数据分析与挖掘3——特征工程
Posted Mrs.King_UP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析与挖掘3——特征工程相关的知识,希望对你有一定的参考价值。
数据和特征决定了机器学习得上限,而模型和算法只是逼近这个上线
1.数据预处理
- 数据采集
- 数据清洗:去除脏数据
- 数据采样:数据存在不平衡得情况下使用,有上采样和下采样之分;正样本>负样本,且数据量大,采用下采样;正样本>负样本,数据量不大,采用上采样;或者修改损失函数设置样本权重
2. 特征处理
- 标准化:使得经过处理后的数据符合标准的正态分布。
#标准化
from sklearn.preprocessing import StandardScaler
ss=StandardScaler()
data=ss.fit_transform(data)
- 归一化:将样本的特征值转换到同一量纲下,消除特征之间不同量纲的影响,区间缩放是归一化的一种。
from sklearn.preprocessing import Normalizer
sn=Normalizer()
data_normalizer=sn.fit_transform(data)
#比较适用于数据较集中的情况
两者区别:
- 归一化容易受极端最大值和最小值的影响,比较适用于数值比较集中的情况;
- 数据中如果存在异常值和较多的噪声,使用标准化;
- SVM、KNN、PCA等模型必须进行标准化或归一化;
- 两者都可以消除量纲的影响;
- 提高梯度下降法求解最优解的速度;
- 定量数据二值化:将数值型数据通过设置阈值的方式进行二值化
from sklearn.preprocessing import Binarizer
b=Binarizer(threshold=3)#设置阈值,大于阈值的设为1,小于阈值的设为0
b.fit_transform(data)
运行结果:

- 定性数据哑编码:将类别型数据转换为数值型数据,如:OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
oh=OneHotEncoder()
oh.fit_transform(target.reshape((-1,1)))
运行结果:
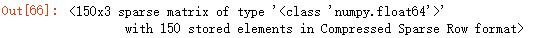
7. 缺失值处理
数据分析与挖掘2——数据预处理
8. 数据转换
3.特征降维
3.1. 特征选择
方差选择特征:计算各个特征的方差,通过设置方差的阈值训责特征
data_train_columns=[col for col in data_train.columns if col not in ['target']]
# 方差筛选特征,设置方差阈值为1
from sklearn.feature_selection import VarianceThreshold
vt=VarianceThreshold(threshold=1)
data_vt=vt.fit_transform(data_train[data_train_columns])
data_vt=pd.DataFrame(data_vt)
相关系数: 计算各个特征对目标值的相关系数(皮尔逊相关系数)
#相关系数法筛选特征,选择特征个数
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
skb=SelectKBest(lambda X,Y:np.array(list(map(lambda x:pearsonr(x,Y),X.T))).T[0],k=10)
data_skb=skb.fit_transform(data_train[data_train_columns],data_train['target'])
卡方检验:计算类别型特征和类别型target之间的相关性.卡方检验
from sklearn.feature_selection import chi2
SelectKBest(chi2,k=2).fit_transform(x,y)
最大信息系数法:计算类别型特征和类别型target之间的相关性
from minepy import MINE
def mic(x,y):
m=MINE()
m.compute_score(x,y)
return (m.mic(),0.5)
SelectKBest(lambda X,Y:np.array(list(map(lambda x:mic(x,Y),X.T))).T[0],k=10).fit_transform(train_data,train_target)
递归消除特征法:RFE 算法通过增加或移除特定特征变量获得能最大化模型性能的最优组合变量。
#RFE递归消除法
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
rfe=RFE(estimator=LogisticRegression(multi_class='auto',
solver='lbfgs',
max_iter=500),n_features_to_select=10)
#estimator为基模型,为逻辑回归模型,用于分类
#solver:几种优化方法。小数据集中,liblinear是一个好选择,sag和saga对大数据集更快;多类别问题中,除了liblinear其它四种算法都可以使用;newton-cg,lbfgs和sag仅能使用L2惩罚项,liblinear和saga使用L1惩罚项。
#max_iter:int类型,默认为‘100’,仅适用于newton-cg, sag和lbfgs算法;表示算法收敛的最大次数。
#n_features_to_select=10为选择的特征的个数
data_rfe=rfe.fit_transform(data_train[data_train_columns],data_train['target'])#data_train['target']为类别型标签
基于模型的特征选择
- 基于惩罚项的特征选择
#基于惩罚项的特征选择算法
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
sfm=SelectFromModel(LogisticRegression(penalty='l2',C=0.1,solver='lbfgs',multi_class='auto'))
#solver为优化算法,lbfgs优化算法仅支持l2;penalty为惩罚项,惩罚项是用来添加参数避免过拟合,可以理解为对当前训练样本的惩罚,用以提高函数的泛化能力;C为正则化系数的倒数,值越小,表示越强的正则化
data_sfm=sfm.fit_transform(data,target)
data_sfm=pd.DataFrame(data_sfm)
data_sfm
- 基于树模型的特征选择算法
#基于树模型的特征选择
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
sfmGBDT=SelectFromModel(GradientBoostingClassifier())
data_sfmGBDT=sfmGBDT.fit_transform(data,target)
data_sfm=pd.DataFrame(data_sfm)
data_sfm
3.2 线性降维
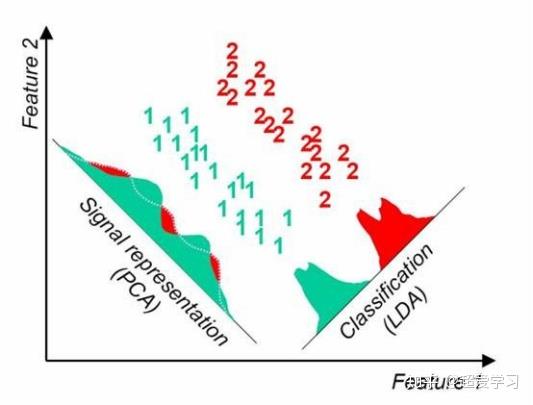
- 主成分分析PCA:利用某种线性投影,将高维数据投影到低维空间,并期望在所投影的维度上数据的方差最大,使得使用较少的数据维度保留较多的原始信息。
#PCA进行特征降维
from sklearn.decomposition import PCA
pca=PCA(n_components=10)#n_components为主成分数目
data_pca=pca.fit_transform(data_train[data_train_columns])
data_pca=pd.DataFrame(data_pca)
data_pca
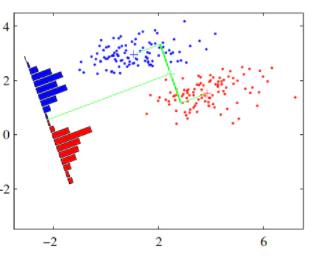
- 线性判别分析法LDA:LDA的思想是利用标签的信息,将数据投影到低维空间之后,使得同一类数据尽可能的紧凑,不同类的数据尽可能分散。因此,LDA算法是一种有监督的机器学习算法。
#LDA线性降维选择特征(应用于分类)
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda=LDA(n_components=2)#特征降维后的维数
data_lda=lda.fit_transform(data,target)
data_lda=pd.DataFrame(data_lda)
data_lda
补充说明:
LASSO回归、RIGDE回归是在线性回归的基础上添加L1、L2正则化项;
首先考虑线性回归模型的损失函数,以平方误差为损失函数,优化目标为:
min
w
∑
i
=
1
m
(
y
i
−
w
T
x
i
)
2
\\min _{w} \\sum_{i=1}^{m}\\left(y_{i}-w^{\\mathrm{T}} \\boldsymbol{x}_{i}\\right)^{2}
wmini=1∑m(yi−wTxi)2
当样本的特征较多,但是样本数较少时,为防止过拟合引入正则化项,若使用L1正则化项,则为LASSO回归:
min
w
∑
i
=
1
m
(
y
i
−
w
T
x
i
)
2
+
λ
∥
w
∥
1
\\min _{\\boldsymbol{w}} \\sum_{i=1}^{m}\\left(y_{i}-\\boldsymbol{w}^{\\mathrm{T}} \\boldsymbol{x}_{i}\\right)^{2}+\\lambda\\|w\\|_{1}
wmini=1∑m(yi−wTxi)2+λ∥w∥1
若使用L2正则化项,则为RIDGE回归:
min
w
∑
i
=
1
m
(
y
i
−
w
T
x
i
)
2
+
λ
∥
w
∥
2
2
\\min _{\\boldsymbol{w}} \\sum_{i=1}^{m}\\left(y_{i}-\\boldsymbol{w}^{\\mathrm{T}} \\boldsymbol{x}_{i}\\right)^{2}+\\lambda\\|\\boldsymbol{w}\\|_{2}^{2}
wmini=1∑m(yi−wTxi)2+λ∥w∥22
其中,
λ
>
0
\\lambda>0
λ>0为正则化系数。
∥
w
∥
1
=
∣
w
1
∣
+
∣
w
2
∣
+
∣
w
3
∣
+
⋯
+
∣
w
n
∣
\\|w\\|_{1}=\\left|w_{1}\\right|+\\left|w_{2}\\right|+\\left|w_{3}\\right|+\\cdots+\\left|w_{n}\\right|
∥w∥1=∣w1∣+∣w2∣+∣w3∣+⋯+∣wn∣
∥
w
∥
2
=
(
∣
w
1
∣
2
+
∣
w
2
∣
2
+
∣
w
3
∣
2
+
⋯
+
∣
w
n
∣
2
)
1
/
2
\\|w\\|_{2}=\\left(\\left|w_{1}\\right|^{2}+\\left|w_{2}\\right|^{2}+\\left|w_{3}\\right|^{2}+\\cdots+\\left|w_{n}\\right|^{2}\\right)^{1 / 2}
∥w∥2=(∣w1∣2+∣w2∣2+∣w3∣2+⋯+∣wn∣2)1/2
假设
x
x
x仅有两个特征,所以
w
w
w也只有两个分量
w
1
,
w
2
w_1,w_2
w1,w2,所以上式变换为
∥
w
∥
1
=
∣
w
1
∣
+
∣
w
2
∣
\\|w\\|_{1}=\\left|w_{1}\\right|+\\left|w_{2}\\right|
∥w∥1=∣w1∣+∣w以上是关于数据分析与挖掘3——特征工程的主要内容,如果未能解决你的问题,请参考以下文章