爬动漫“上瘾”之后,放弃午休,迫不及待的用Python薅了腾讯动漫的数据,啧啧啧
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬动漫“上瘾”之后,放弃午休,迫不及待的用Python薅了腾讯动漫的数据,啧啧啧相关的知识,希望对你有一定的参考价值。
这是爬虫 120 例的第 10 篇
本篇博客在编写的过程中,擦哥跟我说,他顺带复习了一遍 《一人之下》 和 《 至尊瞳术师:绝世大小姐》 ,doge。
阅读本文,你将收获
- 5000+腾讯动漫数据;
- 正则表达式区域提取;
- 多线程爬虫。
腾讯动漫数据大采集术
目标数据源分析
爬取目标网站
本次抓取的目标网站为:https://ac.qq.com/Comic/index/page/1。
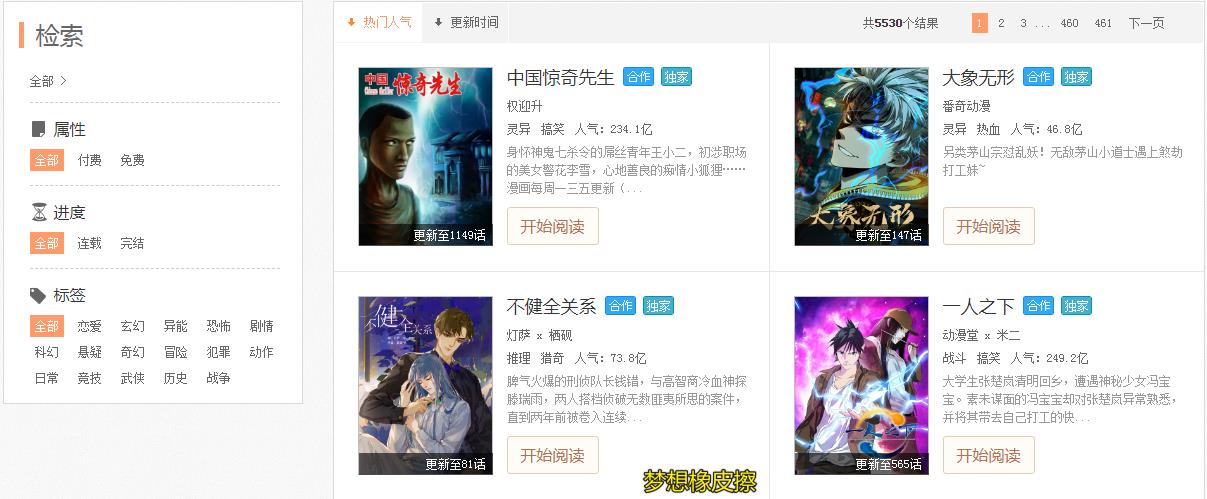
针对上图数据,本文将采集下图框选区域数据,同时本文将通过正则表达式进行区域块匹配。
使用的 Python 模块
requests 模块,re 模块,fake_useragent 模块,threading 模块。
重点学习内容
本文在学习的过程中,重点掌握 fake_useragent 模块与正则表达式分块提取,以及 CSV 文件特殊符号问题。
列表页分析
通过开发者工具页面,查看网页数据由服务器直接返回,顾直接通过正则表达式提取数据即可。
提取过程中,先提取每一动漫所在的 li 标签,然后再提取标签内具体数据信息。
页面规则比较简单,罗列如下:
https://ac.qq.com/Comic/index/page/1
https://ac.qq.com/Comic/index/page/2
https://ac.qq.com/Comic/index/page/3
整理需求如下
- 限制 5 个线程爬取数据;
- 写入文件通过线程互斥锁,防止异常;
- 清洗数据,再存储;
- 因为保存格式为
CSV文件,所以需要处理,,"等特殊符号。
编码时间
本次爬虫学习引入一个新的库,fake_useragent,该库用于随机获取请求参数中的 User-Agent,
使用前需提前通过 pip 进行安装,简易 Demo 如下:
from fake_useragent import UserAgent
ua = UserAgent()
headers= {'User-Agent':ua.random}
如果上述代码出现 BUG,一般禁用浏览器缓存问题即可。
ua = UserAgent(use_cache_server=False)
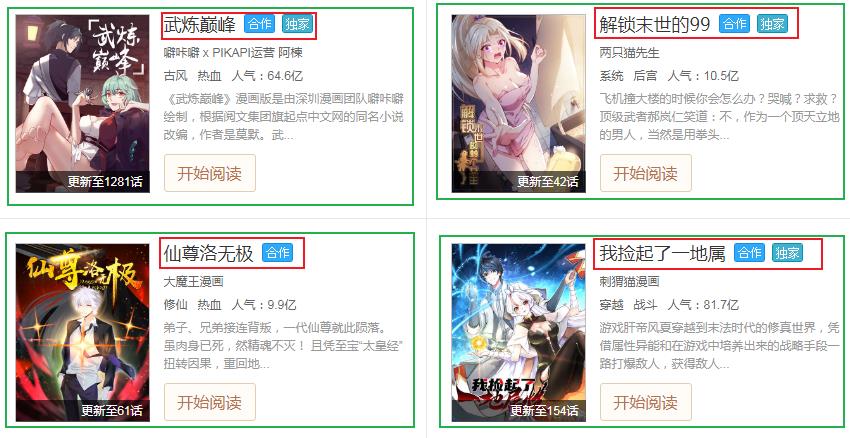
另一个在本文需要注意的一点是,优先使用正则表达式提取父级标签,再在父级标签内部提取子级标签,具体如下图所示。第一步提取绿色方框数据,第二步提取红色方框数据。
在写入 CSV 文件处,需要注意使用了线程互斥锁,防止文件写入异常。锁的声明在 main 部分,案例完整代码如下所示,部分逻辑直接写在注释部分。
import requests
from fake_useragent import UserAgent
import re
import threading
def replace_mark(my_str):
return my_str.replace(",", ",").replace('"', "“")
def format_html(html):
# 各提取正则表达式部分,编写人橡皮擦@CSDN
li_pattern = re.compile(
'<li\\sclass="ret-search-item clearfix">[\\s\\S]+?</li>')
title_url_pattern = re.compile(
'<a href="(.*?)" target="_blank" title=".*?">(.*?)</a>')
sign_pattern = re.compile('<i class="ui-icon-sign">签约</i>')
exclusive_pattern = re.compile('<i class="ui-icon-exclusive">独家</i>')
author_pattern = re.compile(
'<p class="ret-works-author" title=".*?">(.*?)</p>')
tags_pattern = re.compile('<span href=".*?" target="_blank">(.*?)</span>')
score_pattern = re.compile('<span>人气:<em>(.*?)</em></span>')
items = li_pattern.findall(html)
# 依次迭代提取的 li 标签
for item in items:
title_url = title_url_pattern.search(item)
title = title_url.group(2)
url = title_url.group(1)
sign = 0
exclusive = 0
# 数据非空检验
if sign_pattern.search(item) is not None:
sign = 1
if exclusive_pattern.search(item) is not None:
exclusive = 1
author = author_pattern.search(item).group(1)
tags = tags_pattern.findall(item)
score = score_pattern.search(item).group(1)
# 锁开启
lock.acquire()
with open("./acqq.csv", "a+", encoding="utf-8") as f:
f.write(
f'{replace_mark(title)},{url},{sign},{exclusive},{replace_mark(author)},{"#".join(tags)},"{replace_mark(score)}" \\n')
# 锁关闭
lock.release()
def run(index):
ua = UserAgent(use_cache_server=False)
response = requests.get(
f"https://ac.qq.com/Comic/index/page/{index}", headers={'User-Agent': ua.random})
html = response.text
format_html(html)
# 注意释放线程
semaphore.release()
lock = threading.Lock()
if __name__ == "__main__":
num = 0
semaphore = threading.BoundedSemaphore(5)
lst_record_threads = []
for index in range(1, 462):
print(f"正在抓取{index}")
semaphore.acquire()
t = threading.Thread(target=run, args=(index, ))
t.start()
lst_record_threads.append(t)
for rt in lst_record_threads:
rt.join()
print("数据爬取完毕")
上述代码补充说明:
在提取过程中发现,变量 title,author,score 的值存在特殊符号,例如 ",,,这些符号会导致 CSV 文件乱版,针对该内容增加 replace_mark 函数,将这些符号进行中文化处理,即 " → “, , → ,。
抓取结果展示时间
本案例是 Python 爬虫 120 例的第 10 例,如果你已经全部打卡,相信你对爬虫已经建立了初步的认知,下一篇橡皮擦将引入 lxml 模块,更换 re 模块,进行数据提取,爬虫 120 例学习进入第二阶段,一起加油。
完整代码下载地址:https://codechina.csdn.net/hihell/python120,NO10。
以下是爬取过程中产生的各种学习数据,如果只需要数据,可去下载频道下载~。
爬取资源仅供学习使用,侵权删。
抽奖时间
评论数过 100,随机抽取一名幸运读者,
获取 29.9 元《Python 游戏世界》专栏 1 折购买券一份,只需 2.99 元。
今天是持续写作的第 173 / 200 天。可以点赞、评论、收藏啦。
相关阅读
- 10 行代码集 2000 张美女图,Python 爬虫 120 例,再上征途
- 通过 Python 爬虫,发现 60%女装大佬游走在 cosplay 领域
- Python 千猫图,简单技术满足你的收集控
- 熊孩子说“你没看过奥特曼”,赶紧用 Python 学习一下,没想到
- 技术圈的【多肉小达人】,一篇文章你就能做到
- 我用 Python 连夜离线了 100G 图片,只为了防止网站被消失
- 对 Python 爬虫编写者充满诱惑的网站,《可爱图片网》,瞧人这网站名字起的
- 5000 张高清壁纸大图(手机用),用 Python 在法律的边缘又试探了一把
- 10994 部漫画信息,用 Python 实施大采集,因为反爬差一点就翻车了
以上是关于爬动漫“上瘾”之后,放弃午休,迫不及待的用Python薅了腾讯动漫的数据,啧啧啧的主要内容,如果未能解决你的问题,请参考以下文章