陈曦:超低延迟下的实时合唱体验升级
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了陈曦:超低延迟下的实时合唱体验升级相关的知识,希望对你有一定的参考价值。

点击上方“LiveVideoStack”关注我们
RTC(实时音视频通信)近年来广泛应用于语聊房、直播连麦、视频会议、互动课堂等场景,延迟一般在200ms-300ms,已经可以满足大部分场景的互动需求。但还有一些场景对延迟的要求非常苛刻,延迟的高低直接影响用户体验,如“线上KTV”、“云游戏”等。本文来自即构科技行业解决方案总监 陈曦在LiveVideoStack公开课的分享,结合即构科技在实时合唱场景中实现极致工程化的经验,对超低延迟体验的优化思路进行了详细解析。
文 | 陈曦
整理 | LiveVideoStack
陈曦
公开课
大家好,我是即构科技的陈曦,目前主要负责解决方案架构方面的工作,包括新产品、新场景设计以及线上项目维护。
本次分享的主题是即构科技在超低延迟下如何进行优化,以及如何在超低延迟的支持下研发新场景,如实时合唱等。内容主要分为四个部分:第一,RTC发展与泛娱乐场景创新;第二,超低延迟体验的优化思路;第三,实时合唱场景中实现极致工程化的经验;最后是即构即将推出的新场景以及RTC行业的未来展望。
01
RTC发展与泛娱乐场景创新

首先回顾一下在线实时娱乐的发展历程。十几年前还没有实时互动的概念,那时主要是单向直播,技术条件的限制使得延迟高达3-5s,没有观众及麦上用户和主播进行互动;近十年,基于传统CDN技术,延迟勉强可以压缩至1s左右,因而陆续出现了“伪实时互动”。在1s延迟的前提下,一来一回延迟大概是2s,这是人们在面对面交流时无法适应的;随着Google WebRTC技术框架的兴起,近几年延迟逐步压缩至500ms、300ms、200ms,300ms和200ms也就是大家线上语音、连麦、开黑时的常见延迟时长。
结合已有的创新场景,主要是实时共享体验。人类是社会动物,分享欲是与生俱来的,我们乐于向他人分享语言、情感、甚至是肢体语言和表情。由于疫情的发生,以及当前工作压力越来越大,生活节奏越来越快,大家在周末可能更倾向于宅在家中而非线下社交,因此创造贴近线下的线上实时共享体验就成为了主流诉求。目前的共享体验场景主要围绕“一起+”展开,如一起玩、一起看、一起听、一起唱,甚至包括未来网络实时互动的走向,也就是“元宇宙”,通过VR/AR等设备开展沉浸式体验。

日常生活中,恋人、朋友会共用一副耳机来分享好听的歌曲。“一起+”系列中的“一起听”就是将这种分享模式转换为线上,喜马拉雅在今年3月推出了“一起听”,用户可以邀请好友进入房间一起分享音乐,随时进行评论、开麦聊天等。

当我们向好友分享一部好看的影片或是一段搞笑片段时,仅仅通过分享链接无法得知对方是否观看以及看完之后的感受评价。“一起看”的推出避免了以上问题,把朋友拉入视频所在房间,可以直观地看到对方观感,可以实时连麦、打开摄像头进行交流,这就真正地模拟了线下社交时的种种体验。
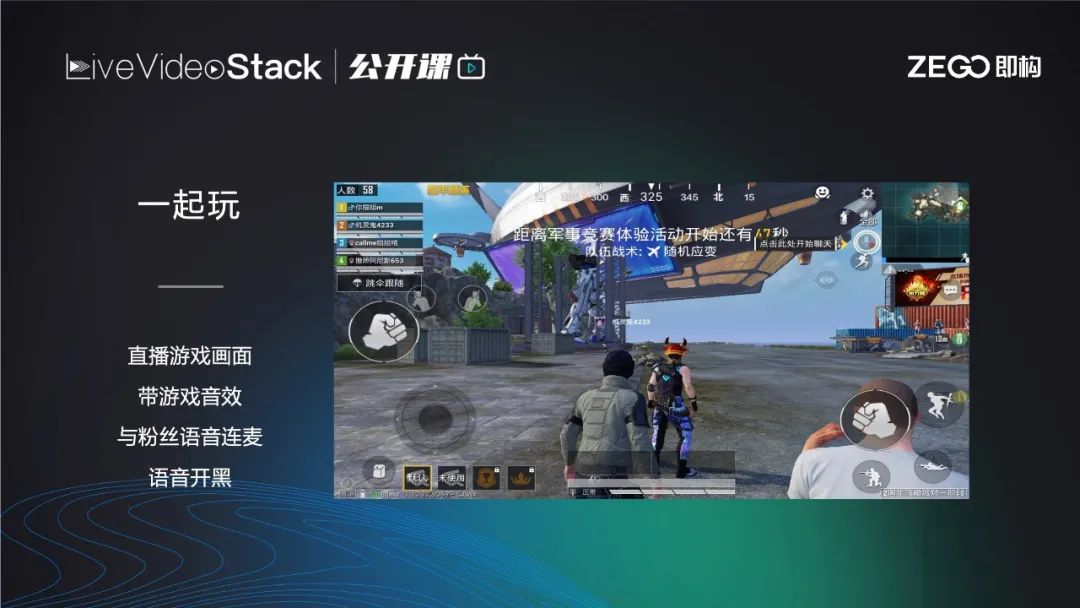
以前的斗鱼游戏主播进行游戏直播时只能通过打字和粉丝进行弱互动,而且在玩游戏时可能漏掉许多留言。“一起玩”中,无论是主播或是任意玩家,都可以在玩游戏时通过实时直播连带画面及音效一同推出,同时可以和粉丝以及小队队友保持语音连麦,相较于之前的互动模式实现了质的飞跃。

“一起唱”包括元宇宙中的沉浸式“一起看演唱会”等,其对延迟的要求更为极致,前面介绍的场景延迟在200-300ms左右就可以满足当前需求。“一起唱”模拟的是线下多位好友一同去KTV包厢时,各拿一个麦克风,或是两到三个甚至是四个麦克风同时唱一首歌,歌的旋律是固定的,不会停顿。如果A和B在合唱时,A需要听到相同进度节奏时B的歌声,并且没有网络传输的延迟以防打乱节奏,这些需求之前行业内基本无法实现,所以更多的是单人唱、排队轮唱、抢唱,后两者存在转场可以留出延迟时间。
大家可以听一下即构“一起唱”方案中app的合唱效果。音频中的男声唱的是和弦的旋律,和主唱的音准基本在3度5度和弦上面。无论是从观众角度还是音频中两位歌手的角度,听到的都是刚才音频中的效果,可以听出延迟非常低大概70~80毫秒,几乎感觉不到线上有网络的阻隔。
02
超低延迟体验的思路

RTC体验刻画中,观看端主要从低延迟、流畅、高音质和画质评价体验,但在RTC的各个场景不断优化的进程中,这三个指标如同三角形的三个角,相加始终等于180°,不可能同时很小,比如降低延迟,buffer减小时流畅度会下降,码率也会减小,因为许多用户下行带宽不稳定,无法实现高音质,高画质需要的高码率。
即构经过二十年的运营经验积累及每天20亿的时长积累,基于对用户的时长行为分析得出调优数据,目前已经基本做到低延迟、流畅,高音质及高画质。

无论是声音还是画面,整个链条从采集、前处理(美声、变声、回声消除等)、编码(编程AAC)、经过MSDN传输、播放端解码、后处理,硬件渲染,其中的每一步既在生产数据也在消费前一个流程的数据,那么会导致任一环节的延迟升高就会成为木桶效应中的短板,从而升高整个流程的延迟甚至崩溃。每一步信息的“保鲜期”很短,如何做到使每个流程的速度彼此匹配,不会因为出现抖动而成为短板,这都需要基于大量线上运行经验、底层的挖掘、即构极致工程思想,一步步在平衡取舍下实现。
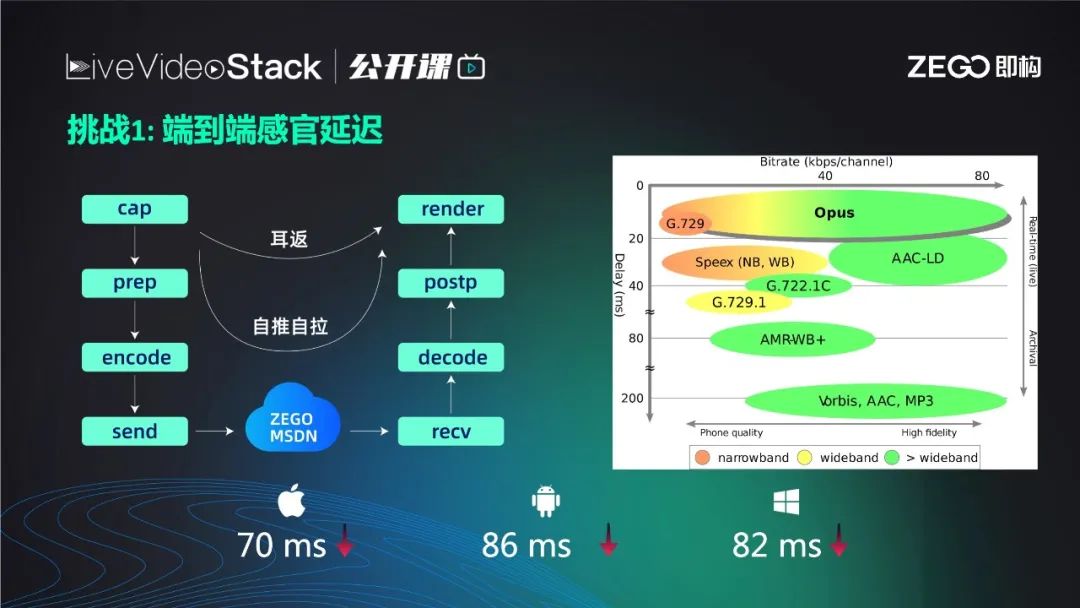
在采集端,无论是ios或是安卓,尤其是安卓,我们采集时用了新的底层接口并做了参数调优,以实现更低的采集延迟;前处理板块,尽量减少了不必要的前处理,对必要的3A包括声音美化,进一步精简处理算法,将延迟降至更低;编码板块,尽量使用Opus(纵坐标代表延迟,横坐标代表码率),右图看到Opus在码率从低到高的过程中,延迟一直很低;网络传输的优化包括实时监控主动探测;对端的拉流侧也相同,推流只是一半,拉流如何保证低延迟渲染及解码都关系着延迟高低,大家可以猜测我们肯定把jitterbuffer设置非常低,只有几十毫秒,但其实jitterbuffer是两难的取舍,设置太低时缓存池小导致卡顿,设置太高时卡顿率下降但是延迟升高,所以需要经过大量数据进行平衡得出结果。
最终即构做到保证稳定流畅前提下,iOS延迟在70ms以内,安卓平均在86ms以内(高通芯片低于86ms,海思芯片稍高于86ms低于100ms),Windows表现正常。从声乐角度、人类听觉原理上通过测试得出,在实时合唱场景中,只要控制端到端延迟稳定在130ms以内,作为主场和副唱,听到的对端歌声和自身感觉一致,不会影响演唱。

即构主要通过对网络传输链路进行优化来保持网络端的稳定并尽量降低RTT、抖动。优化分为两点:
第一,在全球部署了500多个节点,覆盖200多个国家。节点之间可进行主动探测,探测节点之间的链路、sdn线路及当前状态,而不是只依赖于线上用户跑的数据,被动地收集日志;
第二是即构的产品SDK,在接入之前也会进行主动探测的过程。
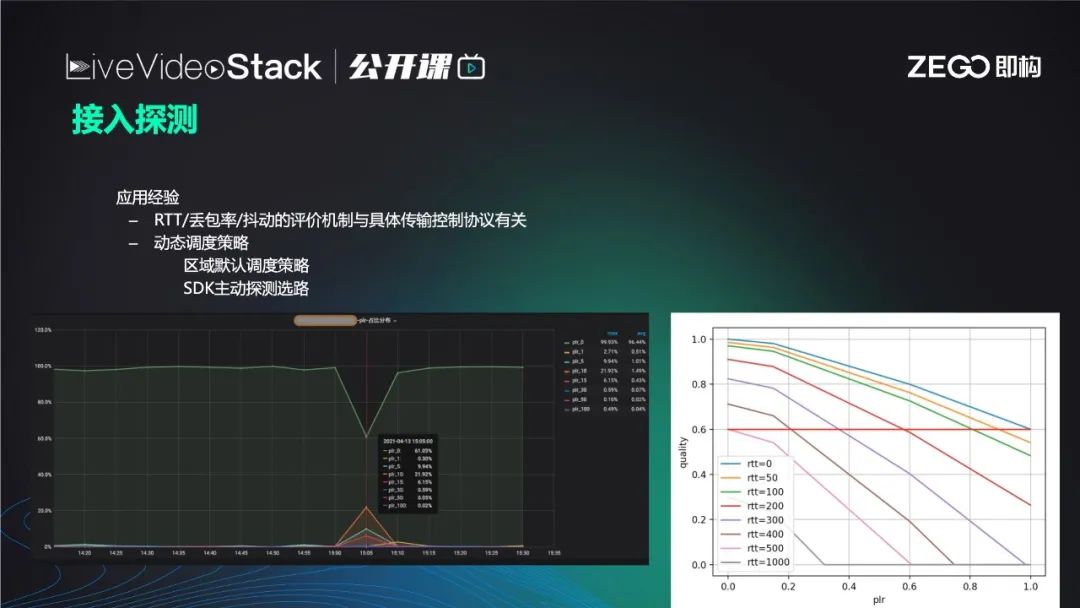
接入之前进行主动探测是调度策略所要求的,一般是两个策略并具:
默认调度策略,即调度服务器实时获取不同节点网络质量,服务器质量,经过算法汇总后,为某一区域用户默认指派某一集群节点服务器。但由于网络瞬息万变,如网络抖动,节点质量发生变化,默认调度策略可能存在反应不及时的情况。因此就需要SDK用户端在接入之前,主动探测、选路,接入探测对比默认调度策略分配节点与其它节点RTT、丢包率、下载速度等,选择更为优质的节点。
03
实时合唱场景中实现极致工程化的经验

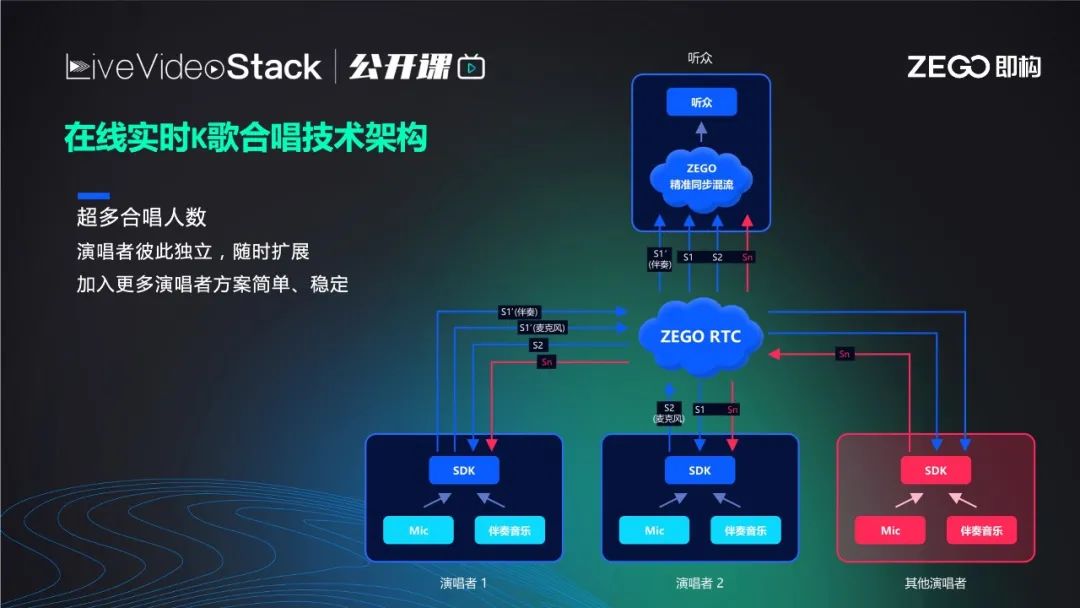
K歌最早是“弱互动”甚至没有互动,用户录好歌曲后上传到社区或者云端服务器,其他用户看到作品后进行评价,唱的好的用户在社区里人气就比较高。后来出现了多人KTV,市面上以抢唱及轮唱为主,少有能够做到伪实时合唱(下文会解释)。今年落地的几个实时合唱项目都由即构科技支持拓宽,可以支持双人、三人甚至几十个人大合唱。
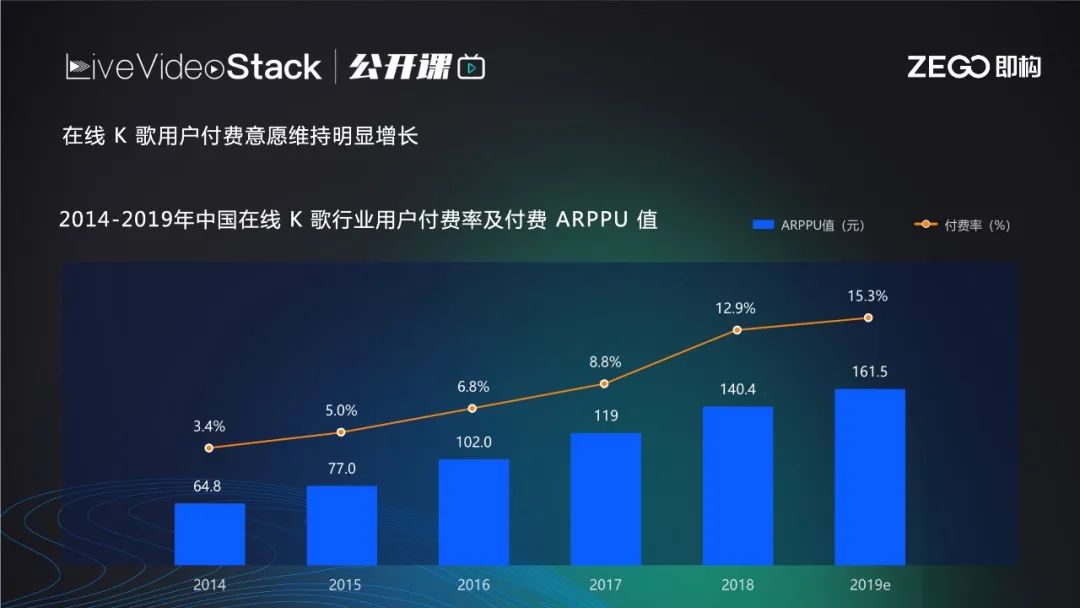
前中国K歌行业用户意愿及付费率逐步升高。
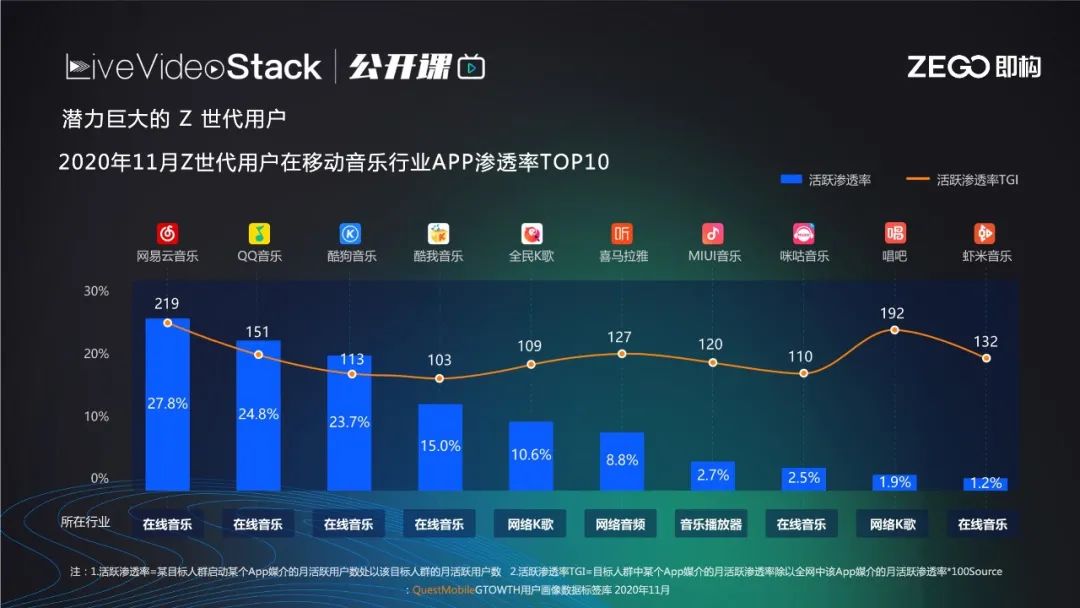
潜力巨大的Z世代用户使用的在线音乐产品中排名前十甚至有50%都和K歌相关,比如全民K歌、唱吧、酷狗,酷狗有自己的酷狗直播、酷狗唱唱、酷狗酷群等。
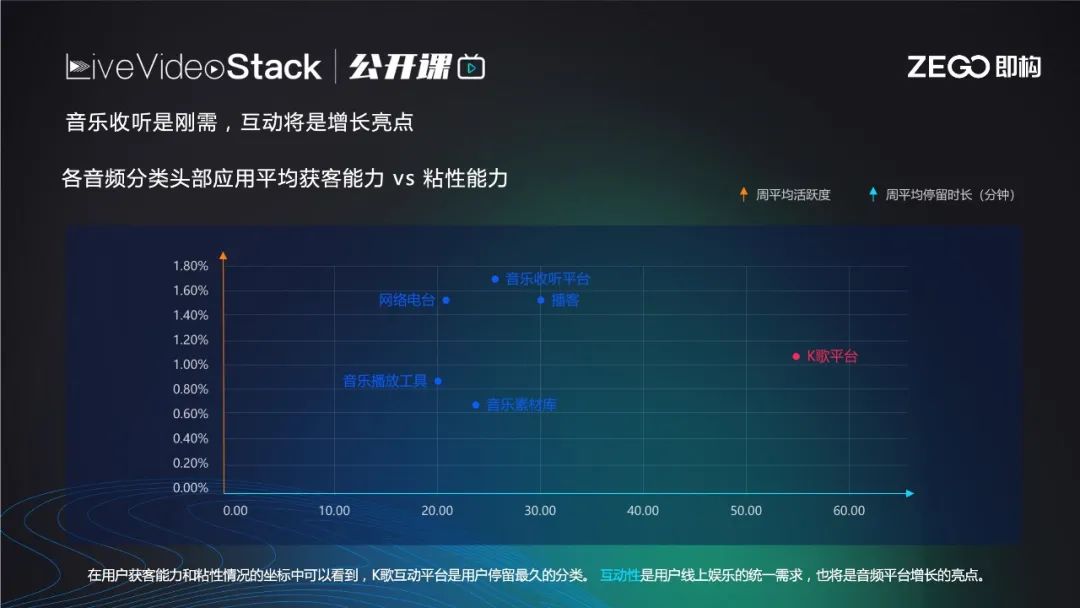
目前在线KTV无论是获客能力还是用户黏性都位居第一,这是一个很火热的场景,对用户社交及互动的吸引力非常高。

上文提到目前市面最多的“伪实时合唱”实质是串行合唱,特点是主唱基本无法听见副唱的声音,他们之间的延迟高达500ms以上,这对节奏较快的歌曲来说会相差1-2拍,严重影响主唱节奏。所以一般“伪实时合唱”的app中,主唱都听不见副唱的声音从而避免干扰,但这和真正的线下K歌完全不同。另外是多人合唱难以落地,因为串行合唱只能主唱串副唱,副唱串观众,无法做到多人合唱。
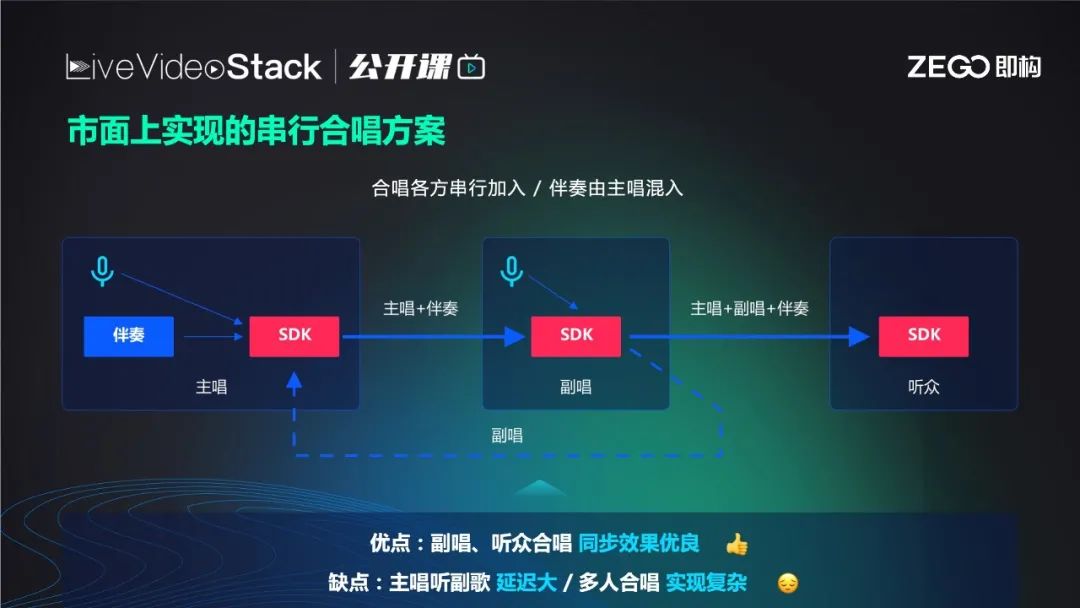
串行合唱方案的架构很简单,主唱先在本地使用麦克风唱歌,麦克风声音过来后加入伴奏音乐混成一路流后推给副唱,副唱听到主唱声音的同时按照节奏从麦克风录入声音,最后的音乐有三个部分,主唱人声、副唱人声和伴奏音乐。最后一起通过低延时或cdn方式播放给观众。
此方案的缺点是,主唱声音到达后,副唱才可以唱,副唱声音回退后,主唱才能听到,一去一回双倍延迟大概500ms声导致主唱体验糟糕,听不见其他人的声音,从而失去社交体。
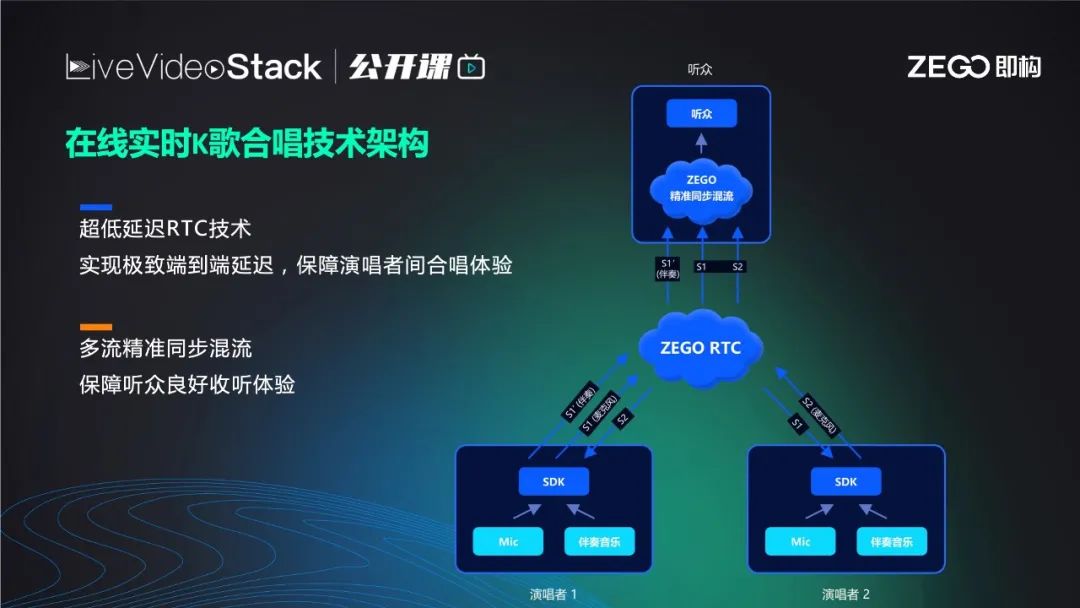
为了解决以上痛点,真正实现线上K歌贴近线下K歌,即构设计了在线实时K歌合唱技术架构。
此架构完全不同于串行架构,它是变形架构,不分主唱和副唱,只分为歌唱者1和2。在业务侧选择一人作为麦主,麦主和另一副唱把麦克风采集的歌声推给 ZEGO RTC,不同的是,麦主会额外推一路音乐,也就是推两路流(一个伴奏一个人声),其他合唱者只需要推自己人声即可。
如果是多人合唱也相同,图中右下红色框可表示一位或多位歌唱者。总之有n个人合唱就有n+1路流,ZEGO RTC会将到达的每一路流时间戳逐帧对齐。这里的时间戳是NTP的绝对时间戳,是由每位歌唱者在歌唱之前向同一个网络NTP时间服务器,通过NTP时间协议获取的绝对时间,对每个人来说都一样。在此前提下,混流服务器就可以把每个人音频的每一帧时间戳取出,因为音频每秒有50帧,相当于每秒把每帧的时间戳取出。然后跟其他所有流的时间戳对比,将相同时间戳的帧合成一路流后播放给观众,观众听到的流里歌声一定是齐的,当然前提是歌手的节奏准确。
那么实现架构原理的前提是什么,歌手如何同步把自己和他人进度相同的歌声推上云,也就是如何保证歌手唱歌的进度和他人一样。唱歌进度取决于伴奏进度,如何保证每位歌手听到的伴奏进度和他人一样。即构给出了一个创新解决方案,不同于串行的一个人推出音乐给别人听,上文强调伴奏推出来只是给观众听,此方案是让每位歌手本地播放伴奏音乐,伴奏音乐基于每位歌手本地提前同步好的绝对NTP时间,约定好12345倒数后同时播放本地伴奏的绝对时间值,只要到了约定时间,所有人本地的媒体服务器会同时播放同首伴奏音乐,只要伴奏音乐对齐,所有人唱歌进度自然也就对齐了。
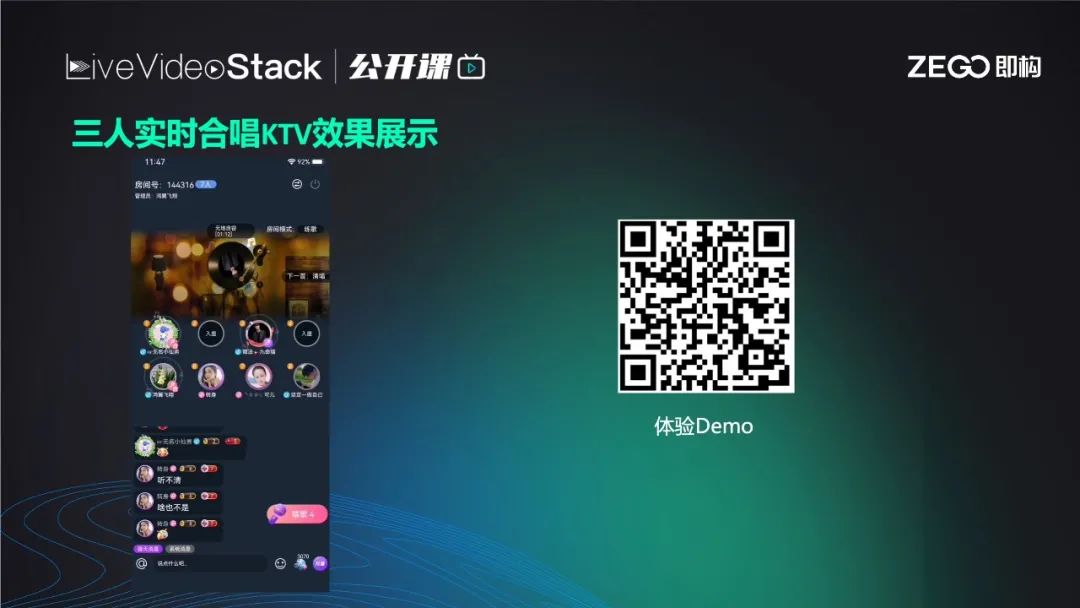
这段音频是三人实时合唱KTV的效果展示,可以听到三人合唱进度非常齐,很难听出是线上合唱,这是每位歌手听本地的伴奏进度来实时合唱的。无论是观众角度还是麦上的其他歌手听到的效果都相同,用户体验非常好。

上文提到了每一步的做法,这里不再赘述。
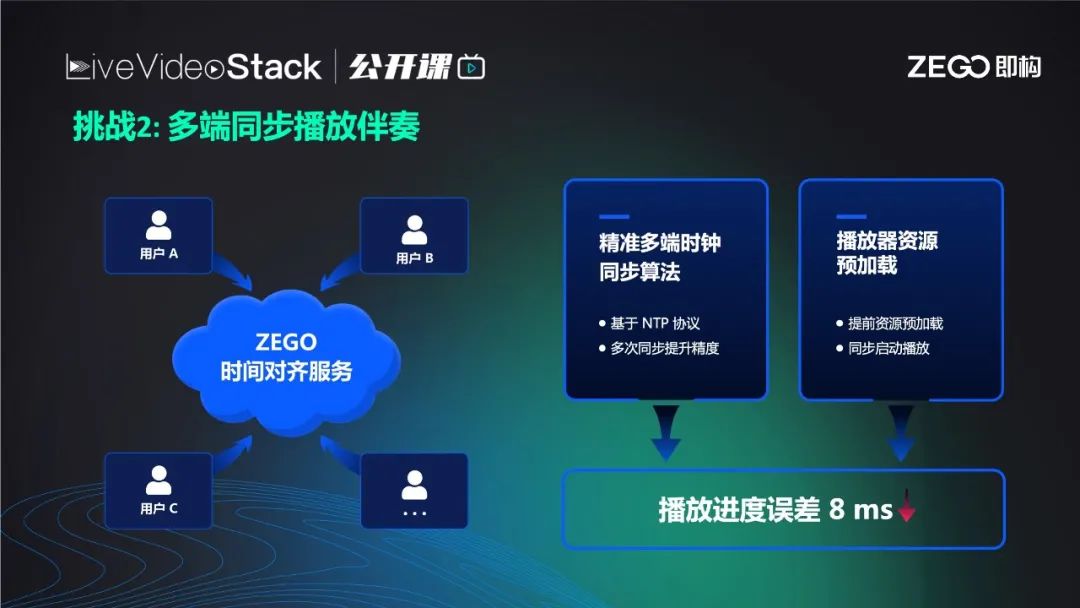
每位歌手本地同步播放伴奏有两个前提:第一,是提前每个端获取同步NTP网络时间;第二,是本地的媒体播放器预加载歌曲资源,只有全部预加载之后,才开始倒计时54321开播,播放器就可以在几毫秒之内开始播放。目前可以做到进度误差在8ms之内,对整个延迟的影响微乎其微。
开始两个人一起合唱可以保障,如果中途有人加入合唱,或是唱到一半播放器突然卡顿,一卡就是50ms,又或是中途用户插拔耳机造成底层流媒体引擎的暂停重启,延迟了几十毫秒,一来一回误差逐渐变大,播放进度误差从8ms到50ms甚至100ms,再加上延迟可能达到200ms。
针对这些情况设置有相应的独特算法,实时从麦主的流获取当前唱歌进度,以SEI方式写在流里,频率可以自定义,非麦主歌唱者不断从麦主流取得进度值,并且比对与麦主流中的进度值相对应的NTP时间戳和发送时间。然后再与非麦主的本地播放进度进行比对,知道麦主在一个NTP时间的进度是多少,再比对本地当前的播放进度,相减就可以消掉网络延迟误差,还可精确预测出麦主目前的进度。非麦主歌手只需向麦主seek对齐即可,这里涉及到seek精度问题,许多厂商的seek精度无法做到很低,大概在百毫秒级,我们经过一系列攻坚,目前可以做到10毫秒级seek从而完成以上动作。
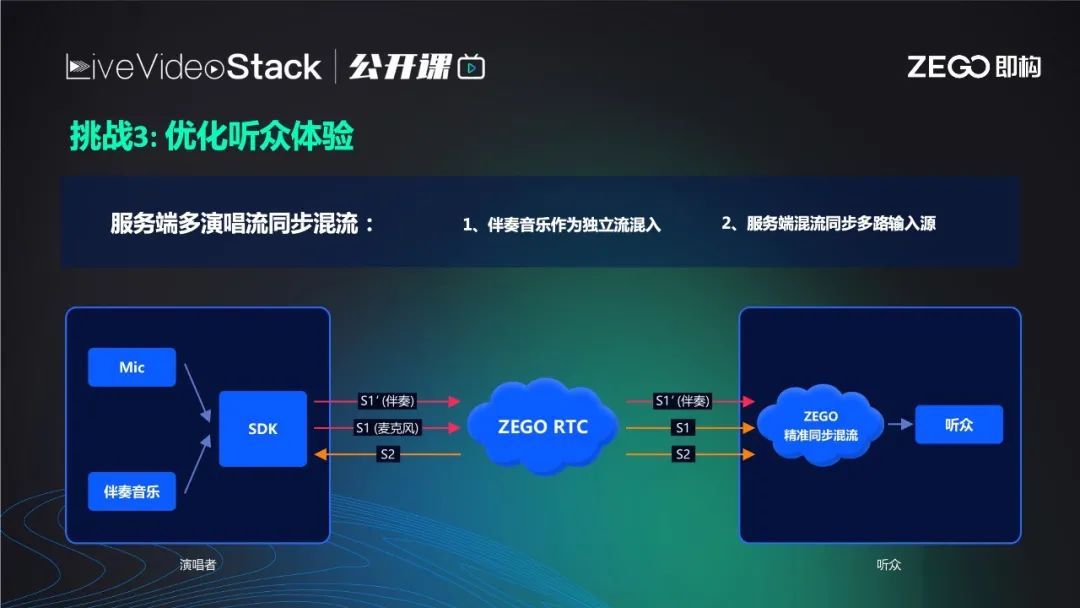
上文也提到了混流服务器是逐帧对齐麦上歌手的所有音频流并混流在一起,从而保证观众的听歌体验。

为了避免网络环境较差的用户场景体验较差,我们做了一些代码和相关参数,接入场景后建议用户合唱之前进行测速,主要测试RTT和丢包率。如果用户网络较差,业务层会给出友好的业务引导,比如建议用户优化网络后再使用进行合唱。

实时合唱除了要求超低延迟以及场景匹配能力达到要求之外,还需要本地播放音乐。那么如何获得版权?响应国家“净网”行动,不能要求用户从其他渠道获得音频,为了让更多平台接入实时KTV,即构和TME打通了版权购买通道,版权费用是其他渠道的1/5以下,支付方式灵活,曲库非常广。

音速达引擎基本覆盖老年、中年、青年及抖音热门歌曲,满足了不同年龄层用户的诉求。
04
超低延迟场景的未来展望

与其说是超低延迟场景的未来展望,其实更确切的说应该是用户之间的实时互动,实时泛娱乐,甚至整个网络社会未来的走向。未来必然会出现更强大的终端,编解码器可能会有H.266或者H.267,编解码质量越来越高,压缩率也越来越高,网络可能发展为6G、7G,传输速度越来越快,丢包率、延迟越来越低。
基于这些系统基石,未来的网络一定是以元宇宙、沉浸式体验、虚拟第二人生为主的充满VR/AR交互、肢体交互、表情控制元素的完整虚拟世界。完全满足用户在线上模拟线下社交的所有诉求。
元宇宙

很多年前的《黑客帝国》,相信大家都了解过,电影讲述了未来社会,人类的生化身体被禁锢在一些维生设备中,每个人所认为的真实社会都是超级AI模拟出的虚拟社会。无论是从肉眼还是哈勃望远镜,我们所能观测到的现实世界都是来自感受到的。从这个角度出发,只要模拟的够逼真,虚拟和现实的区别到底在哪里。现在有一些学术流派说宇宙是一个庞大的超级AI模拟出来的,例证是普朗克时间无法再分,也就是超级AI的计算机频率无法再细分。
总之聚焦于不远的未来,元宇宙一定是完整的,完全自洽的虚拟世界,经济可能来源于区块链。主要依赖于超低延迟,因为每个人都有自己的虚拟形象,虚拟形象之间的社交几乎完全等同于真实社交,所需延迟会低于现在要求的70ms。沉浸式体验和社交体验更依赖于虚拟设备制造厂商,如HTC、惠普、SONY等,VR渲染引擎依靠于游戏厂商。

举个例子,如去年疫情期间,Travis Scott在当时一个用户量很大的游戏《堡垒之夜》中利用VR举办了一场虚拟演唱会,虽然只有10min,但参加用户超过了1200万。短时间内如此大的流量聚集线下基本都无法实现,并且玩家在游戏中可以通过不同的角度观看演唱会,歌手本人在10min内切换了大概十种场景,场景的多样性也是线下演唱会无法比拟的。

从二十多年前的第二人生开始,到现在出现了许多真人社交基于VR引擎的游戏。图中展示的是VR虚拟课堂,人物角色是由VR引擎生成的虚拟形象,声音来自真实的玩家。左上角是用户在游戏中的角色,他们之间可以进行实时语音沟通,与真实世界的教室场景及交互完全相同。
云游戏场景

图中是云游戏的场景, 云游戏不消耗本地硬件资源而是在服务器上,服务器实时运算游戏引擎,把游戏画面以超低延迟传给用户的终端设备,终端屏幕的触控或是电脑键盘鼠标等交互再以超低延迟传回给服务器。目前画面延迟基于上文提到的超低延迟技术可以做到几十毫秒以内,应用新的信令通道,延迟可以压缩到10ms以内。与本地运行游戏基本没有区别,并且节约了显卡、PC、旗舰手机的成本,任意终端都可以不发热地运行游戏。
云游戏+一起玩+直播

我们希望结合云游戏、一起玩和直播,手机本地没有运行超大3D游戏带来的硬件损耗,也就可以实现边玩游戏边直播、和好友连麦、组队或是和粉丝聊天互动。
虚拟形象
视频片段中展示是一组正在唱歌的虚拟形象,是我们即将在10月份上线的虚拟形象引擎。虚拟形象引擎会同时具备人物模型、相关能力、动作、表情等,虚拟形象的表情可以模拟摄像头内的用户表情。并且会将其包装成一套整体的能力,平台接入时无需专业游戏开发人员,只需接入SDK即可快速实现。尽管和真正的VR、沉浸式体验差距较大,但作为虚拟形象的快捷接入也是迈出了第一步。
VR场景
后续我们会添加支持VR设备的VR引擎的输出能力,VR设备支持目前市面上常见的如索尼、HTC、惠普等硬件。
以上就是本次分享的内容,谢谢!
扫描图中二维码或点击阅读原文
了解大会更多信息

喜欢我们的内容就点个“在看”吧!

以上是关于陈曦:超低延迟下的实时合唱体验升级的主要内容,如果未能解决你的问题,请参考以下文章