第三周作业:卷积神经网络(Part 1)
Posted Christine_CS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三周作业:卷积神经网络(Part 1)相关的知识,希望对你有一定的参考价值。
深度学习计算
层和块
单个神经元:(1)接受一些输入;(2)生成相应的标量输出;(3)具有一组相关 参数(parameters)。
层:(1)接受一组输入,(2)生成相应的输出,(3)由一组可调整参数描述。
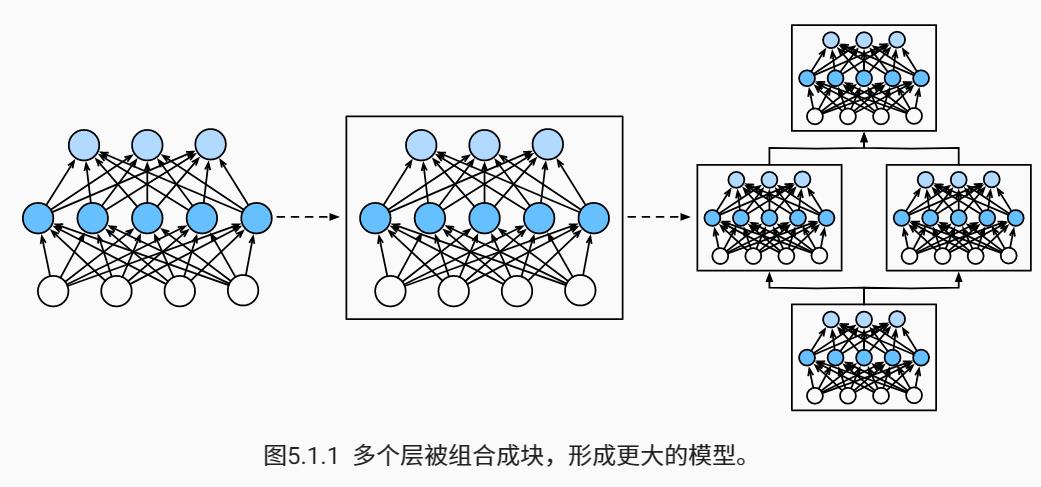
自定义块
每个块必须提供的基本功能:
1.将输入数据作为其正向传播函数的参数。
2.通过正向传播函数来生成输出。请注意,输出的形状可能与输入的形状不同。例如,我们上面模型中的第一个全连接的层接收任意维的输入,但是返回一个维度256的输出。
3.计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
4.存储和访问正向传播计算所需的参数。
5.根据需要初始化模型参数。
顺序块
需要定义两个关键函数: 1. 一种将块逐个追加到列表中的函数。 2. 一种正向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
在正向传播函数中执行代码
到目前为止,我们网络中的所有操作都对网络的激活值及网络的参数起作用。然而,有时我们可能希望合并既不是上一层的结果也不是可更新参数的项。我们称之为常数参数(constant parameters)。
参数管理
选择了架构并设置了超参数之后,我们就进入了训练阶段。此时,我们的目标是找到使损失函数最小化的参数值。经过训练后,我们将需要使用这些参数来做出未来的预测。大多数情况下,我们可以忽略声明和操作参数的具体细节,而只依靠深度学习框架来完成繁重的工作。然而,当我们离开具有标准层的层叠架构时,我们有时会陷入声明和操作参数的麻烦中。
参数管理主要介绍:
1.访问参数,用于调试、诊断和可视化。
2.参数初始化。
3.在不同模型组件间共享参数。
参数访问
目标参数
每个参数都表示为参数(parameter)类的一个实例。要对参数执行任何操作,首先我们需要访问底层的数值。
参数是复合的对象,包含值、梯度和额外信息。除了值之外,我们还可以访问每个参数的梯度。
一次性访问所有参数
当我们处理更复杂的块(例如,嵌套块)时,需要递归整个树来提取每个子块的参数。同时,这为我们提供了另一种访问网络参数的方式。
从嵌套块收集参数
定义一个生成块的函数(可以说是块工厂),然后将这些块组合到更大的块中。因为层是分层嵌套的,所以我们也可以像通过嵌套列表索引一样访问它们。
参数初始化
默认情况下,PyTorch会根据一个范围均匀地初始化权重和偏置矩阵,这个范围是根据输入和输出维度计算出的。PyTorch的nn.init模块提供了多种预置初始化方法。
内置初始化
首先调用内置的初始化器;还可以将所有参数初始化为给定的常数(比如1);还可以对某些块应用不同的初始化方法。
自定义初始化
若深度学习框架没有提供我们需要的初始化方法,我们使用以下的分布为任意权重参数ω定义初始化方法:

1.实现了一个my_init函数来应用到net
2.可以直接设置参数
参数绑定
目的:在多个层间共享参数。
参数绑定的层:不仅值相等,而且由相同的张量表示。因此,如果我们其中一个参数会随另一个参数的改变而改变。
梯度变化情况:当参数绑定时,由于模型参数包含梯度,因此在反向传播期间参数绑定的层的梯度会加在一起。
自定义层
不带参数的层
要构建不带参数的层,我们只需继承基础层类并实现正向传播功能。
带参数的层
我们可以使用内置函数来创建参数,这些函数提供一些基本的管理功能。比如管理访问、初始化、共享、保存和加载模型参数。这样做的好处之一是,我们不需要为每个自定义层编写自定义序列化程序。
读写文件
加载和保存张量
对于单个张量,我们可以直接调用load和save函数分别读写它们。这两个函数都要求我们提供一个名称,save要求将要保存的变量作为输入。
1.可以将存储在文件中的数据读回内存。
2.可以存储一个张量列表,然后把它们读回内存。
3.可以写入或读取从字符串映射到张量的字典。当我们要读取或写入模型中的所有权重时,这很方便。
加载和保存模型参数
深度学习框架提供了内置函数来保存和加载整个网络。需要注意一点,这将保存模型的参数而不是保存整个模型。
卷积神经网络
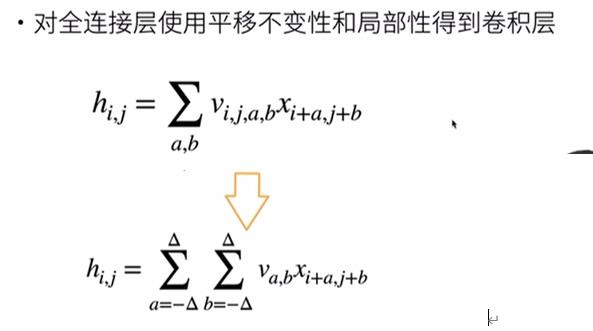
从全连接层到卷积
全连接层



总结
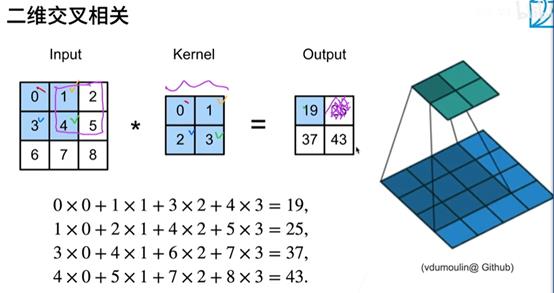
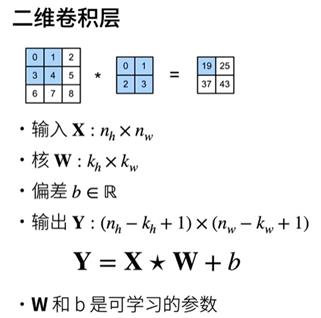
图像卷积




代码实现
互相关运算

注:X:输入 K:核矩阵 h、w: 行数列数
Y(输出):输入的高-核的高度+1,输入的宽度-核的宽度+1
for for遍历所有输出元素
验证上述二维互相关运算的输出

实现二维卷积层

卷积层的简单应用:检测图像中不同颜色的边缘
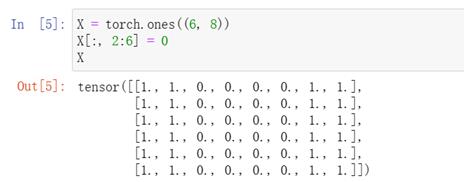


卷积核K只能检测垂直边缘
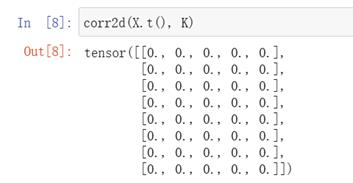
学习由X生成Y的卷积核

注:输入输出均为1
Reshape增加两个维度:通道数,批量大小数,均为1
L:loss
访问Weight.data操作:inplace操作?
所学的卷积核的权重张量

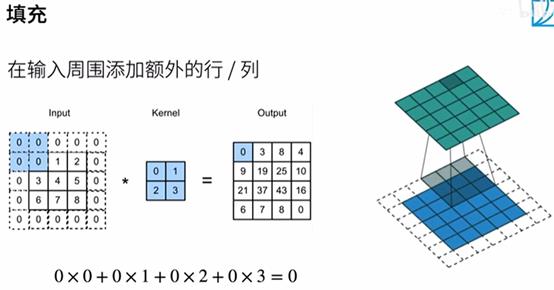
填充和步幅





代码实现
填充(在所有侧边填充1个像素)

注:定义一个函数
在维度前面加入通道数、批量大小数
调用conv2d函数
四维拿掉前两维得到矩阵的输出
填充不同的高度和宽度

注:Padding(填充)行数2 列数1
输出输入还一样88*
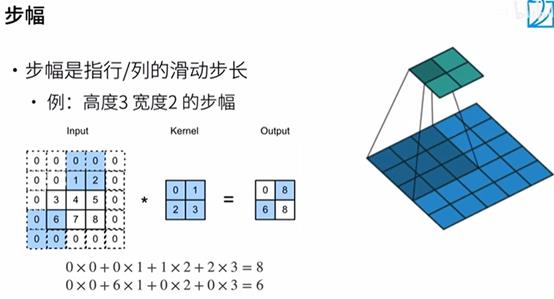
将高度和宽度步幅设置为2

注:stride(步幅)=2
输出44 减半*
复杂例子

QA
1.超参数重要程度:核大小最重要,其次填充,步幅;
2.卷积核3*3居多;
3.多个输入和输出通道,重要超参数:通道数。
多输入多输出通道



变化:卷积核多了Co(output)。


代码实现
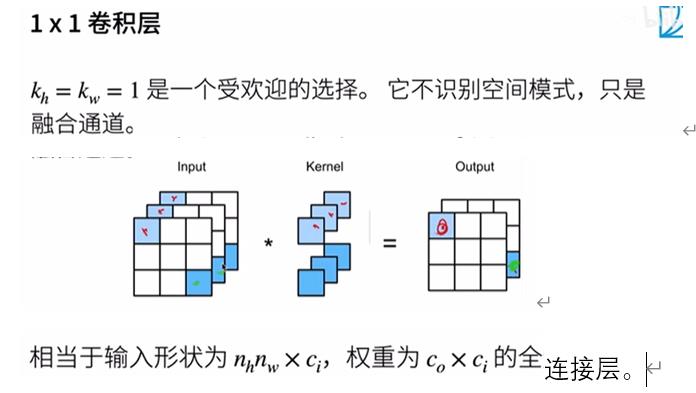
实现多通入通道互相关运算

注:X、K都是3d,zip起来,for拿出对应输入通道的小矩阵,做互相关运算,然后求和。
验证互相关运算的输出
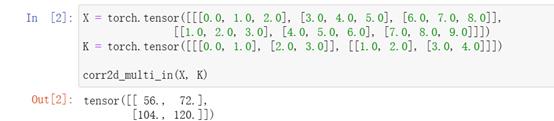
计算多通道的输出的互相关函数
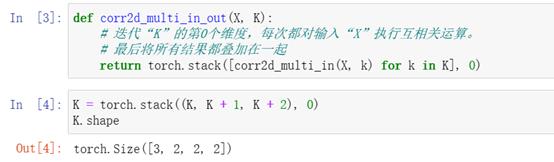
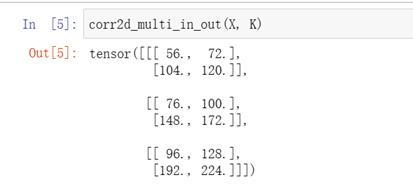
1*1卷积

池化层

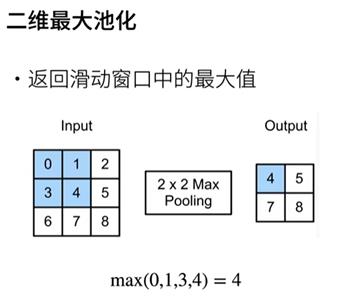



代码实现
实现池化层的正向传播

验证二维最大汇聚层的输出

验证平均汇聚层

填充和步幅

深度学习框架中的步幅与池化窗口的大小相同
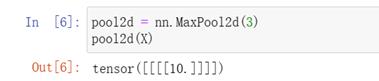
填充和步幅可以手动设定

可以设定一个任意大小的矩形池化窗口,并分别设定填充和步幅的高度和宽度
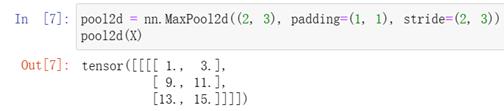
池化层在每个输入通道上单独运算

LeNet
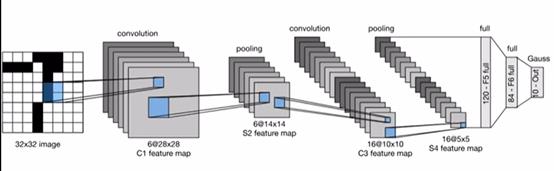

代码实现
LeNet(LeNet-5)由两个部分组成: * 卷积编码器:由两个卷积层组成; * 全连接层密集块:由三个全连接层组成。

注:Reshape() 批量数不变 通道数变成1 2828
卷积层nn.Conv2d(输入1,输出6,kernel55,填充2) 加入nn.Sigmoid()激活函数
均值池化层 nn.AvgPool2d(kernel22 步幅2)
卷积层 nn.Conv2d(输入6,输出16,kernel55) 加入nn.Sigmoid()激活函数
均值池化层 nn.AvgPool2d(kernel22 步幅2) nn.Flatten():第一位批量保持,后面拉成一样的维度
nn.Linear(1655,120) nn.Sigmoid()
nn.Linear(120,84) nn.Sigmoid()
nn.Linear(84,10)*
检查模型

注:第一组卷积+池化+激活
卷积: 12828->62828 通道数变为6,高宽不变
Sigmoid: 62828
平均池化:62828->61414 通道数不变,高宽变了
第二组卷积+池化+激活
卷积: 61414->161010 通道数变为16,高宽变为1010
Sigmoid: 161010
平均池化:161010->1655 通道数不变,高宽变了
Flatten:1400 拉直变成MLP
Liner+Sigmoid:1120
Liner+Sigmoid:184
Liner:110*
LeNet在Fashion-MNIST数据集上的表现

对 evaluate_accuracy函数进行轻微的修改
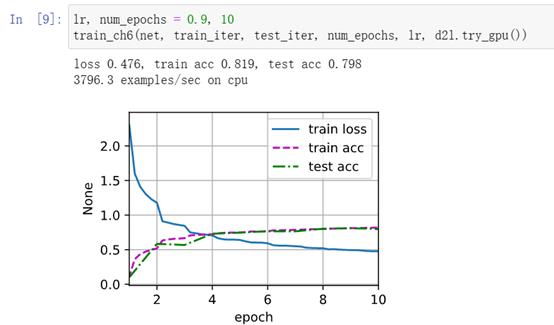
训练和评估LeNet-5模型
猫狗大战
GPU
下载解压数据集到当前目录
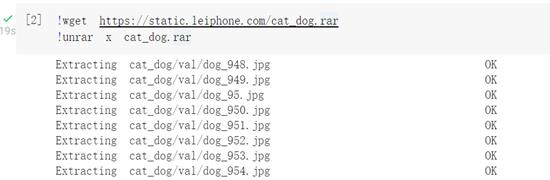
图片处理
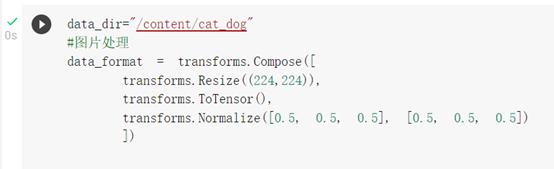
拼接路径

报错…
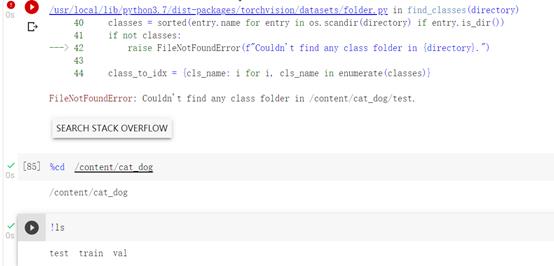
未完待续…
以上是关于第三周作业:卷积神经网络(Part 1)的主要内容,如果未能解决你的问题,请参考以下文章