Learning Spark——使用spark-shell运行Word Count
Posted Trigl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Learning Spark——使用spark-shell运行Word Count相关的知识,希望对你有一定的参考价值。
在hadoop、zookeeper、hbase、spark集群环境搭建 中已经把环境搭建好了,工欲善其事必先利其器,现在器已经有了,接下来就要开搞了,先从spark-shell开始揭开Spark的神器面纱。
spark-shell是Spark的命令行界面,我们可以在上面直接敲一些命令,就像windows的cmd一样,进入Spark安装目录,执行以下命令打开spark-shell:
bin/spark-shell --master spark://hxf:7077 --executor-memory 1024m --driver-memory 1024m --total-executor-cores 4executor-memory是slave的内存,driver-memory是master的内存,total-executor-cores是所有的核数
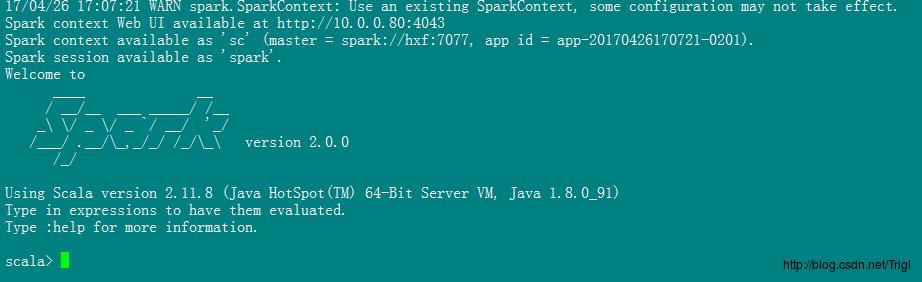
终端显示如下图,可以看到spark-shell已经帮我们初始化了两个变量sc、spark,sc是Spark context,spark是Spark session,没吃过猪肉见过猪跑,像这些包含context啊session啊不用想就很重要,同样Spark的执行就是靠这俩变量,目前先混个眼熟,日后再说
Spark管理页面显示如下图:

OK,现在我们开始动手敲第一个例子,统计Spark目录下 README.md 这个文件中各个单词出现的次数:

首先给出完整的代码,方便大家有一个整体的思路:
val textFile = sc.textFile("file:/data/install/spark-2.0.0-bin-hadoop2.7/README.md")
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCounts.collect()代码很简单,但是第一次见到可能不是很理解,下面进行讲解
1. Spark读取原始数据的方式
首先读取 README.md:
val textFile = sc.textFile("README.md")
这条代码是读取原始数据转化为Spark自己的数据格式RDD,一般读取原始数据有两种方式
1、测试用法:调用SparkContext的parallelize方法
val rdd = sc.parallelize(Array(1 to 10))这样就获取到了1到10的数组,多用于测试程序,正式开发不用这种
2、正式用法:所有Hadoop可以使用的数据源Spark都可以使用,当然我们最常用的还是SparkContext的textFile方法,如读取Hdfs上的文件:
val rdd = sc.parallelize("hadoop://hxf:9000/test/test.log")2. Spark的基础数据类型RDD
上面通过textFile得到的结果叫做RDD,是Spark的基础数据类型。
RDD是Resillient Distributed Dataset的简称,意思是弹性分布式数据集,这个名字不是太好理解,但是我们可以从字面上了解到RDD是分布式的、并且是数据集合,假设分布式系统下有多个文件,这些文件有很多行,RDD指的是所有这些文件所有行的集合,而不是单独某一行。所以我们对RDD进行的一系列操作都是对整个集合进行的操作,并且Spark是将整个RDD放在内存中进行处理,而不是像MapReduce那样放在磁盘中,所以Spark的运算速度才会比MapReduce快。
接下来继续讲解代码:
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCounts.collect()
最后的结果显示各个单词出现的次数,代码中的flatMap、map、reduceByKey是RDD的转化操作,collect是RDD的行动操作,不理解没关系,后文详解。这一节先暂时讲到这里,欲听后事如何,请听下回分解。
以上是关于Learning Spark——使用spark-shell运行Word Count的主要内容,如果未能解决你的问题,请参考以下文章
Spark-SQL CLI:未调用 SupportsPushDownFilters.pushFilters
Learning Spark——使用spark-shell运行Word Count
Learning Spark——使用Intellij Idea开发基于Maven的Spark程序