MapReduce 框架原理OutputFormat 数据输出
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce 框架原理OutputFormat 数据输出相关的知识,希望对你有一定的参考价值。
OutputFormat 数据输出
1. OutputFormat 接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了 OutputFormat 接口。
下面我们介绍几种常见的OutputFormat实现类:
1.OutputFormat实现类
2.TextOutputFormat(默认输出格式)
3.自定义OutputFormat
- 3.1 应用场景:
例如:输出数据到mysql/HBase/Elasticsearch等存储框架中。 - 3.2 自定义OutputFormat步骤:
- 自定义一个类继承FileOutputFormat。
- 改写RecordWriter,具体改写输出数据的方法write()。
2. 自定义 OutputFormat 案例实操
2.1 需求
过滤输入的 log 日志,包含 atguigu 的网站输出到e:/atguigu.log,不包含 atguigu 的网站.
(1)输入数据

(2)期望输出数据

2.2 需求分析
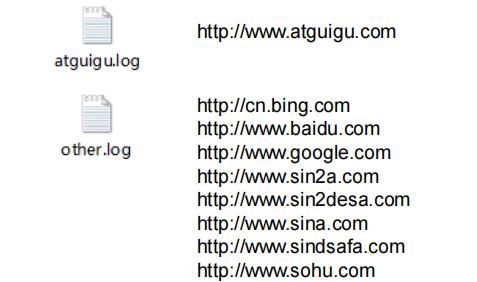
1、需求:过滤输入的log日志,包含atguigu的网站输出到e:/atguigu.log,不包含atguigu的网站输出到e:/other.log
2、输入数据
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.atguigu.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
3、输出数据
4、自定义一个OutputFormat类
(1)创建一个类LogRecordWriter继承RecordWriter
- (a)创建两个文件的输出流:atguiguOut、otherOut
- (b)如果输入数据包含atguigu,输出到atguiguOut流
如果不包含atguigu,输出到otherOut流。
5、驱动类Driver
// 要将自定义的输出格式组件设置到job中
job.setOutputFormatClass(LogOutputFormat.class) ;
2.3 案例实操
LogMapper
package com.zs.mapreduce.outputformat;
import org.apache.commons.lang.ObjectUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// http:www.baidu.com
// 在Map阶段不做任何处理
context.write(value, NullWritable.get());
}
}
LogReducer
package com.zs.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// 防止有相同数据,丢数据
for (NullWritable value : values) {
context.write(key, NullWritable.get());
}
}
}
LogOutputFormat
package com.zs.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
// reduce输出的key到这里
public class LogOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
LogRecordWriter lrw = new LogRecordWriter(job);
return null;
}
}
LogRecordWriter
package com.zs.mapreduce.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class LogRecordWriter extends RecordWriter<Text, NullWritable> {
private FSDataOutputStream zsOut;
private FSDataOutputStream otherOut;
public LogRecordWriter(TaskAttemptContext job) {
// 创建两条流
try {
FileSystem fs = FileSystem.get(job.getConfiguration());
zsOut = fs.create(new Path("D:\\\\software\\\\hadoop\\\\output\\\\zs.log"));
otherOut = fs.create(new Path("D:\\\\software\\\\hadoop\\\\output\\\\other.log"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
String log = key.toString();
// 具体写
if (log.contains("atguigu")) {
zsOut.writeBytes(log);
} else {
otherOut.writeBytes(log);
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
// 关流
IOUtils.closeStream(zsOut);
IOUtils.closeStream(otherOut);
}
}
LogDriver
package com.zs.mapreduce.outputformat;
import com.zs.mapreduce.combiner.WordCountCombiner;
import com.zs.mapreduce.combiner.WordCountMapper;
import com.zs.mapreduce.combiner.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1. 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2. 设置jar包路径
job.setJarByClass(LogDriver.class);
// 3. 关联mapper和reducer
job.setMapperClass(LogMapper.class);
job.setReducerClass(LogReducer.class);
// 4. 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 5. 设置最终输出kV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置自定义的outputformat
job.setOutputFormatClass(LogOutputFormat.class);
// 6.设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\\\software\\\\hadoop\\\\input\\\\inputoutputformat"));
FileOutputFormat.setOutputPath(job, new Path("D:\\\\software\\\\hadoop\\\\output\\\\outputFormat"));
// 7. 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
加油!
感谢!
努力!
以上是关于MapReduce 框架原理OutputFormat 数据输出的主要内容,如果未能解决你的问题,请参考以下文章
MapReduce 框架原理MapReduce 工作流程 & Shuffle 机制
大数据之Hadoop(MapReduce): MapReduce框架原理
打怪升级之小白的大数据之旅(五十)<MapReduce框架原理二:shuffle>