爬虫必备安装和使用Xpath正则表达式插件 以及 F12的抓包流程
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫必备安装和使用Xpath正则表达式插件 以及 F12的抓包流程相关的知识,希望对你有一定的参考价值。
本文以
谷歌浏览器为例子,本文只用到了Xpath,正则,爬虫可以有css选择器的插件,可自己操作一下css选择器的下载使用
目录
1. 安装Xpath插件
打开谷歌浏览器这里,打开扩展程序。

点击这里,进入谷歌插件应用中心
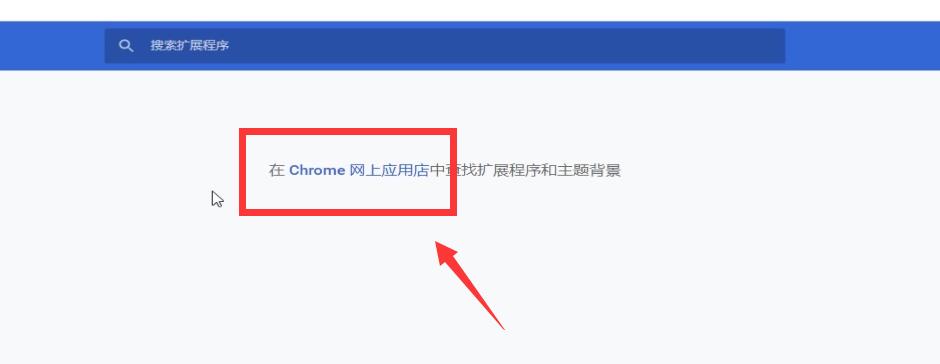
在这里搜索Xpath

我自己喜欢用这个,点击进去
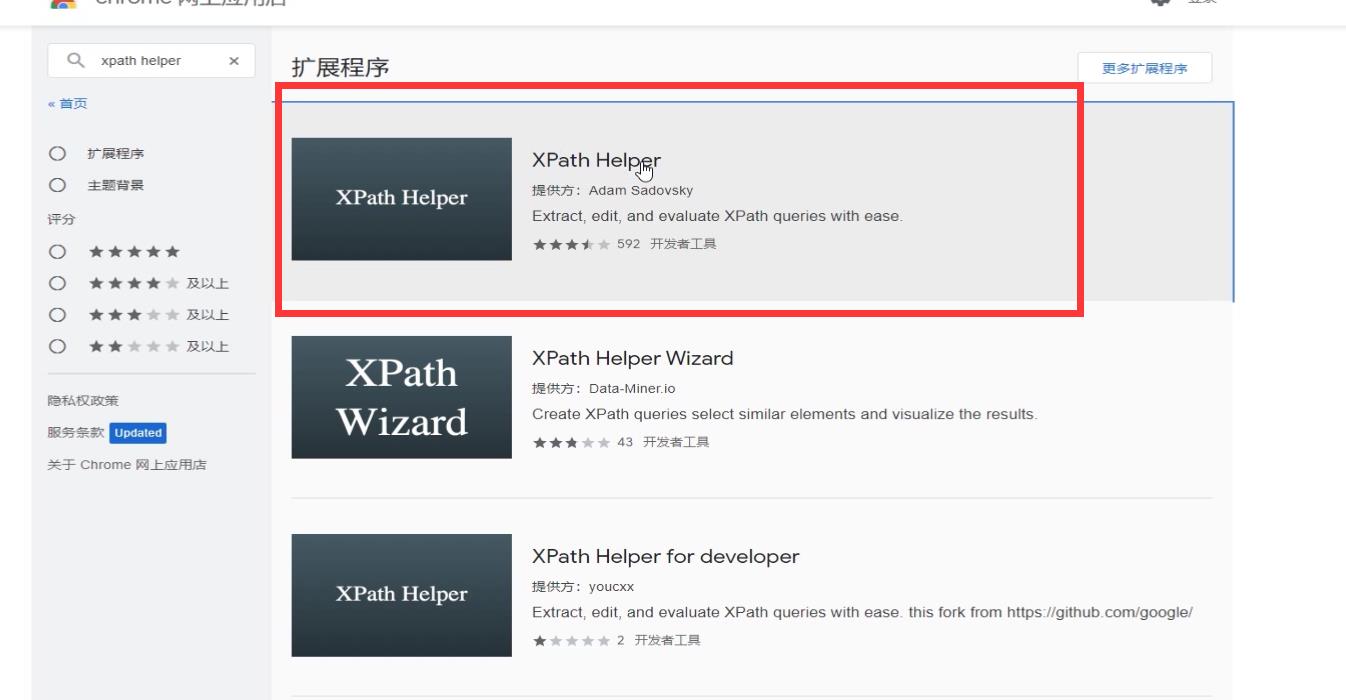
进行安装
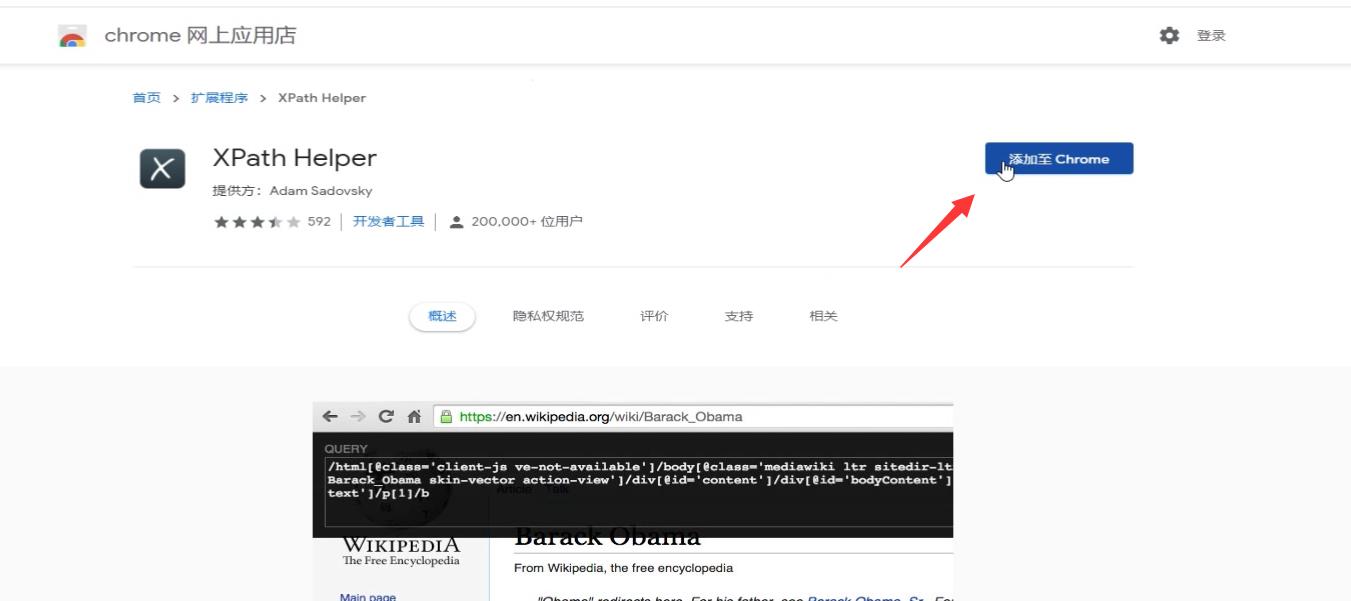

这样就安装成功了
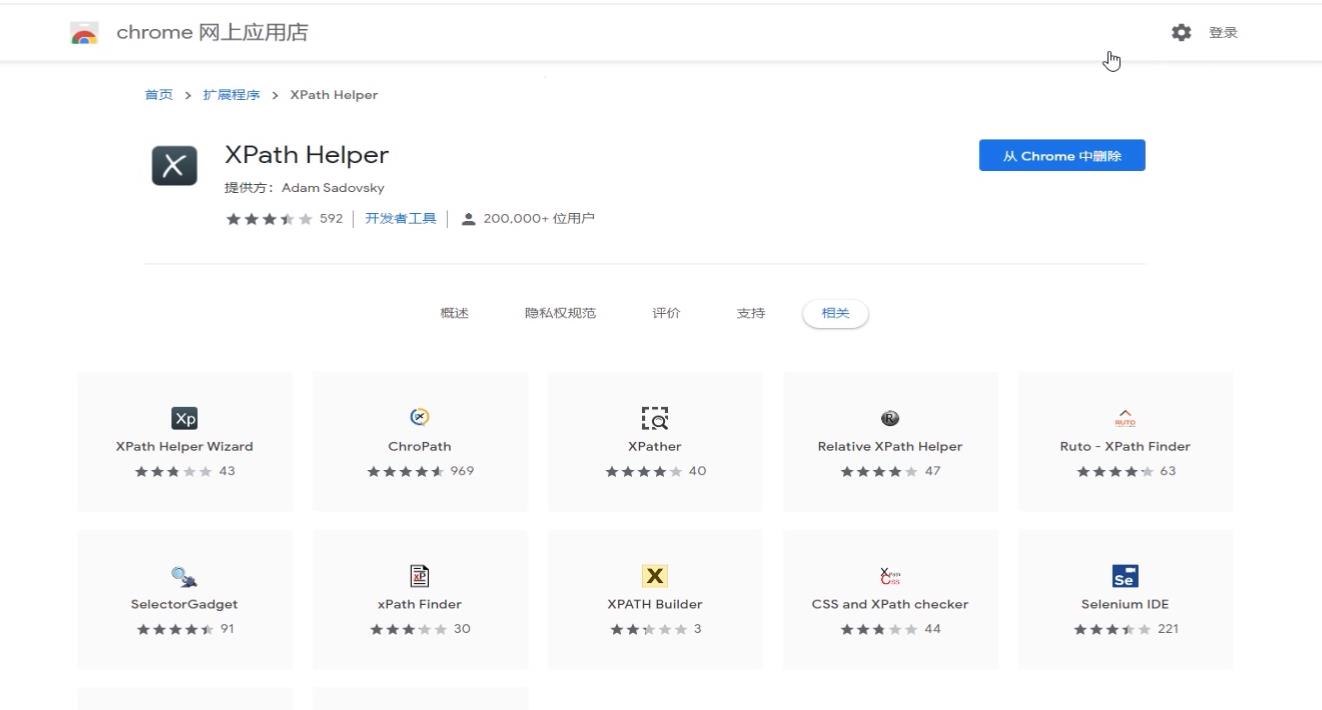
点击这个按钮,把xpath固定在输入框的右侧,方便使用的时候调用这个插件。
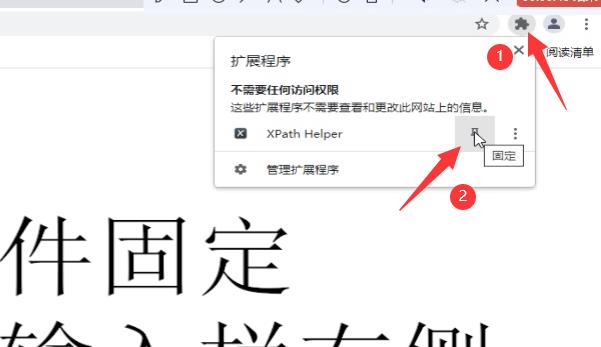
这样就安装成功了。
2. 使用Xpath插件
以豆瓣为例子。

但我们一点击这个插件的时候

就会弹出这个黑色的xpath语法输入框,这个框左边是你输入的Xpath语法,右边的Xpath语法选择出来的结点数据。

当清楚好结点的Xpath语句之后,在左侧输入,就会匹配到这个结点数据了。
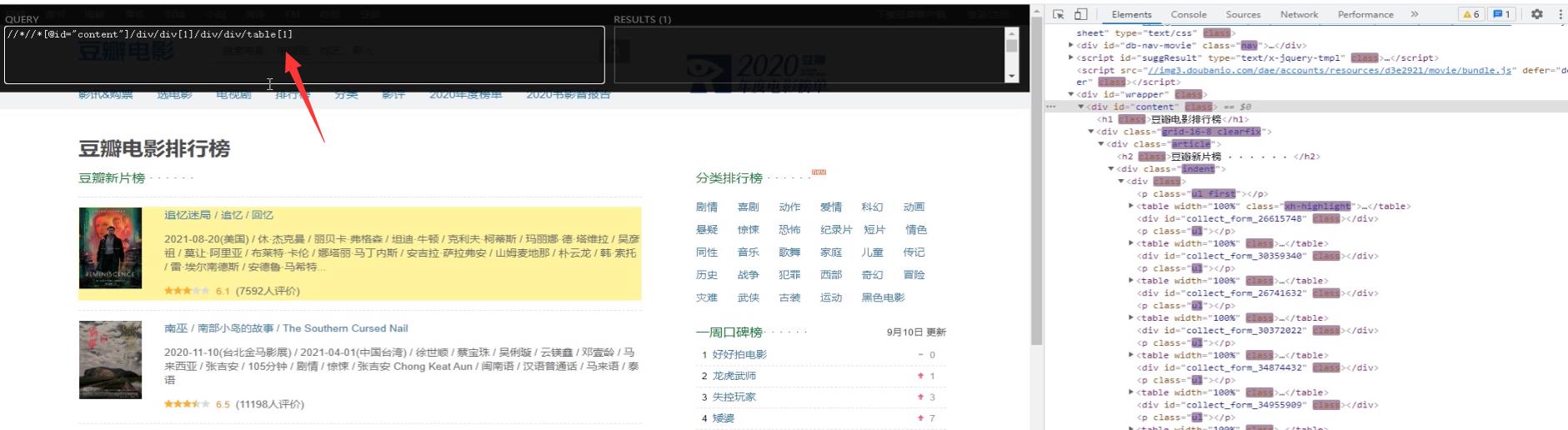
浏览器也会高亮提示,你选择的结点数据。并且右侧也会显示选择的结点信息
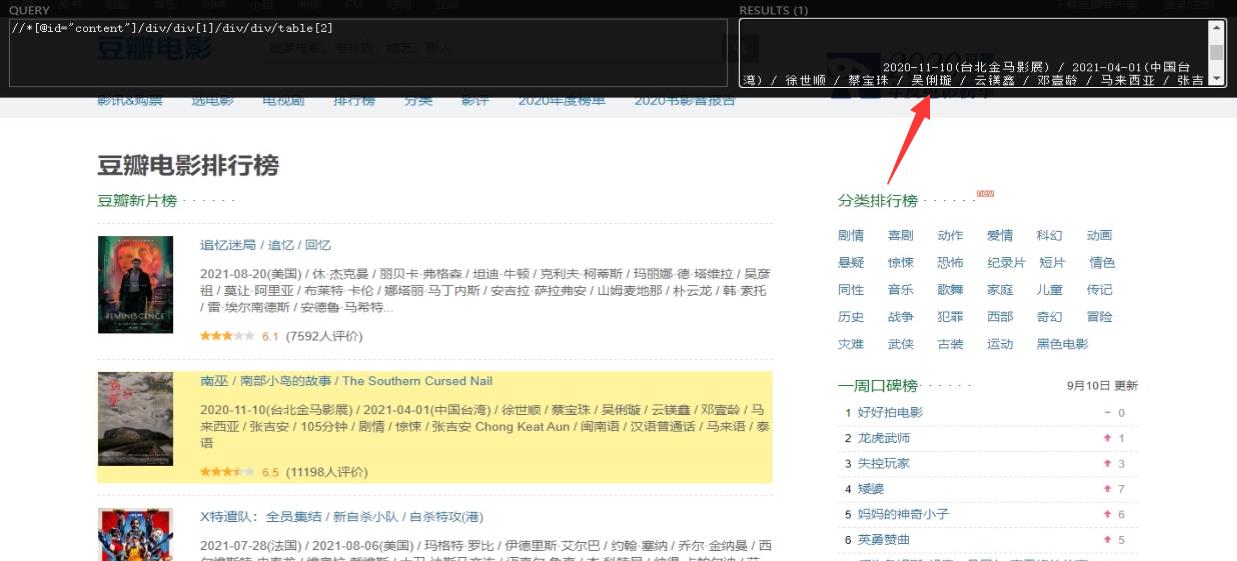
大概就是这个用法
3. 安装正则表达式插件
先打开这里
再打开这里
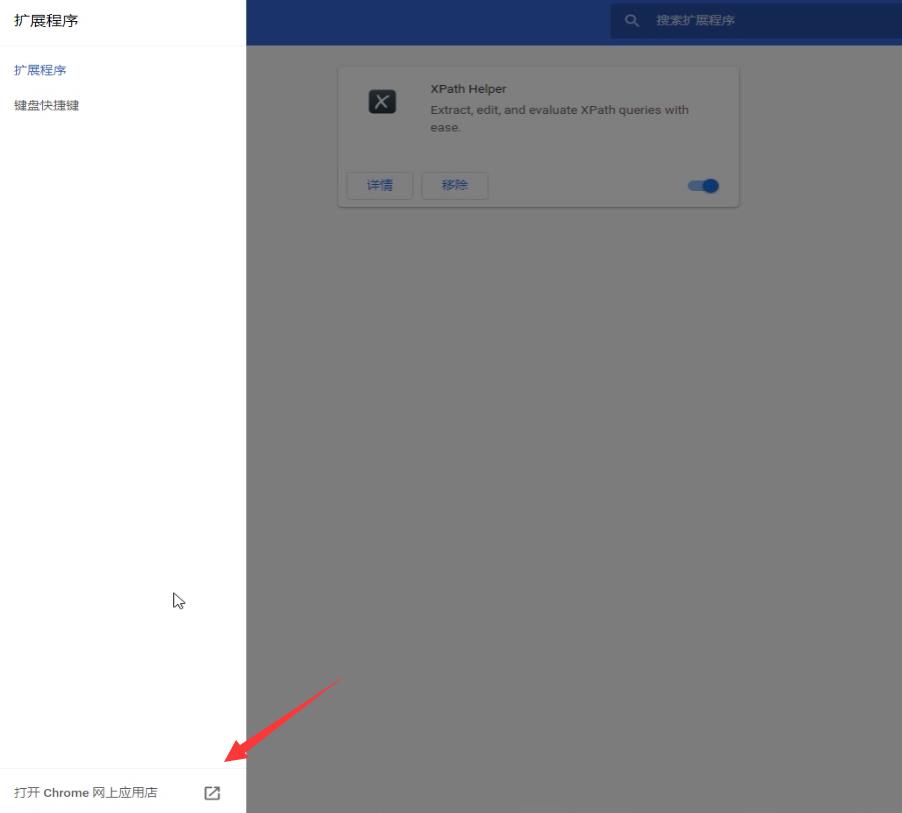
搜索正则表达式的插件

选择这一个插件
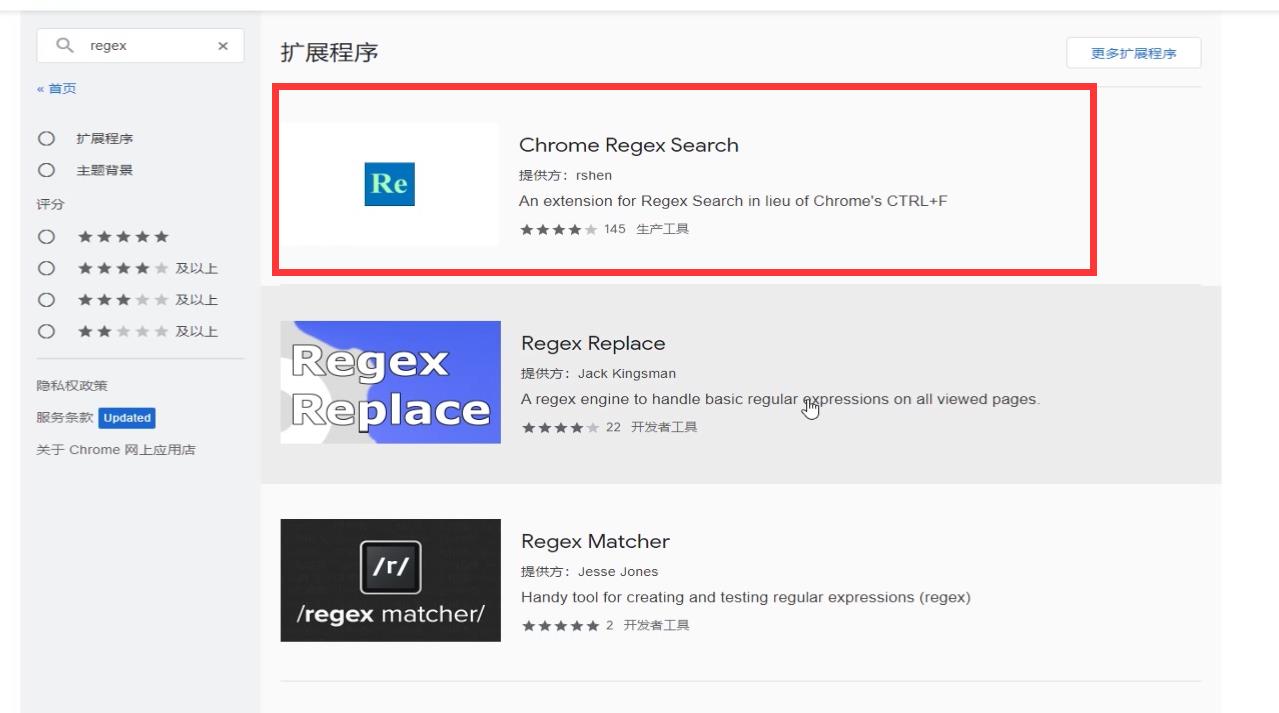
添加到浏览器上
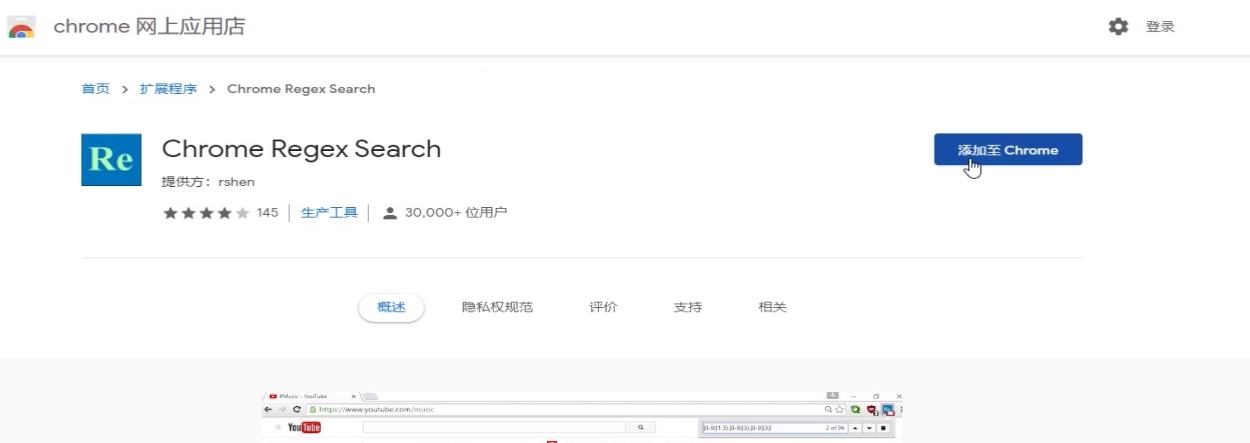
这样就成功了安装完了~
然后把这个东西固定到输入栏的右侧,方便使用
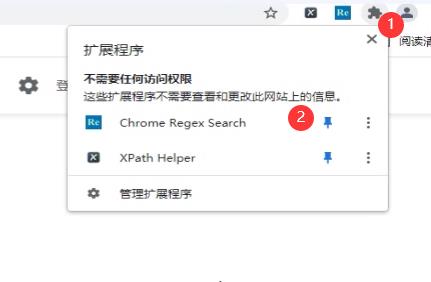
4. 使用正则表达式插件
还是使用正则作为例子
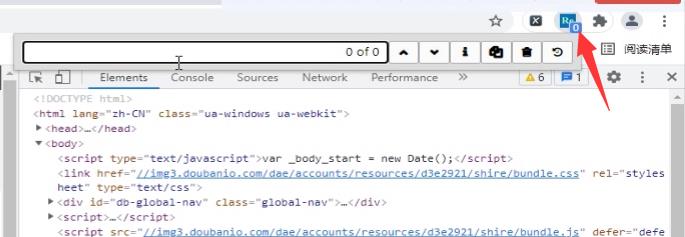
点击插件,就会弹出这个插件
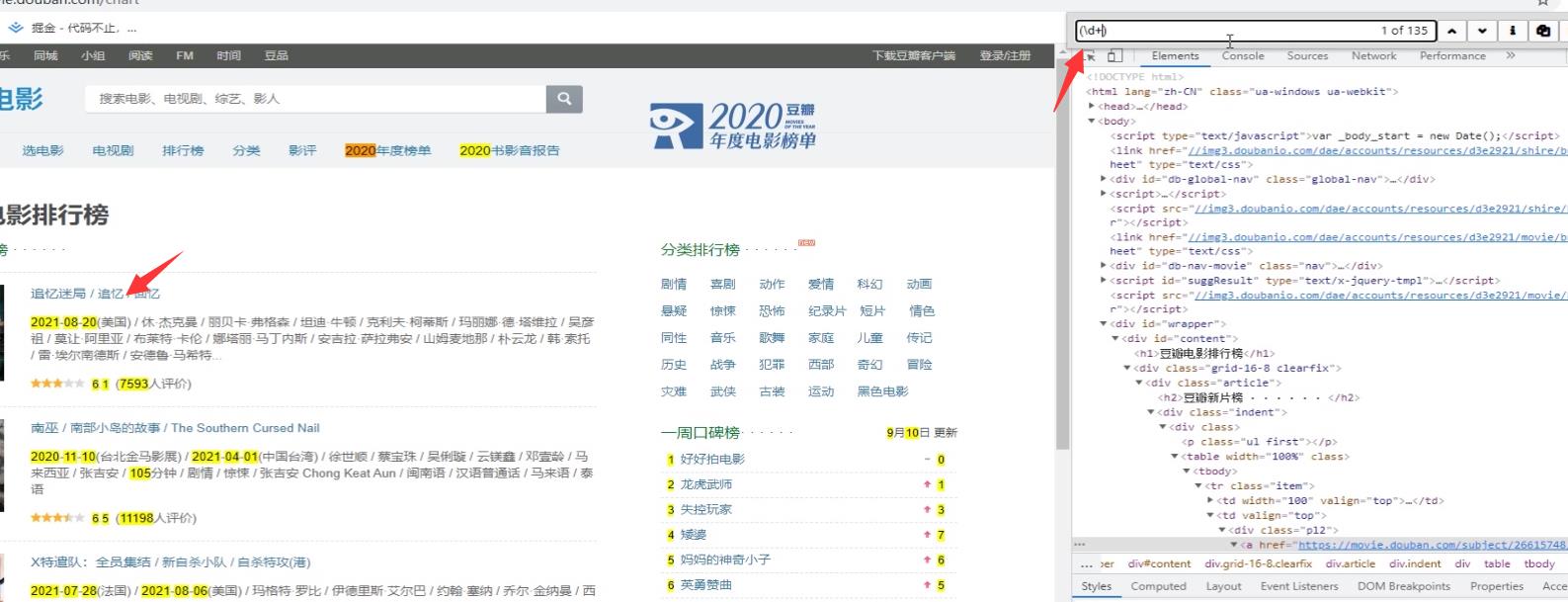
匹配所有的数字,和xpath一样,会高亮提示
简单的使用就是这样了。
但是这个插件有个问题,就是一离开,就会自动收起,很不方便,可以自行下载其他的插件使用,这里i只是做一个列子而已。
另外,大家可以尝试自己安装css选择器的插件
5. F12抓包,CSDN评论为例子
首先随便找一篇博文进行评论的抓取
5.1 Header
打开NetWork找到对应的包,进行分析
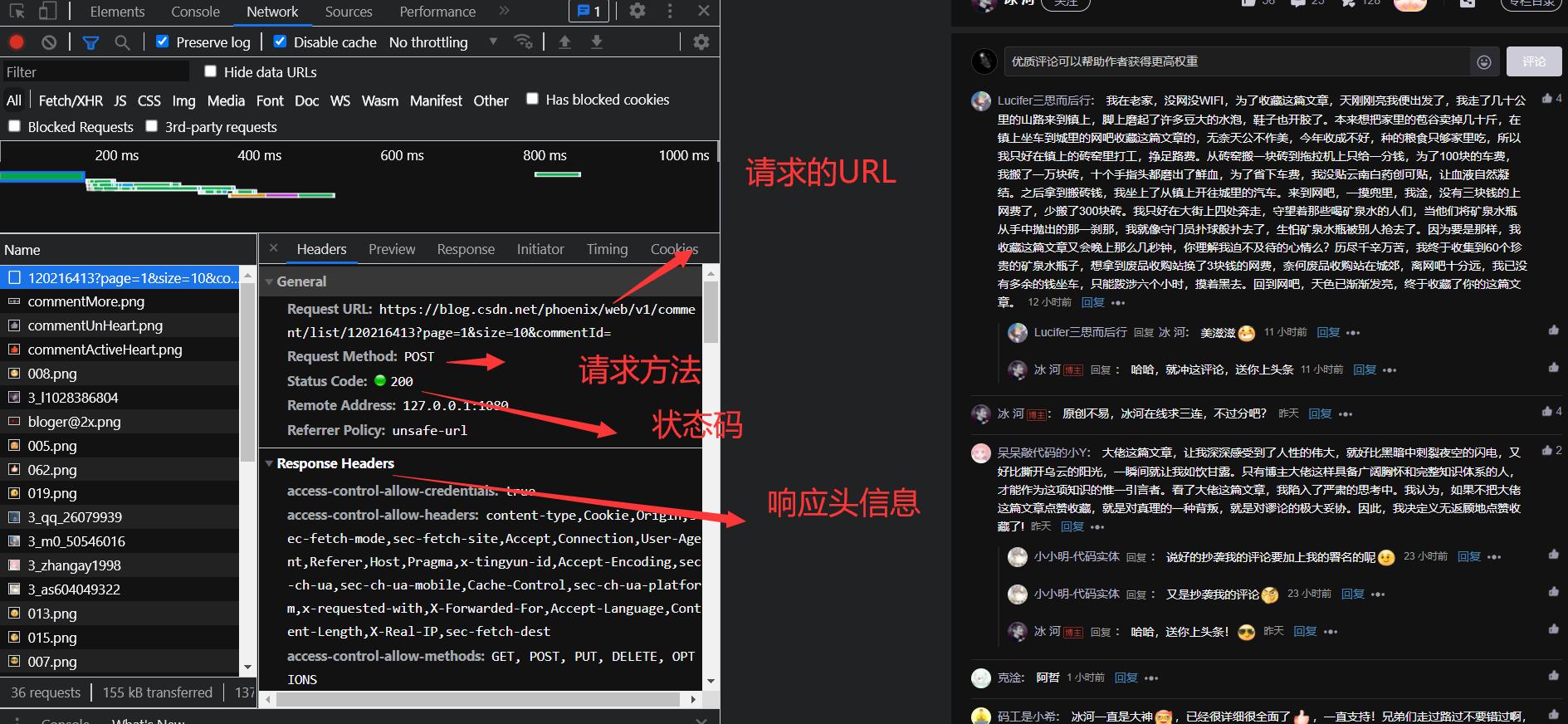
我们可以看到请求的url,http状态码,请求方法之类的

我们爬虫的话,一般都要用请求头去模拟这个过程,因为这个请求头可以起到一个伪装的作用,让服务器知道这是一个正常的访问而不是一个爬虫访问。所以请求头还是很重要的。
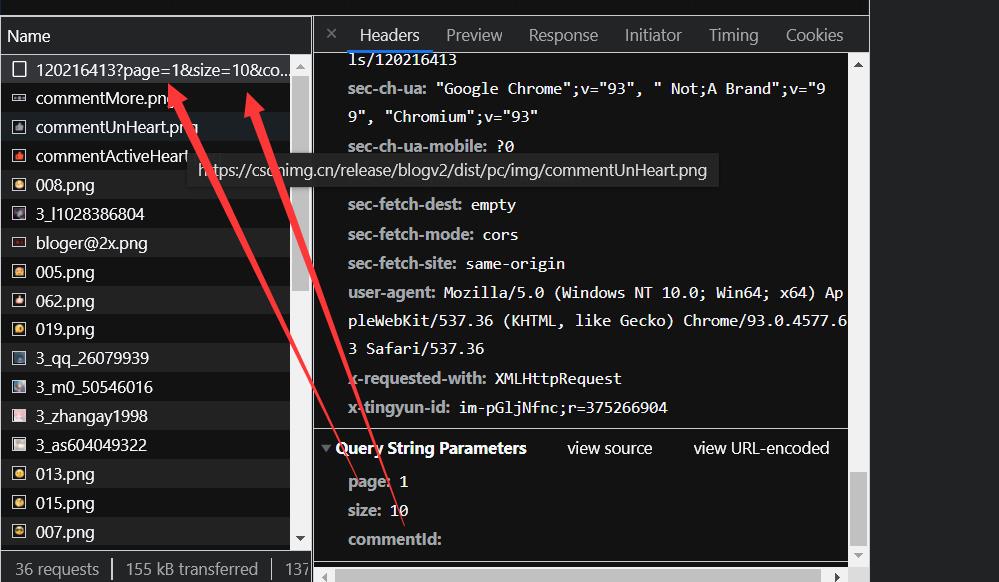
这个就是传的参数,page就是页数,size就是页面大小。
5.2 Preview
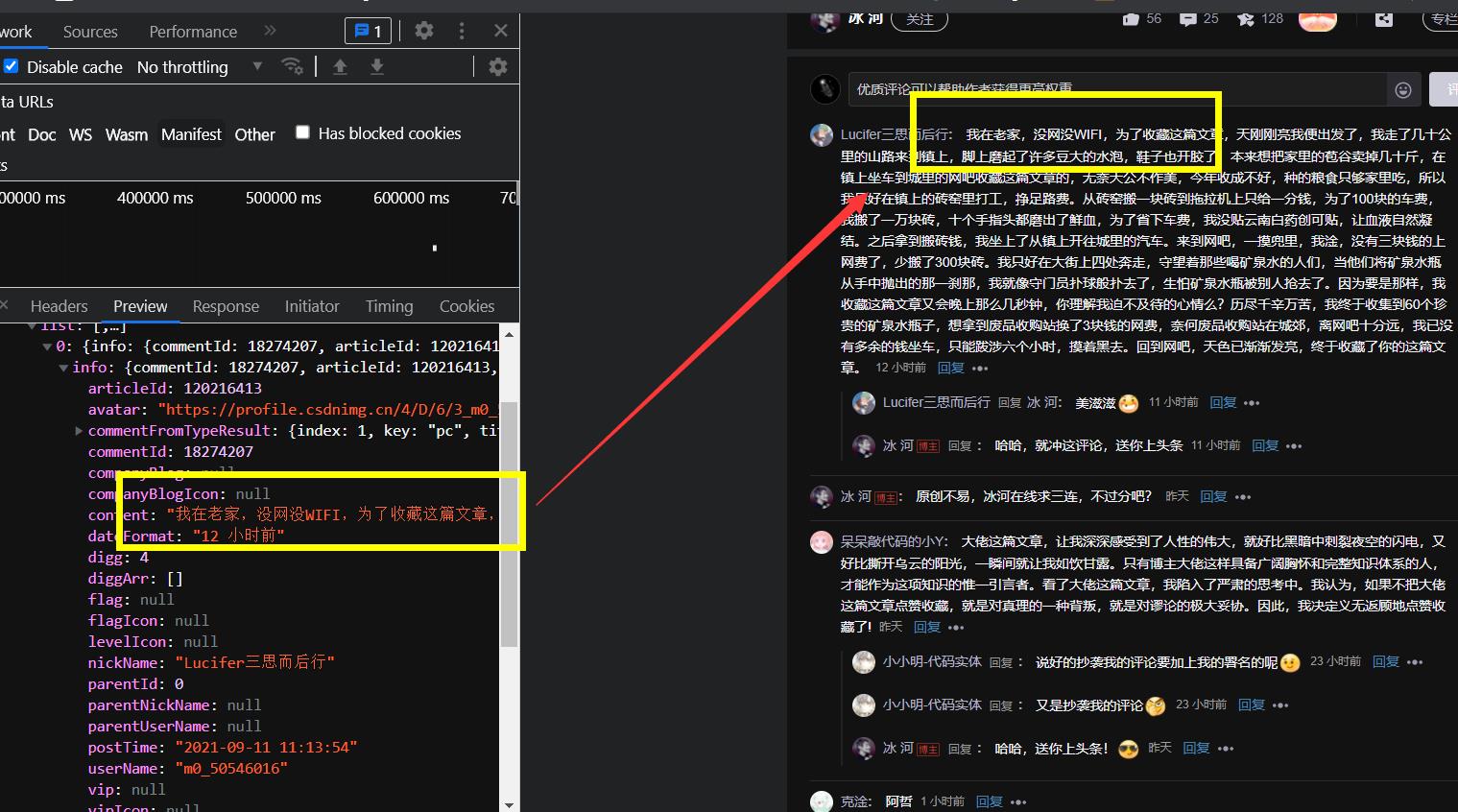
我们就能看见这个评论信息了。这些就是动态数据。这种不是固定在网页源代码里面的。
就是你右键查看网页源代码就看不到的
是没有的,所以要用抓包来获取。

6. F12抓包,B站评论为例子
同样的,我们打开F12,找到这个评论的包。
注意B站这个是一边加载一边渲染的,就是必须滑倒下面有评论的地方,才能有请求的这个包。
比如说这种情况,这种情况是没有看见评论的,所以就是没有这个评论包的,因为根本就没有请求。
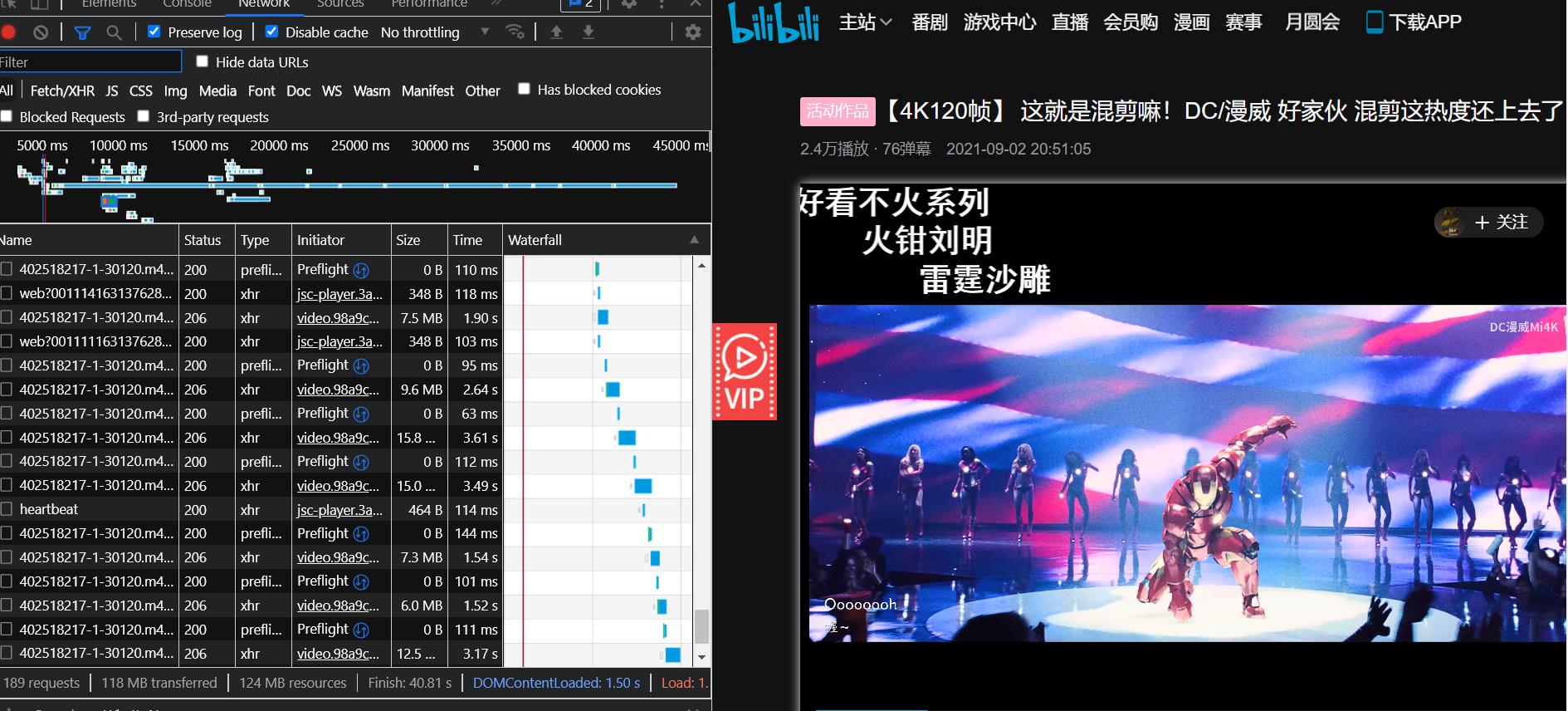
我们要往下拉,知道看到评论,才会慢慢加载出来,这个评论包也会自然而然出现了。就能找到了!
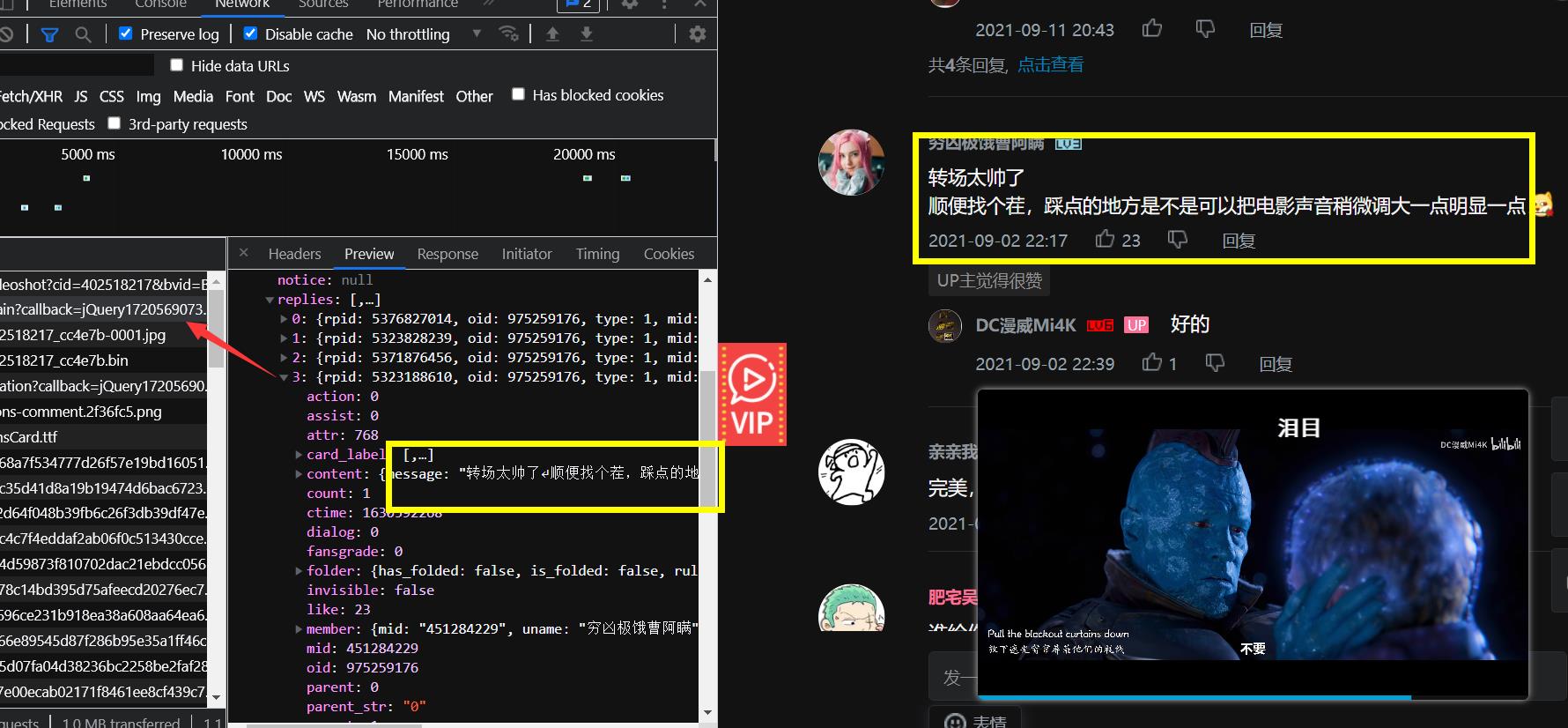
同样的这种请求的动态数据是在网页源代码里面是看不到的。
以上是关于爬虫必备安装和使用Xpath正则表达式插件 以及 F12的抓包流程的主要内容,如果未能解决你的问题,请参考以下文章