回炉重造Python之numpy详细教程(2万字总结)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了回炉重造Python之numpy详细教程(2万字总结)相关的知识,希望对你有一定的参考价值。
Python之numpy详细教程
- 前言
- Numpy库介绍
- NumPy数组基本用法
- Numpy数组操作
- Numpy数组操作
- 深拷贝和浅拷贝
- 文件操作
- CSV文件操作:
- NAN和INF值处理
- np.random模块
- Axis理解
- 通用函数
- Numpy练习题
- 一、查看Numpy的版本号:
- 二、如何创建一个所有值都是False的布尔类型的数组:
- 三、将一个有10个数的数组的形状进行转换:
- 四、将数组中所有偶数都替换成0(改变原来数组和不改变原来数组两种方式实现):
- 五、创建一个一维且有10个数的数组,元素是从`0-1`之间,但是不包含0和1:
- 六、求以下数组大于等于5并且小于等于10的数组:
- 七、将一个二维数组的行和列分别进行逆向:
- 八、如何将科学计数法转换为浮点类型打印:
- 九、获取一个数组中唯一的元素:
- 十、获取一个数组中唯一的元素个数的排行:
- 十一、如何找到数组中每行的最大值:
- 十二、如何按照行求最小值与最大值相除的结果:
- 十三、判断两个数组是否完全相等:
- 十四、设置一个数组不能修改值:
- 十五、找到数组中离某个元素的最近的值:
前言
Numpy(Numerical Python的简称)是一个专门用来做科学计算的库,主要用在多维数组(矩阵)方面的处理。
因为Numpy底层是用C语言开发的,所以他在处理一些多维数组(矩阵)的时候,比原生Python的列表快得很多。
Numpy是个基础的科学计算库,Python其余的科学计算扩展大部分都是以此为基础。
安装:
进入到你自己的环境中,然后输入conda install numpy即可安装。安装完成后,以后在pycharm中使用的时候如果出现以下错误:
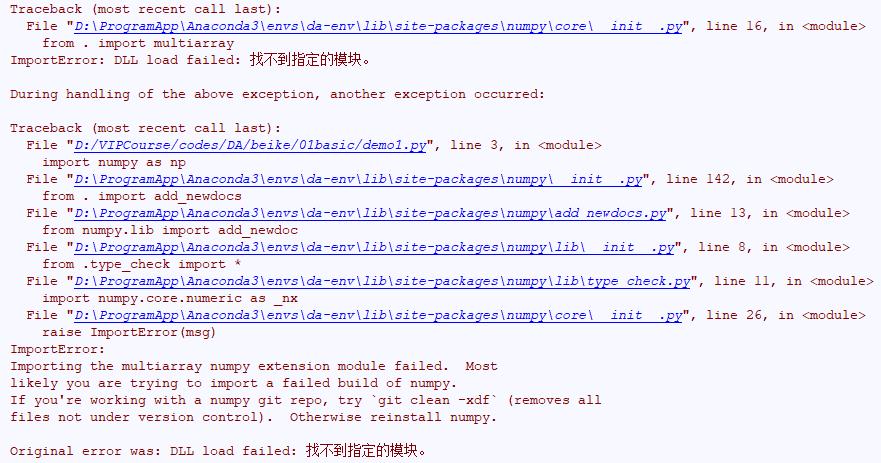
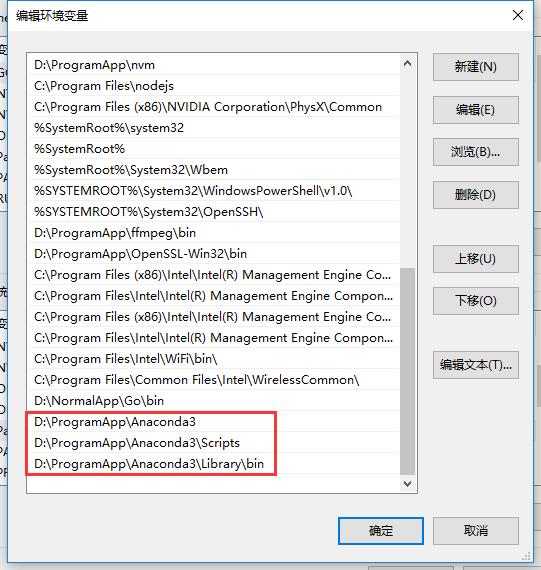
那么需要把Anaconda的安装路径添加到PATH的环境变量中。比如我是把Anaconda安装在D:\\ProgramApp\\Anaconda,那么需要添加以下三个环境变量:
Numpy库介绍
NumPy是一个功能强大的Python库,主要用于对多维数组执行计算。
NumPy这个词来源于两个单词-- Numerical和Python。NumPy提供了大量的库函数和操作,可以帮助程序员轻松地进行数值计算。在数据分析和机器学习领域被广泛使用。他有以下几个特点:
- numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算。
- Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,效率远高于纯Python代码。
- 有一个强大的N维数组对象Array(一种类似于列表的东西)。
- 实用的线性代数、傅里叶变换和随机数生成函数。
总而言之,他是一个非常高效的用于处理数值型运算的包。
安装:
通过pip install numpy即可安装。
教程地址:
- 官网:
https://docs.scipy.org/doc/numpy/user/quickstart.html。 - 中文文档:
https://www.numpy.org.cn/user_guide/quickstart_tutorial/index.html。
Numpy数组和Python列表性能对比:
比如我们想要对一个Numpy数组和Python列表中的每个素进行求平方。那么代码如下:
# Python列表的方式
t1 = time.time()
a = []
for x in range(100000):
a.append(x**2)
t2 = time.time()
t = t2 - t1
print(t)
花费的时间大约是0.07180左右。而如果使用numpy的数组来做,那速度就要快很多了:
t3 = time.time()
b = np.arange(100000)**2
t4 = time.time()
print(t4-t3)
NumPy数组基本用法
Numpy是Python科学计算库,用于快速处理任意维度的数组。NumPy提供一个N维数组类型ndarray,它描述了相同类型的“items”的集合。numpy.ndarray支持向量化运算。NumPy使用c语言写的,底部解除了GIL,其对数组的操作速度不在受python解释器限制。
numpy中的数组:
Numpy中的数组的使用跟Python中的列表非常类似。他们之间的区别如下:
- 一个列表中可以存储多种数据类型。比如
a = [1,'a']是允许的,而数组只能存储同种数据类型。 - 数组可以是多维的,当多维数组中所有的数据都是数值类型的时候,相当于线性代数中的矩阵,是可以进行相互间的运算的。
创建数组(np.ndarray对象):
Numpy经常和数组打交道,因此首先第一步是要学会创建数组。在Numpy中的数组的数据类型叫做ndarray。以下是两种创建的方式:
-
根据
Python中的列表生成:import numpy as np a1 = np.array([1,2,3,4]) print(a1) print(type(a1)) -
使用
np.arange生成,np.arange的用法类似于Python中的range:import numpy as np a2 = np.arange(2,21,2) print(a2) -
使用
np.random生成随机数的数组:a1 = np.random.random(2,2) # 生成2行2列的随机数的数组 a2 = np.random.randint(0,10,size=(3,3)) # 元素是从0-10之间随机的3行3列的数组 -
使用函数生成特殊的数组:
import numpy as np a1 = np.zeros((2,2)) #生成一个所有元素都是0的2行2列的数组 a2 = np.ones((3,2)) #生成一个所有元素都是1的3行2列的数组 a3 = np.full((2,2),8) #生成一个所有元素都是8的2行2列的数组 a4 = np.eye(3) #生成一个在斜方形上元素为1,其他元素都为0的3x3的矩阵
ndarray常用属性:
ndarray.dtype:
因为数组中只能存储同一种数据类型,因此可以通过dtype获取数组中的元素的数据类型。以下是ndarray.dtype的常用的数据类型:
| 数据类型 | 描述 | 唯一标识符 |
|---|---|---|
| bool | 用一个字节存储的布尔类型(True或False) | ‘b’ |
| int8 | 一个字节大小,-128 至 127 | ‘i1’ |
| int16 | 整数,16 位整数(-32768 ~ 32767) | ‘i2’ |
| int32 | 整数,32 位整数(-2147483648 ~ 2147483647) | ‘i4’ |
| int64 | 整数,64 位整数(-9223372036854775808 ~ 9223372036854775807) | ‘i8’ |
| uint8 | 无符号整数,0 至 255 | ‘u1’ |
| uint16 | 无符号整数,0 至 65535 | ‘u2’ |
| uint32 | 无符号整数,0 至 2 ** 32 - 1 | ‘u4’ |
| uint64 | 无符号整数,0 至 2 ** 64 - 1 | ‘u8’ |
| float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | ‘f2’ |
| float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | ‘f4’ |
| float64 | 双精度浮点数:64位,正负号1位,指数11位,精度52位 | ‘f8’ |
| complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | ‘c8’ |
| complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | ‘c16’ |
| object_ | python对象 | ‘O’ |
| string_ | 字符串 | ‘S’ |
| unicode_ | unicode类型 | ‘U’ |
我们可以看到,Numpy中关于数值的类型比Python内置的多得多,这是因为Numpy为了能高效处理处理海量数据而设计的。举个例子,比如现在想要存储上百亿的数字,并且这些数字都不超过254(一个字节内),我们就可以将dtype设置为int8,这样就比默认使用int64更能节省内存空间了。类型相关的操作如下:
-
默认的数据类型:
import numpy as np a1 = np.array([1,2,3]) print(a1.dtype) # 如果是windows系统,默认是int32 # 如果是mac或者linux系统,则根据系统来 -
指定
dtype:import numpy as np a1 = np.array([1,2,3],dtype=np.int64) # 或者 a1 = np.array([1,2,3],dtype="i8") print(a1.dtype) -
修改
dtype:import numpy as np a1 = np.array([1,2,3]) print(a1.dtype) # window系统下默认是int32 # 以下修改dtype a2 = a1.astype(np.int64) # astype不会修改数组本身,而是会将修改后的结果返回 print(a2.dtype)
ndarray.size:
获取数组中总的元素的个数。比如有个二维数组:
import numpy as np
a1 = np.array([[1,2,3],[4,5,6]])
print(a1.size) #打印的是6,因为总共有6个元素
ndarray.ndim:
数组的维数。比如:
a1 = np.array([1,2,3]) print(a1.ndim) # 维度为1 a2 = np.array([[1,2,3],[4,5,6]]) print(a2.ndim) # 维度为2 a3 = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]]) print(a3.ndim) # 维度为3
ndarray.shape:
数组的维度的元组。比如以下代码:
a1 = np.array([1,2,3]) print(a1.shape) # 输出(3,),意思是一维数组,有3个数据 a2 = np.array([[1,2,3],[4,5,6]]) print(a2.shape) # 输出(2,3),意思是二位数组,2行3列 a3 = np.array([ [ [1,2,3], [4,5,6] ], [ [7,8,9], [10,11,12] ] ]) print(a3.shape) # 输出(2,2,3),意思是三维数组,总共有2个元素,每个元素是2行3列的 a44 = np.array([1,2,3],[4,5]) print(a4.shape) # 输出(2,),意思是a4是一个一维数组,总共有2列 print(a4) # 输出[list([1, 2, 3]) list([4, 5])],其中最外面层是数组,里面是Python列表
另外,我们还可以通过ndarray.reshape来重新修改数组的维数。示例代码如下:
a1 = np.arange(12) #生成一个有12个数据的一维数组 print(a1) a2 = a1.reshape((3,4)) #变成一个2维数组,是3行4列的 print(a2) a3 = a1.reshape((2,3,2)) #变成一个3维数组,总共有2块,每一块是2行2列的 print(a3) a4 = a2.reshape((12,)) # 将a2的二维数组重新变成一个12列的1维数组 print(a4) a5 = a2.flatten() # 不管a2是几维数组,都将他变成一个一维数组 print(a5)
注意,reshape并不会修改原来数组本身,而是会将修改后的结果返回。如果想要直接修改数组本身,那么可以使用resize来替代reshape。
ndarray.itemsize:
数组中每个元素占的大小,单位是字节。比如以下代码:
a1 = np.array([1,2,3],dtype=np.int32) print(a1.itemsize) # 打印4,因为每个字节是8位,32位/8=4个字节
Numpy数组操作
数组广播机制:
数组与数的计算:
在Python列表中,想要对列表中所有的元素都加一个数,要么采用map函数,要么循环整个列表进行操作。但是NumPy中的数组可以直接在数组上进行操作。
示例代码如下:
import numpy as np
a1 = np.random.random((3,4))
print(a1)
# 如果想要在a1数组上所有元素都乘以10,那么可以通过以下来实现
a2 = a1*10
print(a2)
# 也可以使用round让所有的元素只保留2位小数
a3 = a2.round(2)
以上例子是相乘,其实相加、相减、相除也都是类似的。
数组与数组的计算:
-
结构相同的数组之间的运算:
a1 = np.arange(0,24).reshape((3,8)) a2 = np.random.randint(1,10,size=(3,8)) a3 = a1 + a2 #相减/相除/相乘都是可以的 print(a1) print(a2) print(a3) -
与行数相同并且只有1列的数组之间的运算:
a1 = np.random.randint(10,20,size=(3,8)) #3行8列 a2 = np.random.randint(1,10,size=(3,1)) #3行1列 a3 = a1 - a2 #行数相同,且a2只有1列,能互相运算 print(a3) -
与列数相同并且只有1行的数组之间的运算:
a1 = np.random.randint(10,20,size=(3,8)) #3行8列 a2 = np.random.randint(1,10,size=(1,8)) a3 = a1 - a2 print(a3)
广播原则:
如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
看以下案例分析:
-
shape为(3,8,2)的数组能和(8,3)的数组进行运算吗?
分析:不能,因为按照广播原则,从后面往前面数,(3,8,2)和(8,3)中的2和3不相等,所以不能进行运算。 -
shape为(3,8,2)的数组能和(8,1)的数组进行运算吗?
分析:能,因为按照广播原则,从后面往前面数,(3,8,2)和(8,1)中的2和1虽然不相等,但是因为有一方的长度为1,所以能参与运算。 -
shape为(3,1,8)的数组能和(8,1)的数组进行运算吗?
分析:能,因为按照广播原则,从后面往前面数,(3,1,4)和(8,1)中的4和1虽然不相等且1和8不相等,但是因为这两项中有一方的长度为1,所以能参与运算。
数组形状的操作:
可以通过一些函数,非常方便的操作数组的形状。
reshape和resize方法:
两个方法都是用来修改数组形状的,但是有一些不同。
-
reshape是将数组转换成指定的形状,然后返回转换后的结果,对于原数组的形状是不会发生改变的。调用方式:a1 = np.random.randint(0,10,size=(3,4)) a2 = a1.reshape((2,6)) #将修改后的结果返回,不会影响原数组本身 -
resize是将数组转换成指定的形状,会直接修改数组本身。并不会返回任何值。调用方式:a1 = np.random.randint(0,10,size=(3,4)) a1.resize((2,6)) #a1本身发生了改变
flatten和ravel方法:
两个方法都是将多维数组转换为一维数组,但是有以下不同:
flatten是将数组转换为一维数组后,然后将这个拷贝返回回去,所以后续对这个返回值进行修改不会影响之前的数组。ravel是将数组转换为一维数组后,将这个视图(可以理解为引用)返回回去,所以后续对这个返回值进行修改会影响之前的数组。
比如以下代码:
x = np.array([[1, 2], [3, 4]])
x.flatten()[1] = 100 #此时的x[0]的位置元素还是1
x.ravel()[1] = 100 #此时x[0]的位置元素是100
不同数组的组合:
如果有多个数组想要组合在一起,也可以通过其中的一些函数来实现。
-
vstack:将数组按垂直方向进行叠加。数组的列数必须相同才能叠加。示例代码如下:a1 = np.random.randint(0,10,size=(3,5)) a2 = np.random.randint(0,10,size=(1,5)) a3 = np.vstack([a1,a2]) -
hstack:将数组按水平方向进行叠加。数组的行必须相同才能叠加。示例代码如下:a1 = np.random.randint(0,10,size=(3,2)) a2 = np.random.randint(0,10,size=(3,1))a3 = np.hstack([a1,a2]) -
concatenate([],axis):将两个数组进行叠加,但是具体是按水平方向还是按垂直方向。则要看axis的参数,如果axis=0,那么代表的是往垂直方向(行)叠加,如果axis=1,那么代表的是往水平方向(列)上叠加,如果axis=None,那么会将两个数组组合成一个一维数组。
需要注意的是,如果往水平方向上叠加,那么行必须相同,如果是往垂直方向叠加,那么列必须相同。
示例代码如下:
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
np.concatenate((a, b), axis=0)
# 结果:
array([[1, 2],
[3, 4],
[5, 6]])
np.concatenate((a, b.T), axis=1)
# 结果:
array([[1, 2, 5],
[3, 4, 6]])
np.concatenate((a, b), axis=None)
# 结果:
array([1, 2, 3, 4, 5, 6])
数组的切割:
通过hsplit和vsplit以及array_split可以将一个数组进行切割。
hsplit:按照水平方向进行切割。用于指定分割成几列,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。
示例代码如下:
a1 = np.arange(16.0).reshape(4, 4)
np.hsplit(a1,2) #分割成两部分
>>> array([[ 0., 1.],
[ 4., 5.],
[ 8., 9.],
[12., 13.]]), array([[ 2., 3.],
[ 6., 7.],
[10., 11.],
[14., 15.]])]
np.hsplit(a1,[1,2]) #代表在下标为1的地方切一刀,下标为2的地方切一刀,分成三部分
>>> [array([[ 0.],
[ 4.],
[ 8.],
[12.]]), array([[ 1.],
[ 5.],
[ 9.],
[13.]]), array([[ 2., 3.],
[ 6., 7.],
[10., 11.],
[14., 15.]])]
vsplit:按照垂直方向进行切割。用于指定分割成几行,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:
np.vsplit(x,2) #代表按照行总共分成2个数组
>>> [array([[0., 1., 2., 3.],
[4., 5., 6., 7.]]), array([[ 8., 9., 10., 11.],
[12., 13., 14., 15.]])]
np.vsplit(x,(1,2)) #代表按照行进行划分,在下标为1的地方和下标为2的地方分割
>>> [array([[0., 1., 2., 3.]]),
array([[4., 5以上是关于回炉重造Python之numpy详细教程(2万字总结)的主要内容,如果未能解决你的问题,请参考以下文章