强烈推荐一文带你搞定Python基础篇(回炉重造)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强烈推荐一文带你搞定Python基础篇(回炉重造)相关的知识,希望对你有一定的参考价值。
1. 变量
变量名自定义,要满足标识符命名规则。
标识符命名规则是Python中定义各种名字的时候的统一规范,具体如下:
- 由数字、字母、下划线组成
- 不能数字开头
- 不能使用内置关键字
- 严格区分大小写
False None True and as assert break class
continue def del elif else except finally for
from global if import in is lambda nonlocal
not or pass raise return try while with
yield
2. 命名习惯
- 见名知义。
- 大驼峰:即每个单词首字母都大写,例如:
MyName。 - 小驼峰:第二个(含)以后的单词首字母大写,例如:
myName。 - 下划线:例如:
my_name。
3. 格式化输出
所谓的格式化输出即按照一定的格式输出内容。
3.1 格式化符号
| 格式符号 | 转换 |
|---|---|
| %s | 字符串 |
| %d | 有符号的十进制整数 |
| %f | 浮点数 |
| %c | 字符 |
| %u | 无符号十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数(小写ox) |
| %X | 十六进制整数(大写OX) |
| %e | 科学计数法(小写’e’) |
| %E | 科学计数法(大写’E’) |
| %g | %f和%e的简写 |
| %G | %f和%E的简写 |
技巧
- %06d,表示输出的整数显示位数,不足以0补全,超出当前位数则原样输出
- %.2f,表示小数点后显示的小数位数。
3.2 体验
格式化字符串除了%s,还可以写为f'{表达式}'
age = 18
name = 'TOM'
weight = 75.5
student_id = 1
# 我的名字是TOM
print('我的名字是%s' % name)
# 我的学号是0001
print('我的学号是%4d' % student_id)
# 我的体重是75.50公斤
print('我的体重是%.2f公斤' % weight)
# 我的名字是TOM,今年18岁了
print('我的名字是%s,今年%d岁了' % (name, age))
# 我的名字是TOM,明年19岁了
print('我的名字是%s,明年%d岁了' % (name, age + 1))
# 我的名字是TOM,明年19岁了
print(f'我的名字是{name}, 明年{age + 1}岁了')
f-格式化字符串是Python3.6中新增的格式化方法,该方法更简单易读。
3.3 转义字符
\\n:换行。\\t:制表符,一个tab键(4个空格)的距离。
3.4 结束符
想一想,为什么两个print会换行输出?
print('输出的内容', end="\\n")
在Python中,print(), 默认自带
end="\\n"这个换行结束符,所以导致每两个
4. 转换数据类型
转换数据类型的函数
| 函数 | 说明 |
|---|---|
| int(x [,base ]) | 将x转换为一个整数 |
| float(x ) | 将x转换为一个浮点数 |
| complex(real [,imag ]) | 创建一个复数,real为实部,imag为虚部 |
| str(x ) | 将对象 x 转换为字符串 |
| repr(x ) | 将对象 x 转换为表达式字符串 |
| eval(str ) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s ) | 将序列 s 转换为一个元组 |
| list(s ) | 将序列 s 转换为一个列表 |
| chr(x ) | 将一个整数转换为一个Unicode字符 |
| ord(x ) | 将一个字符转换为它的ASCII整数值 |
| hex(x ) | 将一个整数转换为一个十六进制字符串 |
| oct(x ) | 将一个整数转换为一个八进制字符串 |
| bin(x ) | 将一个整数转换为一个二进制字符串 |
5. 数据类型
5.1 字符串
- find():检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则返回-1。
- 语法
字符串序列.find(子串, 开始位置下标, 结束位置下标)
注意:开始和结束位置下标可以省略,表示在整个字符串序列中查找。
- index():检测某个子串是否包含在这个字符串中,如果在返回这个子串开始的位置下标,否则则报异常。
- 语法
字符串序列.index(子串, 开始位置下标, 结束位置下标)
注意:开始和结束位置下标可以省略,表示在整个字符串序列中查找。
-
rfind(): 和find()功能相同,但查找方向为右侧开始。
-
rindex():和index()功能相同,但查找方向为右侧开始。
-
count():返回某个子串在字符串中出现的次数
-
replace():替换
-
split():按照指定字符分割字符串。
-
join():用一个字符或子串合并字符串,即是将多个字符串合并为一个新的字符串。
-
capitalize():将字符串第一个字符转换成大写。
注意:capitalize()函数转换后,只字符串第一个字符大写,其他的字符全都小写。
- title():将字符串每个单词首字母转换成大写。
- lower():将字符串中大写转小写。
- upper():将字符串中小写转大写。
- lstrip():删除字符串左侧空白字符。
- ljust():返回一个原字符串左对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串。
- rjust():返回一个原字符串右对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串,语法和ljust()相同。
- center():返回一个原字符串居中对齐,并使用指定字符(默认空格)填充至对应长度 的新字符串,语法和ljust()相同。
- endswith()::检查字符串是否是以指定子串结尾,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查。
- isalpha():如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False。
- isdigit():如果字符串只包含数字则返回 True 否则返回 False。
- isalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False。
- isspace():如果字符串中只包含空白,则返回 True,否则返回 False。
5.2 列表
- index():返回指定数据所在位置的下标 。
- count():统计指定数据在当前列表中出现的次数。
- in:判断指定数据在某个列表序列,如果在返回True,否则返回False
- append():列表结尾追加数据。
如果append()追加的数据是一个序列,则追加整个序列到列表 - extend():列表结尾追加数据,如果数据是一个序列,则将这个序列的数据逐一添加到列表。
- insert():指定位置新增数据。
- del/del name_list[0]
- pop():删除指定下标的数据(默认为最后一个),并返回该数据。
- remove():移除列表中某个数据的第一个匹配项。
- clear():清空列表
- reverse()
- sort()
- copy()
5.3 元组
- 按下标查找数据
- index():查找某个数据,如果数据存在返回 对应的下标,否则报错,语法和列表、字符串的index方法相同。
- count():统计某个数据在当前元组出现的次数。
- len():统计元组中数据的个数。
5.4 字典
- 增:字典序列[key] = 值
- del() / del:删除字典或删除字典中指定键值对。
- clear():清空字典
- key值查找
- 字典序列.get(key, 默认值)
- keys()
- values()
- items()
5.5 集合
- 创建集合使用
{}或set(), 但是如果要创建空集合只能使用set(),因为{}用来创建空字典。 - add()
- update(), 追加的数据是序列。
- remove(),删除集合中的指定数据,如果数据不存在则报错。
- discard(),删除集合中的指定数据,如果数据不存在也不会报错。
- pop(),随机删除集合中的某个数据,并返回这个数据。
- in:判断数据在集合序列
6. 公共操作
6.1 公共方法
| 函数 | 描述 |
|---|---|
| len() | 计算容器中元素个数 |
| del 或 del() | 删除 |
| max() | 返回容器中元素最大值 |
| min() | 返回容器中元素最小值 |
| range(start, end, step) | 生成从start到end的数字,步长为 step,供for循环使用 |
| enumerate() | 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 |
7. 推导式
7.1 列表推导式
作用:用一个表达式创建一个有规律的列表或控制一个有规律列表。
列表推导式又叫列表生成式。
1.1 快速体验
需求:创建一个0-10的列表。
- while循环实现
# 1. 准备一个空列表
list1 = []
# 2. 书写循环,依次追加数字到空列表list1中
i = 0
while i < 10:
list1.append(i)
i += 1
print(list1)
- for循环实现
list1 = []
for i in range(10):
list1.append(i)
print(list1)
- 列表推导式实现
list1 = [i for i in range(10)]
print(list1)
1.2 带if的列表推导式
需求:创建0-10的偶数列表
- 方法一:range()步长实现
list1 = [i for i in range(0, 10, 2)]
print(list1)
- 方法二:if实现
list1 = [i for i in range(10) if i % 2 == 0]
print(list1)
1.3 多个for循环实现列表推导式
需求:创建列表如下:
[(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
- 代码如下:
list1 = [(i, j) for i in range(1, 3) for j in range(3)]
print(list1)
7.2 字典推导式
思考:如果有如下两个列表:
list1 = ['name', 'age', 'gender']
list2 = ['Tom', 20, 'man']
如何快速合并为一个字典?
答:字典推导式
字典推导式作用:快速合并列表为字典或提取字典中目标数据。
2.1 快速体验
- 创建一个字典:字典key是1-5数字,value是这个数字的2次方。
dict1 = {i: i**2 for i in range(1, 5)}
print(dict1) # {1: 1, 2: 4, 3: 9, 4: 16}
- 将两个列表合并为一个字典
list1 = ['name', 'age', 'gender']
list2 = ['Tom', 20, 'man']
dict1 = {list1[i]: list2[i] for i in range(len(list1))}
print(dict1)
- 提取字典中目标数据
counts = {'MBP': 268, 'HP': 125, 'DELL': 201, 'Lenovo': 199, 'acer': 99}
# 需求:提取上述电脑数量大于等于200的字典数据
count1 = {key: value for key, value in counts.items() if value >= 200}
print(count1) # {'MBP': 268, 'DELL': 201}
7.3 集合推导式
需求:创建一个集合,数据为下方列表的2次方。
list1 = [1, 1, 2]
代码如下:
list1 = [1, 1, 2]
set1 = {i ** 2 for i in list1}
print(set1) # {1, 4}
注意:集合有数据去重功能。
7.4 总结
- 推导式的作用:简化代码
- 推导式写法
# 列表推导式
[xx for xx in range()]
# 字典推导式
{xx1: xx2 for ... in ...}
# 集合推导式
{xx for xx in ...}
8. 函数
-
函数的作用:封装代码,高效的代码重用
-
函数使用步骤
- 定义函数
def 函数名(): 代码1 代码2 ...- 调用函数
函数名() -
函数的参数:函数调用的时候可以传入真实数据,增大函数的使用的灵活性
- 形参:函数定义时书写的参数(非真实数据)
- 实参:函数调用时书写的参数(真实数据)
-
函数的返回值
- 作用:函数调用后,返回需要的计算结果
- 写法
return 表达式 -
函数的说明文档
- 作用:保存函数解释说明的信息
- 写法
def 函数名(): """ 函数说明文档 """ -
函数嵌套调用:一个函数内部嵌套调用另外一个函数
8.1 变量作用域
变量作用域指的是变量生效的范围,主要分为两类:局部变量和全局变量。
- 局部变量
所谓局部变量是定义在函数体内部的变量,即只在函数体内部生效。
局部变量的作用:在函数体内部,临时保存数据,即当函数调用完成后,则销毁局部变量。
- 全局变量
所谓全局变量,指的是在函数体内、外都能生效的变量。
8.2 多函数程序执行流程
一般在实际开发过程中,一个程序往往由多个函数(后面知识中会讲解类)组成,并且多个函数共享某些数据,如下所示:
- 共用全局变量
# 1. 定义全局变量
glo_num = 0
def test1():
global glo_num
# 修改全局变量
glo_num = 100
8.3 函数的参数
- 位置参数:调用函数时根据函数定义的参数位置来传递参数。
注意:传递和定义参数的顺序及个数必须一致。
- 函数调用,通过“键=值”形式加以指定。可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求。
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序。
- 缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)。
注意:函数调用时,如果为缺省参数传值则修改默认参数值;否则使用这个默认值。
-
不定长参数也叫可变参数。用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。此时,可用包裹(packing)位置参数,或者包裹关键字参数,来进行参数传递,会显得非常方便。
-
包裹位置传递
def user_info(*args):
print(args)
# ('TOM',)
user_info('TOM')
# ('TOM', 18)
user_info('TOM', 18)
注意:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是包裹位置传递。
- 包裹关键字传递
def user_info(**kwargs):
print(kwargs)
# {'name': 'TOM', 'age': 18, 'id': 110}
user_info(name='TOM', age=18, id=110)
综上:无论是包裹位置传递还是包裹关键字传递,都是一个组包的过程。
8.4 拆包和交换变量值
- 拆包:元组
def return_num():
return 100, 200
num1, num2 = return_num()
print(num1) # 100
print(num2) # 200
- 拆包:字典
dict1 = {'name': 'TOM', 'age': 18}
a, b = dict1
# 对字典进行拆包,取出来的是字典的key
print(a) # name
print(b) # age
print(dict1[a]) # TOM
print(dict1[b]) # 18
8.5 引用
在python中,值是靠引用来传递来的。
我们可以用id()来判断两个变量是否为同一个值的引用。 我们可以将id值理解为那块内存的地址标识。
# 1. int类型
a = 1
b = a
print(b) # 1
print(id(a)) # 140708464157520
print(id(b)) # 140708464157520
a = 2
print(b) # 1,说明int类型为不可变类型
print(id(a)) # 140708464157552,此时得到是的数据2的内存地址
print(id(b)) # 140708464157520
# 2. 列表
aa = [10, 20]
bb = aa
print(id(aa)) # 2325297783432
print(id(bb)) # 2325297783432
aa.append(30)
print(bb) # [10, 20, 30], 列表为可变类型
print(id(aa)) # 2325297783432
print(id(bb)) # 2325297783432
引用当做实参
代码如下:
def test1(a):
print(a)
print(id(a))
a += a
print(a)
print(id(a))
# int:计算前后id值不同
b = 100
test1(b)
# 列表:计算前后id值相同
c = [11, 22]
test1(c)
效果图如下:
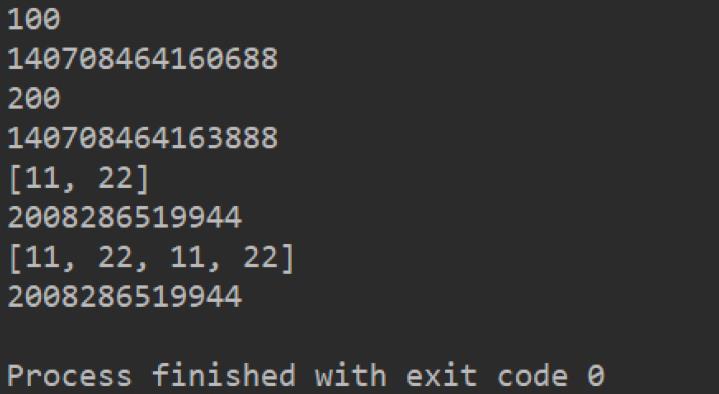
基本数据类型传入的是值,引用数据类型传入的实参引用地址
8.6 可变和不可变类型
所谓可变类型与不可变类型是指:数据能够直接进行修改,如果能直接修改那么就是可变,否则是不可变.
- 可变类型
- 列表
- 字典
- 集合
- 不可变类型
- 整型
- 浮点型
- 字符串
- 元组
8.7 高阶函数
把函数作为参数传入,这样的函数称为高阶函数,高阶函数是函数式编程的体现。函数式编程就是指这种高度抽象的编程范式。
体验高阶函数
在Python中,abs()函数可以完成对数字求绝对值计算。
abs(-10) # 10
round()函数可以完成对数字的四舍五入计算。
round(1.2) # 1
round(1.9) # 2
需求:任意两个数字,按照指定要求整理数字后再进行求和计算。
- 方法1
def add_num(a, b):
return abs(a) + abs(b)
result = add_num(-1, 2)
print(result) # 3
- 方法2
def sum_num(a, b, f):
return f(a) + f(b)
result = sum_num(-1, 2, abs)
print(result) # 3
注意:两种方法对比之后,发现,方法2的代码会更加简洁,函数灵活性更高。
函数式编程大量使用函数,减少了代码的重复,因此程序比较短,开发速度较快。
内置高阶函数
map()
map(func, lst),将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表(Python2)/迭代器(Python3)返回。
需求:计算list1序列中各个数字的2次方。
list1 = [1, 2, 3, 4, 5]
def func(x):
return x ** 2
result = map(func, list1)
print(result) # <map object at 0x0000013769653198>
print(list(result)) # [1, 4, 9, 16, 25]
reduce()
reduce(func,lst),其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累积计算。
注意:reduce()传入的参数func必须接收2个参数。
需求:计算list1序列中各个数字的累加和。
import functools
list1 = [1, 2, 3, 4, 5]
def func(a, b):
return a + b
result = functools.reduce(func, list1)
print(result) # 15
filter()
filter(func, lst)函数用于过滤序列, 过滤掉不符合条件的元素, 返回一个 filter 对象。如果要转换为列表, 可以使用 list() 来转换。
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def func(x):
return x % 2 == 0
result = filter(func, list1)
print(result) # <filter object at 0x0000017AF9DC3198>
print(list(result)) # [2, 4, 6, 8, 10]
8.8 总结
-
递归
- 函数内部自己调用自己
- 必须有出口
-
lambda
- 语法
lambda 参数列表: 表达式-
lambda的参数形式
- 无参数
lambda: 表达式- 一个参数
lambda 参数: 表达式- 默认参数
lambda key=value: 表达式- 不定长位置参数
lambda *args: 表达式- 不定长关键字参数
lambda **kwargs: 表达式
-
高阶函数
- 作用:把函数作为参数传入,化简代码
- 内置高阶函数
- map()
- reduce()
- filter()
9. 文件操作
9.1 打开文件模式
在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
open(name, mode)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
打开文件模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
- read()
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
- readlines()
readlines可以
以上是关于强烈推荐一文带你搞定Python基础篇(回炉重造)的主要内容,如果未能解决你的问题,请参考以下文章