深度学习Generative Adversarial Networks ,GAN生成对抗网络分类
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习Generative Adversarial Networks ,GAN生成对抗网络分类相关的知识,希望对你有一定的参考价值。
目录
1 思维导图

2 大纲
序号对应论文中的参考文献《A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications》
按损失函数分
Original GAN
f-GAN
Energy-based GAN
Least-square GAN
Loss-sensitive GAN
W-GAN、improved W-GAN
Boundary-equilibrium GAN
Boundary-seekingGAN
按网络结构分
Conditional GAN
InfoGAN
Stacked GAN
CycleGAN、DualGAN、 DiscoGAN
Triple GAN
Triangle GAN
TAC-GAN
CVAE-GAN
按应用领域分
图像处理和计算机视觉
超分辨
SRGAN【63】
ESRGAN【64】
CyCle-In-Cycle GANs【65】
SRDGAN【66】
TGAN【67】
图像合成和处理
DR-GAN【68】
TP-GAN【69】
PG【70】
PSGAN【71】
APDrawingGAN【72】
IGAN【73】
Introspective adversarial networks【74】
GuaGN 【75】
纹理合成
MGAN【76】
SGAN【77】
PSGAN【78】
目标检测
Segan【79】
perceptual GAN【80】
MIGAN【81】
视频
VGAN【82】
DRNET【83】
Pose-GAN【84】
video2video【85】
MoCoGan【86】
序列数据
自然语言处理
RANKGAN【87】
IRGAN【88】
TAC-GAN【92】
音乐
RNN-GAN【91】
ORGAN【92】
SeqGAN【93-94】
3 经典GAN简介
GitHUb代码汇总https://github.com/823316627bandeng/Keras-GAN
3.1 SGAN
是在半监督学习的背景下提出的,与监督学习(其中每个样本都需要一个标签)和非监督学习(其中不提供标签)不同,半监督学习具有一小部分示例的标签。与FCGAN相比,SGAN的鉴别器是multi-headed的,即具有softmax和Sigmoid,以对真实数据进行分类并分别区分真实和生成样本。作者在MNIST数据集上训练SGAN,结果表明与原始GAN相比,SGAN中的鉴别器和生成器均得到了改进。
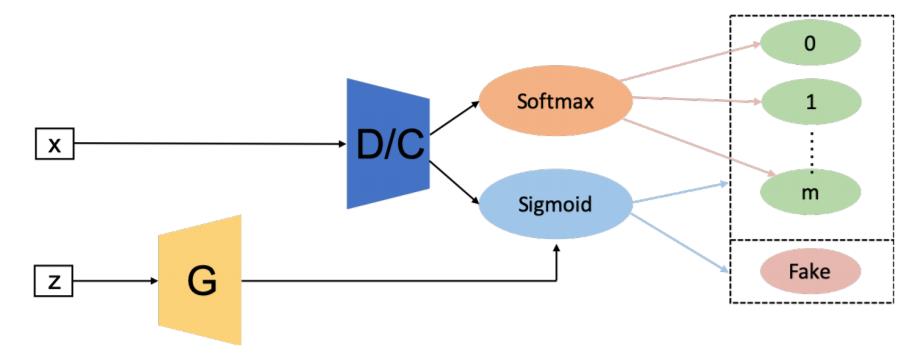
3.2 Conditional GAN
CGAN将随机噪声 和类别标签 作为生成器的输入,判别器则将生成的样本或真实样本与类别标签作为输入。以此学习标签和图片之间的关联性。具体看代码,用了两次鉴别器。一次是鉴别真样本,一次鉴别生成的样本

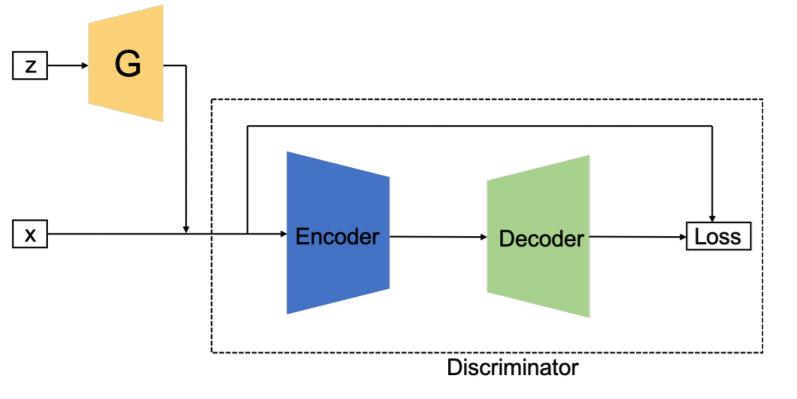
3.3 Bidirectional GAN (BiGAN)
-
整个结构包括三部分:Encode网络,G网络,D网络。 Encode网络,提取原始图片的隐变量。G网络,将噪声生成图片。D网络,判断这个配对(原始图片和隐变量 生成图片和噪声)是来自encoder还是decoder
-
中文翻译是“双向Gan”,对于配对“原始图片和隐变量 ”原始图片是已知的,隐变量 是学习噪声,对于配对“生成图片和噪声”,噪声是已知的,生成图片是学习原始图片,这就是一个双向学习过程。

3.4 InfoGAN
-
提出把输入的噪声向量分成两部分:(1)z,可以看成是输入的噪声向量。(2)c,对应的语义向量。其中Info代表互信息,它表示生成数据x与隐藏编码c之间关联程度大小。
-
InfoGAN提出一种无监督的方式,让生成网络输入噪声变量z、隐藏编码c,即生成数据可以表示成:G(z,c)。然而,在标准GAN中,如果直接这样作为网络的输入进行训练,那么生成器将忽略隐藏编码的作用,或者可以看成z与c相互独立、不相关。为了解决这个问题,文章提出正则化约束项:隐藏编码c与生成样本G(z,c)的互信息量应该较大,即I(c;G(z,c))应该较大。

3.5 Auxiliary Classifier GAN (AC-GAN)
ACGAN的原理GAN(CGAN)相似。对于CGAN和ACGAN,生成器输入均为潜在矢量及其标签,输出是属于输入类标签的伪造图像。对于CGAN,判别器的输入是图像(包含假的或真实的图像)及其标签, 输出是图像属于真实图像的概率。对于ACGAN,判别器的输入是一幅图像,而输出是该图像属于真实图像的概率以及其类别概率

3.6 Boundary Equilibrium GAN (BEGAN)
- 应用auto-encoder实现Discriminator
- Discriminator的Loss_D由输入原图(input_img)与Decoder恢复的输出图(recover_img)之间的逐点error构成
- Loss_D可看成是随机的分布,由real_img所形成的Loss_D_Real分布与由Generator生成的假图(fake_img)所形成的Loss_D_Fake分布,出现了两个分布,用Wasserstein Distance(简称WD)来衡量这两个分布的距离。Discriminator的目标是尽量拉开这两个分布的距离,而Generator的目标是缩小这两个分布的距离——GAN的基本思想。
- 引入了一个均衡的概念来调节Discriminator训练时的两个目标的比重:目标1,是提高auto-encoder的重构能力,即auto-encoder恢复输入input_img的能力;目标2,提高D的分辨真伪的能力。该均衡控制量是可以变动的,就像是电路中的反馈环,构成了反馈比例控制(Proportional Control)迭代机制。
3.7 Self-attention GAN (SAGAN)
《Self-Attention Generative Adversarial Networks(SAGAN)》网络主要引入了注意力机制,不仅解决了卷积结构带来的感受野大小的限制,也使得网络在生成图片的过程中能够自己学习应该关注的不同区域。
GAN之前存在的问题: 对于含有较少结构约束的类别,比如海洋、天空等,得到结果较好;而对于含有较多几何或结构约束的类别则容易失败,比如合成图像中狗(四足动物)的毛看起来很真实但手脚很难辨认。这是因为复杂的几何轮廓需要long-range dependencies(长距离依赖),卷积的特点就是局部性,受到感受野大小的限制很难提取到图片中的这些长距离依赖。虽然可以通过加深网络或者扩大卷积核的尺寸一定程度解决该问题,但是这会使卷积网络丧失了其参数和计算的效率优势。
论文的主要贡献:
把self-attention机制引入到了GAN的框架中,对卷积结构进行了补充,有助于对图像区域中长距离,多层次的依赖关系进行建模,并对该机制做了可视化实验;
在判别器和生成器中均使用spectral normalization,提升生成器的性能;
训练中使用Two Timescale Update Rule (TTUR),对判别器使用较高学习率,从而可以保证生成器和判别器可以更新比例为1:1,加快收敛速度,减少训练时间。

3.8 Deep Convolutional GAN (DCGAN)
该网络主要用的是卷积层,而之前的简单的一些网络用的都是全连接层。

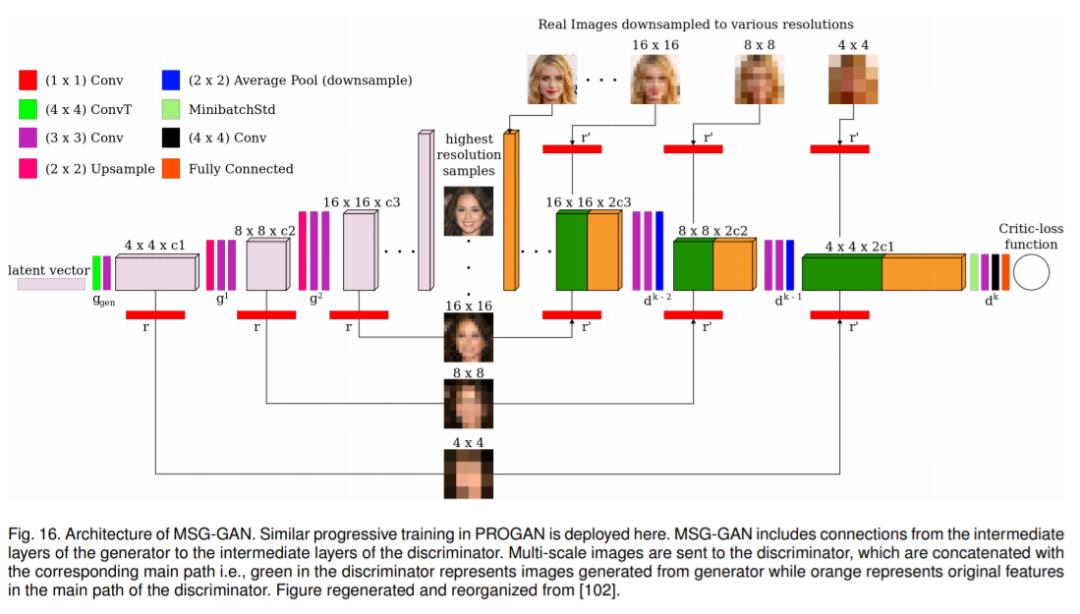
3.9 MSG-GAN
在训练 GAN 的过程中常遇到的一个问题是训练不够稳定, 提出了一种方法, 通过研究如何使用多个尺度的梯度来生成高分辨率图像 (由于数据维数而更具挑战性), 而无需依靠先前的贪婪方法 (例如渐进式生长技术), 来解决图像生成任务的训练不稳定性.
左半部分是生成器, 右半部分是鉴别器. 在生成器中, 粉色的方块是特征图, 将特征图通过 1 ×1 的卷积核来生成下面的图像, 将这些图像传递到鉴别器中对应尺度的位置
以上是关于深度学习Generative Adversarial Networks ,GAN生成对抗网络分类的主要内容,如果未能解决你的问题,请参考以下文章
深度学习Generative Adversarial Networks ,GAN生成对抗网络分类
Diffusion Models/Score-based Generative Models背后的深度学习原理:配分函数
Diffusion Models/Score-based Generative Models背后的深度学习原理:配分函数
Diffusion Models/Score-based Generative Models背后的深度学习原理:基于能量模型和受限玻尔兹曼机
Diffusion Models/Score-based Generative Models背后的深度学习原理:蒙特卡洛采样法和重要采样法
Diffusion Models/Score-based Generative Models背后的深度学习原理:蒙特卡洛采样法和重要采样法