四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作增删改查
Posted 快乐糖果屋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作增删改查相关的知识,希望对你有一定的参考价值。
elasticsearch(搜索引擎)基本的索引和文档CRUD操作
也就是基本的索引和文档、增、删、改、查、操作
注意:以下操作都是在kibana里操作的
elasticsearch(搜索引擎)都是基于http方法来操作的
GET 请求指定的页面信息,并且返回实体主体
POST 向指定资源提交数据进行处理请求,数据被包含在请求体中,POST请求可能会导致新的资源的建立和/或已有资源的修改
PUT 向服务器传送的数据取代指定的文档的内容
DELETE 请求服务器删除指定的页面

1、索引初始化,相当于创建一个数据库
用kibana创建
代码说明

# 初始化索引(也就是创建数据库)
# PUT 索引名称
"""
PUT jobbole #设置索引名称
{
"settings": { #设置
"index": { #索引
"number_of_shards":5, #设置分片数
"number_of_replicas":1 #设置副本数
}
}
}
"""
代码
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}

我们也可以使用可视化根据创建索引
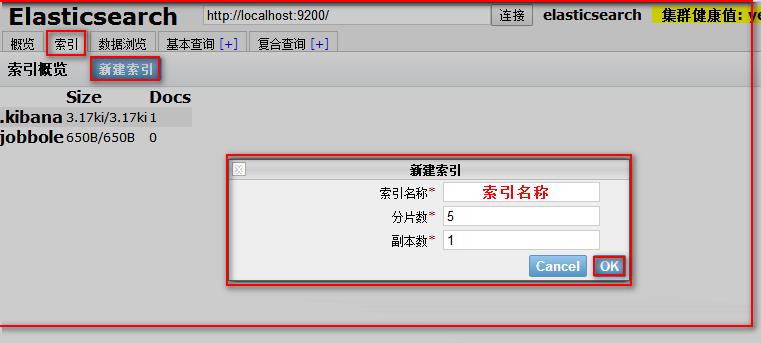
注意:索引一旦创建,分片数量不可修改,副本数量可以修改的
2、获取索引的settings(设置信息)
GET 索引名称/_settings 获取指定索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
#获取指定索引的settings(设置信息)
GET jobbole/_settings
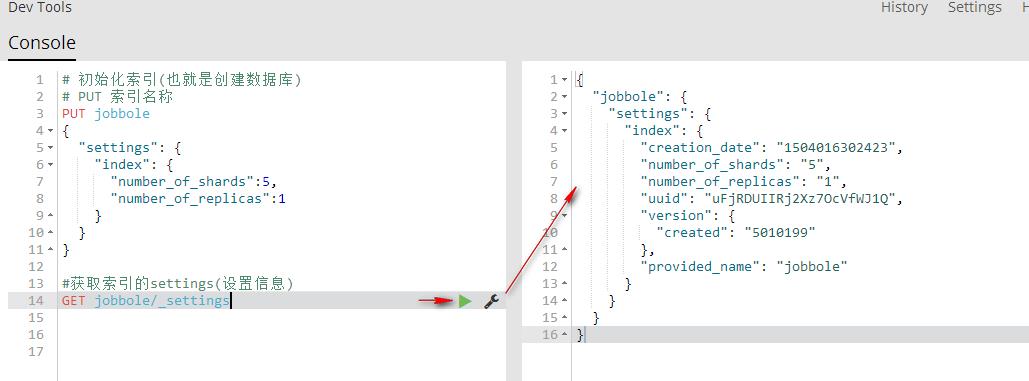
GET _all/_settings 获取所有索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
#获取索引的settings(设置信息)
#GET jobbole/_settings
#获取所有索引的settings(设置信息)
GET _all/_settings
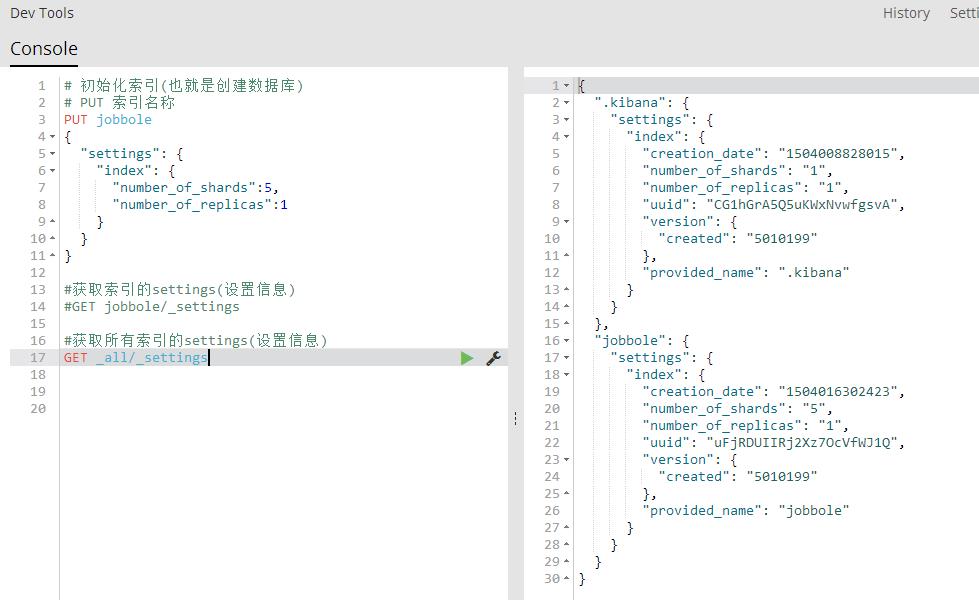
GET .索引名称,索引名称/_settings 获取多个索引的settings(设置信息)
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
#获取索引的settings(设置信息)
#GET jobbole/_settings
#获取所有索引的settings(设置信息)
#GET _all/_settings
GET .kibana,jobbole/_settings

3、更新索引的settings(设置信息)
PUT 索引名称/_settings 更新指定索引的设置信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
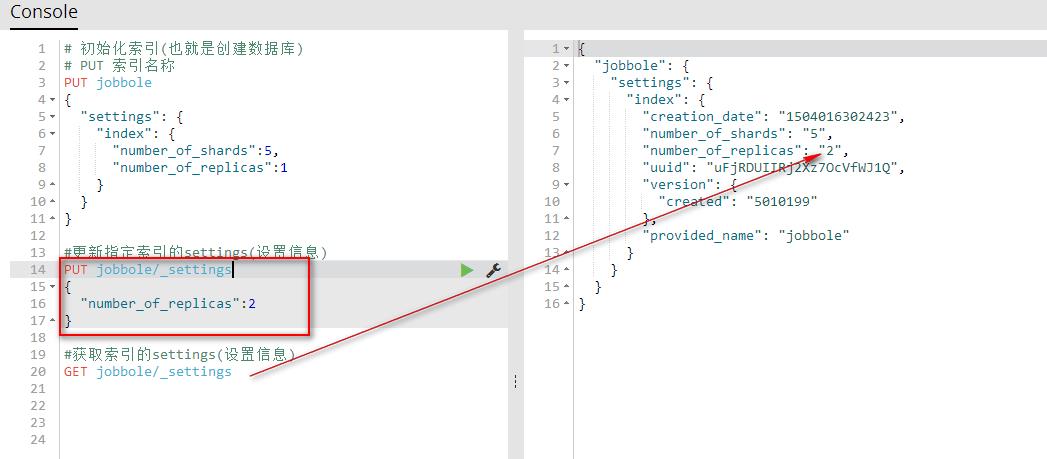
#更新指定索引的settings(设置信息)
PUT jobbole/_settings
{
"number_of_replicas":2
}
#获取索引的settings(设置信息)
GET jobbole/_settings
4、获取索引的(索引信息)
GET _all 获取所有索引的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
#获取索引的settings(设置信息)
#GET jobbole/_settings
GET _all
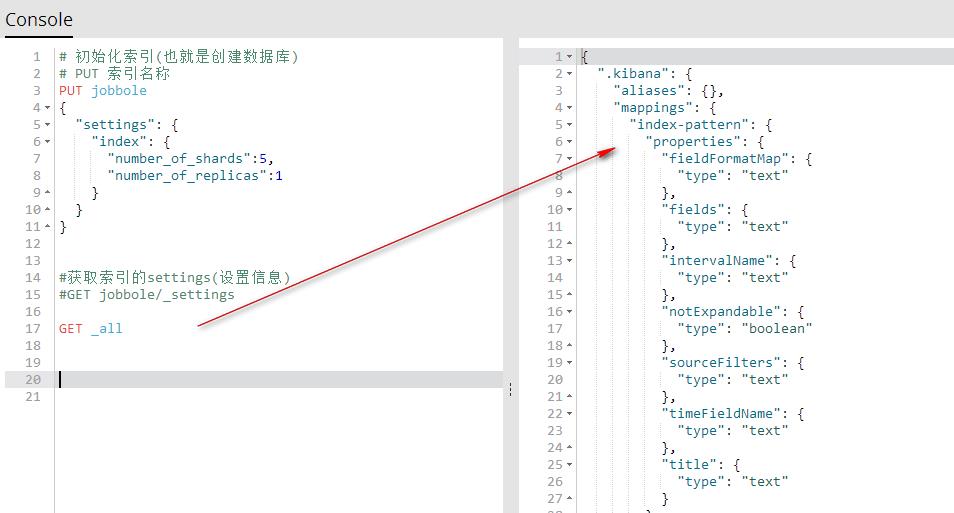
GET 索引名称 获取指定的索引信息
# 初始化索引(也就是创建数据库)
# PUT 索引名称
PUT jobbole
{
"settings": {
"index": {
"number_of_shards":5,
"number_of_replicas":1
}
}
}
#获取索引的settings(设置信息)
#GET jobbole/_settings
#GET _all
GET jobbole
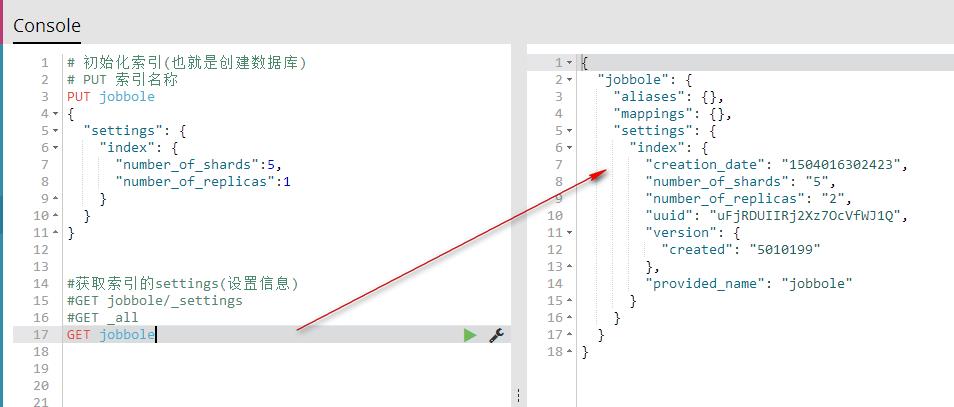
5、保存文档(相当于数据库的写入数据)
PUT index(索引名称)/type(相当于表名称)/1(相当于id){字段:值} 保存文档自定义id(相当于数据库的写入数据)
#保存文档(相当于数据库的写入数据)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}
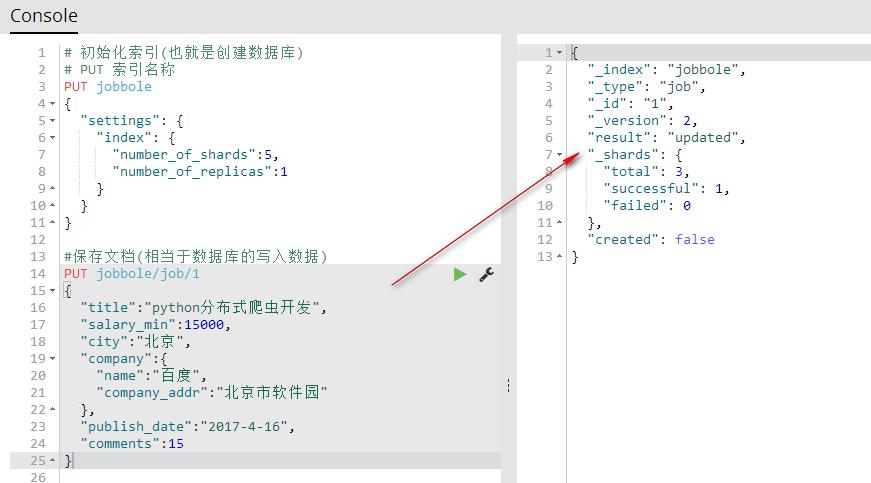
可视化查看

POST index(索引名称)/type(相当于表名称)/{字段:值} 保存文档自动生成id(相当于数据库的写入数据)
注意:自动生成id需要用POST方法
#保存文档(相当于数据库的写入数据)
POST jobbole/job
{
"title":"html开发",
"salary_min":15000,
"city":"上海",
"company":{
"name":"微软",
"company_addr":"上海市软件园"
},
"publish_date":"2017-4-16",
"comments":15
}

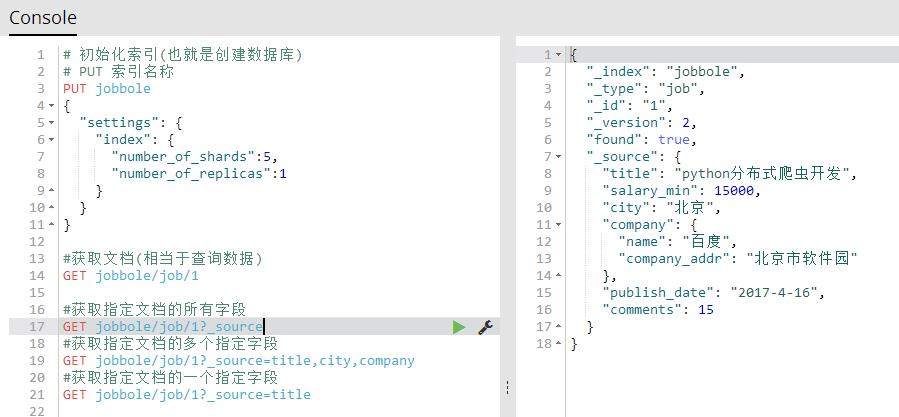
6、获取文档(相当于查询数据)
GET 索引名称/表名称/id 获取指定的文档所有信息
#获取文档(相当于查询数据) GET jobbole/job/1
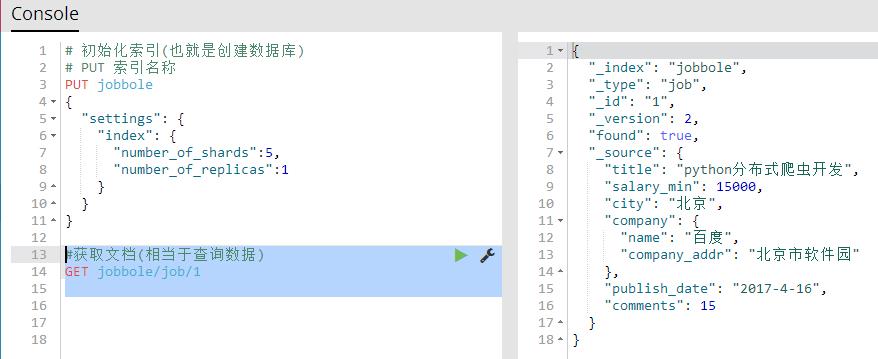
GET 索引名称/表名称/id?_source 获取指定文档的所有字段
GET 索引名称/表名称/id?_source=字段名称,字段名称,字段名称 获取指定文档的多个指定字段
GET 索引名称/表名称/id?_source=字段名称 获取指定文档的一个指定字段
#获取指定文档的所有字段 GET jobbole/job/1?_source #获取指定文档的多个指定字段 GET jobbole/job/1?_source=title,city,company #获取指定文档的一个指定字段 GET jobbole/job/1?_source=title
7、修改文档(相当于修改数据)
修改文档(用保存文档的方式,进行覆盖来修改文档)原有数据全部被覆盖
#修改文档(用保存文档的方式,进行覆盖来修改文档)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园"
},
"publish_date":"2017-4-16",
"comments":20
}
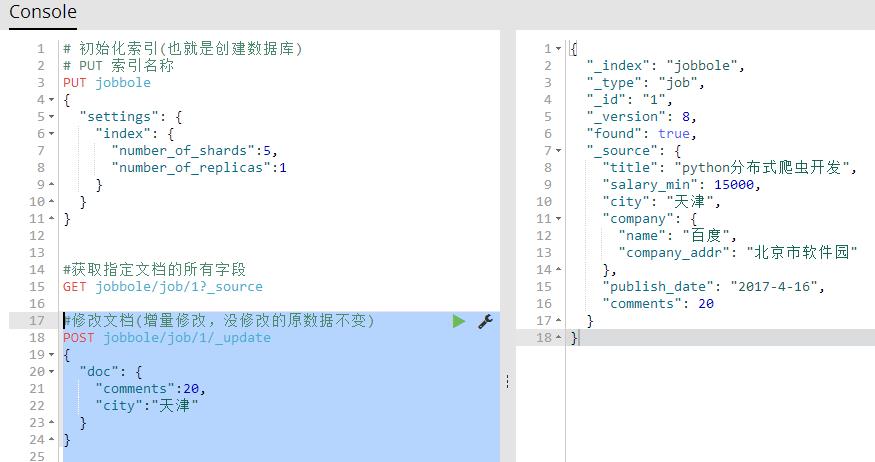
修改文档(增量修改,没修改的原数据不变)【推荐】
POST 索引名称/表/id/_update
{
"doc": {
"字段":值,
"字段":值
}
}
#修改文档(增量修改,没修改的原数据不变)
POST jobbole/job/1/_update
{
"doc": {
"comments":20,
"city":"天津"
}
}
8、删除索引,删除文档
DELETE 索引名称/表/id 删除索引里的一个指定文档
DELETE 索引名称 删除一个指定索引
#删除索引里的一个指定文档 DELETE jobbole/job/1 #删除一个指定索引 DELETE jobbole
以上是关于四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作增删改查的主要内容,如果未能解决你的问题,请参考以下文章
第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略
第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
四十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能