听Alluxio小姐姐讲述:Alluxio云上K8S部署如何加速深度学习训练
Posted Alluxio Tianyu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了听Alluxio小姐姐讲述:Alluxio云上K8S部署如何加速深度学习训练相关的知识,希望对你有一定的参考价值。
在2021 Alluxio Day V 中,Alluxio核心研发工程师 邱璐,为我们带来[Alluxio云上K8S部署如何加速深度学习训练]的分享

邱璐 毕业于乔治华盛顿大学数据科学专业,有多年开源社区贡献经验,2018年加入Alluxio 团队,主要负责Alluxio与公有云场景的结合,分布式系统选举机制,日志管理,监控系统,机器学习场景下的数据供给研究开发。
·以下为邱璐在本次大会中的演讲实录·
 非常感谢大家来参加活动,今天我主要讲的主题是Alluxio云上的K8S部署如何加速深度学习训练。
非常感谢大家来参加活动,今天我主要讲的主题是Alluxio云上的K8S部署如何加速深度学习训练。

我们今天主要讲的是三部分内容,首先我会快速讲一下Alluxio API的定义以及应用场景,然后我们重点会放在Alluxio云上Kubernetes的部署问题,最后我们将花几分钟时间来展示一下Alluxio POSIX的研发进展。
Alluxio POSIX API定义及使用场景
首先是Alluxio POSIX的定义以及使用场景,相信这幅图大家都不是很陌生了,通过使用Alluxio用户可以去连接不同的远端数据源,可能是阿里云、腾讯云、或者HDFS cluster,然后通过使用Alluxio,我们可以把一部分的热数据缓存在本地,以提升训练性能。Alluxio POSIX API往前走了一步,它可以把Alluxio 挂载为一个本地的文件夹,一些应用比如说Pytorch,Tensorflow等,就可以像使用本地数据源一样去使用各种远端数据源,无需改变训练脚本。

比如说这边有个截图,我们如果看到这个截图可能会觉得说这个Alluxio文件夹可能就代表一个本地的文件夹,而它的大小也是受限于这个本地文件系统的大小,然而这个本地文件夹里面的各个子文件夹可能代表的是不同的远端数据,可能是HDFS,也可能是阿里云、腾讯云,而里面的这些文件夹的数据可能依然存在于你的远端数据源中,也有可能已经缓存到你的本地存储以提升训练性能。对于应用而言,你可以像使用本地文件夹一样,去使用这些远端的分布式数据。
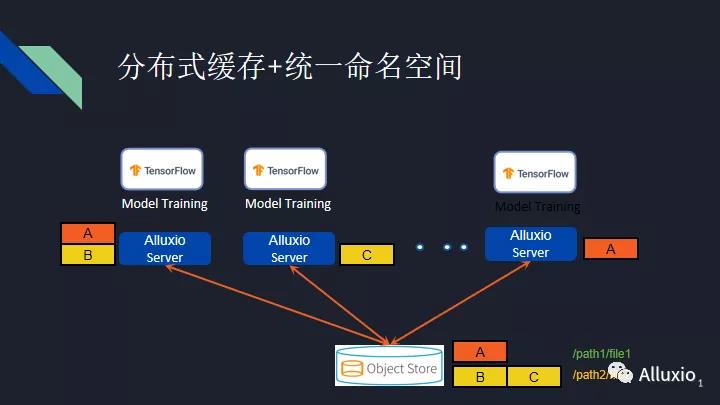
Alluxio的另外一个好处在于在我们传统的机器学习训练中,你需要把一份完整的数据拷贝到每一个台训练机子上。拷贝的过程是非常耗时的,拷贝完之后,在训练中,一旦一台机子的一个磁盘挂掉了,你可能要花时间去研究究竟哪个磁盘挂掉了,重新去拷贝数据,重跑训练。通过使用Alluxio,我们把你的全部数据分散到不同的机器上进行分布式缓存,你可以设置想要的备份数量,一旦一台机子挂掉了,这个数据可能依然存在于你隔壁的机子上,你就可以在隔壁拿到这份数据,而不需要在远端重新获取。即使你的集群上没有缓存这部分数据,我们依然可以去远端重新拿到这份数据。训练性能可能会受一定影响,但是训练本身可以照常进行, 无需重跑。
Alluxio 云上 Kubernetes 部署
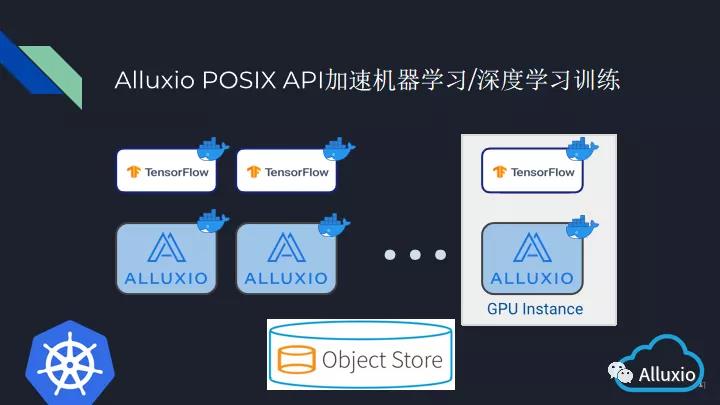
可能有些小伙伴会问为什么我们要讲如何在云上K8S进行Alluxio POSIX API的部署。这其实不是Alluxio的一个选择,而是我们的社区用户给我们的反馈。基本上我们所有的社区用户, 他们的机器学习、深度学习训练都是搭建在云上K8S环境中的,这可能来源于这个环境能让他们更方便的进行分布式机器学习训练,也可能他们会讲说我已经有这么一套环境了,我已经知道如何跑我的训练了,我考虑的就是如何把Alluxio加进来。这就导致了我们有这个需求,就是如何在云上k8s进行Alluxio POSIX API的部署问题。
首先你要有一个云上K8s集群,可以通过使用docker和Kubernetes来部署Alluxio集群。当我们部署好Alluxio集群之后,就可以考虑我们的数据了,是不是要把一部分数据先缓存进来,以提升你之后的一个训练效率?你也可以选择在进行训练时再去动态的获取并缓存这些热数据。当你已经确定了要使用多少数据进行缓存之后,你可能就要就要使用Kubeflowh或者Arena之类的一系列软件,一键部署你的分布式训练,而这些训练呢就可以像使用本地数据一样去使用不同的远端数据。我们的数据科学家们可以更加关注于我要设计一个怎样的模型,以及如何去更改这些模型来适用于我们的训练,而不需要过多的去关注我想要的数据源在哪里,如何把我的训练脚本连接到数据源或者说如何把数据拷贝到训练集群上。我们可以更加的关注于训练逻辑本身,所有关于数据的问题,就让Alluxio来解决。
我们将会今天将会讲到4种不同的部署方式,其实我们并不希望有这么多种的部署方式,我们当然希望说只有一种部署方式,我们的用户可以更方便地部署,我们也可以更方便地进行开发,我们只需要把这种方式做到尽善尽美就可以了。然而现实情况是我们不同的用户的确有不同的自己喜好的部署方式,而且在Kubernetes现在的开源社区中,也没有一种方式一统江湖,所以我们就不得不介绍这么多种部署方式。我们会列出它适用的场景,大家可以根据自己的实际使用情况和自己比较擅长的使用情况去进行选择。
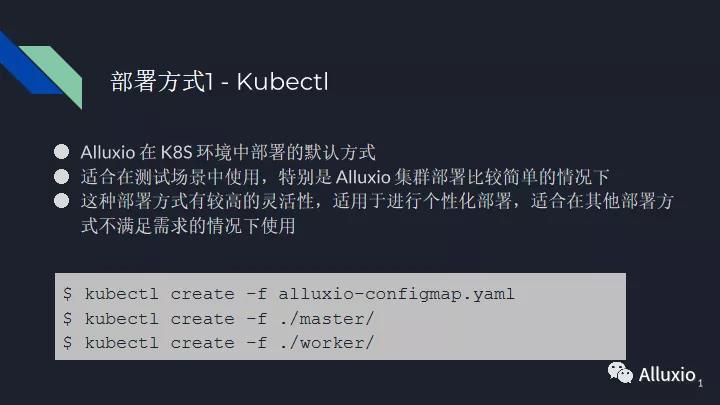
第一种部署方式是Kubectl——这种部署方式比较适合于测试场景,特别是在Alluxio集群比较简单的情况下进行使用,毕竟我们会有很多不同的脚本。如果我们的集群特别复杂的话,我们的脚本变得可能有几十个 yaml 文件,很长的文件,可能我们自己都不知道我们进行了什么样的一个配置。这种部署方式有较高的灵活性,特别适用于进行个性化部署,也特别适用于在其他三种部署方式不适用的情况下,你们可能有更深一步的需求的情况下,你们可以去使用Kubectl。
对于更多的普通用户,我们其实建议大家去使用Helm,这是Kubernetes的软件包管理器——在社区中比起Kubectl,其实大家也更愿意也更常用Helm。我们可以通过使用Alluxio提供的Helm Charts,其实就是一个模板,然后在这个模板的基础上,你可以提供你的个性化配置来一键部署Alluxio集群,而且通过使用这个通用模板,你可以在多个不同的环境中部署多个相似以及相或者相同的Alluxio集群。你不需要像第一种方式一样,建立一堆的yaml脚本,然后把这一堆的脚本不停的拷贝到每一个环境中,然后做一些些许的改变,很可能你会忘记到底做什么改变,因为它实在太复杂了。而通过Helm你可以非常清晰的知道这个集群跟上一个有什么样的不同,而且你只需要提供你那一部分想要改变的那些配置就可以了。
第三种部署方式是Alluxio CSI——我们发现我们的社区用户,特别是一些在生产环境中部署Alluxio的用户都十分喜爱这种方式。像微软、腾讯,他们都使用了Alluxio CSI来进行Alluxio API的部署。Alluxio CSI也叫做容器存储接口,也就是把Alluxio CSI暴露给容器应用,比如说Docker, Kubernetes来作为持久化存储的这种方式,我们可以个性化的定制我们所需要的存储系统功能,我们不需要把Alluxio放置在kubernetes 的包裹中,然后再慢慢等待Kubernetes版本发布。当我们有需求时,就可以改Alluxio CSI并把它嵌套进Kubernetes中。
 Alluxio CSI的一大优点是他支持挂载点级别的访问控制,我们可以对不同的挂载点,给不同的用户不同的挂载点的权限,而且你可以对不同的挂载点进行个性化配置,比如说有挂载点,我想要进行读优化,另一个挂载点我想进行写优化,这都是支持的。
Alluxio CSI的一大优点是他支持挂载点级别的访问控制,我们可以对不同的挂载点,给不同的用户不同的挂载点的权限,而且你可以对不同的挂载点进行个性化配置,比如说有挂载点,我想要进行读优化,另一个挂载点我想进行写优化,这都是支持的。

关于这部分的具体信息,后续我们来自微软的李镔洋同学会更具体的讲解他们是如何在微软中进行Alluxio CSI的部署实例(后面几期公众号会更新相关文章),我这边就不再进行重复了。
如果大家对Alluxio CSI感兴趣的话,这里有一些相关的文档以及我们的Github链接,然后特别感谢微软的李镔洋以及腾讯的毛宝龙对Alluxio CSI贡献,稍后呢微软的李镔洋和张虔熙也会带来他们关于Alluxio CSI的部署实例。
最后一种部署方式是叫Fluid,Fluid的概念其实挺复杂的,它是一个开源Kubernetes原生的分布式数据编排和加速引擎,它主要服务于云原生场景下的数据密集型应用,比如说大数据应用以及AI应用等等。你可以理解为Fluid就是把Alluxio嵌套在内部,它的特殊之处在于它为数据科学家提供了数据级层面的访问控制,而所有关于如何配置Alluxio,如何搭建Alluxio,又如何进行Alluxio的扩展问题,这些问题呢用户都无需考虑。用户只需要考虑的是我今天想要使用哪个数据集,我想要给这个数据集分配多大的缓存就可以了,所有背后的逻辑Fluid都会帮你去思考,帮你去想是否要把这部分数据缓存起来,然后帮你去想说Alluxio集群应该如何配置如何扩展,所以它特别适用于大家想要刚开始尝试Alluxio POSIX API,但是又对Alluxio不太了解,不知道该如何部署的情况下,我觉得直接使用Fluid进行初步尝试是非常好的。

这就是Fluid背后的概念,你可以看到整个服务也是非常复杂的一套体系,而Alluxio是其中嵌套的一个引擎,它为我们提供一个缓存功能,基于它之上的Fluid增加了很多数据集的管理,以及缓存磁盘管理之类的一些新的管理。
如果大家对Fluid特别感兴趣的话,欢迎大家去参考这些关于Fluid的一些相关文档,以及我们之前的一些关于Fluid的讲座,特别感谢来自阿里巴巴的车漾对于Fluid项目的贡献。
Alluxio POSIX 研发进展

我必须非常骄傲的说,Alluxio POSIX不是Alluxio自己独有的一个项目,它其实是一个完全社区驱动的项目,我们有来自南京大学、阿里巴巴、腾讯、微软以及其他公司的一系列优秀的开源贡献者,他们一起找到我们表示说我们有在机器学习中场景中使用Alluxio的需求,然后他们想办法让Alluxio能符合这个场景的的需求,并进一步把Alluxio这个解决方案做得更加尽善尽美,然后在各种的生产环境中进行使用。Alluxio POSIX已经在Microsoft,Analytics Aspects, Boss直聘的生产环境中进行使用。
在2.6.1的版本中,也就是最新刚刚发布的一个版本中,我们有一系列关于Alluxio JNI-Fuse的优化,我们把Fuse和Worker进程结合起来,进一步减少了本地读写 RPC来提高本地读写性能,我们优化了Alluxio CSI以便更便捷的在Kubernetes环境中部署Alluxio,我们添加了Fuse的相关指标以及Fuse进程的网络服务器,能方便大家更清晰的知道Alluxio负载是怎么样的以及Alluxio有没有性能瓶颈。我们添加了Alluxio自带的Fuse单机多线程读写测试程序,进一步模块化了JNI-Fuse包,包括Alluxio以及其他程序也可以更便捷的使用JNI-Fuse;我们进一步优化了Alluxio JNI-Fuse,不光想要Alluxio在常规的场景里,比如说元数据以及读写场景中进行使用,我们也希望Alluxio JNI-Fuse可以更加贴近于POSIX的标准,支持更多的Linux Command,fix更多的bug,更加正确。我们进一步优化Alluxio的分布式缓存以及原数据缓存。

我们还有一些正在进行的项目:我们正在优化远程gRPC的读写性能,希望进一步提高Alluxio解决方案的性能;我们添加了Alluxio自带的Fuse多机多线程读写性能的测试程序;我们支持动态的更新Alluxio集群配置,来更好的在Kubernetes环境中使用Alluxio,我们支持Libfuse 3以及正在优化Alluxio dockor image。我们每周有一个Alluxio POSIX的社区大会,在这个社区大会上大家会进行一些讨论,关于如何把JNI-Fuse做的更好,Alluxio POSIX API做的更加Solid,然后一起想办法把场景解决方案做得更好,欢迎大家加入来讨论如何把它变得更好, 然后提出解决方案,特别是我们有些开源用户在他们的生产实践中使用了Alluxio JNI-Fuse, 然后发现说好像我们这里有一些代码的贡献是可以贡献回我们社区的,他们也会提出他们想要做的一些贡献,我们一起去进行代码审阅和讨论,然后把这份代码可以让更多的人去进行使用。
今天的分享就到这里,谢谢大家~
预告:
【Alluxio云上K8S部署如何加速深度学习训练】后小姐姐们将继续手把手教你玩转Alluxio
小姐姐有话说:Alluxio 加速云上深度训练👭
将于本周六 9月11日
10:00-11:00am线上举行
欢迎大家持续关注公众号最新动态敬请期待!
了解更多精彩内容
以上是关于听Alluxio小姐姐讲述:Alluxio云上K8S部署如何加速深度学习训练的主要内容,如果未能解决你的问题,请参考以下文章