李宏毅机器学习回归
Posted 7TribeZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李宏毅机器学习回归相关的知识,希望对你有一定的参考价值。
1. Function with Unknown Parameters
第一个步骤是我们要写出一个,带有未知参数的函式,简单来说就是 我们先猜测一下,我们打算找的这个函式F,它的数学式到底长什麼样子。举例来说,我们这边先做一个最初步的猜测,我们写成这个样子
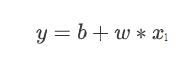
2. Define Loss from Training Data
第二个步骤,是我们要定义一个东西叫做Loss,Loss它也是一个Function,那这个Function它的输入,是我们Model裡面的参数,我们的Model叫做,
ₗ
,而跟是未知的,是我们準备要找出来的,所谓的这个Loss啊,它是一个Function,这个Function的输入,就是跟,所以L它是一个Function,它的输入是Parameter,是model裡面的Parameter,那这个Loss 这个Function,这个Function输出的值代表说,现在如果我们把这一组未知的参数,设定某一个数值的时候,这笔数值好还是不好。

3. Optimization
接下来我们进入机器学习的第三步,那第三步要做的事情,其实是解一个最佳化的问题,如果你不知道最佳化的问题,是什麼的话也没有关係,我们今天要做的事情就是,找一个w跟b,把未知的参数,找一个数值出来,看代那一个数值进去,可以让我们的大L,让我们的Loss的值最小,那个就是我们要找的w跟b,那这个可以让loss最小的w跟b,我们就叫做 跟 代表说他们是最好的一组w跟b,可以让loss的值最小.
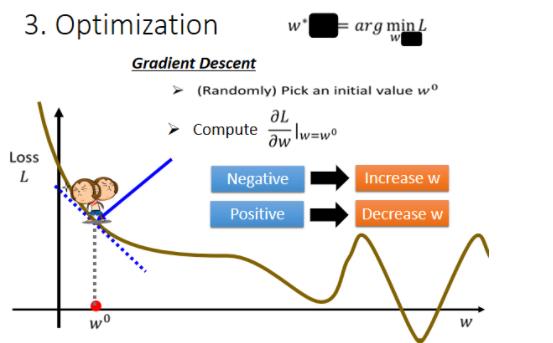
那怎麼样找一个w,去让这个loss的值最小呢?
那首先你要随机选取一个初始的点,那这个初始的点,我们叫做
₀
,那这个初始的点往往真的就是随机的,那在往后的课程裡面,我们其实会看到也许有一些方法,可以给我们一个比较好的w零的值.我们先当作都是随机的,那假设我们随机决定的结果,是在w0这个地方。
那接下来你就要计算,在w等於w0的时候,w这个参数对loss的微分是多少,如果你不知道微分是什麼的话,那没有关係反正我们做的事情就是,计算在这一个点,在w₀这个位置的error surface的切线斜率,也就是这一条蓝色的虚线,它的斜率,那如果这一条虚线的斜率是负的,那代表什麼意思呢,代表说左边比较高 右边比较低,在这个位置附近,左边比较高 右边比较低。
那如果左边比较高右边比较低的话,我们就把w的值变大,那我们就可以让loss变小,如果算出来的斜率是正的,就代表说左边比较低右边比较高,是这个样子的,左边比较低右边比较高,如果左边比较低 右边比较高的话,那就代表我们把w变小了,w往左边移 我们可以让Loss的值变小,那这个时候你就应该把w的值变小,那假设你连斜率是什麼都不知道的话,也没有关係,你就想像说有一个人站在这个地方,然后他左右环视一下,那这一个算微分这件事啊,就是左右环视,它会知道左边比较高还是右边比较高,看哪边比较低,它就往比较低的地方跨出一步,
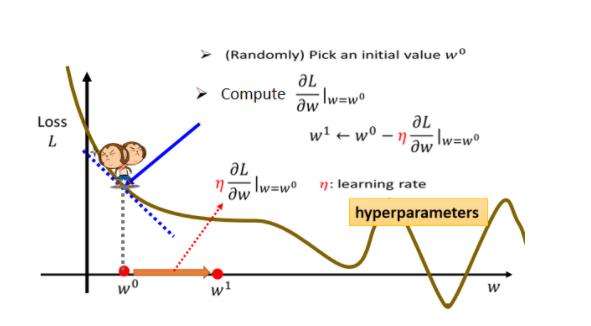
那这一步要跨多大呢,这一步的步伐的大小取决於两件事情,
第一件事情是这个地方的斜率有多大,这个地方的斜率大,这个步伐就跨大一点,斜率小步伐就跨小一点,
另外 除了斜率以外,就是除了微分这一项,还有另外一个东西会影响步伐大小,这个东西我们这边用来表示,这个叫做learning rate,叫做学习速率,这个learning rate 它是怎麼来的呢,它是你自己设定的,你自己决定这个的大小,如果设大一点,那你每次参数update就会量大,你的学习可能就比较快,如果η设小一点,那你参数的update就很慢,每次只会改变一点点参数的数值,那这种你在做机器学习,需要自己设定的东西,叫做hyperparameters
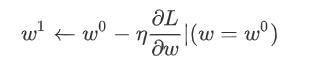
总结

Pokemon:原始的CP值极大程度的决定了进化后的CP值,但可能还有其他的一些因素。
Gradient descent:梯度下降的做法;后面会讲到它的理论依据和要点。
Overfitting和Regularization:过拟合和正则化,主要介绍了表象;后面会讲到更多这方面的理论
以上是关于李宏毅机器学习回归的主要内容,如果未能解决你的问题,请参考以下文章