MySQL 是如何实现 ACID 的?
Posted Java技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 是如何实现 ACID 的?相关的知识,希望对你有一定的参考价值。
点击关注公众号,Java干货及时送达
来源:https://llc687.top/131.html
本文主要探讨mysql InnoDB 引擎下ACID的实现原理,对于诸如什么是事务,隔离级别的含义等基础知识不做过多阐述。
ACID
MySQL 作为一个关系型数据库,以最常见的 InnoDB 引擎来说,是如何保证 ACID 的。
(Atomicity)原子性: 事务是最小的执行单位,不允许分割。原子性确保动作要么全部完成,要么完全不起作用;
(Consistency)一致性: 执行事务前后,数据保持一致;
(Isolation)隔离性: 并发访问数据库时,一个事务不被其他事务所干扰。
(Durability)持久性: 一个事务被提交之后。对数据库中数据的改变是持久的,即使数据库发生故障。
隔离性
先说说隔离性,首先是四种隔离级别。
| 隔离级别 | 说明 |
|---|---|
| 读未提交 | 一个事务还没提交时,它做的变更就能被别的事务看到 |
| 读提交 | 一个事务提交之后,它做的变更才会被其他事务看到 |
| 可重复读 | 一个事务中,对同一份数据的读取结果总是相同的,无论是否有其他事务对这份数据进行操作,以及这个事务是否提交。InnoDB默认级别。 |
| 串行化 | 事务串行化执行,每次读都需要获得表级共享锁,读写相互都会阻塞,隔离级别最高,牺牲系统并发性。 |
不同的隔离级别是为了解决不同的问题。也就是脏读、幻读、不可重复读。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可以出现 | 可以出现 | 可以出现 |
| 读提交 | 不允许出现 | 可以出现 | 可以出现 |
| 可重复读 | 不允许出现 | 不允许出现 | 可以出现 |
| 序列化 | 不允许出现 | 不允许出现 | 不允许出现 |
那么不同的隔离级别,隔离性是如何实现的,为什么不同事物间能够互不干扰?答案是 锁 和 MVCC。
锁
先来说说锁, MySQL 有多少锁。
粒度
从粒度上来说就是表锁、页锁、行锁。表锁有意向共享锁、意向排他锁、自增锁等。行锁是在引擎层由各个引擎自己实现的。但并不是所有的引擎都支持行锁,比如 MyISAM 引擎就不支持行锁。
行锁的种类
在 InnoDB 事务中,行锁通过给索引上的索引项加锁来实现。这意味着只有通过索引条件检索数据,InnoDB才使用行级锁,否则将使用表锁。行级锁定同样分为两种类型:共享锁和排他锁,以及加锁前需要先获得的意向共享锁和意向排他锁。
共享锁:读锁,允许其他事务再加S锁,不允许其他事务再加X锁,即其他事务只读不可写。
select...lock in share mode加锁。排它锁:写锁,不允许其他事务再加S锁或者X锁。
insert、update、delete、for update加锁。
行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
行锁的实现算法
Record Lock
单个行记录上的锁,总是会去锁住索引记录。
Gap Lock
间隙锁,想一下幻读的原因,其实就是行锁只能锁住行,但新插入记录这个动作,要更新的是记录之间的“间隙”。所以加入间隙锁来解决幻读。
Next-Key Lock
Gap Lock + Record Lock, 左开又闭。
锁之于隔离性
大致介绍了下锁,可以看到。有了锁,当某事务正在写数据时,其他事务获取不到写锁,就无法写数据,一定程度上保证了事务间的隔离。但前面说,加了写锁,为什么其他事务也能读数据呢,不是获取不到读锁吗?
MVCC
前面说到,有了锁,当前事务没有写锁就不能修改数据,但还是能读的,而且读的时候,即使该行数据其他事务已修改且提交,还是可以重复读到同样的值。这就是MVCC,多版本的并发控制,Multi-Version Concurrency Control。
版本链
Innodb 中行记录的存储格式,有一些额外的字段:DATA_TRX_ID和DATA_ROLL_PTR。
DATA_TRX_ID:数据行版本号。用来标识最近对本行记录做修改的事务 id。
DATA_ROLL_PTR:指向该行回滚段的指针。该行记录上所有旧版本,在
undo log中都通过链表的形式组织。
undo log : 记录数据被修改之前的日志,后面会详细说。
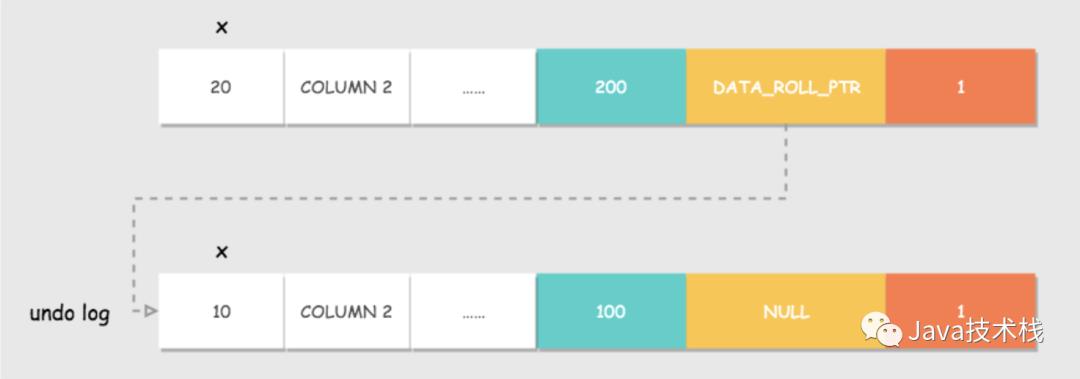
ReadView
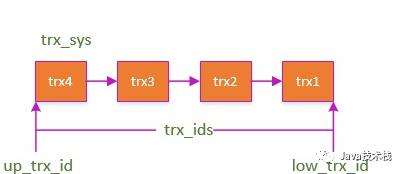
在每一条 SQL 开始的时候被创建,有几个重要属性:
trx_ids: 当前系统活跃(未提交)事务版本号集合。
low_limit_id: 创建当前 read view 时“当前系统最大事务版本号+1”。
up_limit_id: 创建当前read view 时“系统正处于活跃事务最小版本号”
creator_trx_id: 创建当前read view的事务版本号;
开始查询
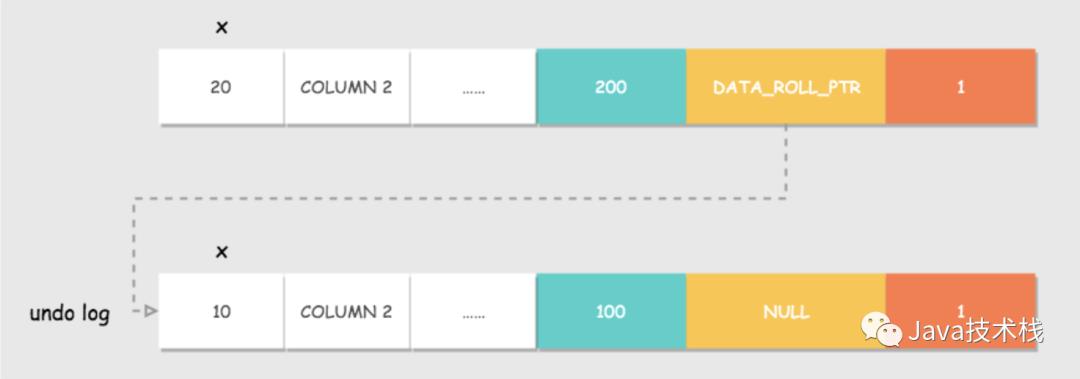
现在开始查询,一个 select 过来了,找到了一行数据。
DATA_TRX_ID <up_limit_id :说明数据在当前事务之前就存在了,显示。
DATA_TRX_ID >= low_limit_id:
说明该数据是在当前read view 创建后才产生的,数据不显示。
不显示怎么办,根据 DATA_ROLL_PTR 从 undo log 中找到历史版本,找不到就空。
up_limit_id <DATA_TRX_ID <low_limit_id :就要看隔离级别了。
点击关注公众号,Java干货及时送达
RR 级别的幻读
有了锁和 MVCC , 事务的隔离性得到解决。这里要引申一下,默认的 RR 的级别,解决了幻读吗?幻读通常针对的是 INSERT, 不可重复度则针对 UPDATE 。
| 事物 1 | 事物 2 |
|---|---|
| begin | begin |
| select * from dept | |
| - | insert into dept(name) values("A") |
| - | commit |
| update dept set name="B" | |
| commit |
我们期望是
id name
1 A
2 B实际却是
id name
1 B
2 B其实在 MySQL 可重复读的隔离级别中并不是完全解决了幻读的问题,而是解决了读数据情况下的幻读问题。而对于修改的操作依旧存在幻读问题,就是说 MVCC 对于幻读的解决时不彻底的。另外,MySQL 系列面试题和答案全部整理好了,微信搜索Java技术栈,在后台发送:面试,可以在线阅读。
原子性
接着说说原子性。前文有提到 undo log ,回滚日志。隔离性的MVCC其实就是依靠它来实现的,原子性也是。实现原子性的关键,是当事务回滚时能够撤销所有已经成功执行的sql语句。
最新 Java 核心技术推荐:https://github.com/javastacks/javastack
当事务对数据库进行修改时,InnoDB会生成对应的 undo log;如果事务执行失败或调用了 rollback,导致事务需要回滚,便可以利用 undo log 中的信息将数据回滚到修改之前的样子。undo log 属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB 会根据 undo log 的内容做与之前相反的工作:
对于每个 insert,回滚时会执行 delete;
对于每个 delete,回滚时会执行insert;
对于每个 update,回滚时会执行一个相反的 update,把数据改回去。
以update操作为例:当事务执行update时,其生成的undo log中会包含被修改行的主键(以便知道修改了哪些行)、修改了哪些列、这些列在修改前后的值等信息,回滚时便可以使用这些信息将数据还原到update之前的状态。
持久性
Innnodb有很多 log,持久性靠的是 redo log。
一条SQL更新语句怎么运行
持久性肯定和写有关,MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘。就像小店做生意,有个粉板,有个账本,来客了先写粉板,等不忙的时候再写账本。点击在线刷题,看看你可以打多少分了。
redo log
redo log 就是这个粉板,当有一条记录要更新时,InnoDB 引擎就会先把记录写到 redo log(并更新内存),这个时候更新就算完成了。在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,这就像打烊以后掌柜做的事。
redo log 有两个特点:
大小固定,循环写
crash-safe
对于redo log 是有两阶段的:commit 和 prepare 如果不使用“两阶段提交”,数据库的状态就有可能和用它的日志恢复出来的库的状态不一致. 好了,先到这里,看看另一个。
Buffer Pool
InnoDB还提供了缓存,Buffer Pool 中包含了磁盘中部分数据页的映射,作为访问数据库的缓冲:
当读取数据时,会先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool;
当向数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中。
Buffer Pool 的使用大大提高了读写数据的效率,但是也带了新的问题:如果MySQL宕机,而此时 Buffer Pool 中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。
所以加入了 redo log。当数据修改时,除了修改Buffer Pool中的数据,还会在redo log记录这次操作;
当事务提交时,会调用fsync接口对redo log进行刷盘。
如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。
redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool,保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。而且这样做还有两个优点:
刷脏页是随机 IO,redo log 顺序 IO
刷脏页以Page为单位,一个Page上的修改整页都要写;而redo log 只包含真正需要写入的,无效 IO 减少。
binlog
说到这,可能会疑问还有个 bin log 也是写操作并用于数据的恢复,有啥区别呢。
binlog 和 redo log
对于语句 update T set c=c+1 where ID=2;
执行器先找引擎取 ID=2 这一行。ID 是主键,直接用树搜索找到。如果 ID = 2 这一行所在数据页就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,再返回。
引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
为什么先写 redo log 呢 ?
先 redo 后 bin : binlog 丢失,少了一次更新,恢复后仍是0。
先 bin 后 redo : 多了一次事务,恢复后是1。
一致性
一致性是事务追求的最终目标,前问所诉的原子性、持久性和隔离性,其实都是为了保证数据库状态的一致性。当然,上文都是数据库层面的保障,一致性的实现也需要应用层面进行保障。
也就是你的业务,比如购买操作只扣除用户的余额,不减库存,肯定无法保证状态的一致。
总结
MySQL 都很熟, ACID 也知道是个啥,但 MySQL 的 ACID 怎么实现的?
有时候,就像你知道了有 undo log、redo log 但可能并不太清楚为什么有,当知道了设计的目的,了解起来就会更加清晰了。另外,关注公众号Java技术栈,在后台回复:面试,可以获取我整理的 Java/ MySQL 系列面试题和答案,非常齐全。
参考:
https://zhuanlan.zhihu.com/p/52977862
https://learnku.com/articles/39212
https://www.cnblogs.com/rjzheng/p/10841031.html
https://www.cnblogs.com/kismetv/p/10331633.html







关注Java技术栈看更多干货


获取 Spring Boot 实战笔记!
以上是关于MySQL 是如何实现 ACID 的?的主要内容,如果未能解决你的问题,请参考以下文章