Learning Spark——RDD常用操作
Posted Trigl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Learning Spark——RDD常用操作相关的知识,希望对你有一定的参考价值。
RDD支持两种操作:转换(Transformation)操作和行动(Action)操作。
为什么会分为两种操作,这两种操作又有什么区别呢?
我们先考虑一下平常我们使用的一些函数,举个例子Long.toString(),这个转换是把Long类型的转换为String类型的。
如果同样的事情在Spark中,是如何执行的呢?
在Spark中转换操作是“懒”执行的,就是说虽然我答应了把Long转换成String,但是我只是把这个事情记在小本本里面,并不是现在去做,而是以后有了让我做的动力才去做。
那么什么才是这个“动力”呢?那就是行动操作。一般来说,转换操作是把某种RDD转换成另一种RDD,而行动操作却是实际地产生一个结果,比如把RDD写入一个外部文件系统,或者打印到驱动器程序输出中。
这就好比我学数据挖掘,我网上搜了很多攻略,告诉我可以先看看公开课,再读读书,然后参加Kaggle竞赛,我信心满满地把这些都记录下来,放在了某个和岛国片一样重要的收藏夹下面,然后。。。就没有然后了。
But!如果此时,老大告诉我,我们的产品要添加基于位置性别以及年龄的用户推荐,给你一个月时间去学习,否则卷铺盖走人。
面临着这种生存还是死亡的问题,我当然会鼓足干劲力争上游,把之前记录好的学习步奏按部就班地做一遍,最后把推荐系统做了出来。
这里,公开课->读书->Kaggle可以看做是转换操作,做出推荐系统是行动操作,才是我们要的最终结果。只有有一个明确的行动操作,转换操作才会被执行。
所以说人生如码码如人生,人生来就有惰性,想要坚持下去,任何时候都不要忘记我们到底想要什么,我们的目标是什么。
OK,言归正传,大家可以考虑一下Spark的转换操作为什么要用这种“懒”执行的机制,而不是正常地转换一次执行一次呢?
Spark所有RDD都存在内存上,非常追求速度,所以要尽量减少RDD转换的次数。使用“懒”执行可以把整个RDD转换过程中可以合并的步奏合并起来执行,例如原来是a=>b,b=>c,Spark发现可以合并成a=>c,这样就省了一步,加快了速度。对于我们开发者来说,就不需要考虑为了减少转换次数如何从a直接跳到c,我们每次写一个简单的转换操作a到b就可以了,这就是它的强大之处。
没有对比就没有伤害,在类似Hadoop MapReduce 的系统中,开发者常常花费大量时间考虑如何把操作组合到一起,以减少 MapReduce 的周期数。
下面我们结合代码讲解一下几种常见的转换操作和行动操作
1. 基本转换操作
map
将一个RDD中的每个数据项,通过map中的函数变为一个新的元素。
输入分区与输出分区一对一,即:有多少个输入分区,就有多少个输出分区。
// 文件内容
hadoop fs -cat /test/test.log
haha 你好
hehe 你滚
heihei 你猜
// map操作
val data = sc.textFile("/test/test.log")
val mapresult = data.map(line => line.split(" "))
mapresult.collect
Array[Array[String]] = Array(Array(haha, 你好), Array(hehe, 你滚), Array(heihei, 你猜))
flatMap
flatMap可以看做是两步,第一步是map,第二步是flat。假设原始数据是 RDD[A],经过map以后变成 RDD[集合[B]],然后经过flat变成 RDD[B],所以如果我们的转换操作会产生集合,但是我们要的结果不是这个集合,而是集合里面的元素,那么就可以使用flatMap
// flatMap操作
val flatmapresult = data.flatMap(line => line.split(" "))
flatmapresult.collect
Array[String] = Array(haha, 你好, hehe, 你滚, heihei, 你猜)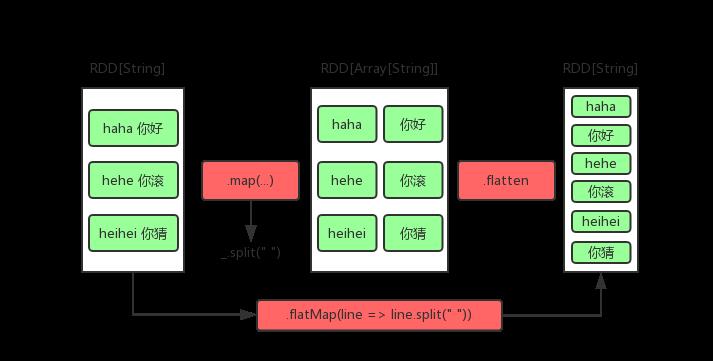
filter
这个算子相对简单,对输入的RDD中的每一个元素,通过一个函数判断真假,过滤掉结果为假的元素
// filter操作
val intRDD = sc.parallelize(1 to 10)
val filterRDD = intRDD.filter(i => i > 3)
filterRDD.collect()
Array[Int] = Array(4, 5, 6, 7, 8, 9, 10)distinct
对RDD中的元素进行去重操作
// distinct操作
val rdd = sc.parallelize(List("My","Book","My","Pen","Your","Her","His","Book","Pen"))
var distinctRDD = rdd.distinct()
distinctRDD.collect()
Array[String] = Array(My, Pen, Book, Her, His, Your)coalesce
def coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null): RDD[T]
该函数用于将RDD进行重分区,使用HashPartitioner。
第一个参数为重分区的数目,第二个为是否进行shuffle,默认为false
scala> var data = sc.textFile("/test/test.log")
data: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[53] at textFile at :21
scala> data.collect
res37: Array[String] = Array(haha 你好, hehe 你滚, heihei 你猜)
scala> data.partitions.size
res38: Int = 2 //RDD data默认有两个分区
scala> var rdd1 = data.coalesce(1)
rdd1: org.apache.spark.rdd.RDD[String] = CoalescedRDD[2] at coalesce at :23
scala> rdd1.partitions.size
res1: Int = 1 //rdd1的分区数为1
scala> var rdd1 = data.coalesce(4)
rdd1: org.apache.spark.rdd.RDD[String] = CoalescedRDD[3] at coalesce at :23
scala> rdd1.partitions.size
res2: Int = 2 //如果重分区的数目大于原来的分区数,那么必须指定shuffle参数为true,//否则,分区数不便
scala> var rdd1 = data.coalesce(4,true)
rdd1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at coalesce at :23
scala> rdd1.partitions.size
res3: Int = 4repartition
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
该函数其实就是coalesce函数第二个参数为true的实现,重新分区很有必要,比如如果分区数过于多,而每个分区对应的内存不够用,那么可能会发生OOM异常,这是就可以重新分区减少总分区数
scala> var rdd2 = data.repartition(1)
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at repartition at :23
scala> rdd2.partitions.size
res4: Int = 1
scala> var rdd2 = data.repartition(4)
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[15] at repartition at :23
scala> rdd2.partitions.size
res5: Int = 4randomSplit
def randomSplit(weights: Array[Double], seed: Long = Utils.random.nextLong): Array[RDD[T]]
该函数用来切分RDD成为多个RDD,有两个参数,第一个是权重,是一个双精度浮点数数组,正常情况下该数组的和应等于1;第二个是随机数种子,随意写一个整数就OK。
该函数就是用来把一份数据分成几份,比如我们做推荐系统,就会将数据按某个权重分成训练数据和测试数据
// 一个包含10万个数的RDD
scala> var rdd = sc.makeRDD(1 to 100000,10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[18] at makeRDD at <console>:24
// 分成两份,三七开
scala> var splitRDD = rdd.randomSplit(Array(0.3,0.7),10)
splitRDD: Array[org.apache.spark.rdd.RDD[Int]] = Array(MapPartitionsRDD[19] at randomSplit at <console>:26, MapPartitionsRDD[20] at randomSplit at <console>:26)
// 最后的结果差不多是三七开
scala> splitRDD(0).count()
res20: Long = 30072
scala> splitRDD(1).count()
res21: Long = 69928union
懂SQL的应该对这个函数很熟悉,就是将结构相同的两个RDD合并在一起,合并后的RDD可能包含重复元素
scala> var rdd1 = sc.makeRDD(1 to 2,1)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[45] at makeRDD at :21
scala> rdd1.collect
res42: Array[Int] = Array(1, 2)
scala> var rdd2 = sc.makeRDD(2 to 3,1)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[46] at makeRDD at :21
scala> rdd2.collect
res43: Array[Int] = Array(2, 3)
scala> rdd1.union(rdd2).collect
res44: Array[Int] = Array(1, 2, 2, 3)于此类似的函数还有:intersection,返回两个RDD的交集,去重;subtract,返回在RDD中出现,并且不在otherRDD中出现的元素,不去重
zipWithIndex
该函数将会产生一个键值对,键是RDD中的元素,值是从零开始的ID值
scala> var rdd2 = sc.makeRDD(Seq("A","B","R","D","F"),2)
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[34] at makeRDD at :21
scala> rdd2.zipWithIndex().collect
res27: Array[(String, Long)] = Array((A,0), (B,1), (R,2), (D,3), (F,4))Refer
http://lxw1234.com/archives/2015/07/363.htm
http://www.iwwenbo.com/spark-map-flatmap
以上是关于Learning Spark——RDD常用操作的主要内容,如果未能解决你的问题,请参考以下文章
Learning Spark中文版--第六章--Spark高级编程
Spark RDD常用算子操作 键值对关联操作 subtractByKey, join,fullOuterJoin, rightOuterJoin, leftOuterJoin
pyspark3.0.0+spark3.0.0学习01(RDD的创建,RDD算子(常用Transformation算子 常用Action算子 分区操作算子)的学习及应用)