过滤爬虫爬取下来的关键字
v1,来不及了,先上车
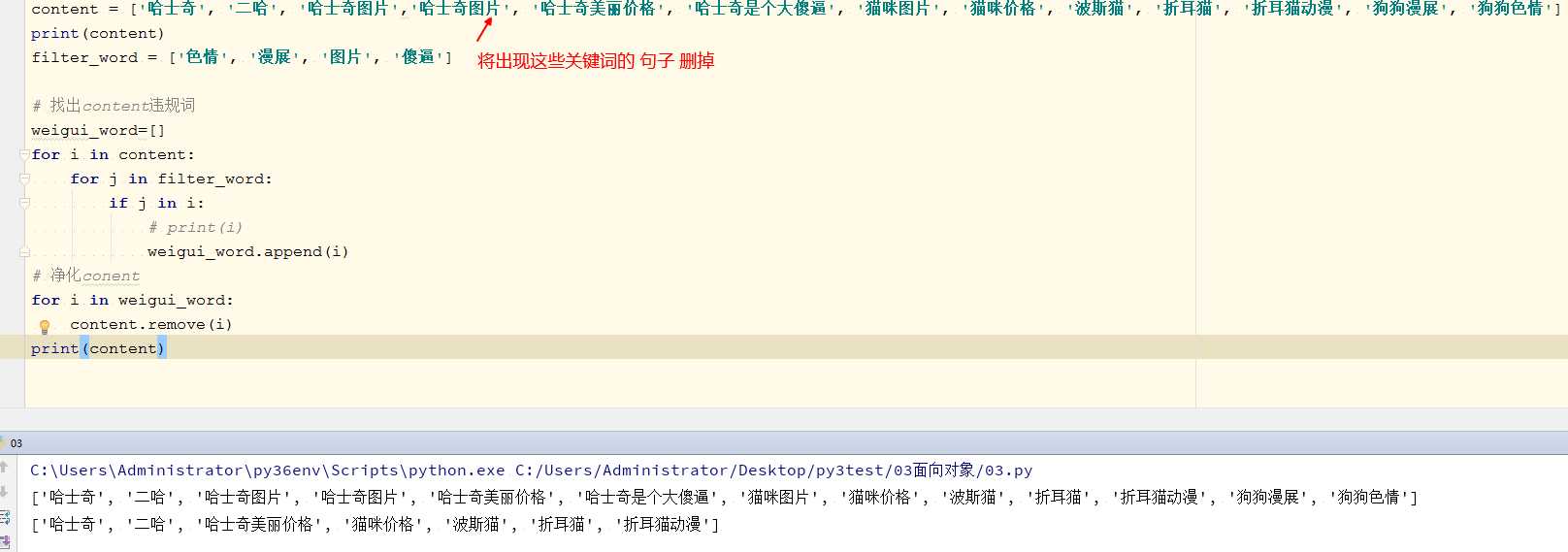
content = ['哈士奇', '二哈', '哈士奇图片','哈士奇图片', '哈士奇美丽价格', '哈士奇是个大傻逼', '猫咪图片', '猫咪价格', '波斯猫', '折耳猫', '折耳猫动漫', '狗狗漫展', '狗狗色情']
print(content)
filter_word = ['色情', '漫展', '图片', '傻逼']
# 找出content违规词
weigui_word=[]
for i in content:
for j in filter_word:
if j in i:
# print(i)
weigui_word.append(i)
# 净化conent
for i in weigui_word:
content.remove(i)
print(content)
v2: 改进循环
content = ['哈士奇', '二哈', '哈士奇图片', '哈士奇图片', '哈士奇美丽价格', '哈士奇是个大傻逼', '猫咪图片', '猫咪价格', '波斯猫', '折耳猫', '折耳猫动漫', '狗狗漫展', '狗狗色情']
print(content)
filter_word = ['色情', '漫展', '图片', '傻逼']
# 合规填充天空到这个列表
hegui_word = []
for i in content:
# 如果 关键字不在 content某项,则计数
count = 0
for j in filter_word:
if j not in i:
count += 1
if count == len(filter_word):
hegui_word.append(i)
print(hegui_word)
v3: 简化代码,for else
for else: 顺利循环完说明not in 才执行else, 一旦in 即break,不执行else
keywords = ['哈士奇', '二哈', '哈士奇图片', '哈士奇图片', '哈士奇美丽价格', '哈士奇是个大傻逼', '猫咪图片', '猫咪价格', '波斯猫', '折耳猫', '折耳猫动漫', '狗狗漫展', '狗狗色情']
bad_keys = ['色情', '漫展', '图片', '傻逼']
res=[]
for key in keywords:
for bkey in bad_keys:
if bkey in key:
break
else:
res.append(key)
print(res)