第五周作业:卷积神经网络(Part3)
Posted Qxw1012
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第五周作业:卷积神经网络(Part3)相关的知识,希望对你有一定的参考价值。
文章目录
- 一、《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
- 二、《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
- 三、《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》
- 四、《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
- 五、《Squeeze-and-Excitation Networks》
- 六、《Deep Supervised Cross-modal Retrieval》
一、《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
1.原文地址
2.TensorFlow官方
3.论文亮点
1.MobileNet模型基于深度可分解卷积(depthwise separable convolutions),它由分解后的卷积组成,分解后的卷积就是将标准卷积分解成一个深度卷积(depthwise convolution)和一个1x1的点卷积(pointwise convolution)。深度卷积将每个卷积核应用于输入的每一个通道;然后,深度卷积的输出作为点卷积的输入,点卷积用1x1卷积来组合这些输入。大大减少了运算量和参数数量。结构如下图所示:


2.引入控制模型大小的超参数:
- 宽度因子α (Width multiplier ),用于控制输入和输出的通道数。对于深度可分离卷积,其计算量为: D k × D k × α M × D F × D F + 1 × 1 × α M × α N × D F × D F D_k×D_k×αM×D_F×D_F+1×1×αM×αN×D_F×D_F Dk×Dk×αM×DF×DF+1×1×αM×αN×DF×DF
- 分辨率因子ρ (resolution multiplier ),用于控制输入和内部层表示。即用分辨率因子控制输入的分辨率。对于深度可分离卷积,其计算量为: D k × D k × α M × ρ D F × ρ D F + 1 × 1 × α M × α N × ρ D F × ρ D F D_k×D_k×αM×ρD_F×ρD_F+1×1×αM×αN×ρD_F×ρD_F Dk×Dk×αM×ρDF×ρDF+1×1×αM×αN×ρDF×ρDF
注:α,ρ是人为手动设置的,在给出的测试代码中,α,ρ均设置为1。
4.代码学习
注:如果真实复现MobileNetV1网络结构,需将代码中的
cfg = [(64, 1), (128, 2), (128, 1), (256, 2), (256, 1), (512, 2), (512, 1),
(1024, 2), (1024, 1)]
修改成
cfg = [(64, 1), (128, 2), (128, 1), (256, 2), (256, 1), (512, 2), (512, 1),
(512, 1),(512, 1),(512, 1),(512, 1),(1024, 2), (1024, 1)]
参考文章:
论文笔记:MobileNet v1
【深度学习】经典分类网络 亮点及结构
MobileNet网络详解
MobileNets: Efficient CNN for Mobile Vision Applications[1704.04861]
二、《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
1.原文地址
2.非官方Pytorch代码
3.论文亮点
- Inverted Residuals(倒残差结构),先升维再降维,增强梯度的传播,显著减少推理期间所需的内存占用。
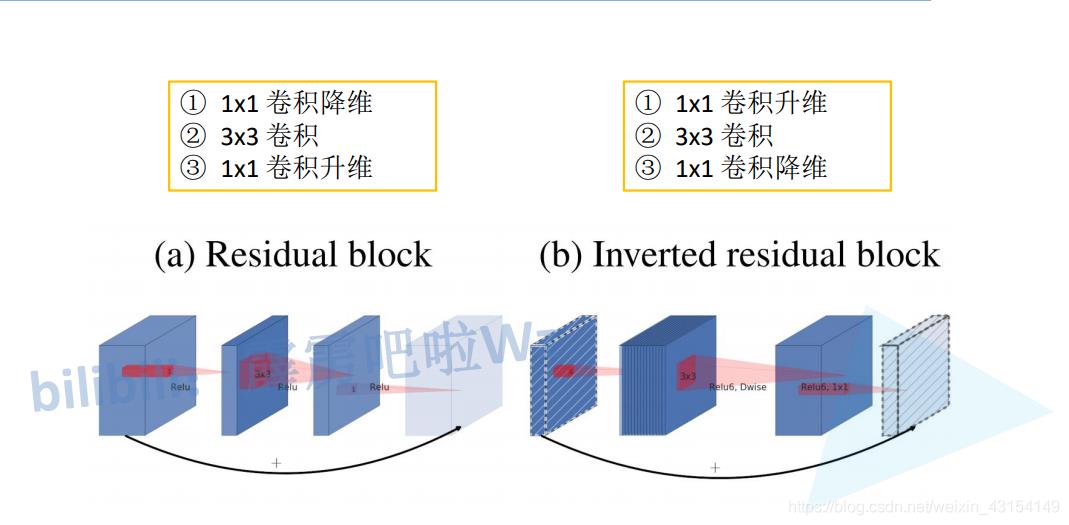
-
网络为全卷积的,使得模型可以适应不同尺寸的图像;使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性
-
Linear Bottlenecks,去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性,增强网络的表达能力。
注:针对于论文中给出的shortcut连接表述是有误的,只有当stride=1且输入特征矩阵与输出特征矩阵的shape相同时,满足这两个条件的时候,才会有shortcut连接,其他情况均没有。
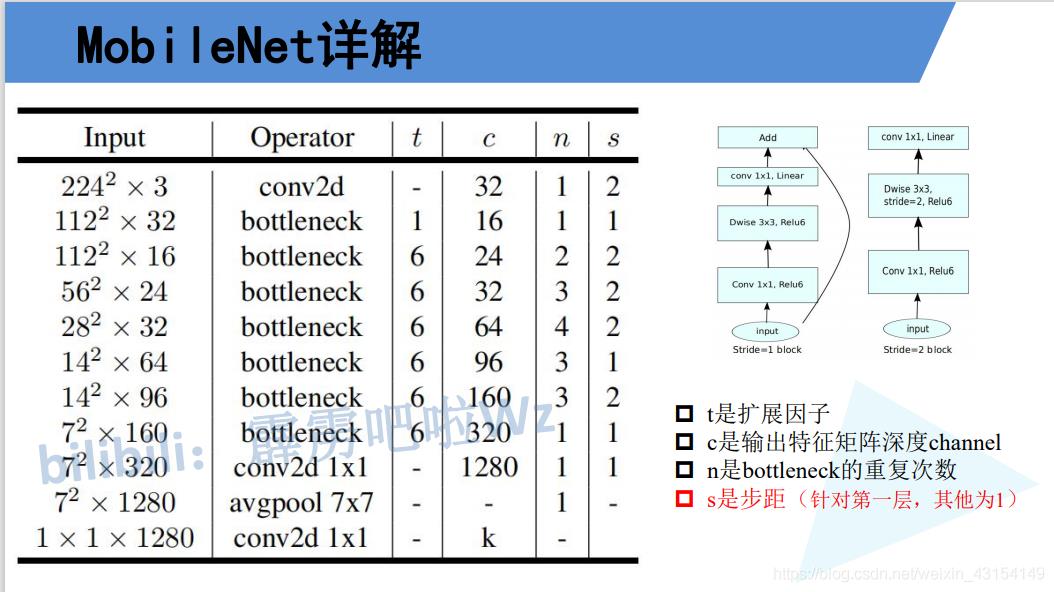
4.代码学习
2个epoch结果
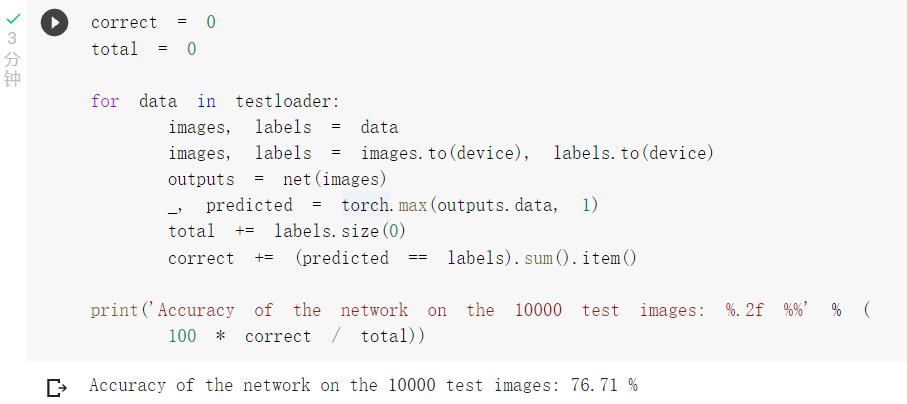
10个epoch结果
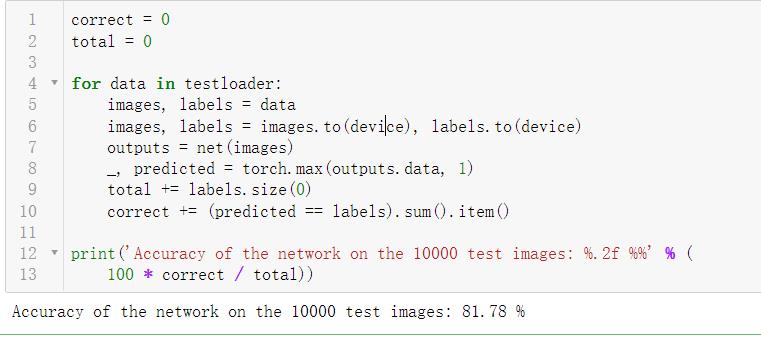
注:
代码细节部分:
cfg = [(1, 16, 1, 1),
#根据MobileNetV2网络结构,应将老师给出的代码中,(6, 24, 2, 1)应改成(6, 24, 2, 2)
(6, 24, 2, 2),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
应该使用nn.ReLU6代替F.relu激活函数
参考文章:
MobileNetV1 & MobileNetV2 简介
论文阅记 MobileNetV2:Inverted Residuals and Linear Bottlenecks
三、《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》
1.原文地址
2.代码
3.论文解读
1.高光谱图像(HyperSpectral Image,简称HSI)是三维立体数据,包含两个空间维度和一个光谱维度。
作者提出HybirdSN模型:将空间光谱和光谱的互补信息分别以3D-CNN和2D-CNN层组合到了一起,从而充分利用了光谱和空间特征图,结合二维和三维卷积的优势,设计的网络结构中先使用三维卷积,再堆叠二维卷积,最后连接分类器。既发挥了三维卷积的优势,充分提取光谱-空间特征,也避免了完全使用三维卷积而导致的模型复杂。
2.网络结构
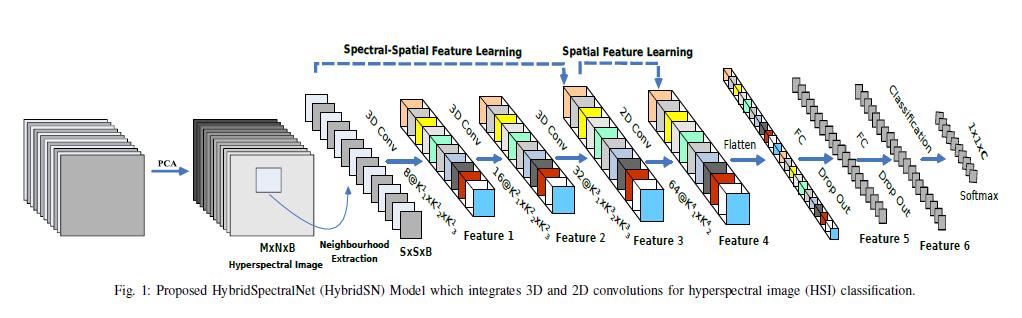
网络首先进行的PCA降维操作,然后由3层三维卷积(3D Conv)→ 1层二维卷积(2D Conv)→ 2层全连接层(Fc) → 1层softmax分类层组成。
3.代码学习
根据给出的网络结构,搭建网络。参考网上代码,Batch Norm适合用于分类任务,所以在搭建网络的时候,添加Batch Norm可以使训练更容易、加速收敛、防止模型过拟合。
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv3d_1 = nn.Sequential(
nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace = True),
)
self.conv3d_2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
self.conv2d_4 = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,16)
self.dropout = nn.Dropout(p = 0.4)
def forward(self,x):
out = self.conv3d_1(x)
out = self.conv3d_2(out)
out = self.conv3d_3(out)
out = self.conv2d_4(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
测试结果:

4.问题思考
1.2D卷积和3D卷积的区别?
- 二维卷积(2D-CNN):可以提取高光谱图像的空间特征(spatial feauture);特点是相对三维卷积,模型比较简单,但不能提取高光谱图像的光谱特征;
- 三维卷积(3D-CNN):可以同时提取高光谱图像的光谱特征(spectral feature)和空间特征;同时提取三个维度的数据的特征,能同时进行空间和空间特征表示,但数据计算量要比二维卷积大不少;但捕获光谱特征之后可以提升分类准确率;
2、每次分类的结果为什么都不一样?
(1)首先,权重初始化都是随机的,经过梯度下降以后最后的权值肯定也不是相同的。
(2)其次,就是在网络中,为了防止过拟合,采用了Dropout,随机dropout掉不同的隐藏神经元来进行网络训练,所以最终的分类结果也不一样。可以通过model.train(),model.eval()来解决和这个问题。
3、如果想要进一步提升高光谱图像的分类性能,可以如何改进?
添加注意力机制,自从Transformer提出之后,自注意力机制也随即在CV领域大放异彩。Attention是从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
# 通道注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
# 空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
测试结果,相比较未添加注意力机制的代码,准确率竟然从0.9822下降到0.9771:

5.注意力机制在CV的简单总结
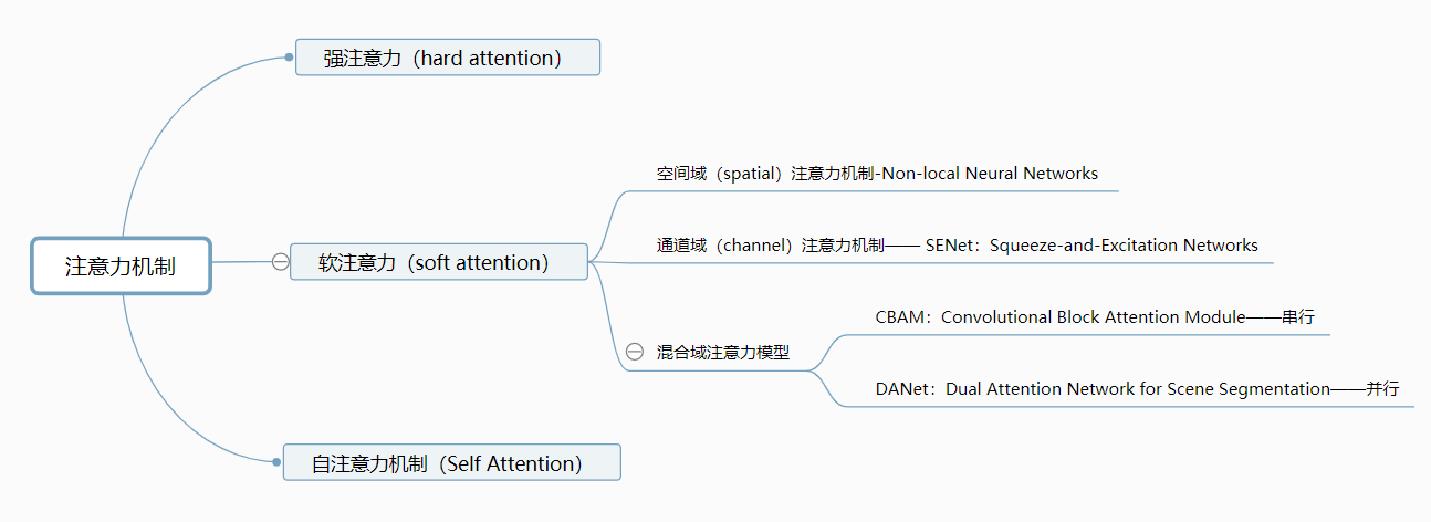

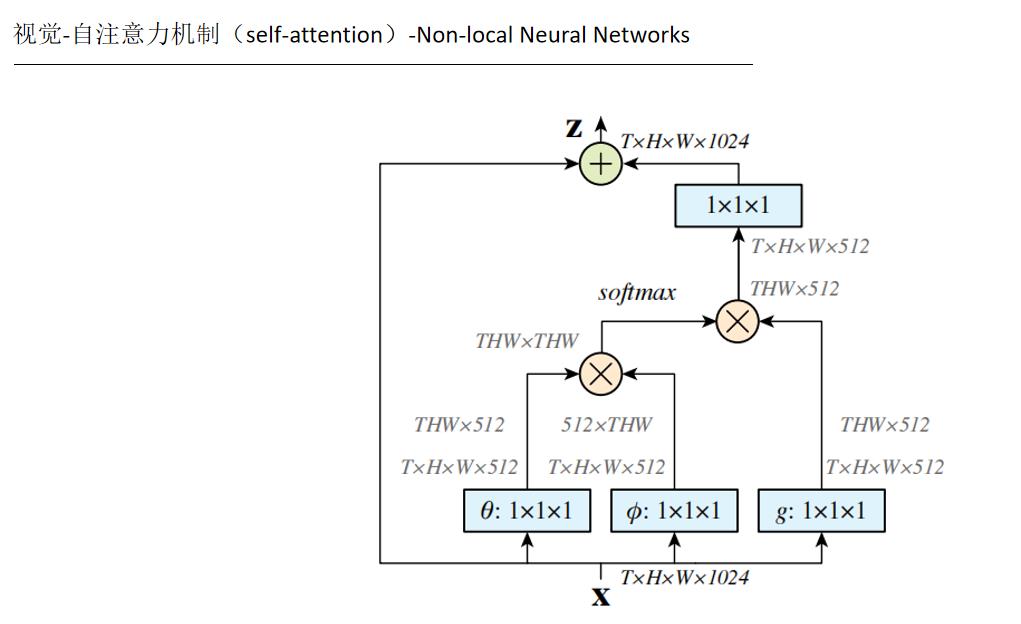
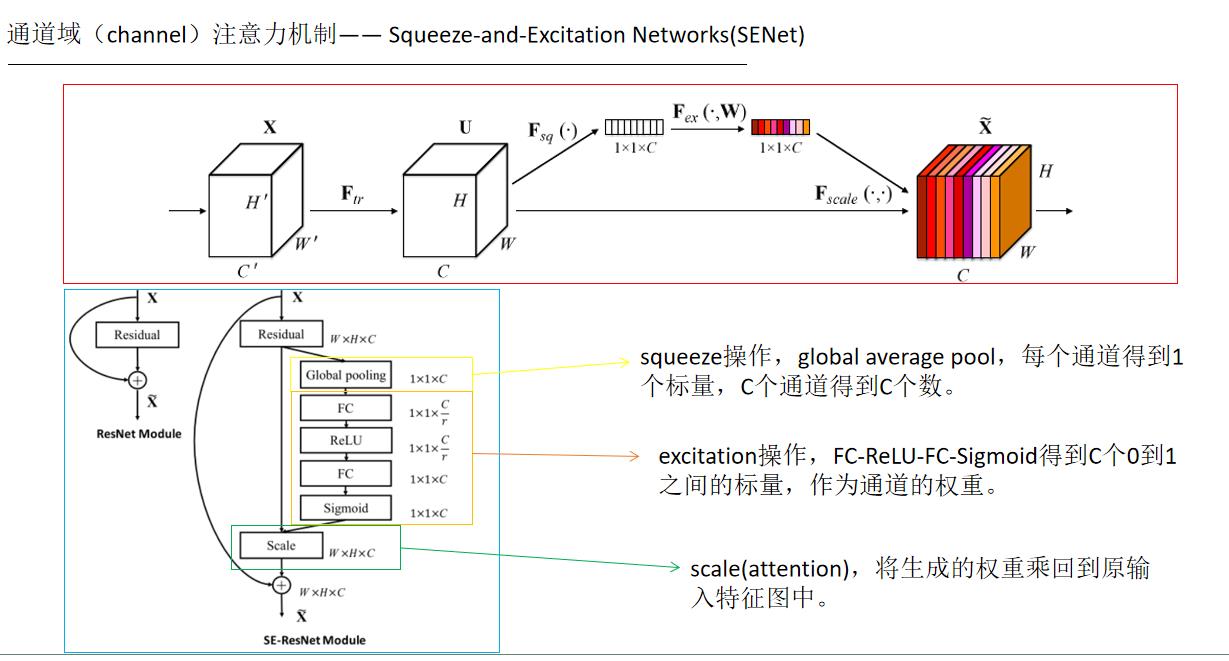
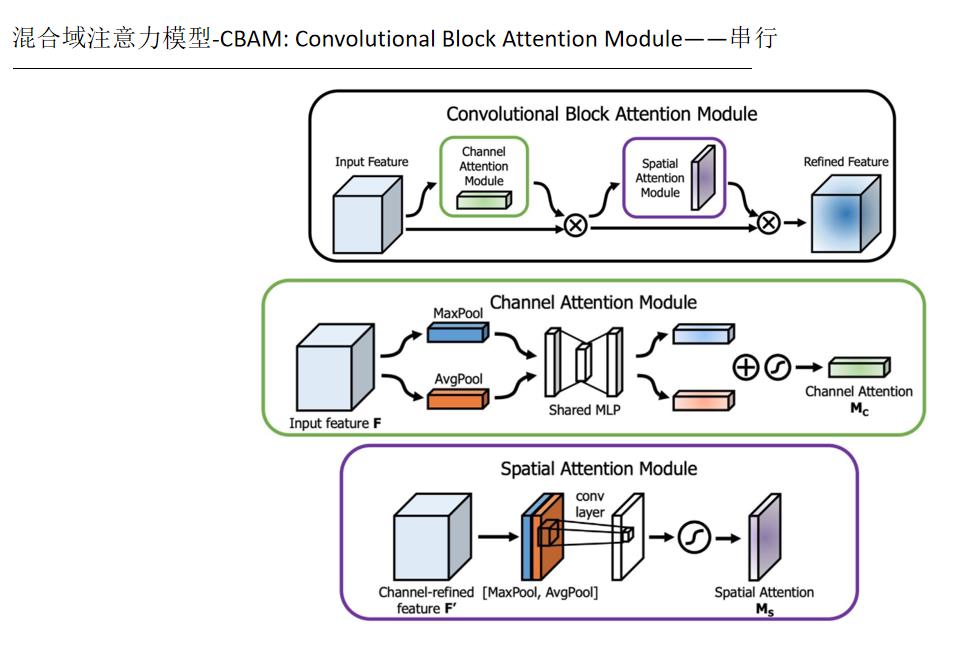

参考文章:
[HSI论文阅读] | HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification
《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》论文阅读
四、《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
1.原文地址
2.代码
3.论文解读
- 强调了residual learning(残差学习)和batch normalization(批量标准化)在图像复原中相辅相成的作用,可以在较深的网络的条件下,依然能带来快的收敛和好的性能。
- 文章提出DnCNN,在高斯去噪问题下,用单模型应对不同程度的高斯噪音;甚至可以用单模型应对高斯去噪、超分辨率、JPEG去锁三个领域的问题。
参考文章:
<
以上是关于第五周作业:卷积神经网络(Part3)的主要内容,如果未能解决你的问题,请参考以下文章