Web漏洞扫描这件事爬虫
Posted 南瓜__pumpkin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Web漏洞扫描这件事爬虫相关的知识,希望对你有一定的参考价值。
面对一个Web系统,脚本fuzz的对象是一个个 url 。
面对一个 ip 或者 域名,第一步要做的是获取这个 Web 系统的所有 url ,用到爬虫技术。
burpsuite 有爬虫模块,先学习一下。
测试靶场使用 DVWA 。
burpsuite爬虫
burpsuite2.0 抓包,把请求发送到 Repeater,发现已经有了该 Web 系统的网站地图 Site map,但基本没有进行访问(没有访问状态码)
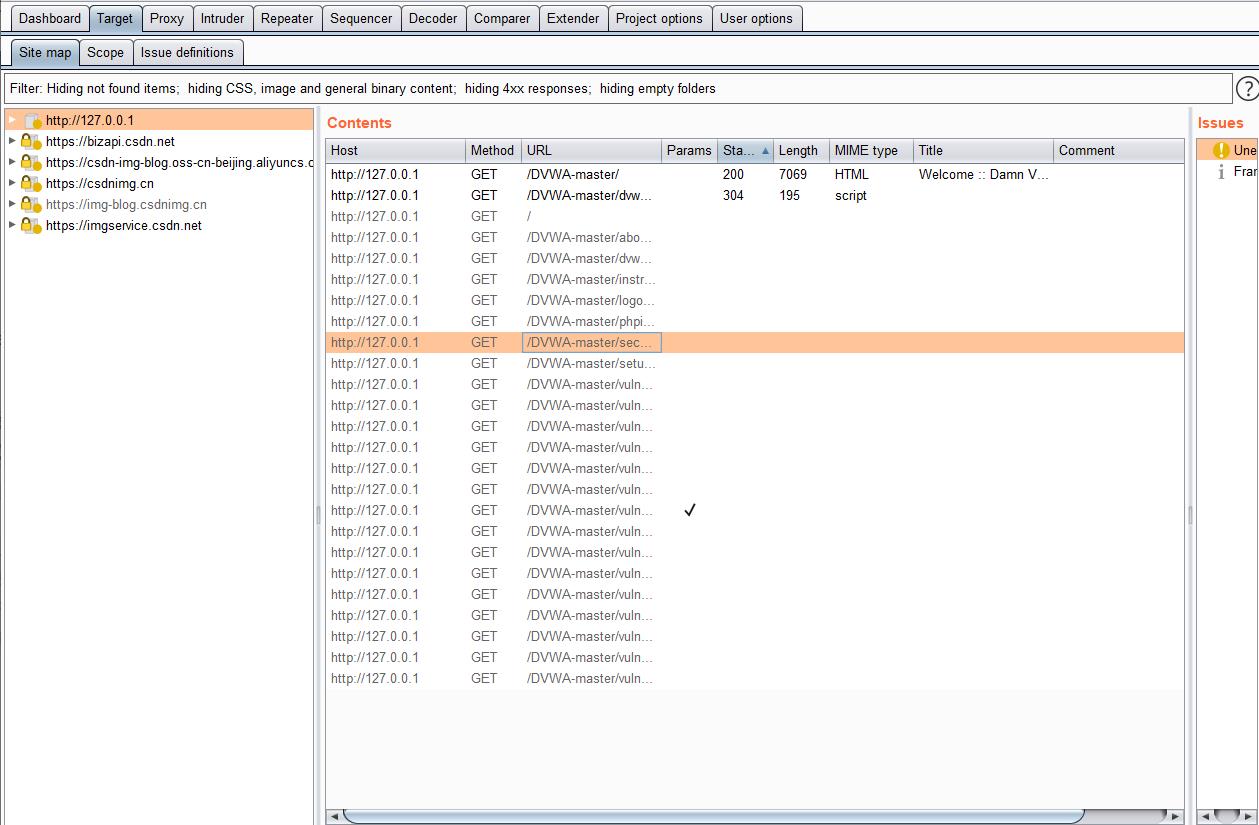
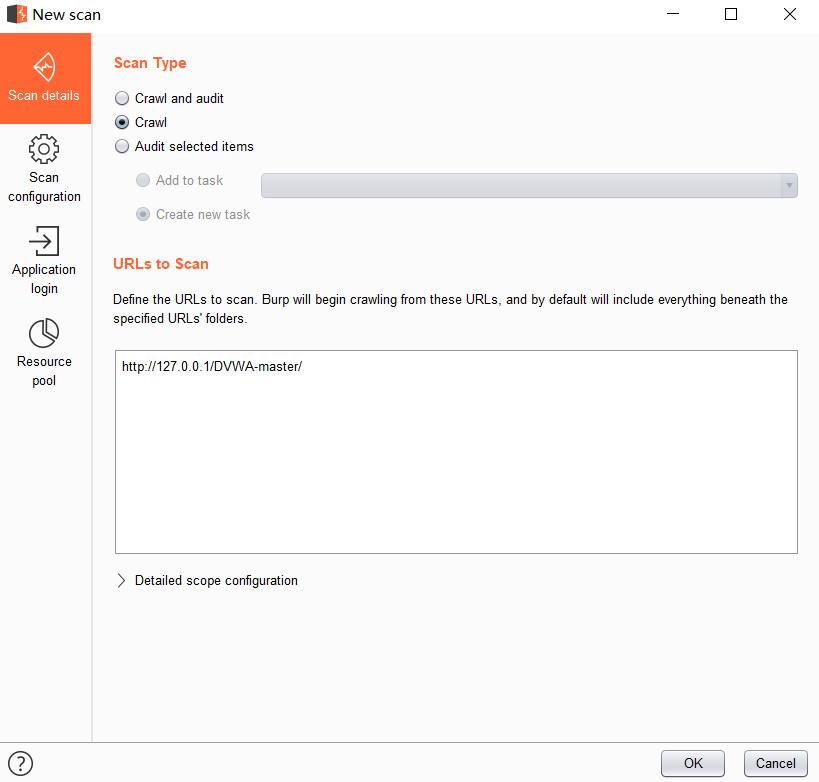
Repeater模块右键选择 scan-Crawl ,创建任务
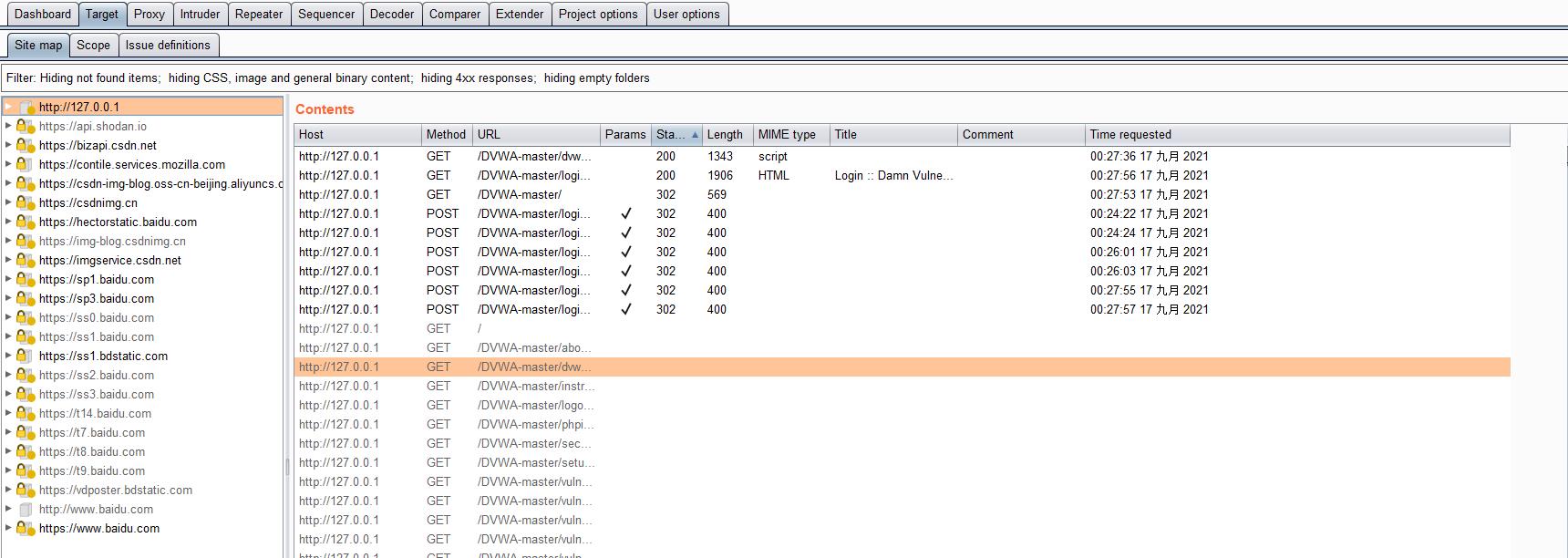
执行扫描任务后查看网站地图 SiteMap,发现爬虫一直被302重定向到登录页面,说明默认情况下 burpsuite 的爬虫是不带状态的,没有使用请求包里的 cookie 信息。gg
爬虫框架和爬虫算法
百度搜索 SiteMap ,看到爬虫框架 Scrapy ,顺藤摸瓜查看相关框架文章:Scrapy爬虫入门教程,爬虫的各种框架对比、8个Python爬虫框架。
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。而我们需要的爬虫,返回结果只需要是如下模式:url-参数方式-参数-标题-状态码 ,不需要提取过多的数据。
值得注意,点击式访问只会得到 url ,不会提交页面参数即 url?param=x ,所以需要改进。
百度搜索爬虫算法,浅谈网络爬虫中深度优先算法和简单代码实现,爬虫(一)—爬行算法。
自行开发
预估需要解决的问题:爬虫算法(爬取顺序)、并发运行爬虫。(不一定非要自己写,最好审计二开)
数据量大小:针对 url 参数,只记录一次值即可(那需要比对是否存在于记录之中),所以访问最大次数设置成1000。
爬虫状态:需要附带身份信息,以通过验证机制。
审计二开
scrapy 爬取全站URL,很明显是可行的,只是需要定制。看了爬虫框架对比文章,认为 scrapy 框架的风评较高,明天查找相关文章,尝试在 scrapy 框架基础上定制专属南瓜的爬虫。
定制南瓜的专属爬虫
整体把握scrapy框架
定制爬虫
以上是关于Web漏洞扫描这件事爬虫的主要内容,如果未能解决你的问题,请参考以下文章
安全测试 web安全测试 常规安全漏洞 可能存在SQL和JS注入漏洞场景分析。为什么自己没有找到漏洞,哪么可能存在漏洞场景是?SQL注入漏洞修复 JS注入漏洞修复 漏洞存在场景分析和修复示例(代码片段