SNE-RoadSeg 解读结合表面法向量的路面分割网络(ECCV2020)
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SNE-RoadSeg 解读结合表面法向量的路面分割网络(ECCV2020)相关的知识,希望对你有一定的参考价值。

本文由加州大学圣地亚哥分校与港科大机器人实验室共同发表,收录于ECCV2020。本文创新型地提出了表面法向估计器(SNE),并将其用于路面分割网络中,使得 SNE-RoadSeg 在不同的数据集中获得了很好的检测性能。
论文:http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123750341.pdf
GitHub仓库:https://github.com/hlwang1124/SNE-RoadSeg
一、SNE-RoadSeg 简介
自由空间检测是自动驾驶汽车视觉感知的重要组成部分。最近在数据融合卷积神经网络(CNNs)方面所做的努力已经显著地改善了语义驱动场景分割。可以将自由空间假设为一个地平面,在该地平面上的点具有相似的曲面法线。
因此,本文首先介绍了一种新的模型——表面法向估计器(SNE),它可以高精度、高效率地从密集的深度/视差图像中提取表面法向信息。此外,本文还提出了一种数据融合的CNN结构,称为RoadSeg,它可以从RGB图像和推断的表面法线信息中提取和融合特征,从而实现精确的自由空间检测。
为了达成研究目的,我们发布了一个在不同的光照和天气条件下收集的,大规模的自由空间检测数据集,命名为Ready-to-Drive(R2D)道路数据集。实验结果表明,我们提出的SNE模块可以使所有最先进的CNN都受益于自由空间检测,并且我们的SNE-RoadSeg在不同的数据集中获得了最好的整体性能。
二、表面法向估计器 SNE
SNE 的作用就是要将输入的深度图转换成表面法向量,并输入到网络中:
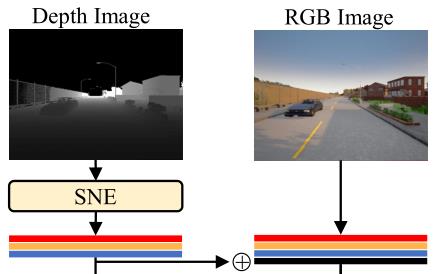
如何准确求取图像中的表面法向量就成为了一个重要的数学问题,下面就来详细介绍它的推到过程。
1、建立相机坐标系到图像像素坐标系之间的关系
其中,p=[x, y],表示像素坐标(x, y);P=[X, Y, Z],表示p在相机坐标系中对应的空间点位置;K是相机内参,由相机标定获得。
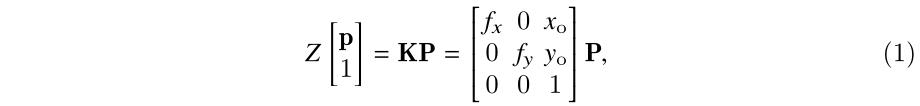
2、建立点P处的法向量方程
点P处的法向量为(nx, ny, nz),则法向量方程可表示为:
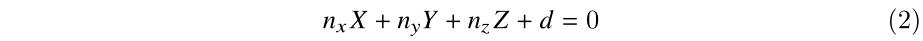
由(1)、(2)式联立可得:
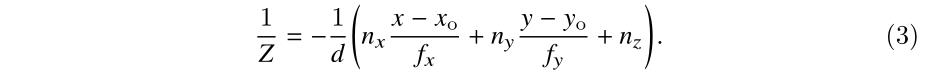
分别对x, y求偏导:
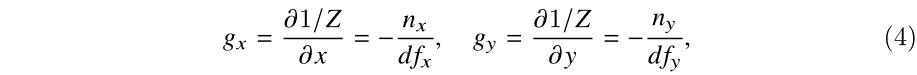
3、表示法向量
由 (4) 式可以得到: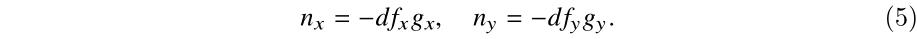
对于任意的
Q
i
∈
N
p
Q_i \\in N_p
Qi∈Np,其中
N
p
=
[
Q
1
,
Q
2
,
.
.
.
,
Q
k
]
N_p =[Q_1, Q_2, ... ,Q_k]
Np=[Q1,Q2,...,Qk],是点 P 的 k 个临近点。将(5)代入(2)中,可以计算出其相应的
n
z
i
n_{zi}
nzi:
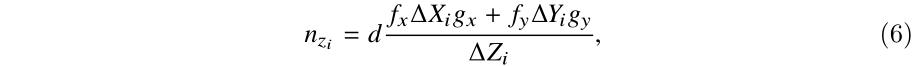
由此可知,法向量可以表示为:
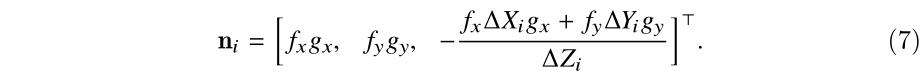
4、球坐标系法向量
由球坐标系性质可知,在点P处的法向量为:
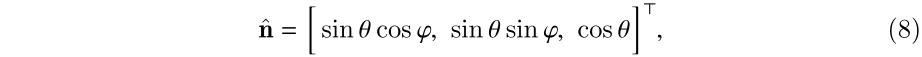
其中,一个角度可以求出来: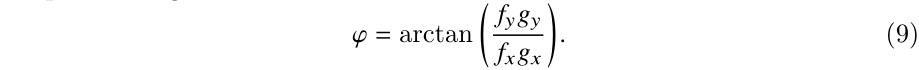
通过建立如下关系式,其中k是点P的k个临近点,
n
^
\\hat{n}
n^表示常规法向量,
n
i
ˉ
\\bar{n_i}
niˉ表示球坐标系下的法向量。
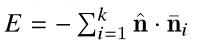
当E最小时,说明
n
i
ˉ
\\bar{n_i}
niˉ与
n
^
\\hat{n}
n^无限接近,此时即可求得理想的
θ
\\theta
θ。即令:
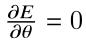
可得
θ
\\theta
θ 的表达式:
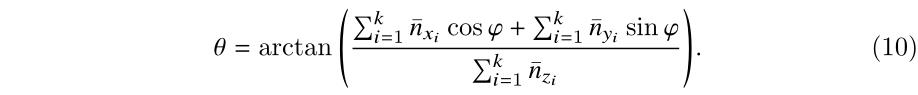
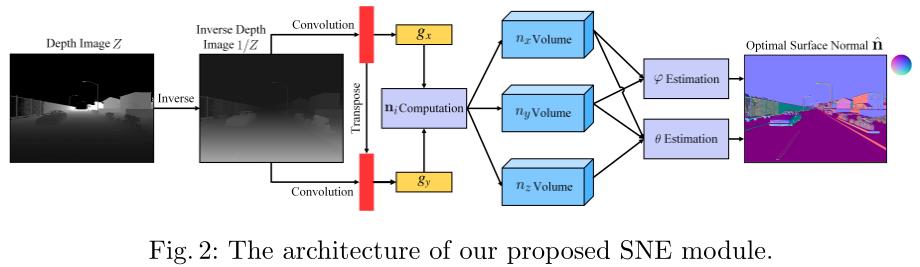
综上所述,整个计算过程,表示可以如下图所示:
三、路面分割架构 RoadSeg
如下图所示,是 SNE-RoadSeg 的整体结构图。在整体结构上,仍然采用的是编码-解码器的结构。不同于 Unet 的是,本文借鉴DenseNet的跳过连接在解码器中实现了更加灵活的特征融合。并且,认为跳过连接仅在编码器和解码器的相同尺度特征图上强制聚合是一个不必要的约束。
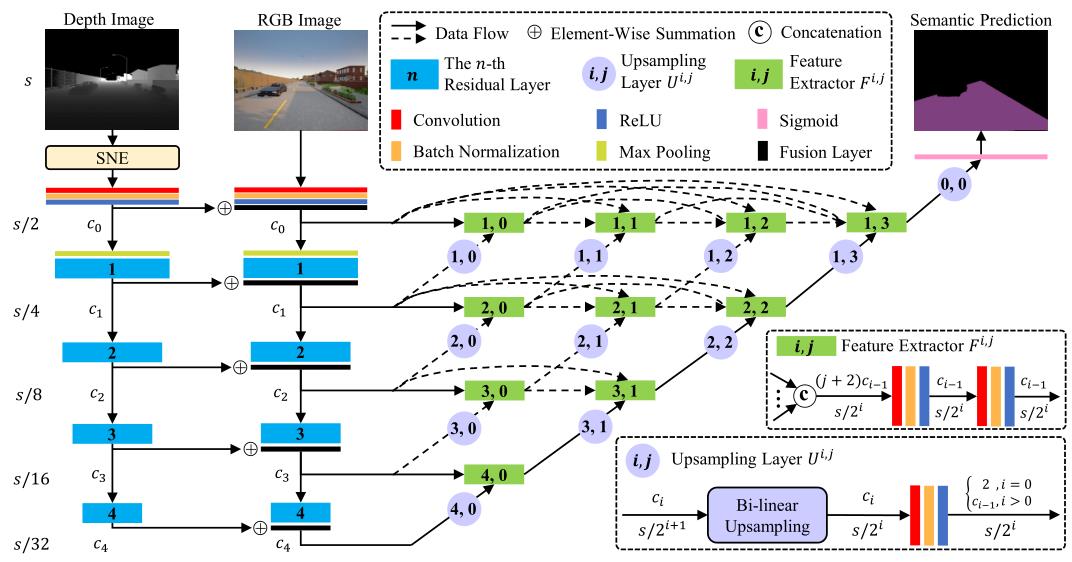
从上图可知,提取的 RGB 和表面法线特征图通过逐元素求和进行分层融合。然后通过DenseNet的跳跃连接在解码器中再次融合已经融合的特征图以恢复特征图的分辨率。在RoadSeg的最后,使用sigmoid层生成语义驾驶场景分割的概率图。
我们使用 ResNet 编码器的主干网络。具体来说,初始块由卷积层、批量归一化层和 ReLU 激活层组成。然后,依次使用最大池化层和四个残差层来逐渐降低分辨率并增加特征图通道的数量。
ResNet 有五种架构:ResNet-18、ResNet-34、ResNet-50、ResNet-101 和 ResNet-152。我们的 RoadSeg 遵循与 ResNet 相同的命名规则。特征图通道的数量 c n c_n cn 根据采用的 ResNet 架构不同而变化。具体来说,对于 ResNet-18 和 ResNet-34,c0–c4 分别为 64、64、128、256 和 512;对于 ResNet-50、ResNet-101 和 ResNet-152 分别为 64、256、512、1024 和 2048。
解码器由两种不同类型的模块组成:(a) 特征提取器 Fi,j (b) 上采样层 Ui,j。它们紧密连接以实现灵活的特征融合。特征提取器用于从融合特征图中提取特征,并确保特征图分辨率不变。上采样层用于提高分辨率并减少特征图通道。特征提取器和上采样层中的三个卷积层具有相同的内核大小 3×3、相同的步长 1 和相同的填充 1。
四、SNE-RoadSeg 实验效果
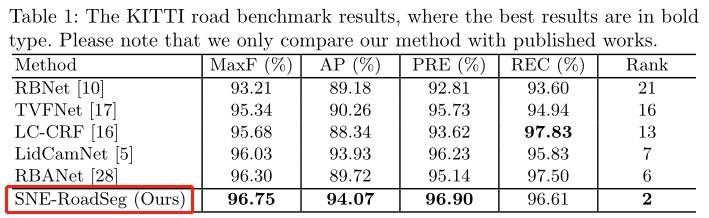
本文提出的方法与 KITTI 道路基准上发布的五个最先进的 CNN 进行了比较。实验结果示下图所示:

如下表所示,给出了定量的比较,表明本文提出的 SNE-RoadSeg 实现了最高的 MaxF、AP 和 PRE,而 LCCRF实现了最好的 REC。本文的自由空间检测方法在 KITTI 道路基准测试中排名第二。
五、总结
简而言之,本文的主要贡献包括:
- 提出了 SNE 模块,能够从深度/视差图像中以高精度和高效率推断表面法线信息;
- 提出了名为 RoadSeg 的数据融合 CNN 架构,能够融合 RGB 和表面法线信息以进行准确的自由空间检测,并且在检测可行驶道路区域时优于所有其他 CNN。
- 发布了一个用于语义驾驶场景分割的公开可用合成数据集。
以上是关于SNE-RoadSeg 解读结合表面法向量的路面分割网络(ECCV2020)的主要内容,如果未能解决你的问题,请参考以下文章