低调的采集,低调的学习,用自然资源部信息中心网站,来练习Python爬虫
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了低调的采集,低调的学习,用自然资源部信息中心网站,来练习Python爬虫相关的知识,希望对你有一定的参考价值。
本篇博客为《爬虫 120 例》第 31 例,坚持打卡学习走起,评论区留言,100% 回复。
目标站点分析
本次用于学习目的的站点为:http://landchina.mnr.gov.cn/land/crgg/gyyd/,域名中携带了 gov,所以咱就不能上多线程了,而且每次采集都要间隔几秒钟,控制一下节奏,并且数据下载到本地,秒删。采集案例随时可能消失,如果采集不到了,就采集不到吧。
对目标站点的分析如下:
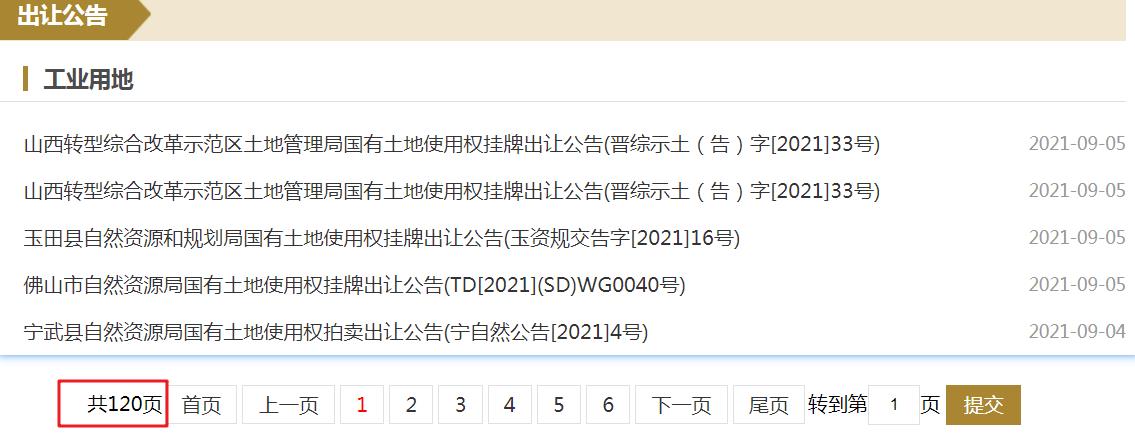
列表页地址分页规则
http://landchina.mnr.gov.cn/land/crgg/gyyd/index.htm
http://landchina.mnr.gov.cn/land/crgg/gyyd/index_1.htm
http://landchina.mnr.gov.cn/land/crgg/gyyd/index_2.htm
神奇的操作出现了,第一页没有后缀,然后第二页的后缀是从 index_1.html 开始。
这里最麻烦的不是列表页的逻辑,而是详情页的解析,恰好咱们可以用于联系 requests-html 库。
下图为其中一种详情页,详情页分为一个或者多个表格,表格基本内容如下所示。

所有本案例中难点就是解析这些格式不统一的数据。
代码编写时间
首先是列表页地址提取,本步骤直接采用 requests-html 库即可实现。
from requests_html import HTMLSession, HTML
import random
import time
import os
def get_detail() -> list:
# 待抓取的详情页地址
wait_scrapy_urls = []
# 声明一个 url 模板,用于批量生成待采集地址
url_format = "http://landchina.mnr.gov.cn/land/crgg/gyyd/index_{}.htm"
urls = ["http://landchina.mnr.gov.cn/land/crgg/gyyd/index.htm"]
base_url = "http://landchina.mnr.gov.cn/land/crgg/gyyd/"
# 测试只存储3页即可
for page in range(1, 3):
urls.append(url_format.format(page))
for url in urls:
try:
res = session.get(url, timeout=3)
res.html.encoding = "utf-8"
# print(res.html.html)
details = res.html.find("ul.gu-iconList>li>a")
for detail in details:
# http://landchina.mnr.gov.cn/land/crgg/gyyd/202109/t20210904_8081129.htm
wait_scrapy_urls.append(base_url + detail.attrs['href'][2:])
except Exception as e:
print("采集分页数据异常", e)
# 时间停留
time.sleep(random.randint(1, 3))
return wait_scrapy_urls
其中提取链接使用的是 html.find() 方法,拿到对应的 Element 对象之后,再调用 detail.attrs['href'][2:] 提取链接,由于得到的链接如下所示:
./202109/t20210904_8081129.htm
./202109/t20210904_8081129.htm
./202109/t20210904_8081129.htm
所以最终的链接需要进行一下拼接操作。
提取到链接之后,基于该链接获取一下详情页数据,为了便于后续提取,直接保存 HTML 源代码到本地。
def save(index: int, url: str) -> str:
try:
print("正在采集:", url)
res = session.get(url=url, timeout=3)
res.html.encoding = "utf-8"
with open(f"./htmls/{index}.html", "w+", encoding="utf-8") as f:
f.write(res.html.html)
except Exception as e:
print("采集详情页数据异常", e)
return save(index, url)
经过多次测试,存在部分数据缺失的情况,丢失的异常数据占比非常低,可以忽略或者针对性处理。
最后一步就是对保存到本地的 HTML 源码,进行数据解析,也就是本案例最重要的一个步骤,本次使用 requests-html 库的 xpath 方法进行提取。
一开始使用的代码如下:
# 提取数据
file_names = os.listdir("./htmls/")
for file in file_names:
with open(f"./htmls/{file}", "r", encoding="utf-8") as f:
html_content = f.read()
html_doc = HTML(html=html_content)
zongdi = html_doc.xpath('//td[contains(text(),"宗地编号:")]/following-sibling::td[1]/text()')
mianji = html_doc.xpath('//td[contains(text(),"宗地总面积:")]/following-sibling::td[1]/text()')
for z in mianji:
print(z.strip())
结果出现一个比较大的问题是,分批提取数据,最终由于每次得到列表的长度不一致,导致数据无法一一对应,故修改策略。
在修改策略前,先注意阅读一下代码,本文使用的 XPath 在之前的博客中并未说明。
单独查看 XPath 表达式如下所示:
//td[contains(text(),"宗地编号:")]/following-sibling::td[1]/text()
其中 td 后面的筛选项,增加了 contains 函数的用法,该函数的意思为包含,即验证 td 元素内部的文本是否包含 宗地编号: ,如果包含,则提取 following-sibling,即后续兄弟结点中的第一个 td(td[1]),最后在提取其中的文本内容。
后续提取策略基本一致,还需要了解上述代码中 res.html.xpath 的基本格式:
xpath(self, selector: str, *, clean: bool = False, first: bool = False, _encoding: str = None)
其中参数如下所示:
selector:xpath 选择器;clean:对找到的
还有在本案例中,并未使用 requests-html 库直接获取服务器源码进行解析,而是读取的本地文本,因此使用了 requests-html 的 HTML 类,将本地 HTML 代码进行序列化。
html_doc = HTML(html=html_content)
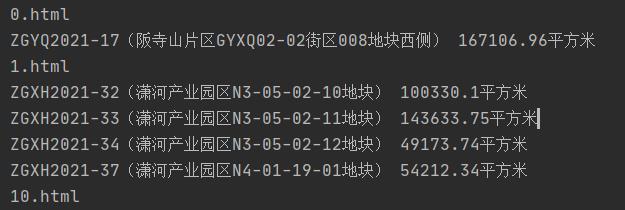
在上文提及的数据不对应的问题,后续的解决方案是,先获取到区域表格,也就是博客开篇第二张图中红色方框,和绿色方框部分内容,然后再对其进行解析。
修改解析代码如下,忽略汉语拼音命名的变量(尴尬~)
zongdi = html_doc.xpath('//td[contains(text(),"宗地编号:")]/../../../table')
print(file)
for z in zongdi:
card_id = z.xpath('.//td[contains(text(),"宗地编号:")]/following-sibling::td[1]/text()')[0].strip()
mianji = z.xpath('.//td[contains(text(),"宗地总面积:")]/following-sibling::td[1]/text()')[0].strip()
print(card_id, mianji)
第一个 XPath 表达式,使用了 .. 去访问父级结点,然后在追溯到父级 table,该用法需要学习并掌握。
收藏时间
代码仓库地址:https://codechina.csdn.net/hihell/python120,去给个关注或者 Star 吧。
有没有想要学习和咨询的 Python 问题,评论区留言吧,有问必答
今天是持续写作的第 214 / 365 天。
可以关注,点赞、评论、收藏。
更多精彩
以上是关于低调的采集,低调的学习,用自然资源部信息中心网站,来练习Python爬虫的主要内容,如果未能解决你的问题,请参考以下文章