清华大学-刘知远:表示学习与知识获取
Posted vector11248
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清华大学-刘知远:表示学习与知识获取相关的知识,希望对你有一定的参考价值。
---恢复内容开始---
分布式表示优势:
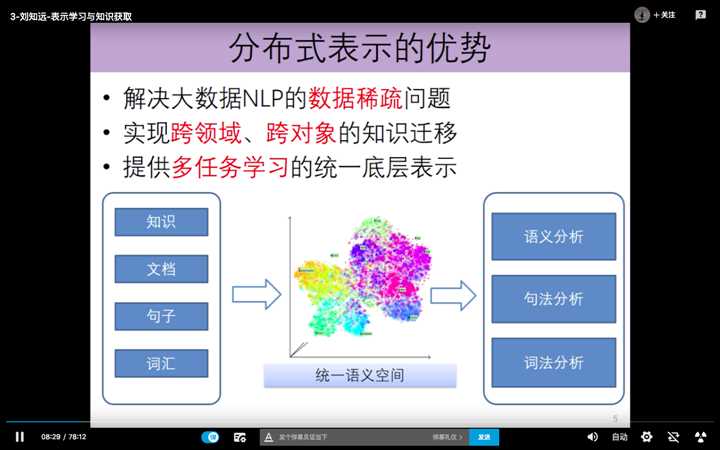
在一段文本当中,进行实体抽取:实际是在计算词汇与文档之间的相似度。
自动摘要技术:是在计算句子与文档之间的相似度。
优势2:由表层的数据,关联关系,能够进一步挖掘出数据底层的深层语义,因果关系。
————————————————————————————————————————
NLP的任务:标注、理解、生成。
从多源异构的文本中,依次进行词汇表示、网络表示、知识表示。
其中词汇表示,包括实体、短语、文档、词义、句子的表示。
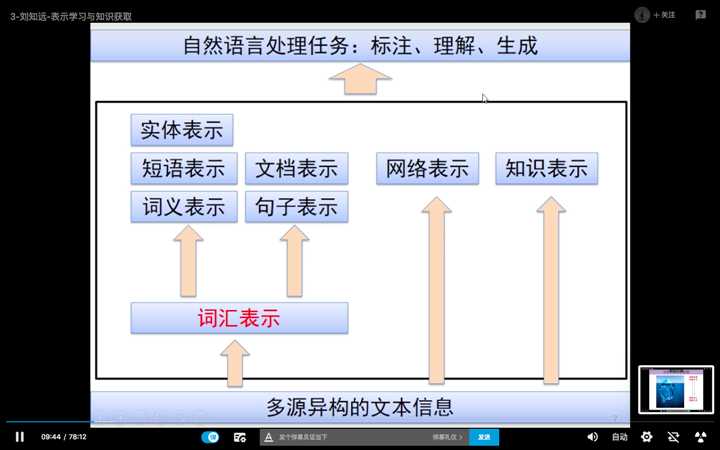
下面详细讲一讲词汇的表示。
word2Vec 主要包括2个模型
cbow: 知道一个词的前两个词和后两个词,推导出该词。
skip-gram: 知道改词,推导其前后两个词。
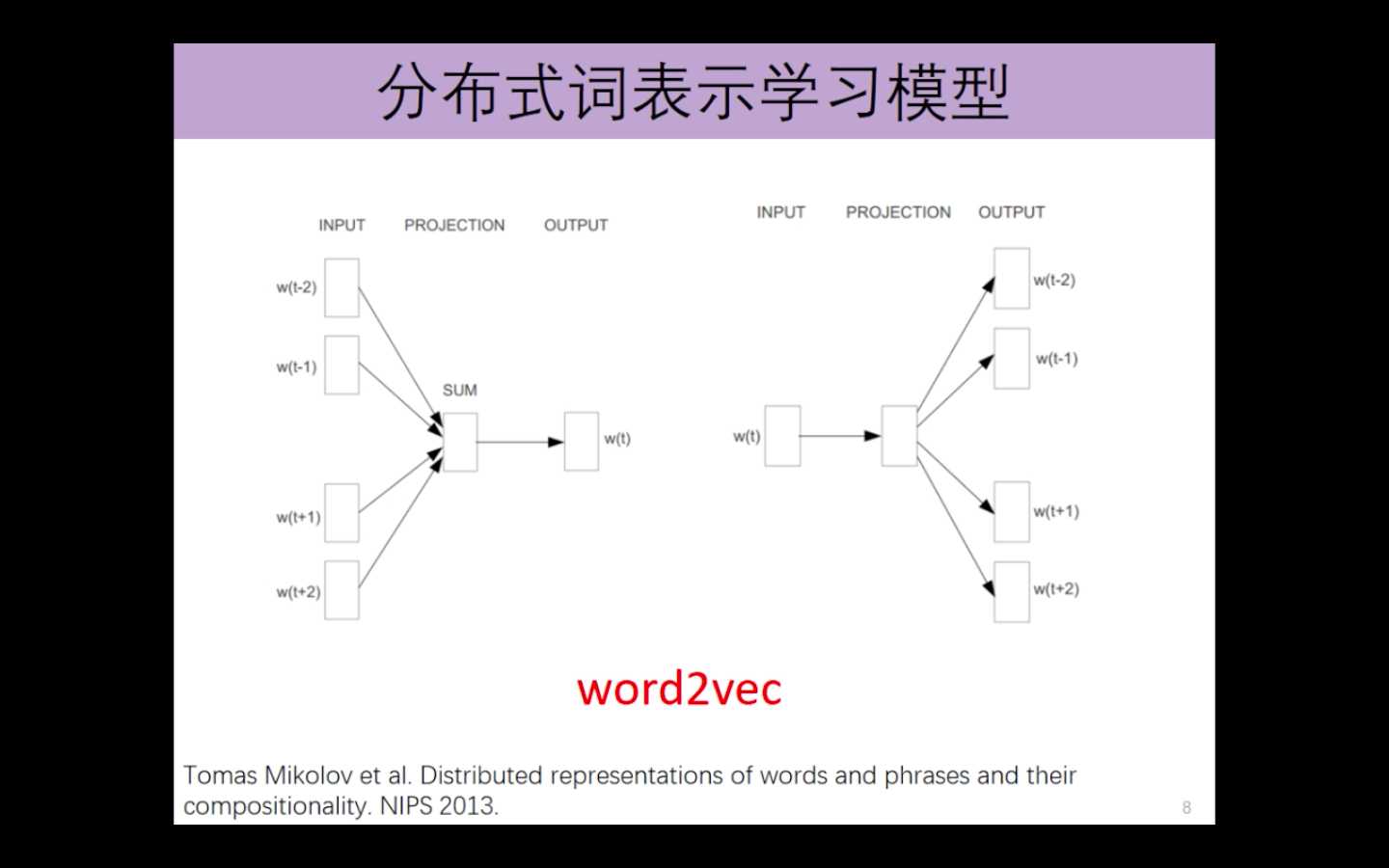
分布式词表示学习模型,可以进行词汇相似度的计算。比如,输入China ,计算如下。
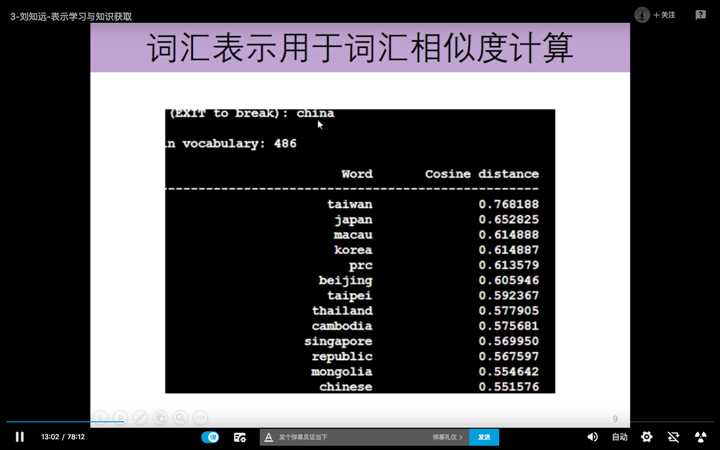
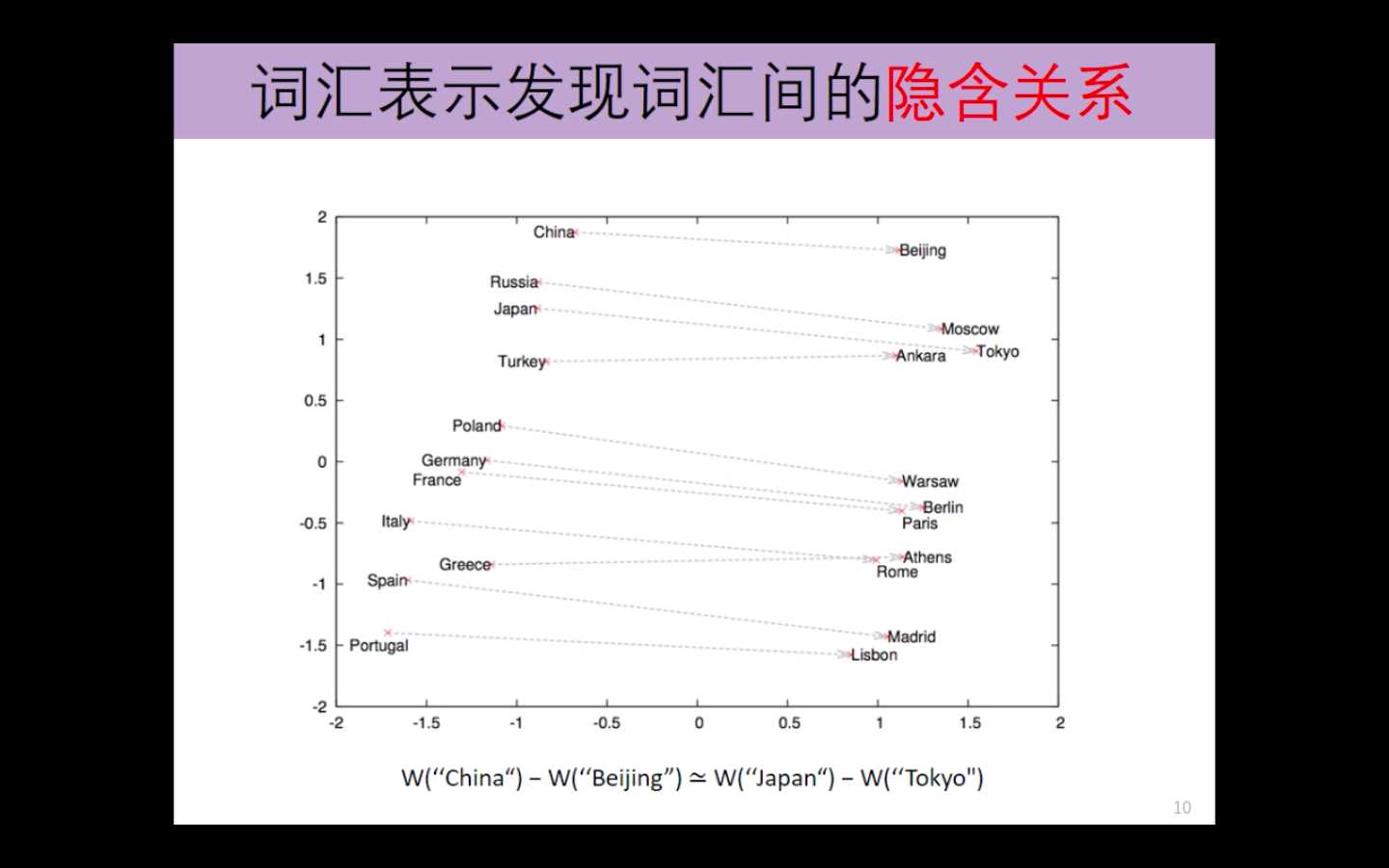
词汇表示还可以发现词汇间的隐含关系
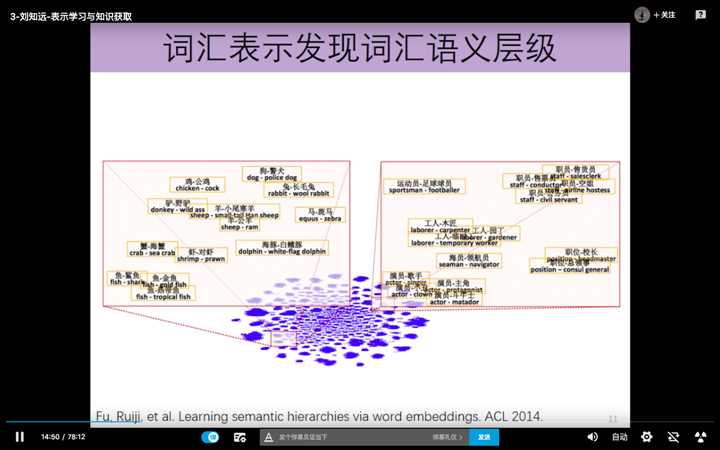
词汇表示还可以发现词汇之间的语义层级关系
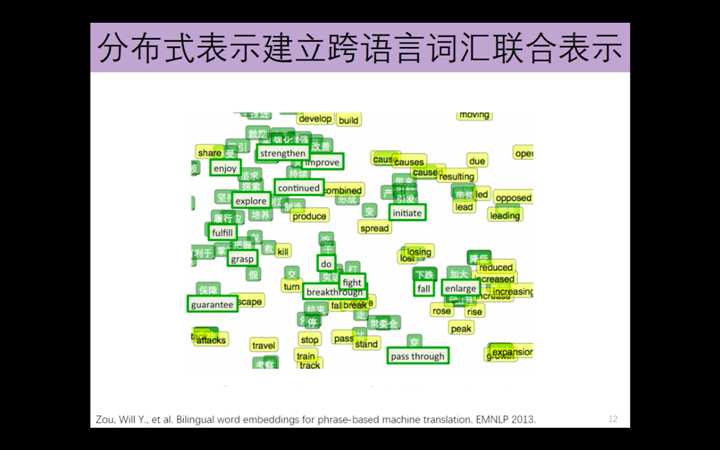
跨语言词汇联合表示
视觉-文本联合表示

一个有意思的任务:给你一张图,生成该图的一句话的简要描述。image caption generation
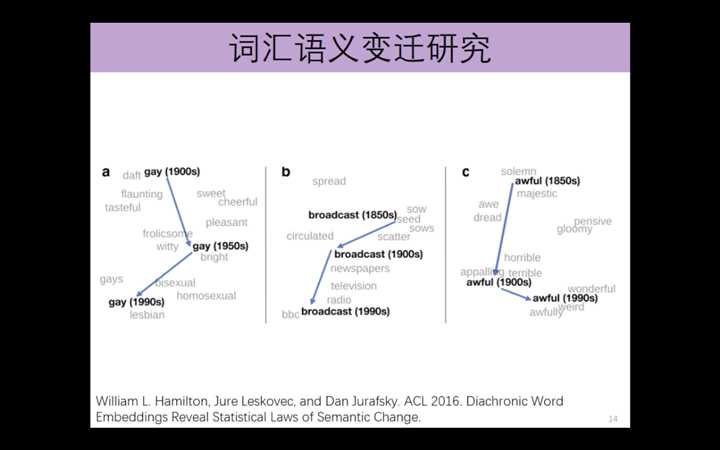
词汇语义变迁研究
——————————————————————————————————————————————————————————————
知识表示:
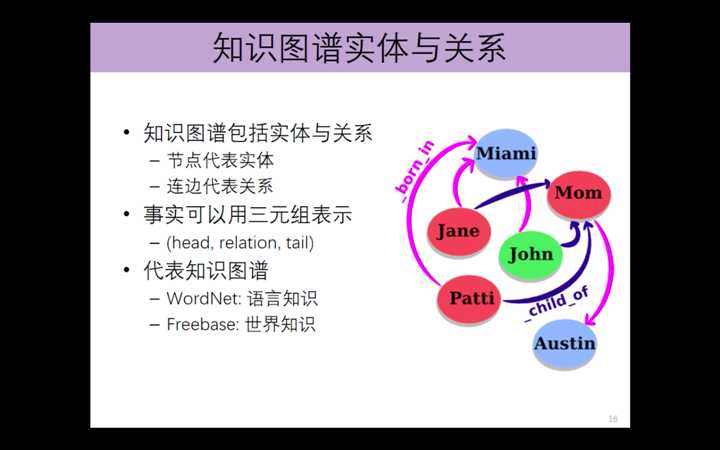
知识表示与关系抽取
- 融合文本与知识进行关系抽取
- 利用关系路径进行关系抽取
- 利用远程监督多实例进行关系抽取

融合文本与知识进行关系抽取
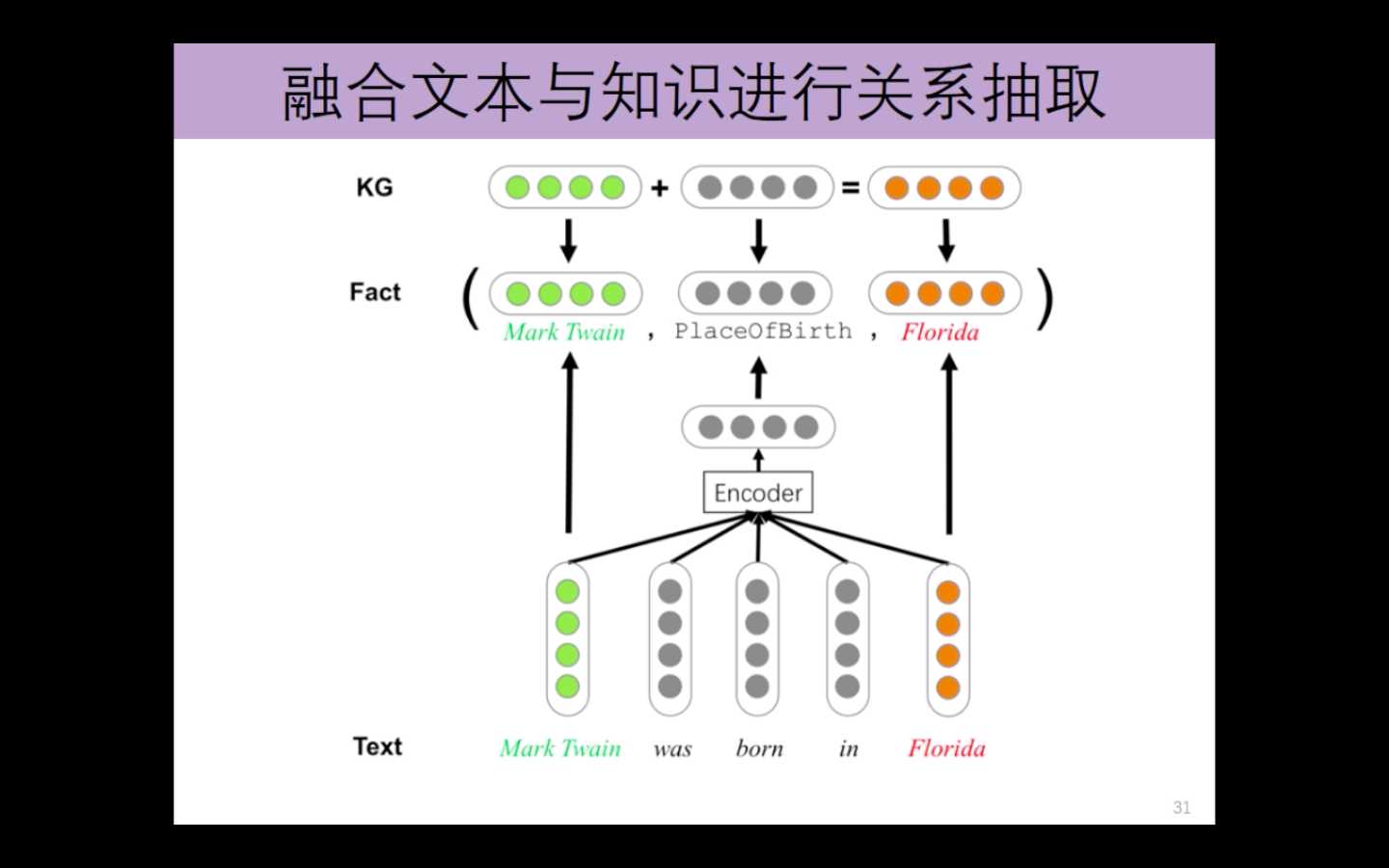
融合实体描述的知识表示

zero-shot场景下的 关系预测
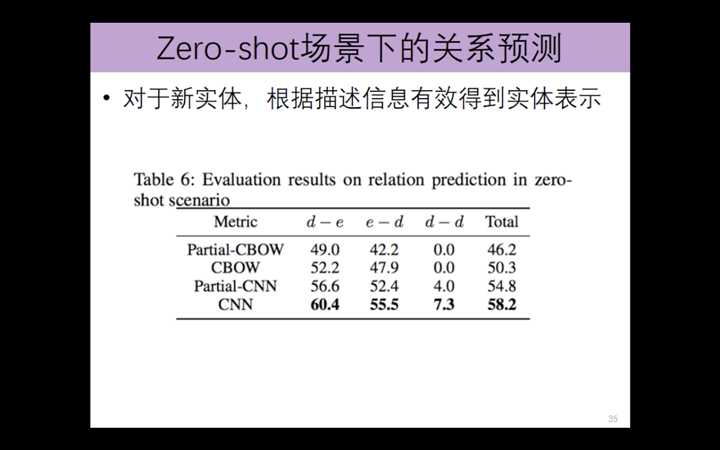
---恢复内容结束---
以上是关于清华大学-刘知远:表示学习与知识获取的主要内容,如果未能解决你的问题,请参考以下文章