清华刘知远团队巨作!Pre-trained Prompt Tuning框架,让超大模型调参变简单
Posted 机器学习算法与Python学习-公众号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清华刘知远团队巨作!Pre-trained Prompt Tuning框架,让超大模型调参变简单相关的知识,希望对你有一定的参考价值。
点击 机器学习算法与Python学习 ,选择加星标
精彩内容不迷路

机器之心报道
来自清华大学的刘知远、黄民烈等研究者提出了一个名为「PPT」的新框架。PPT=Pre-trained Prompt Tuning。
近年来,微调预训练语言模型(PLM)取得了很大进展。通过微调 PLM 的全部参数,从大规模无标签语料库中获得的多方面知识可以用于处理各种 NLP 任务,并优于从头学习模型的方法。为简单起见,此处将这种全模型调整(full-model tuning)称为 FT。
如下图 1 (b) 和 (c)所示,主流的 FT 方法共有两种。第一种是任务导向的微调,在 PLM 上添加一个 task-specific 的头(head),然后通过优化 task-specific 训练数据上的 task-specific 学习目标,来微调整个模型。
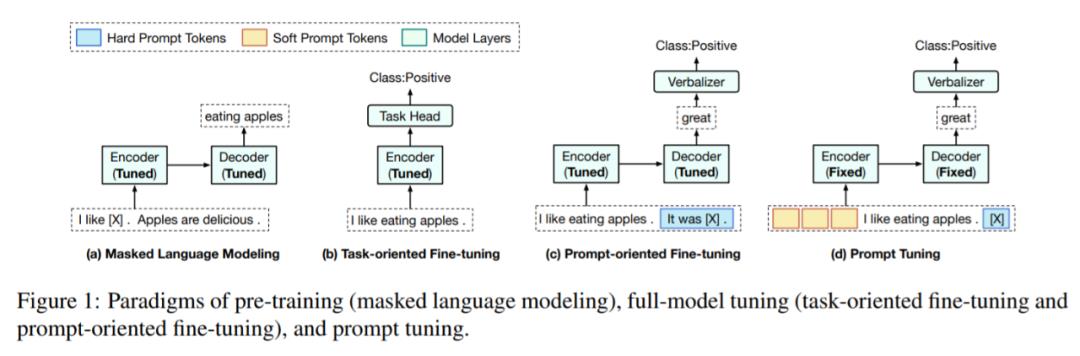
第二种是以 prompt 为导向的微调,其灵感来自最近的一些研究,这些研究利用语言 prompt 来激发 PLM 的知识。在以 prompt 为导向的微调中,数据样本被转换为包含 prompt token 的线性序列,所有的下游任务都被转化为语言建模问题。
如图 1 (c) 所示,通过在句子中添加 prompt(It was hXi),我们可以根据 PLM 在掩码位置给出的预测结果(great 或 terrible)来确定这个句子到底是积极还是消极。
如图 1 所示,与以任务为导向的微调相比,在目标方面(掩码语言建模),以 prompt 为导向的微调更类似于预训练,因此有助于更好地利用 PLM 中的知识,通常也能取得更好的结果。
尽管上述 FT 方法已经显示出很好的结果,但随着模型规模的迅速扩张,为每个下游任务微调一个完整的大模型正变得越来越昂贵。为了应对这一挑战,来自谷歌的 Brian Lester 等人在《 The Power of Scale for Parameter-Efficient Prompt Tuning 》中提出了 prompt tuning(PT),以降低为下游任务微调大模型的成本,如图 1 (d)所示。
具体来说,PT 采用包含连续嵌入的 soft prompt 代替 hard prompt(离散语言短语)。这些连续 prompt 嵌入通常是随机初始化和端到端学习的。为了避免为每个下游任务存储整个模型,PT 冻结了 PLM 的所有参数,只调整 soft prompt,无需添加任何中间层和 task-specific 组件。尽管 PT 具有很少的可调参数和简单的设计,但它仍然可以媲美 FT,如图 2(a)所示。
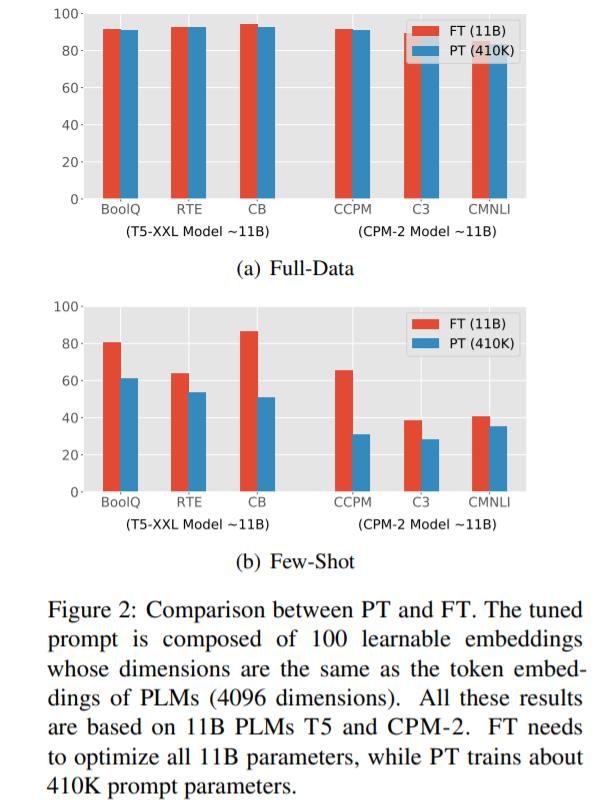
PT 有两个非常有前景的优势:1)与 hard prompt 相比,soft prompt 可以端到端学习;2)PT 是大规模 PLM 实际应用的一种高效、有效的范式。然而,如图 2 (b)所示,在 few-shot 场景下,PT 的表现比 FT 差很多,这可能会阻碍 PT 在各种低资源场景下的应用。
因此,在这篇论文中,来自清华大学的 Yuxian Gu、Xu Han、刘知远、黄民烈四位研究者广泛探索了如何通过 PT 以高效和有效的方式使用 PLM 进行 few-shot 学习。
具体来说,在论文的第二部分,他们进行了试点实验,分析了 PT 在大规模 PLM 中用于 few-shot 学习的有效性,这是现在很多研究所忽略的问题。他们发现:1)verbalizer 的选择对于性能有很大的影响;2)简单地用具体的词嵌入初始化 soft prompt 并不能提高性能;3)将 soft 和 hard prompt 结合起来很有帮助;4)所有这些方法都不能很好地处理 few-shot prompt 调优问题。上述观察结果表明,为大规模 PLM 找到合适的 prompt 并非易事,而精心设计的 soft prompt token 初始化至关重要。

论文链接:https://arxiv.org/pdf/2109.04332.pdf
为了帮助模型找到合适的 prompt,研究者使用大规模无标记语料库上的自监督任务对这些 token 进行预训练。为了保证预训练 prompt 的泛化能力,他们将典型分类任务分为三种:sentence-pair 分类、multiple-choice 分类和 single-text 分类,每种对应一个自监督的预训练任务。此外,他们发现 multiple-choice 分类比其他分类都要普遍,可以将所有下游分类任务都统一到这种分类中。他们给这种 Pre-trained Prompt Tuning 框架起名为「PPT」。
研究者使用 3 个 11B 的 PLM(T5-XXL、mT5-XXL、CPM-2)在多个数据集上评估了 PPT 的性能。实验结果表明,PPT 不仅可以大幅提升 few-shot PT,媲美甚至超越 FT 方法,还能降低 few-shot 学习的方差。除有效性之外,PPT 还保留了现有 PT 方法的参数效率,这对未来在大规模 PLM 上的应用具有重要价值。
PPT 架构概览
遵循 T5 和 PT 的方法,研究者以一种 text-to-text 的方式解决所有下游任务。如图 1(d)所示,为了弥合预训练和下游任务之间的 objective gap,以 prompt 为导向的微调将下游任务转化为一些完形填空式的目标。以分类任务为例,给定输入句子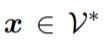 及其标签
及其标签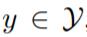 ,首先应用模式映射
,首先应用模式映射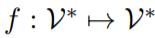 将 x 转换为一个新的 token 序列 f(x),其中 V 是 PLM 的词汇表。f(x)不仅添加了一些 prompt token 作为提示,还保留了至少一个 masking token <X>,让 PLM 预测掩码位置的 token。接下来,使用一个 verbalizer
将 x 转换为一个新的 token 序列 f(x),其中 V 是 PLM 的词汇表。f(x)不仅添加了一些 prompt token 作为提示,还保留了至少一个 masking token <X>,让 PLM 预测掩码位置的 token。接下来,使用一个 verbalizer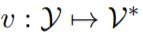 将 y 映射到一个标签 token 序列 v(y)。借助 f(·)和 v(·),分类任务可以用 pattern-verbalizer 对 (f, v) 来表示:
将 y 映射到一个标签 token 序列 v(y)。借助 f(·)和 v(·),分类任务可以用 pattern-verbalizer 对 (f, v) 来表示:
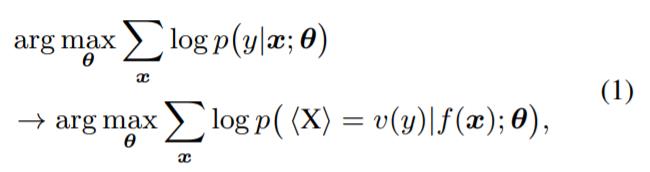
其中,θ表示所有可调参数,特别是 PLM 的参数。为了方便起见,研究者使用「PVP」来表示这个 pattern-verbalizer 对。
在 PT 中,将一组 soft prompt token P 连接到序列的前面,模型输入变为 [P;f (x)]。其中, [·; ·] 为连接函数。通过单独调整 P,其他参数固定,将式(1) 替换为:
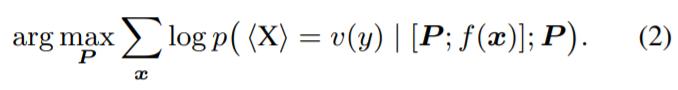
由于大规模 PLM 性能强大,在多个全数据情境下,式(2) 被证实与这些 FT 方法具有可比性。但是研究者发现,学习有效的 soft prompt 并不容易,这可能导致模型在各种 few-shot 情境下性能较低。参数的初始化通常对模型的学习难度有很大的影响。一般来说,除了随机初始化 p 之外,一些研究从 PLM 的词汇表 V 中采样词嵌入作为初始化。然而,试点实验的结果表明,现有初始化策略及其简单变体对基于大规模 PLM 的模型性能影响很小或有消极影响(具体细节参见论文第四部分)。
近年来,预训练已经被证明是一种寻找模型良好初始化的有效方法。受此启发,研究者提出预训练 soft prompt。他们注意到,若干组下游任务与基于无标签预训练语料库的某些自监督任务相关。例如,一些 sentence-pair 分类的任务(如自然语言推理和句子相似度计算),与预训练阶段使用的 NSP 任务相似。如图 3 所示,这些任务都以两个句子作为输入并比较它们的语义。因此,对于这些 sentence-pair 任务来说,由 NSP 预训练的 soft prompt 可以是一个很好的初始化。

假设可以将下游任务分为 m 组:{T_1, T_2, ..., T_m},其中,T_i 是包含 n_i 个下游任务的集合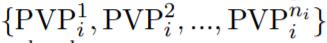 ,其中,
,其中,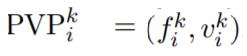 。针对每个组,研究者设计了一个对应的预训练任务
。针对每个组,研究者设计了一个对应的预训练任务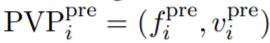 ,在这些预训练任务上预训练了 soft prompt 之后(所有模型参数固定),研究者得到 m 个预训练 prompt:{P_1, P_2, ..., P_m}。在预训练之后,对于 T_i 中的每个任务
,在这些预训练任务上预训练了 soft prompt 之后(所有模型参数固定),研究者得到 m 个预训练 prompt:{P_1, P_2, ..., P_m}。在预训练之后,对于 T_i 中的每个任务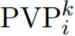 ,研究者继续优化式(2),使用 P_i 作为 soft prompt 的初始化。
,研究者继续优化式(2),使用 P_i 作为 soft prompt 的初始化。
实验及结果
之前的工作(Lester 等,2021;Zhang 等,2021b)表明,T5-XXL 在完全数据设置方面可以与 FT 相媲美。因此在实验部分,对于英文数据集,该研究使用具有 11B 个参数的 T5-XXL 作为基础模型来进行 PT。该研究还对各种尺寸的 T5 进行了 FT 实验,验证了 T5-XXL 在 few-shot 场景中的表现优于其他尺寸,并且基于 T5-XXL 改进 PT 是有意义的。对于中文数据集,该研究基于 CPM-2 进行 PT。由于 CPM-2 不提供其他尺寸的模型,研究者将其与各种尺寸的 mT5 (Xue 等, 2021) 进行比较。
主要实验结果
在英文和中文数据集上的结果如下表 4 所示,其中 FT 的部分展示了各种尺寸 T5 模型的全模型微调结果;PT 的部分展示了 PPT 和其他基线的结果。第一个基线是 Vanilla PT,其中的 soft token 是从正态分布中随机初始化的;第二个基线是混合策略;然后该研究还考虑了 Lester 等人(2021)使用的 LM Adaption。其中 T5 模型通过语言建模进一步预训练 10K 步,以减少预训练和微调之间的差距。除了 PPT 以外,该研究还测试了 PPT 的两种变体:一种是 Hybrid PPT,将精心设计的 hard prompt 与预训练的 soft prompt 相结合;另一种是 Unified PPT,其中所有任务都以 multiple-choice 的格式统一。
表 4 给出了关于有效性的结果:
随着参数数量的增加,FT 的性能有所提升。
在大多数数据集中,PPT 明显优于 Vanilla PT 和 LM Adaption。
PPT 在所有中文数据集和大多数英文数据集上都优于 10B 模型的 FT。
PPT 在大多数数据集上会产生较小的方差,相比之下,一般的 few-shot 学习常存在不稳定性,例如 Vanilla PT。
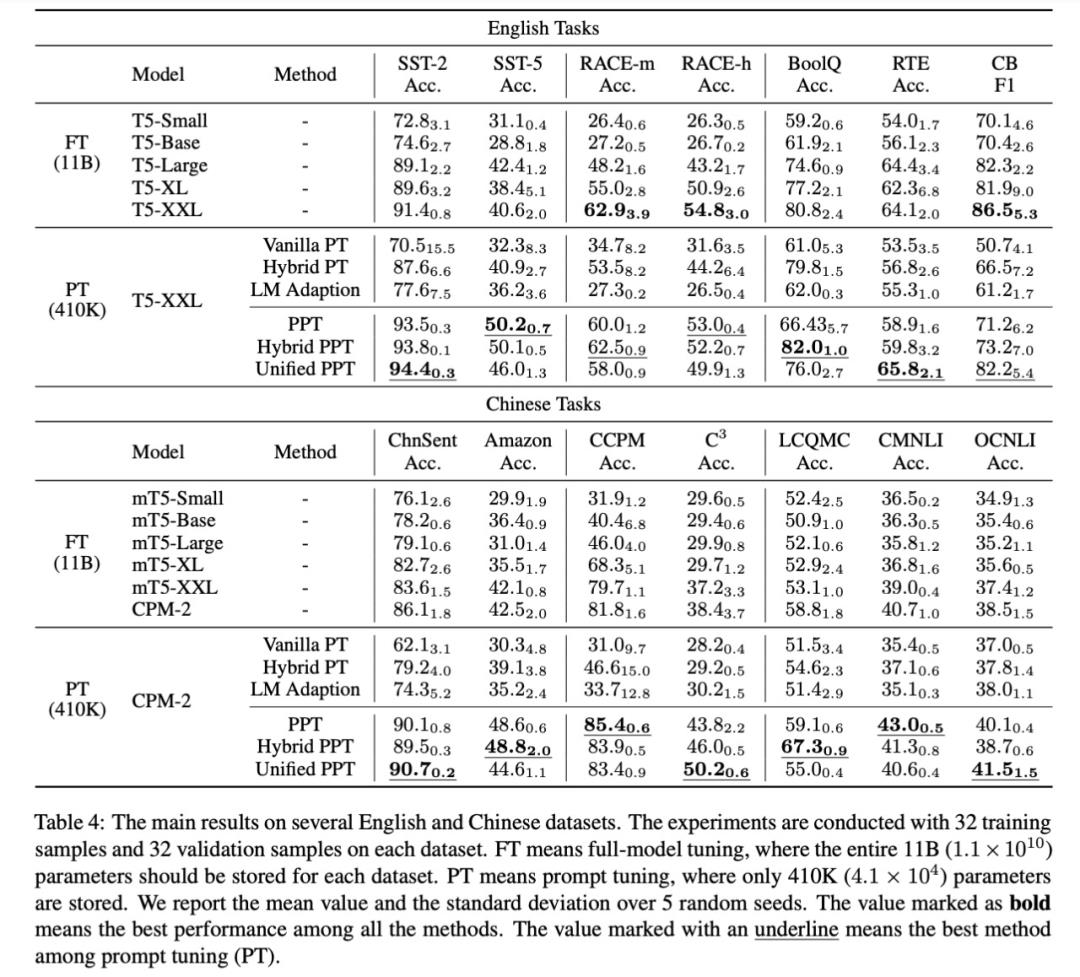
Unified PPT 将所有格式统一为 multiple-choice 的格式,是 PPT 的另一种变体。表 4 的结果表明 Unified PPT 达到了与 PPT 和 Hybrid PPT 相当的性能,并且优于 soft-prompt 调整基线。
觉得不错,请点个在看呀
以上是关于清华刘知远团队巨作!Pre-trained Prompt Tuning框架,让超大模型调参变简单的主要内容,如果未能解决你的问题,请参考以下文章