iOS底层探索之LLVM——初识LLVM
Posted 卡卡西Sensei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iOS底层探索之LLVM——初识LLVM相关的知识,希望对你有一定的参考价值。
1. 写在前面
现在出去面试,启动优化是绕不开的,到底我们的 APP 该如何去进行优化呢 ?在优化之前我们必须要先了解 LLVM,那什么是 LLVM呢?

在介绍LLVM之前,先来认识一下解释型语言和编译型语言。
我们编写的
源代码是偏向于我们人类直接的语言,我们非常轻松的就理解了,但是对于计算机硬件(CPU)而言,简直就是个天书,计算机是无法直接运行的。计算机只能识别某些特定的二进制指令,所以我们的代码在程序真正运行之前必须将源代码转换成二进制指令。源代码转换成二进制指令,不同的编程语言有不同的规定。
解释型语言
有的编程语言可以一边执行一边转换,不会生成可执行文件再去执行,这种编程语言称为解释型语言,使用的转换工具称为解释器,比如 Python、javascript、php等。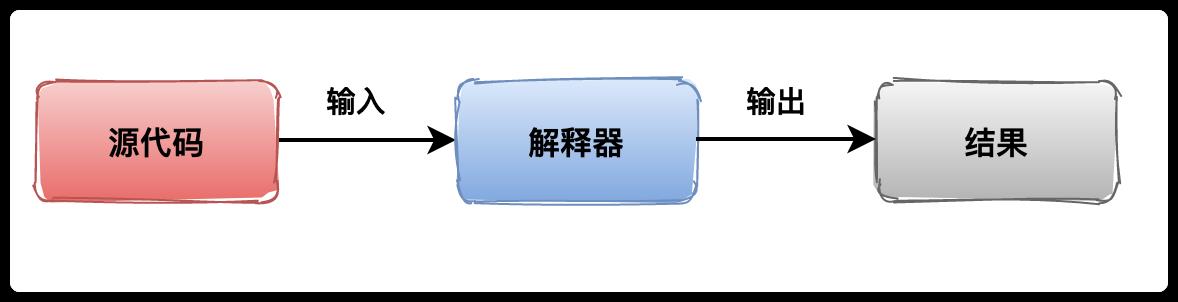
下面就举个例子,使用
vim命令新建立一个python文件,后缀为.py,写入代码print("hello world!"),通过python命令,解释这段代码,打印一下hello world !这句话。

我看可以看到解释型语言,它是边解释边执行,不可脱离解释器环境运行。
MAC电脑自带了Python环境,无需另外手动配置环境。
编译型语言
有的编程语言要转换成二进制指令,也就是生成一个可执行程序这种编程语言称为编译型语言,使用的转换工具称为编译器,比如C语言、C++、OC等。

编译型语言也同样举个例子,新建立一个
C文件,写入如下代码:
#include<stdio.h>
int main (int argc,char *agrv[])
{
printf("hello world\\n");
return 0;
}
通过clang hello.c命令,进行编译处理,会生成一个可执行文件,如下图中红色的a.out文件。

这个可执行文件,可以直接运行,通过./a.out即可运行,如图中也可以正常输出hello world这句话。
编译型语言是先整体编译,再执行,运行速度快,任意改动需重新编译,可脱离编译环境运行。
小结:
-
解释型语言:读到相应代码就直接执行。
-
编译型语言:先将代码编译成计算机可以识别的二进制文件,才能执行。
扩展:
通过
open /usr/bin命令可以查看,电脑上安装的一些系统软件。
/usr不是user的缩写,其实usr是Unix Software Resource的缩写, 也就是Unix操作系统软件资源所放置的目录,而不是用户的数据;所有系统默认的软件都会放置到/usr, 系统安装完时,这个目录会占用最多的硬盘容量。
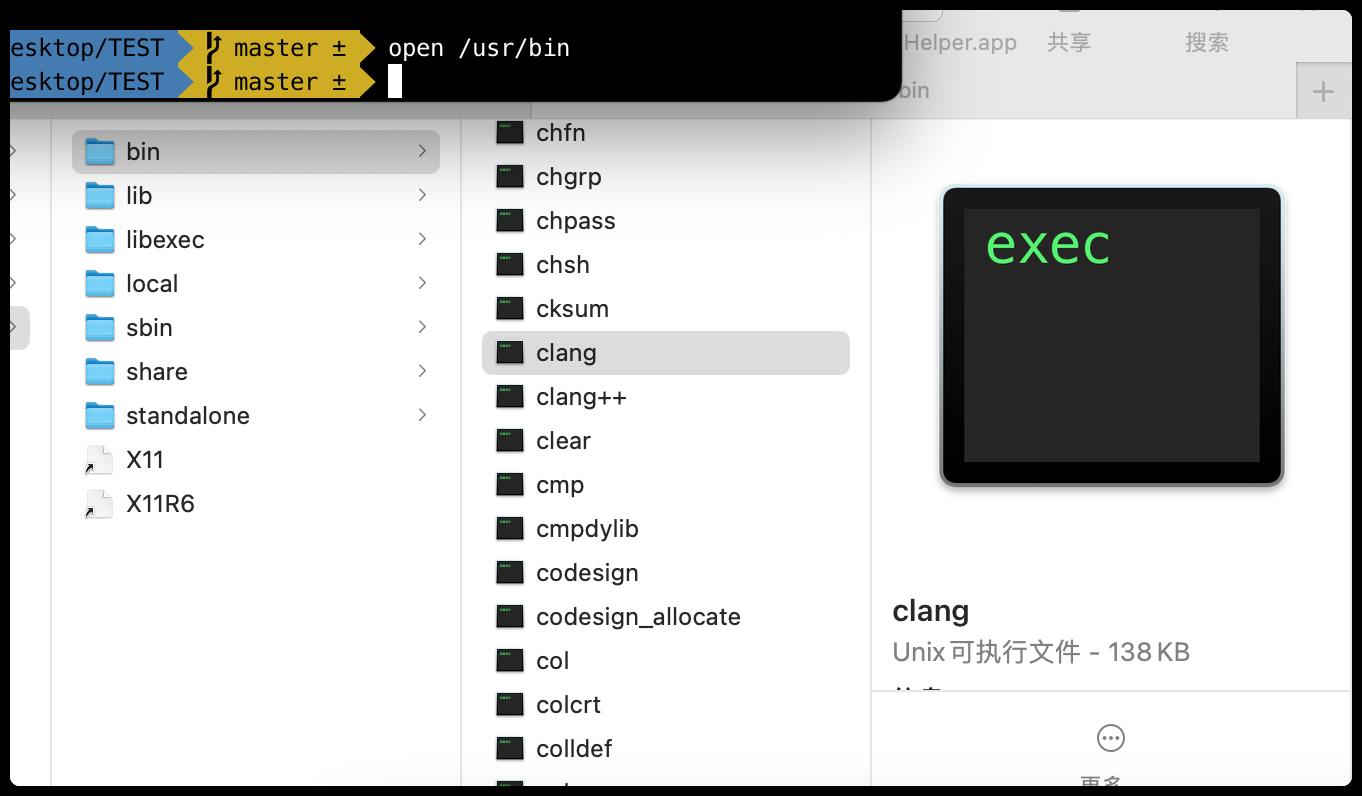
在该目录下可以看到,有我们的
clang编译器,还有Python解释器,如下图所示:
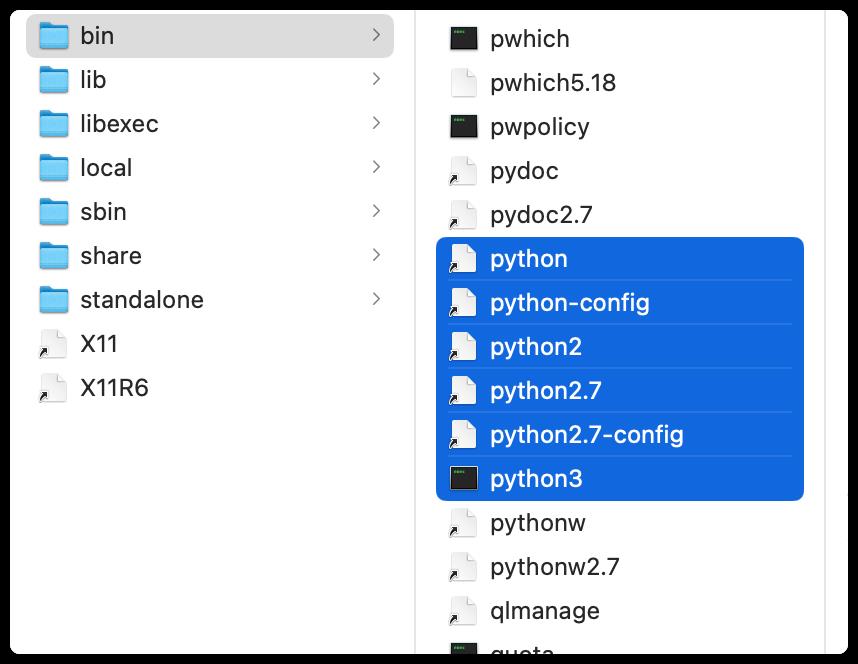
MacOS系统 默认安装的是python2的环境,输入python,按下enter回车键,可以查看:
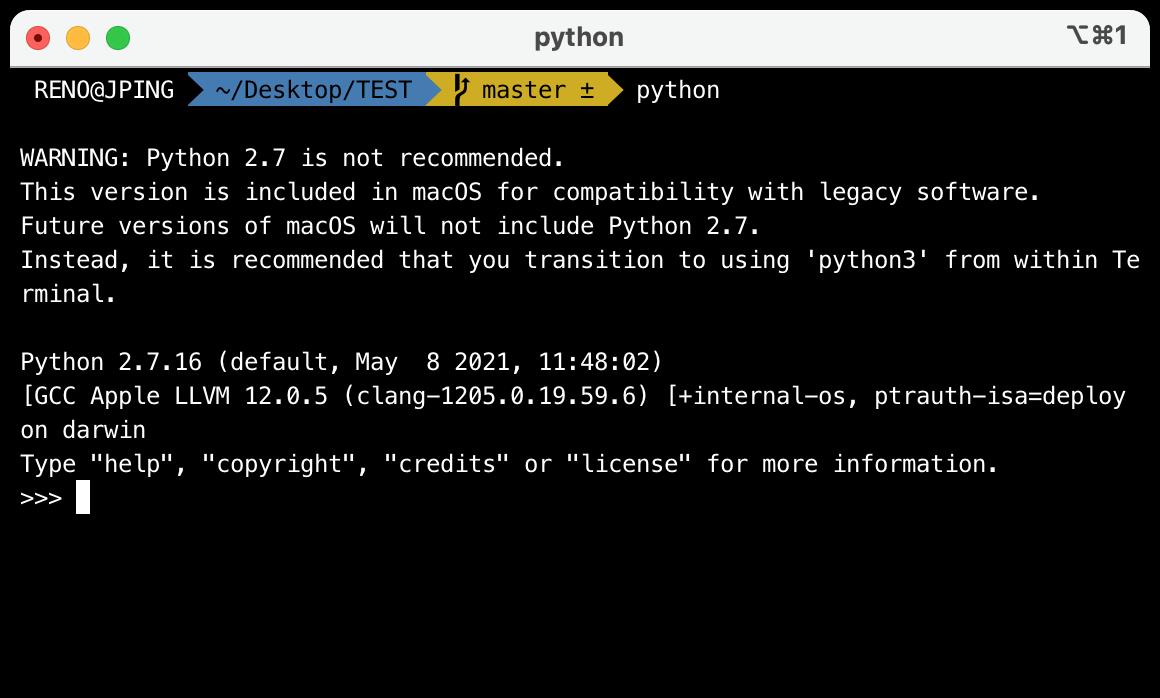
警告:不推荐使用
Python 2.7,为了与旧软件兼容macOS中才包含了此版本。macOS的未来版本将不包含Python 2.7。
相反,建议您从终端内过渡到使用“python3”。
如果你是python的开发者,那么日常使用的是python3,可以在终端中输入python3查看是否支持:
可以看到我的电脑是支持的,我这里的版本是Python 3.7.7的版本,如果你的电脑没有支持,可以去python官网下载。
2. LLVM
LLVM简介
LLVM是构架编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time),对开发者保持开放,并兼容已有脚本。
LLVM计划启动于2000年,最初由美国UIUC大学的 ChrisLattner博士主持开展。2006年ChrisLattner加盟AppleInc并致力于LLVM在Apple开发体系中的应用。 Apple也是LLVM计划的主要资助者。目前LLVM已经被苹果ios开发工具、Xilinx Vivado、Facebook、Google等各大公司采用。
传统编译器设计
我们先来看看传统编译器设计是怎么样的,如下图所示:
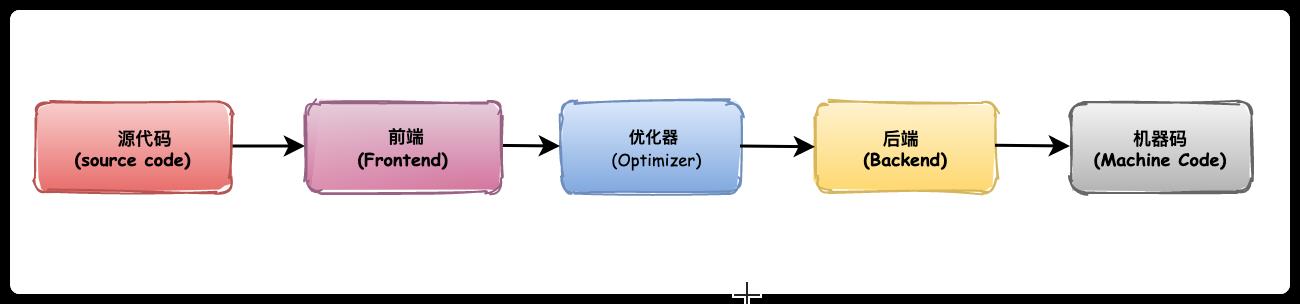
- 编译器前端(Frontend)
编译器前端的任务是解析源代码。它会进行:词法分析,语法分析,语义分析,检查源代码是否存在错误,然后构建抽象语法树(Abstract Syntax Tree, AST),LLVM的前端还会生成中间代码(intermediate representation,IR)。
- 优化器(Optimizer)
优化器负责进行各种优化,改善代码的运行时间,例如消除冗余计算等。
- 后端(Backend)/代码生成器(CodeGenerator)
将代码映射到目标指令集,生成机器语言,并且进行机器相关的代码优化。
iOS的编译器架构
ObjectiveC/C/C++使用的编译器前端是Clang,Swift是Swift,后端都是LLVM。

LLVM的设计
当编译器决定支持多种源语言或多种硬件架构时,LLVM最重要的地方就来了。
其他的编译器如GCC是非常成功的一款编译器,但由于它是作为整体应用程序设计的,因此它的用途受到了很大的限制。
LLVM设计的最重要方面是,使用通用的代码表示形式(IR),它是用来在编译器中表示代码的形式。所以LLVM可以为任何编程语言独立编写前端,并且可以为任意硬件架构独立编写后端。
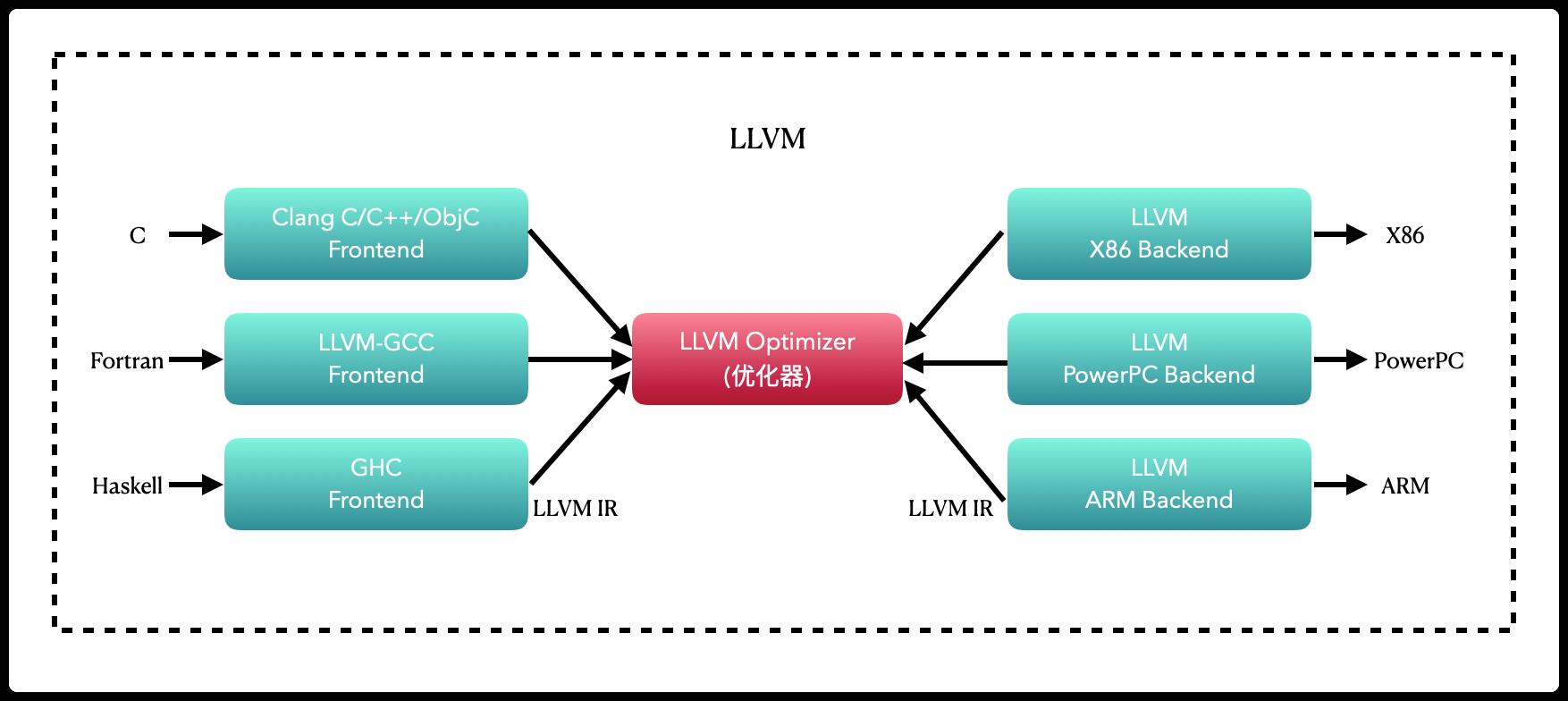
- Clang
对于我们的开发人员来说,看得见摸得着的,接触最多的就是我们的Clang。
Clang是LLVM项目中的一个子项目。它是基于LLVM架构的轻量级编译器,诞生之初是为了替代GCC,提供更快的编译速度。它是负责编译C、C++、Objecte- C语言的编译器,它属于整个LLVM架构中的,编译器前端。对于开发者来说,研究Clang可以给我们带来很多好处。
3. 编译流程
那么我们写一段代码,来测试一下,看看编译流程是什么样子的。
int main(int argc, const char * argv[]) {
@autoreleasepool {
}
return 0;
}
编译的各个阶段
通过一下命令,可以打印源码的编译阶段。
clang -ccc-print-phases main.m
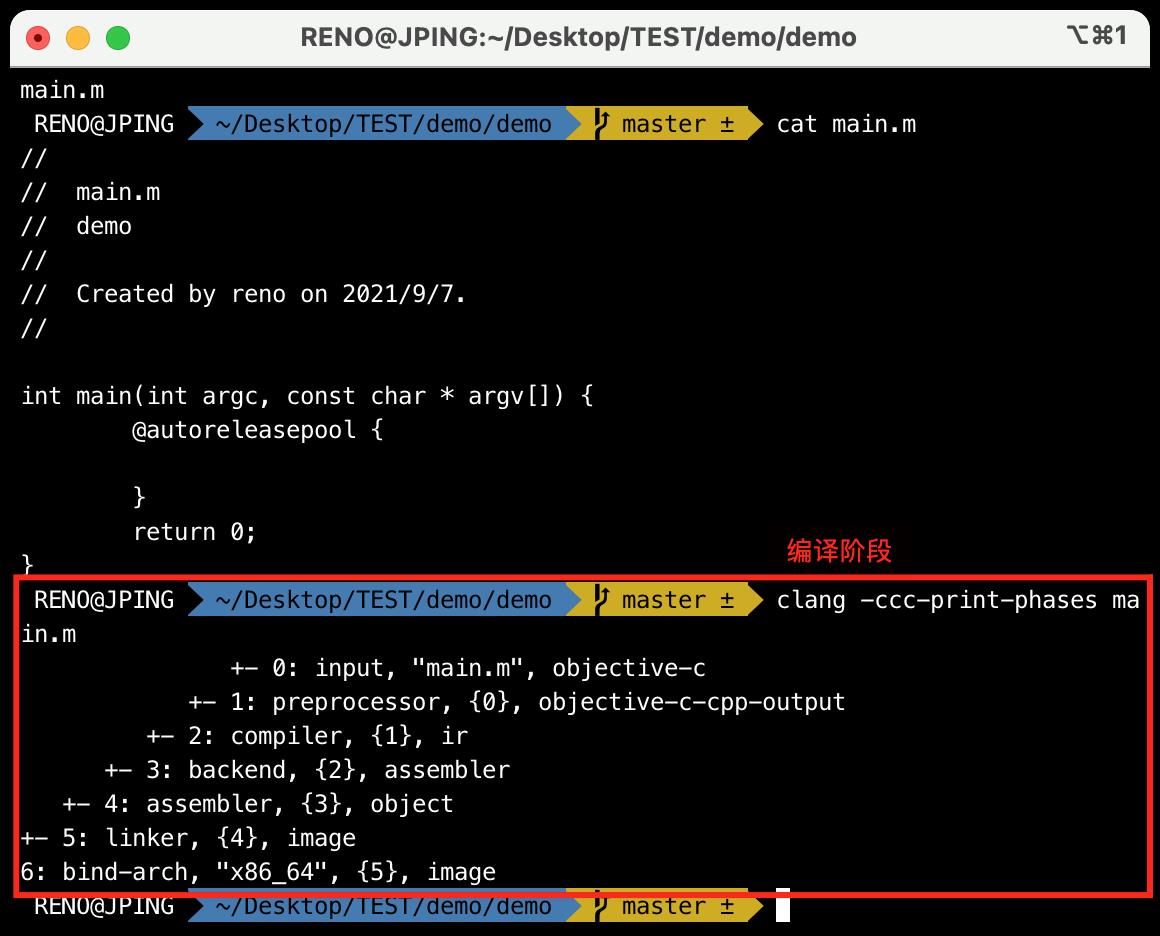
- 0:
输入文件:找到源文件。 - 1:
预处理阶段:这个过程处理包括宏的替换,头文件的导入。 - 2:
编译阶段:进行词法分析、语法分析、检测语法是否正确,最终生成IR。 - 3:
后端:这里LLVM会通过一个一个的Pass(可以理解为一个节点)去优化,每个Pass做一些事情,最终生成汇编代码。 - 4:汇编代码
生成目标文件。 - 5:
链接:链接需要的动态库和静态库,生成相应的镜像可执行文件。 - 6:根据不同的系统架构,生成对应的可执行文件。
上面已经知道了编译的流程了,那么我们一步一步去看看各个阶段是什么样子的。
#import <stdio.h>
#define B 50
int main(int argc, const char * argv[]) {
int a = 10;
int c = 20;
printf("%d",a + c + B);
return 0;
}
预处理阶段
执行如下命令
clang -E main.m >> main1.m
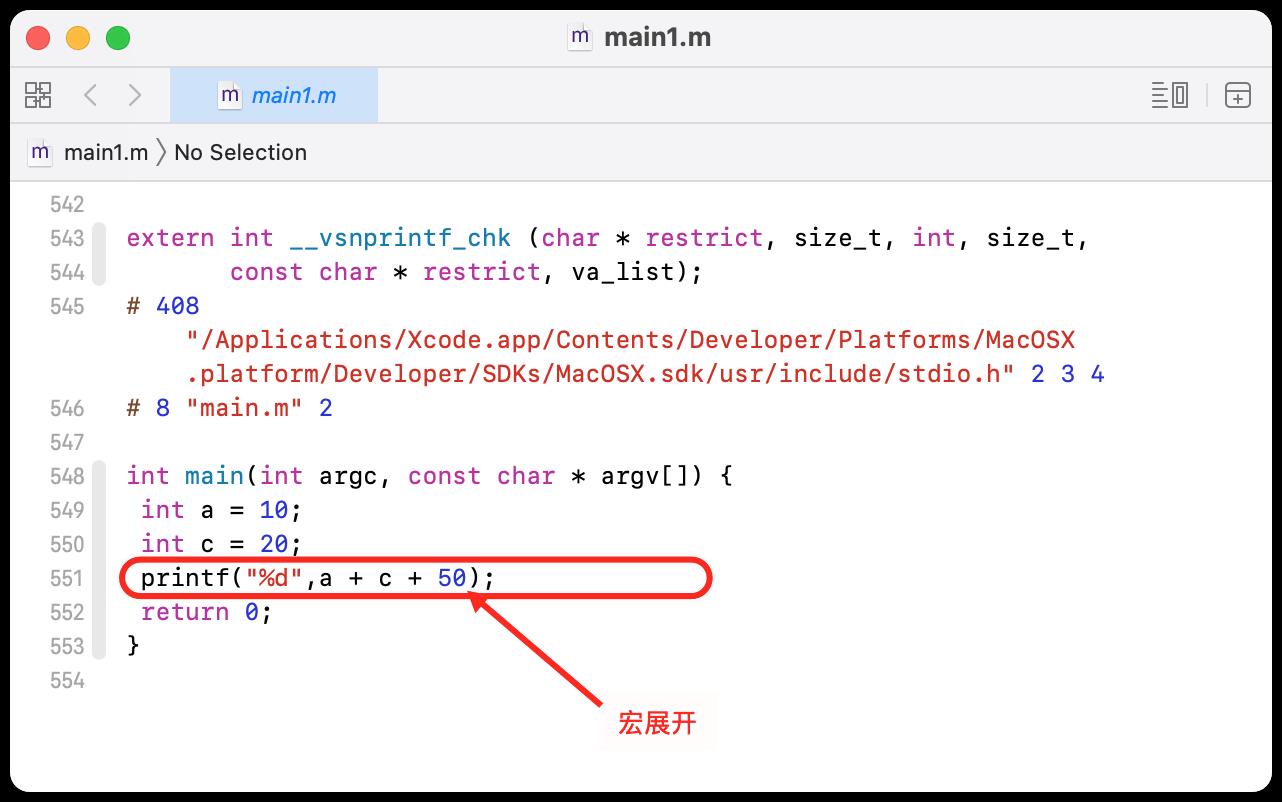
执行完毕后,我们可以在 main1.m 的文件中,可以看到头文件的导入和宏的替换。
词法分析
编译阶段-词法分析
预处理完成后就会进行词法分析,这里会把代码切成一个个Token,比如大小括号,等于号还有字符串等。
#import <stdio.h>
#define B 50
typedef int JP_INT;
int main(int argc, const char * argv[]) {
JP_INT a = 10;
JP_INT c = 20;
printf("%d",a + c + B);
return 0;
}
clang -fmodules-fsyntax-only -Xclang -dump-tokens main.m
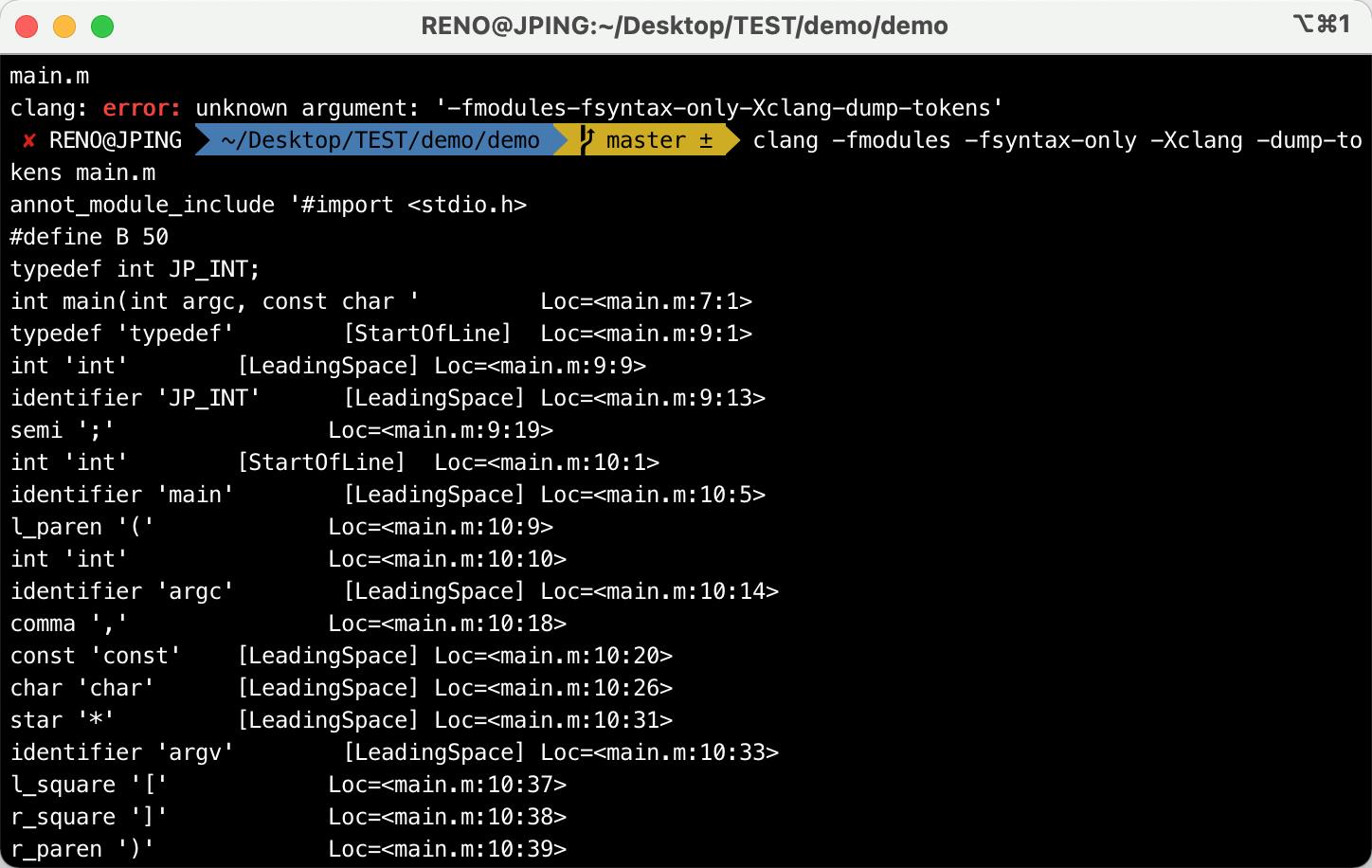
命令运行之后,进行了词法分析,每一行的代码都分开了,切成一个个Token。
语法分析
词法分析完成之后就是语法分析,它的任务是验证语法是否正确。在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等,然后将所有节点组成抽象语法树(AbstractSyntaxTree,AST)。语法分析其目的就是对源程序进行分析判断,在结构上是否正确。
clang -fmodules -fsyntax-only -Xclang -ast-dump main.m
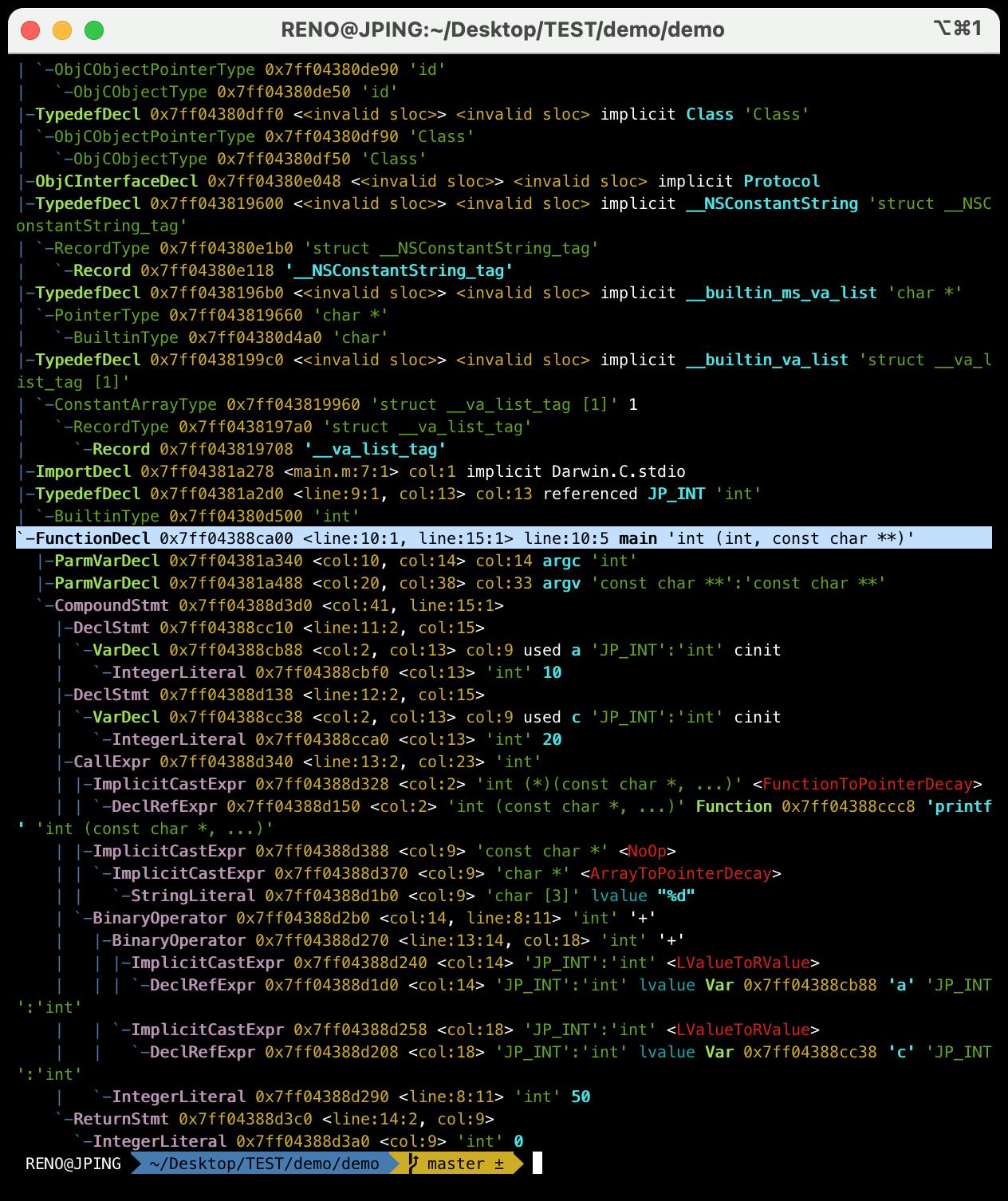
FunctionDecl函数方法声明,范围是第10行第1个字符开始 到第15行第1个字符结束。第10行第5个字符开始,名称叫main,返回值是int类型,第一个参数的类型是int,第二个参数的类型是const char **。这里为什么是const char **呢?因为数组的名称就是一个指针,const char ** argv等于const char * argv[]。

ParmVarDecl参数,当前行的第10个字符到第14个字符是int类型所占有,第14个字符是参数argc。CompoundStmt复合语句,当前行第41个字符到,第15行代码的第1个字符,也就是{}包裹的范围。- 这两句代码
JP_INT a = 10; JP_INT c = 20;对应的是下面这个
CallExpr调用表达式, 代码中的printf函数的打印语法分析如下图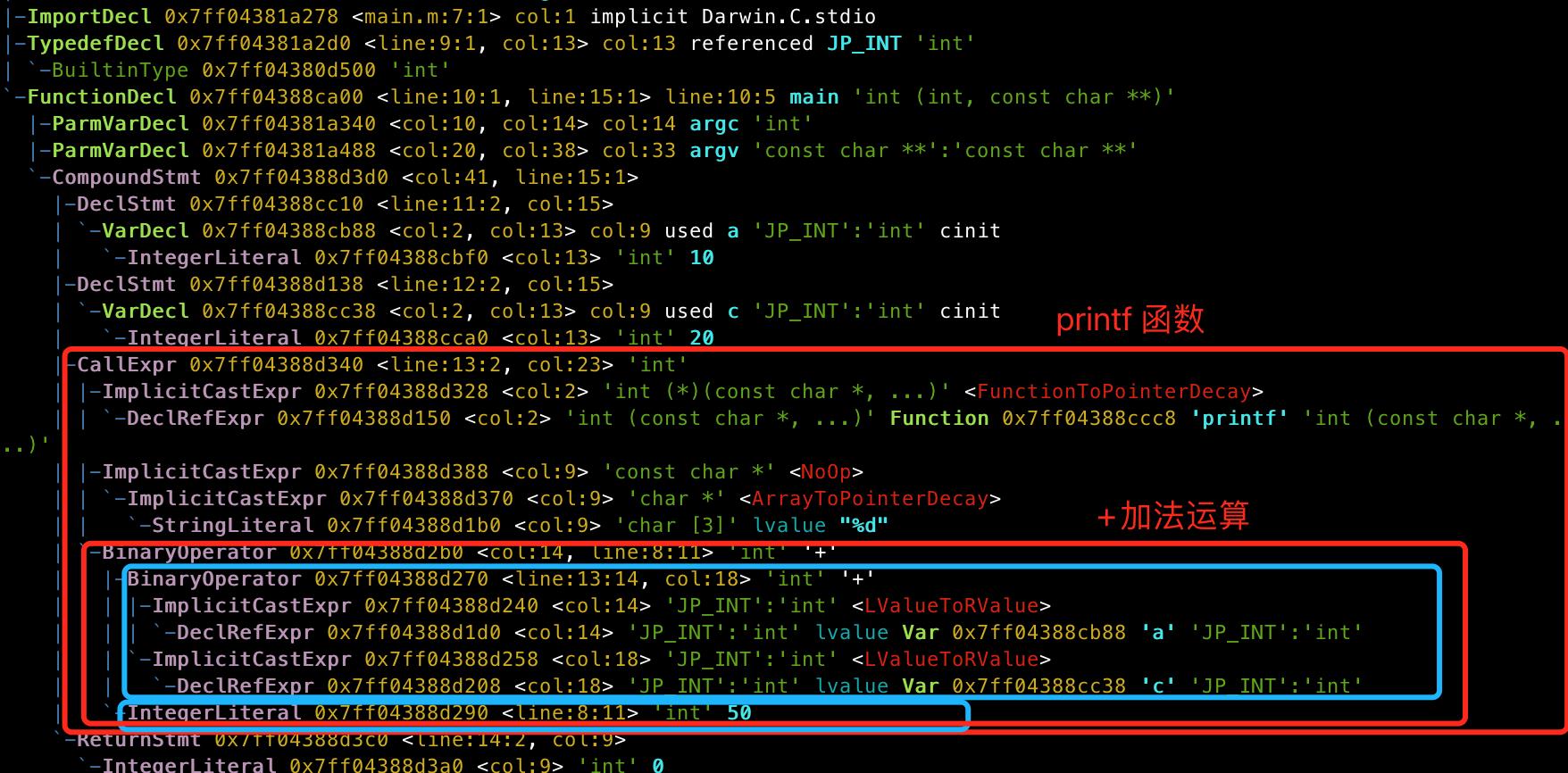
包括printf函数的指针,告诉我们函数的类型和返回值的类型;第一个参数"%d",第二个参数是一个+加运算的结果,是由a和c相加之和,再与50进行相加得到。ReturnStmt返回VarDecl变量声明StringLiteral字符串字面量IntegerLiteral整型字面量BinaryOperator二元运算符
补充:如果导入的头文件找不到,可以指定SDK
clang isysroot/Applications/Xcode.app/Contents/Developer/Platforms/
iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator12.2.sdk(自己的 sdk路径) -fmodules -fsyntax-only -Xclang -ast-dump main.m
中间代码IR
完成以上步骤后就开始生成中间代码IR(intermediate representation)了,代码生成器(Code Generation)会将语法树自顶向下遍历逐步翻译成LLVM IR。
#import <stdio.h>
//#define B 50
//typedef int JP_INT;
int JPTest(int a,int b) {
return a + b + 1;
}
int main(int argc, const char * argv[]) {
int c = JPTest(1, 2);
printf("%d",c);
return 0;
}
通过下面命令可以生成.ll的文本文件,查看IR代码,如下。
clang -S -fobjc-arc -emit-llvm main.m

从图中可以看到,生成了一个.ll的文件,使用 VS Code打开如下:
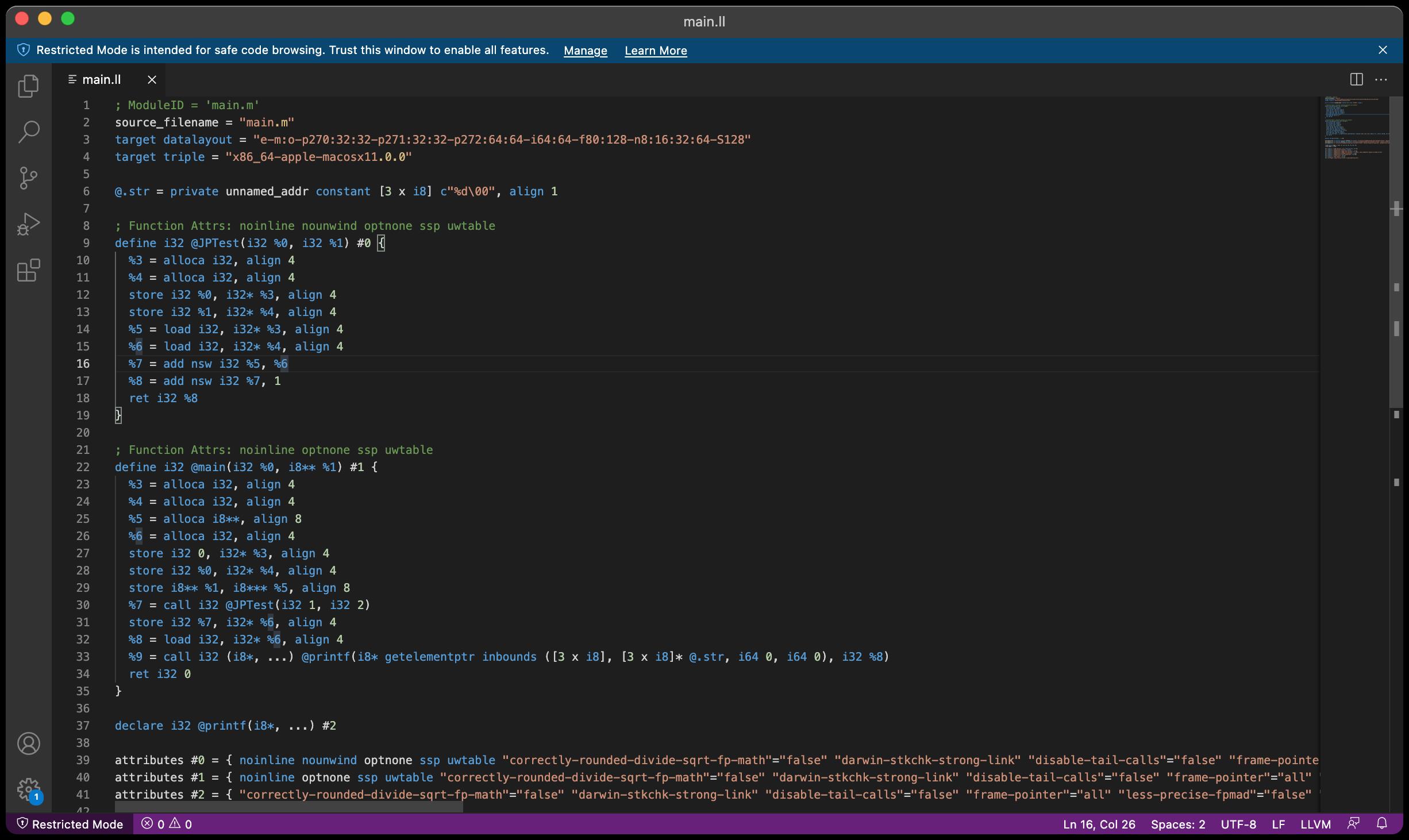
JPTest方法的生成的IR代码解读如下:

ObjectiveC代码在这一步会进行runtime的桥接:property合成,ARC处理等。
IR的基本语法
@: 全局标识
% : 局部标识
alloca: 开辟空间
align: 内存对齐
i32: 32个bit,4个字节
store: 写入内存
load: 读取数据
call: 调用函数
ret: 返回
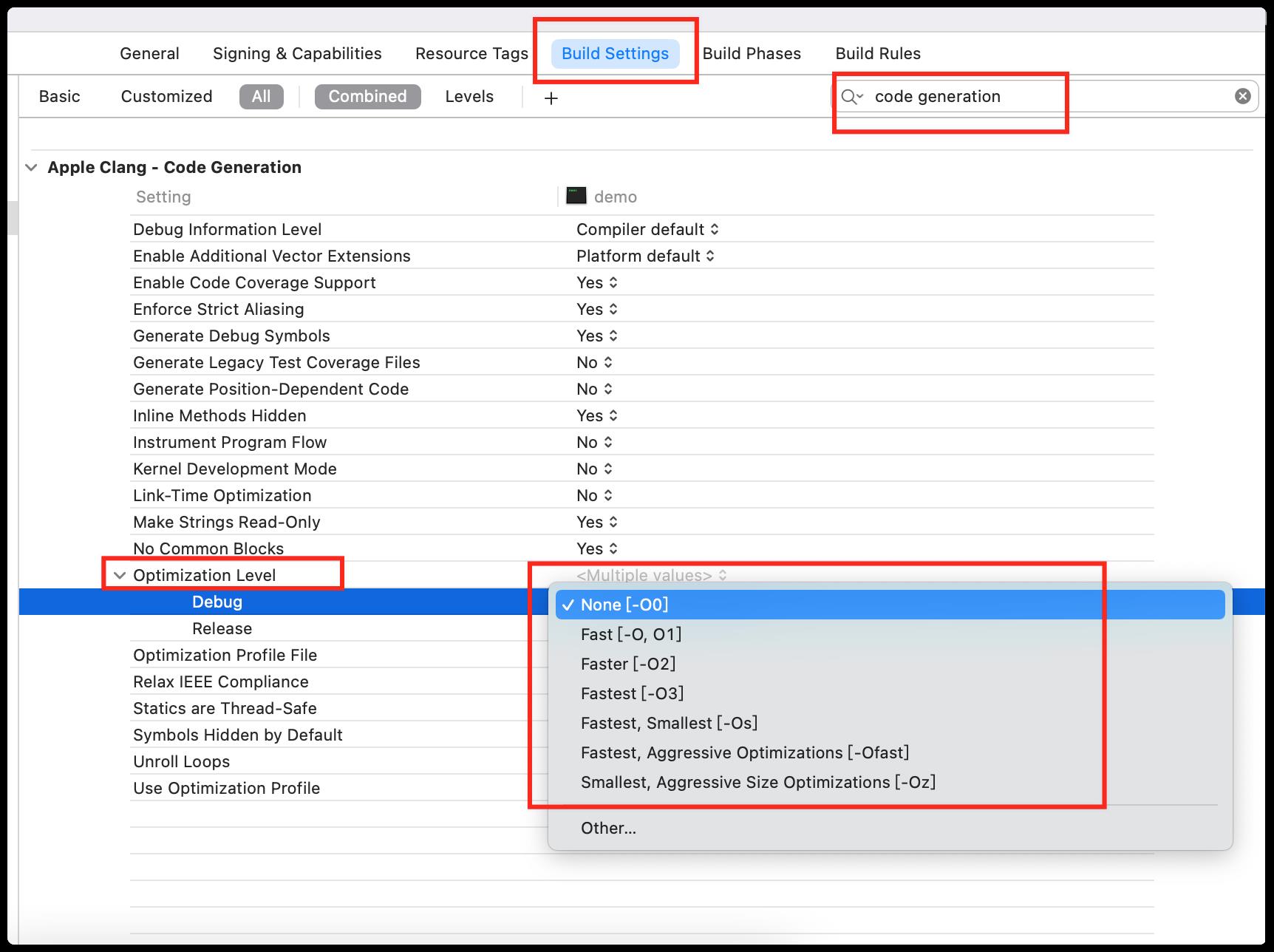
以上生成的代码是没有经过优化的,我们可以手动的开启编译器的优化,在 XCode里面可以进行设置的。
IR的优化
LLVM的优化级别分别是-O0-O1-O2-O3-Os(第一个是大写英文字母O)
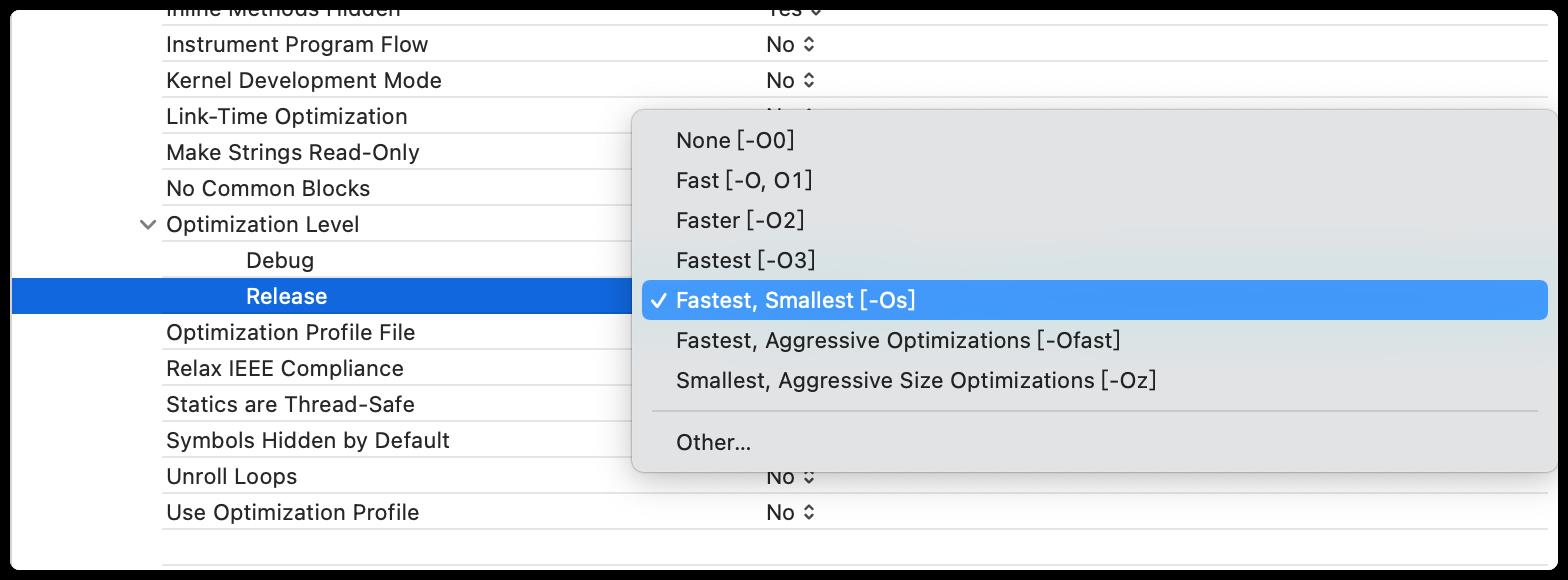
使用终端的命令,也是可以优化的,那么现在去优化一下,刚刚的代码。
clang -Os -S -fobjc-arc -emit-llvm main.m -o main1.ll
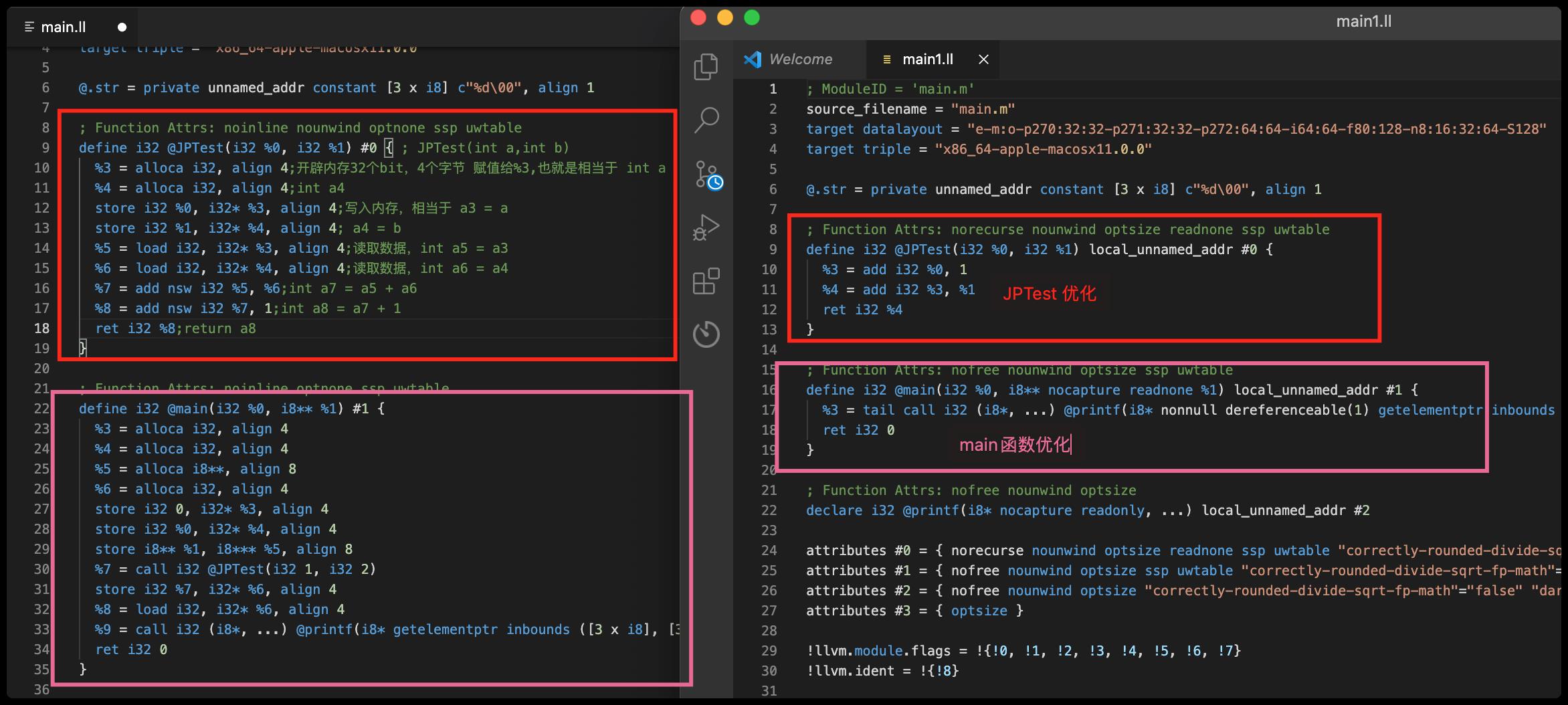
从上面的对比图,可以看出优化之后,JPTest和 mian代码都少了很多,在mian函数里面并没有看到调用JPTest函数,而是printf直接打印了c的结果 4,这就是优化的强大之处,如下:

优化之后,直接就算出来结果了,这优化还是很给力的哈!优化等级也不是越高就越好。在XCode 里面的优化选项里面release 环境下默认的优化就是最好的了,苹果肯定是给你最好的优化啊。
- 小结:
编译流程:首先是预处理,对输入代码的宏进行展开;然后是词法分析,会分成一个一个的 token;再是语法分析,会生成 AST语法树;再就会生成IR代码,交给优化器去处理优化代码。
- bitCode
这是xcode7以后开启bitcode苹果会做进一步的优化,生成bc的中间代码。我们通过优化后的IR代码生成bc代码,这也是一个中间代码,目的是会根据 CPU 的不同架构生成不同大小的包(App Store 商店下载)。
clang -emit-llvm -c main.ll -o main.bc
生成汇编代码
- 生成汇编代码
我们通过最终的.bc或者.ll代码生成汇编代码
clang -S -fobjc-arc main.bc -o main.s
clang -S -fobjc-arc main.ll -o main.s
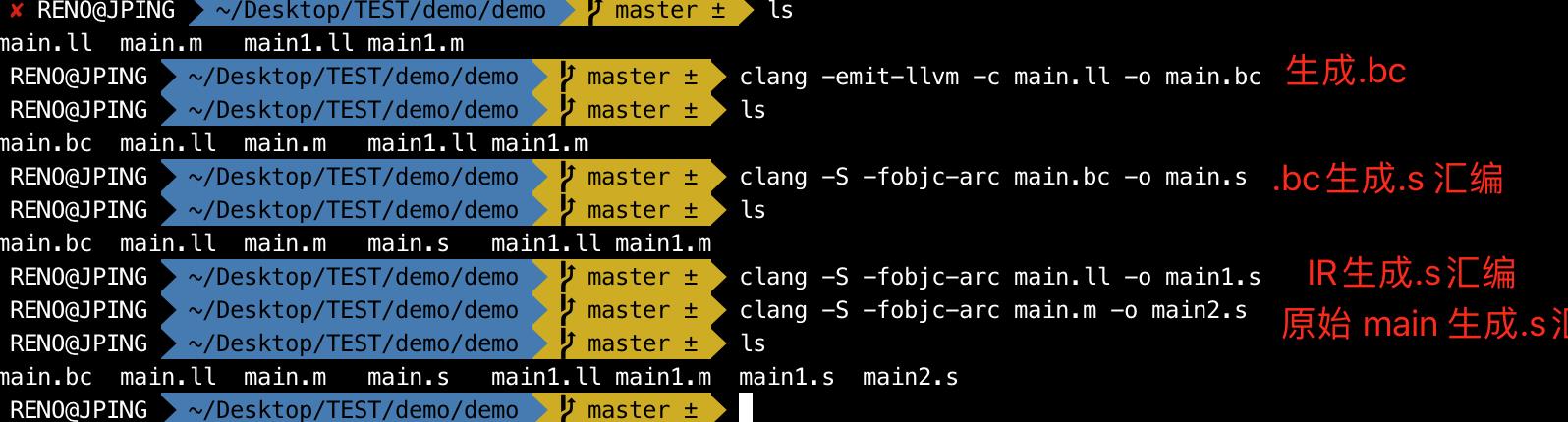
- 生成的汇编比较

图中是三种不同后缀生成的汇编代码
IR直接生成的汇编是55行,计算优化了IR生成的bc在生成汇编,在IR的基础上没有进一步的优化了,还是55行- 原始的
main代码直接生成的汇编就是62行了
生成汇编代码的时候也是可以再次进行优化的,那么我们用上面生成的.bc 试一下,开启优化最大,看看生成的汇编是有多少行呢?
clang -Os -S -fobjc-arc main.bc -o main3.s
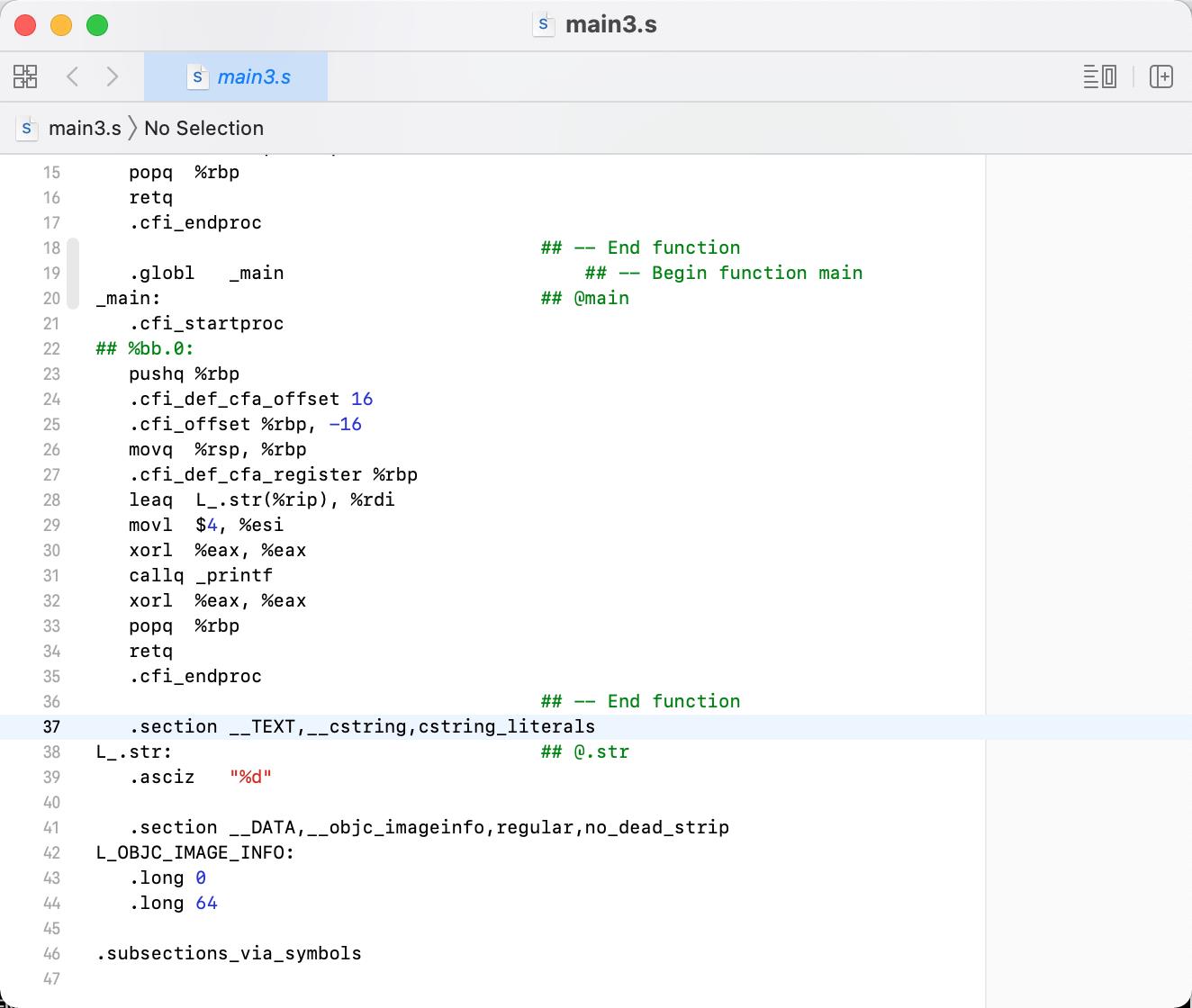
我们把优化等级调到最高,生成的汇编代码就
47行了,比上面的55行少了8行,也就是说生成的IR或者bc的时候,优化并没有停止,每一个节点上面都有可能再次优化。
生成目标文件(汇编器)
目标文件的生成,是汇编器以汇编代码作为输入,将汇编代码转换为机器代码,最后输出目标文件(object-file),这个阶段就是属于编译器后端的工作了。
clang -fmodules -c main.s -o main.o
通过
nm命令,查看下main.o中的符号xcrun nm -nm main.o
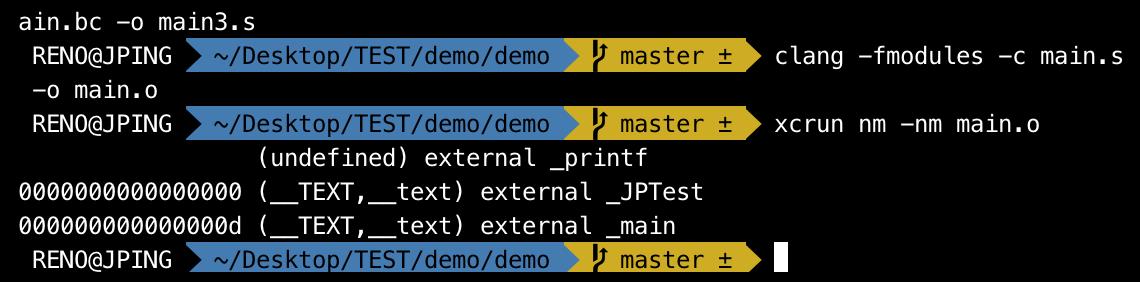
_printf是一个是undefined external的。undefined表示在当前文件暂时找不到符号_printfexternal表示这个符号是外部可以访问的。
生成可执行文件(链接)
连接器把编译产生的.o文件和(dylib .a)文件,生成一个mach-o文件(可执行文件)。
clang main.o -o main
- 查看链接之后的符号
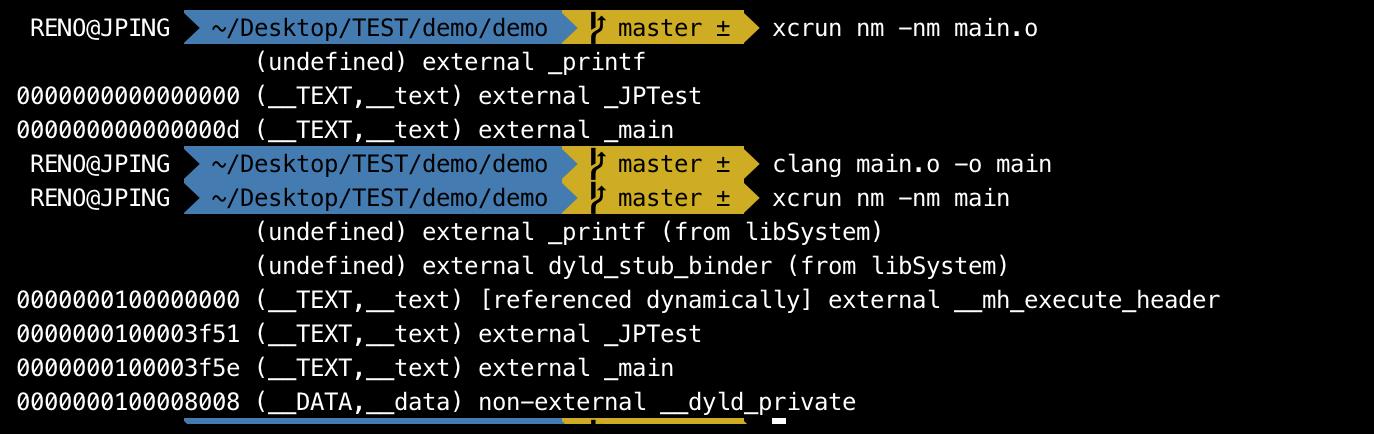
- 现在打印的信息就多了,
_JPTest和_main也还在,偏移地址也有了,也就是说在执行文件中的位置就确定了。 - 现在的外部函数除了
_printf还有dyld_stub_binder,这是为什么呢? dyld_stub_binder是在dyld里面,当我们的执行文件mach-o进入的内存之后,外部的符号就会立刻马上和dyld_stub_binder进行绑定,这个过程是dyld强制绑定的。- 链接和绑定是两个概念:链接是我要知道你外部的符号在哪个动态库里面,就是做个标记,我要知道去哪个动态库里面找到你。
- 绑定是在执行的时候,把动态库
libSystem里面的和你这个外部调用的_printf进行绑定,绑定是在执行期,链接是在编译期。
以上就是 LLVM大致的工作流程,接下来将介绍如何写一个自己的Clang插件。
4. 写在后面
关注我,更多内容持续输出
🌹 喜欢就点个赞吧👍🌹
🌹 觉得有收获的,可以来一波 收藏+关注,以免你下次找不到我😁🌹
🌹欢迎大家留言交流,批评指正,
转发请注明出处,谢谢合作!🌹
以上是关于iOS底层探索之LLVM——初识LLVM的主要内容,如果未能解决你的问题,请参考以下文章