B表(写入、删除、更新)的事务结束。
- 扫描B表,并建立索引。
- 结束事务1。
- 开启事务2,拿到当前snapshot2。
- 再次扫描B表前,等待所有修改过B表(写入、删除、更新)的事务结束。
- 在snapshot2之后启动的事务对B表执行的DML,会修改这个idx_b_2的索引。
- 再次扫描B表,更新索引。(从TUPLE中可以拿到版本号,在snapshot1到snapshot2之间变更的记录,将其合并到索引)
- 上一步更新索引结束后,等待事务2之前开启的持有snapshot的事务结束。
- 结束索引创建。索引可见。
注意点:
- 此选项只能指定一个索引的名称
- 普通CREATE INDEX命令可以在事务内执行,但是CREATE INDEX CONCURRENTLY不可以在事务内执行
- 列存表、分区表和临时表不支持CONCURRENTLY方式创建索引。
为了减少等待的时间,尽量避免创建索引过程中,两次SCAN之前对被创建索引表实施长事务,并且长事务中包含修改被创建索引的表。在第二次SCAN前,尽量避免开启长事务。
二、hash
适用场景:
hash索引存储的是被索引字段VALUE的哈希值,只支持等值查询。
hash索引特别适用于字段VALUE非常长(不适合b-tree索引,因为b-tree一个PAGE至少要存储3个ENTRY,所以不支持特别长的VALUE)的场景,例如很长的字符串,并且用户只需要等值搜索,建议使用hash index。
在pg10之前是不提倡使用hash索引的,因为hash索引不会写wal日志。不过从pg10开始解决了这一问题,并且对hash索引进行了一些加强hash索引其主要目的就是对于某些数据类型(索引键)的值,我们的任务是快速找到匹配的行的ctid。
当插入索引时,让我们计算键的哈希函数。PostgreSQL中的哈希函数总是返回integer类型,其范围为2的32次方≈40亿个值。存储桶的数量最初等于2,然后根据数据大小动态增加。bucket编号可以使用位算法从哈希码中计算出来。这是我们将放置ctid的bucket。当搜索索引时,我们计算键的哈希函数并获取bucket编号。现在,仍然需要遍历bucket的内容,并仅返回具有适当哈希码的匹配ctid。由于存储的“hash code - ctid”对是有序的,因此可以高效地完成此操作。
如图所示,哈希索引包含4种页:meta page,primary bucket page,overflow page,bitmap page。
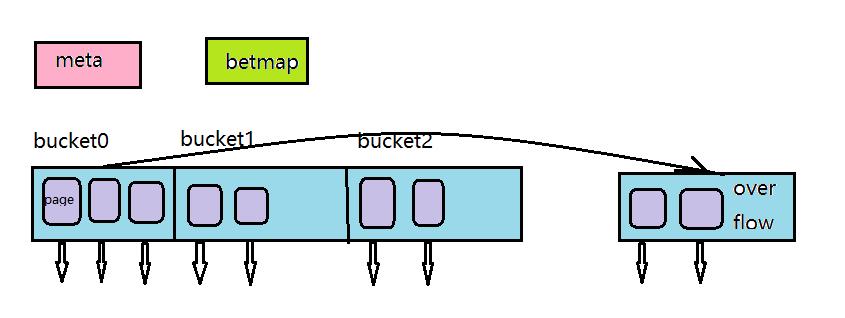
meta page(0号页),包含了HASH索引的控制信息,指导如何找到其他页面(每个bucket的primary page)index将存储划分为多个bucket(逻辑概念),每个bucket中包含若干page(每个bucket的page数量不需要一致),当插入数据时,根据计算得到的哈希,通过映射算法,映射到某个bucket,也就是说数据首先知道应该插入哪个bucket中,然后插入bucket中的primary page,如果primary page空间不足时,会扩展overflow page,数据写入overflow page。在page中,数据是有序存储(TREE),page内支持二分查找(binary search),而page与page之间是不保证顺序的,所以hash index不支持order by。
overflow page,是bucket里面的页,当primary page没有足够空间时,扩展的块称为overflow page。
bimap page,记录primary,overflow page是否为空可以被重用。
注意bucket,page都没有提供收缩功能,即无法从OS中收缩空间,但是提供了reuse(通过bitmap page跟踪),如果想要减小索引大小的唯一办法就是使用REINDEX或VACUUM FULL命令从头开始重建索引。
三、GIN
GIN(Generalized Inverted Index, 通用倒排索引) 是一个存储对(key, posting list)集合的索引结构。
倒排索引来源于搜索引擎的技术,正是有了倒排索引技术,搜索引擎才能有效率的进行数据库查找、删除等操作。
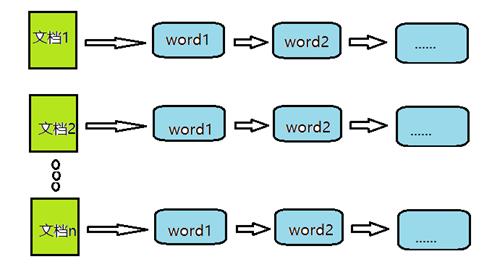
正排表结构如图所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。倒排表的结构图如下图。
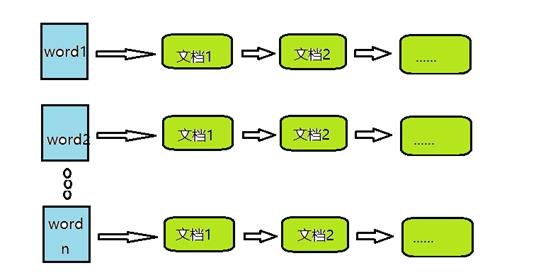
GIN是一个存储对(key, posting list)集合的索引结构
eg.(‘hello’, ‘14:2 23:4’)
posting list:一个key出现的物理位置(heap ctid,堆表行号)的链表。
GIN索引常用于查询索引字段中的部分元素值,如在text类型和json类型字段中检索某个关键字。相同的键值只存储一次。
在PG中,GIN索引会为每一个键建立一个B-tree索引,这会导致GIN索引的更新速度非常慢,因为插入或更新一条记录,所有相关键值的索引都会被更新。
PG提供gin_pending_list_limit参数来控制GIN索引的更新速度
适当将maintenance_work_mem参数增大,可以加快GIN索引的创建过程
如果查询返回的结果集特别大,则可以用gin_fuzzy_search_limit参数来控制返回的行数,默认为0,不限制,一般建议设置为5000~20000比较合适。
四、gist
GIST索引不是单独一种索引类型,而是一种架构,可以在这种架构上实现很多不同的索引策略。因此,可以使用GIST索引的特定操作符类型高度依赖于索引策略(操作符类)
GIST是广义搜索树generalized search tree的缩写。这是一个平衡搜索树。
用于解决一些B-tree,GIN难以解决的数据减少问题,例如,范围是否相交,是否包含,地理位置中的点面相交,或者按点搜索附近的点。
五、spgist
SP代表空间分区。这里的空间通常就是我们所说的空间,例如,一个二维平面。但我们会发现,任何搜索空间,实际上都是任意值域。不相交的特性简化了在插入和搜索时的决策。另一方面,作为规则,树是低分枝的。例如,四叉树的一个节点通常有四个子节点(与b树不同,b树的节点有数百个),而且深度更大。像这样的树很适合在内存中工作,但索引存储在磁盘上,因此,为了减少I/O操作的数量,必须将节点打包到页中。此外,由于分支深度的不同,在索引中找到不同值所需的时间也会不同。
六、brin
BRIN 索引是块级索引,有别于B-TREE等索引,BRIN记录并不是以行号为单位记录索引明细,而是记录每个数据块或者每段连续的数据块的统计信息。因此BRIN索引空间占用特别的小,对数据写入、更新、删除的影响也很小。
BRIN属于LOSSLY索引,当被索引列的值与物理存储相关性很强时,BRIN索引的效果非常的好。例如时序数据,在时间或序列字段创建BRIN索引,进行等值、范围查询时效果很好。与我们已经熟悉的索引不同,BRIN避免查找绝对不合适的行,而不是快速找到匹配的行。BRIN是一个不准确的索引:不包含表行的tid。
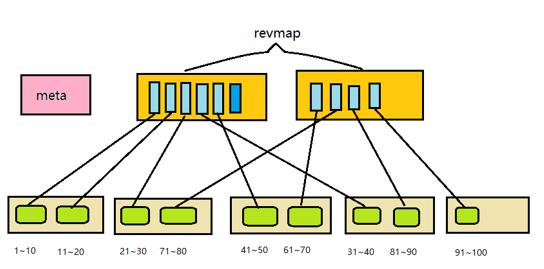
表被分割成ranges(好多个pages的大小):因此被称作block range index(BRIN)。在每个range中存储数据的摘要信息。作为规则,这里是最小值和最大值,但有时也并非如此。假设执行了一个查询,该查询包含某列的条件;如果所查找的值没有进入区间,则可以跳过整个range;但如果它们确实在,所有块中的所有行都必须被查看以从中选择匹配的行。在元数据页和摘要数据之间,是reverse range map页(revmap)。是一个指向相应索引行的指针(TIDs)数组。
在BRIN索引中,PostgreSQL会为每个8k大小的存储数据页面读取所选列的最大值和最小值,然后将该信息(页码以及列的最小值和最大值)存储到BRIN索引中。一般可以不把BRIN看作索引,而是看作顺序扫描的加速器。 如果我们把每个range都看作是一个虚拟分区,那么我们可以把BRIN看作分区的替代方案。BRIN适合单值类型,当被索引列存储相关性越接近1或-1时,数据存储越有序,块的边界越明显,BRIN索引的效果就越好。
以上是关于PostgreSQL常用索引的主要内容,如果未能解决你的问题,请参考以下文章