ElasticSearch实战(四十一)-存储桶聚合
Posted 张志翔ۤ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch实战(四十一)-存储桶聚合相关的知识,希望对你有一定的参考价值。
Elasticsearch除了在搜索方面非常之快,对数据分析也是非常重要的一面。正确理解Bucket aggregation对我们使用Kibana非常重要。Elasticsearch提供了非常多的aggregation可以供我们使用。其中Bucket aggregation对于初学者来说也是比较不容易理解的一个。在今天的这篇文章中,我来重点讲述这个。
简单地说:一个桶代表一个具有共同标准的文档集合。存储桶(bucket)是聚合的关键要素。比如,我们想分析每个月的log流量:
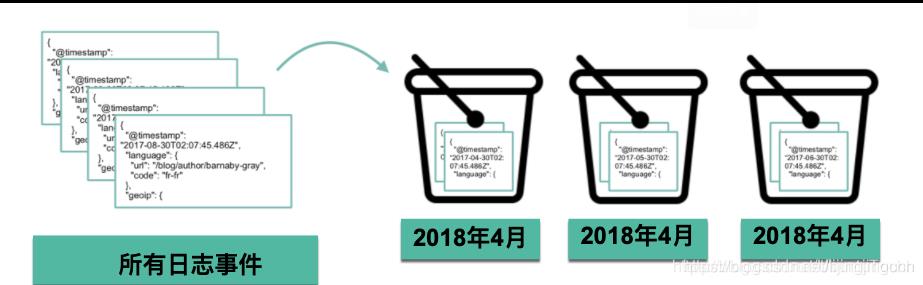
桶聚合(bucket aggregation)不像指标聚合(Metric aggregation)那样计算字段的指标,而是创建文档存储桶。 每个存储桶都与一个标准(取决于聚合类型)相关联,该标准确定当前上下文中的文档是否“落入”其中。 换句话说,存储桶有效地定义了文档集。 除了存储桶本身之外,存储桶聚合还计算并返回落入每个存储桶的文档数量。
与指标聚合相反,存储桶聚合可以保存子聚合。 这些子聚合将针对其“父”存储桶聚合创建
以上是关于ElasticSearch实战(四十一)-存储桶聚合的主要内容,如果未能解决你的问题,请参考以下文章
ElasticSearch实战(四十二)-数据离线同步技术选型
ElasticSearch实战(四十二)-数据离线同步技术选型
四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作增删改查
Android项目实战(四十一):游戏和视频类型应用 状态栏沉浸式效果