一文看懂NLP预训练模型前世今生
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文看懂NLP预训练模型前世今生相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :量子位
搞出了全球最大预训练模型的悟道团队,现在来手把手地教你怎么弄懂预训练这一概念了。
刚刚,清华唐杰教授联合悟道团队发布了一篇有关预训练模型的综述:

整篇论文超过40页,从发展历史、最新突破和未来研究三个方向,完整地梳理了大规模预训练模型(PTM)的前世今生。

现在就一起来看看这篇论文的主要内容吧。
预训练的历史
论文首先从预训练的发展过程开始讲起。

早期预训练的工作主要集中在迁移学习上,其中特征迁移和参数迁移是两种最为广泛的预训练方法。
从早期的有监督预训练到当前的自监督预训练,将基于Transformer的PTM作用于NLP任务已经成为了一种标准流程。
可以说,最近PTM在多种工作上的成功,就得益于自监督预训练和Transformer的结合。
这也就是论文第3节的主要内容:
神经架构Transformer,以及两个基于Transformer的里程碑式的预训练模型:BERT和GPT。

两个模型分别使用自回归语言建模和自编码语言建模作为预训练目标。
后续所有的预训练模型可以说都是这两个模型的变种。
例如论文中展示的这张图,就列出了近年修改了模型架构,并探索了新的预训练任务的诸多PTM:
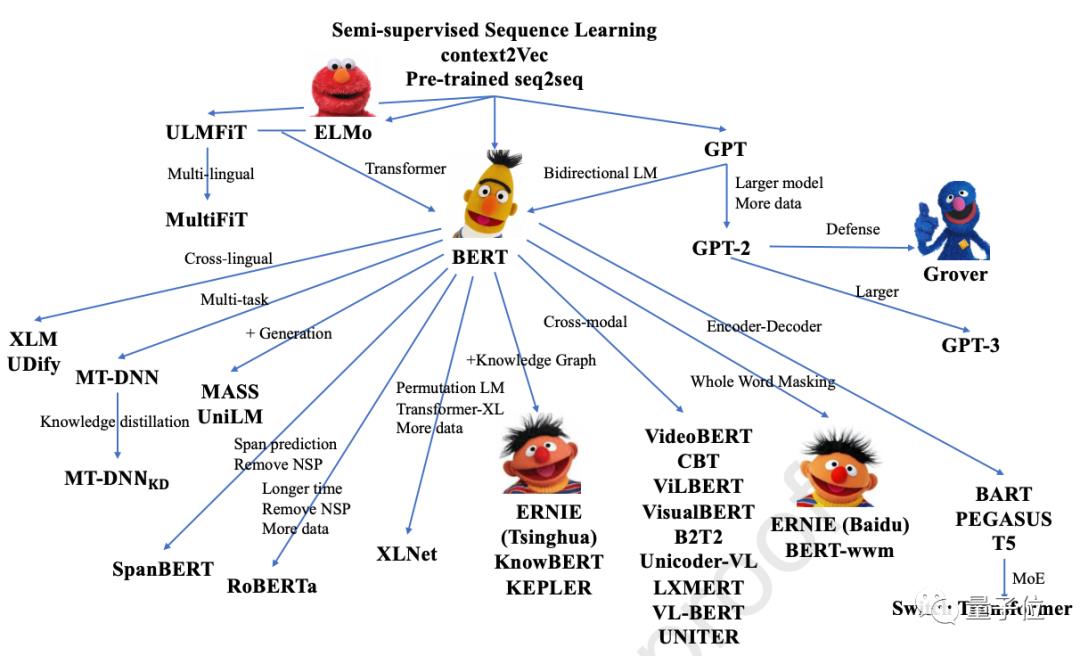
大规模预训练模型的最新突破
论文的4-7节则全面地回顾了PTM的最新突破。
这些突破主要由激增的算力和越来越多的数据驱动,朝着以下四个方向发展:
设计有效架构
在第4节中,论文深入地探究了BERT家族及其变体PTM,并提到,所有用于语言预训练的基于Transformer的BERT架构都可被归类为两个动机:
统一序列建模
认知启发架构
除此以外,当前大多数研究都专注于优化BERT架构,以提高语言模型在自然语言理解方面的性能。
利用多源数据
很多典型PTM都利用了数据持有方、类型、特征各不相同的多源异构数据。
比如多语言PTM、多模态PTM和知识(Knowledge)增强型PTM。
提高计算效率
第6节从三个方面介绍了如何提升计算效率。
第一种方法是系统级优化,包括单设备优化和多设备优化。
比如说像是ZeRO-Offload,就设计了精细的策略来安排CPU内存和GPU内存之间的交换,以便内存交换和设备计算能够尽可能多地重叠。
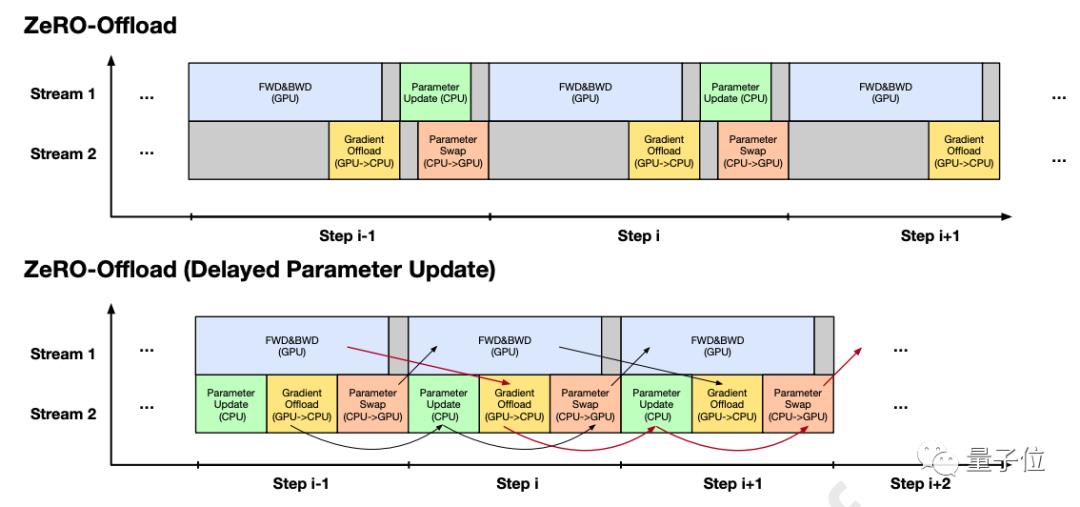
第二种方法是探索更高效的预训练方法和模型架构,以降低方案的成本。
第三种则是模型压缩策略,包括参数共享、模型剪枝、知识蒸馏和模型量化。
解释和理论分析
对于PTM的工作原理和特性,论文在第7节做了详细的解读。
首先是PTM所捕获的两类隐性知识:
一种是语言知识,一般通过表征探测、表示分析、注意力分析、生成分析四种方法进行研究。
另一种是包括常识和事实在内的世界知识。
随后论文也指出,在最近相关工作的对抗性示例中,PTM展现出了严重的鲁棒性问题,即容易被同义词所误导,从而做出错误预测。
最后,论文总结了PTM的结构稀疏性/模块性,以及PTM理论分析方面的开创性工作。
未来的研究方向
到现在,论文已经回顾了PTM的过去与现在,最后一节则基于上文提到的各种工作,指出了PTM未来可以进一步发展的7个方向:
架构和预训练方法
包括新架构、新的预训练任务、Prompt Tuning、可靠性
多语言和多模态训练
包括更多的模态、解释、下游任务,以及迁移学习
计算效率
包括数据迁移、并行策略、大规模训练、封装和插件
理论基础
包括不确定性、泛化和鲁棒性
模识(Modeledge)学习
包括基于知识感知的任务、模识的储存和管理
认知和知识学习
包括知识增强、知识支持、知识监督、认知架构、知识的互相作用
应用
包括自然语言生成、对话系统、特定领域的PTM、领域自适应和任务自适应
论文最后也提到,和以自然语言形式,即离散符号表现的人类知识不同,储存在PTM中的知识是一种对机器友好的,连续的实值向量。
团队将这种知识命名为模识,希望未来能以一种更有效的方式捕捉模识,为特定任务寻找更好的解决方案。
更多细节可点击直达原论文:
http://keg.cs.tsinghua.edu.cn/jietang/publications/AIOPEN21-Han-et-al-Pre-Trained%20Models-%20Past,%20Present%20and%20Future.pdf
参考链接:
https://m.weibo.cn/status/4678571136388064
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于一文看懂NLP预训练模型前世今生的主要内容,如果未能解决你的问题,请参考以下文章
最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型