爬虫基础之一:XPath插件语法及使用
Posted 涂涂努力ing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫基础之一:XPath插件语法及使用相关的知识,希望对你有一定的参考价值。
XPath插件语法及使用
最近在学习爬虫相关的知识,对于网页标签选取,google浏览器的插件xpath很好用,在此分享给大家。
1. 在浏览器上面安装xpath插件
在浏览器的扩展程序中搜索xpath,选择第一个安装,安装成功如下图所示:

2. XPath使用
2.1 XPath路径表达式
|
| 路径表达式 | 描述 |
|---|---|
| /div | 从根节点开始选取div节点 |
| //a | 选取文档中所有a节点而不考虑位置 |
| @class | 选取名为class的属性 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| /div/a | 从根节点开始选取div节点下的a节点 |
| /div/a[2]/img | 从根节点开始选取div节点下的第二个a节点下的img节点 |
| //div[@class=‘header-wrapper’] | 选取所有属性class的值为header-wrapper的div节点 |
| //* | 选取文档中的所有元素 |
| //@* | 选取文档中所有带属性的元素 |
| /div/p/text() | 选取p节点的文本内容 |
| //div[contains(@class,“post”)] | 选取带有class属性且包涵“post”的所有div节点,取反//div[not(contains(@class,“post”))] |
| /div/p[last()-1] | 选取div下倒数第二个p节点 |
| /div/p[position()>1] | 选取div下第二个p节点后的所有兄弟节点 |
| /div/a|div/p | 选取div下的a节点和div下的p节点 |
归纳来自于:https://www.imooc.com/video/22764
2.2 例子
我们采用http://www.ruiwen.com/wenxue/wangzengqi/58200.html此网页作为例子示范
e.g.1 目标是利用xpath找到下图时间的内容


e.g.2 目标是找到下图所示文字
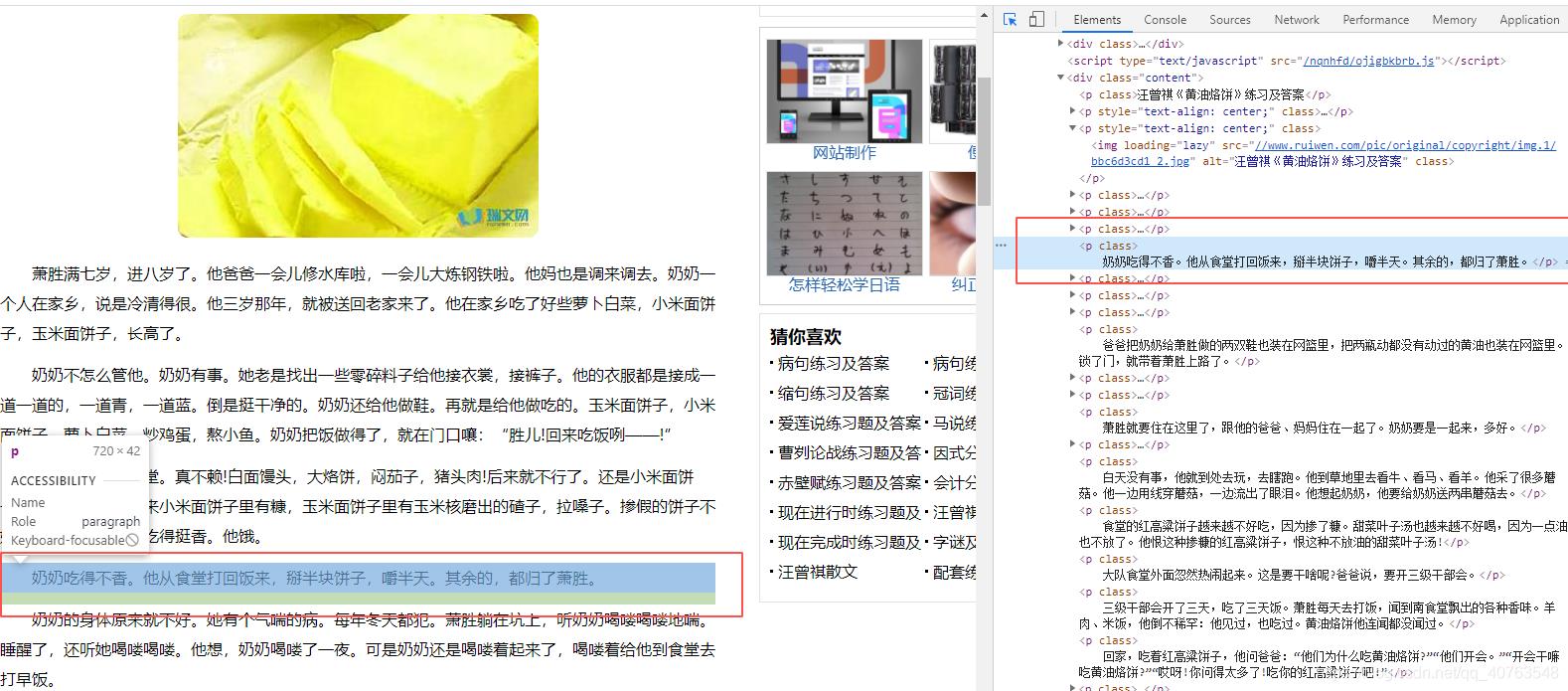

e.g.3 获取所有属性class的值为‘time’的div节点

希望对大家有帮助啊
继续愉快学习,涂涂努力ing!
以上是关于爬虫基础之一:XPath插件语法及使用的主要内容,如果未能解决你的问题,请参考以下文章