DeepMind 的新强化学习系统,是迈向通用人工智能的一步吗?
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DeepMind 的新强化学习系统,是迈向通用人工智能的一步吗?相关的知识,希望对你有一定的参考价值。


作者:Ben Dickson
来源:数据实战派
前言

尽管已经掌握围棋、星际争霸 2 和其他游戏,深度强化学习模型的主要挑战之一是,它们无法将其能力泛化到训练领域之外。这种限制使得将这些系统在现实世界中的应用变得非常困难,因为现实世界中的情况比训练模型的环境复杂得多且不可预测。
但是在最近的研究中, DeepMind 声称,为了解决上面的问题,他们已经迈出了第一步,训练一种能够在不需要人类交互数据的情况下玩许多不同游戏的智能体。他们的这个新项目包括一个具有真实动态的 3D 环境和可以学习解决各种挑战的深度强化学习智能体。
根据 DeepMind 说法,新系统是“朝着创建更通用智能体迈出的重要一步,具有在不断变化的环境中快速适应的灵活性。”(“数据实战派”后台回复“ DM ”获取论文链接)
该论文的研究结果表明,他们在将强化学习应用于复杂问题方面取得了一些令人印象深刻的进展。但他们也提醒,当前的系统距离实现人工智能领域几十年来一直梦寐以求的通用智能能力还有多远。
深度强化学习的脆弱性

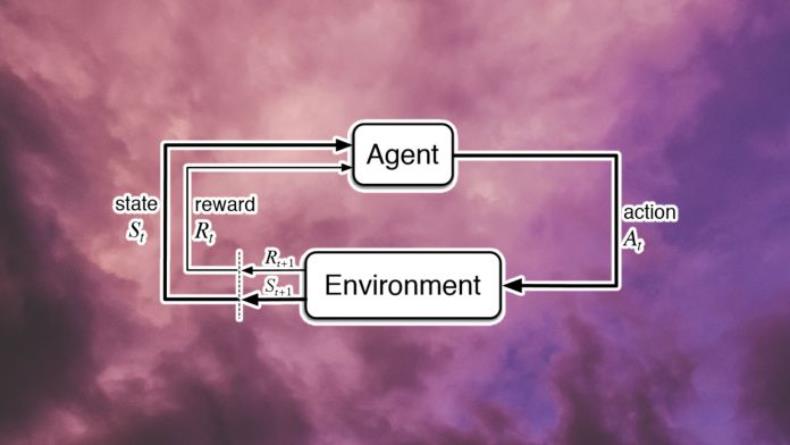
强化学习的主要优势在于,它通过采取行动和获得反馈来发展行为,类似于人类和动物通过与环境互动来学习的方式。一些科学家将强化学习描述为“第一个智能计算理论”。
强化学习和深度神经网络的结合,称为深度强化学习,是人工智能众多进展的核心,包括 DeepMind 著名的 AlphaGo 和 AlphaStar 模型。对于这两种模型,人工智能系统都能够在各自的比赛中击败人类世界冠军。
但强化学习系统也因其缺乏灵活性而屡遭批评。例如,强化学习模型能够以专家级水平玩《星际争霸 2 》,但却不能玩具有类似机制的游戏(例如,魔兽争霸 3 )。即使对原始游戏稍有改动,也会大大降低 AI 模型的性能。
DeepMind 写道:“这些智能体通常被限制在只能玩他们接受过训练的游戏——而游戏的实际情况可能会有所不同(例如布局、初始条件、对手),这会改变智能体在训练和测试之间保持环境不变的要求。偏离这一点可能会导致智能体灾难性的失败”,该论文提供了有关其开放式学习的全部细节。
另一方面,人类非常擅长跨领域转移知识。
XLand环境


DeepMind 新项目的目标,是创建“一个人工智能体并使其行为超越它所接受的训练。”
为此,该团队创建了 XLand ,这是一个可以生成由静态拓扑和可移动对象组成的 3D 环境的引擎。该游戏引擎模拟刚体物理学并允许玩家以各种方式使用对象(例如,创建斜坡、块路径等)。
XLand 是一个丰富的环境,用户可以在其中训练智能体执行几乎无限数量的任务。
XLand 的主要优势之一是能够使用程序化规则自动生成大量环境和挑战来训练 AI 智能体。这解决了机器学习系统的主要挑战之一,即系统通常需要大量手动策划的训练数据
该文章称,研究人员“在 XLand 中创建了数十亿个任务,跨越不同的游戏、世界和玩家。”这些游戏包括非常简单的目标,例如在更复杂的设置中寻找对象,其中 AI 智能体会权衡不同奖励的收益。有些游戏包括涉及多个智能体的合作或竞争元素。
深度强化学习

DeepMind 使用深度强化学习和一些高明的技巧来创建可以在 XLand 环境中茁壮成长的 AI 智能体。
每个智能体的强化学习模型接收认知世界的第一人称视角、智能体的物理状态(例如,它是否持有对象)以及它当前目标。每个智能体微调其策略神经网络的参数,以最大化其对当前任务的奖励。神经网络架构包含一个注意力机制,以确保智能体能够平衡完成主要目标所需的子目标的优化。
一旦智能体掌握了当前的挑战,计算任务生成器就会为智能体创建一个新的挑战。每个新任务都是根据智能体的训练历史生成的,并以某种方式帮助智能体在各种挑战中分配其技能。
DeepMind 还利用其庞大的计算资源(其隶属的 Alphabet 集团提供)来并行训练大量智能体,并在不同智能体之间传输学习参数,以提高强化学习系统的总体能力。
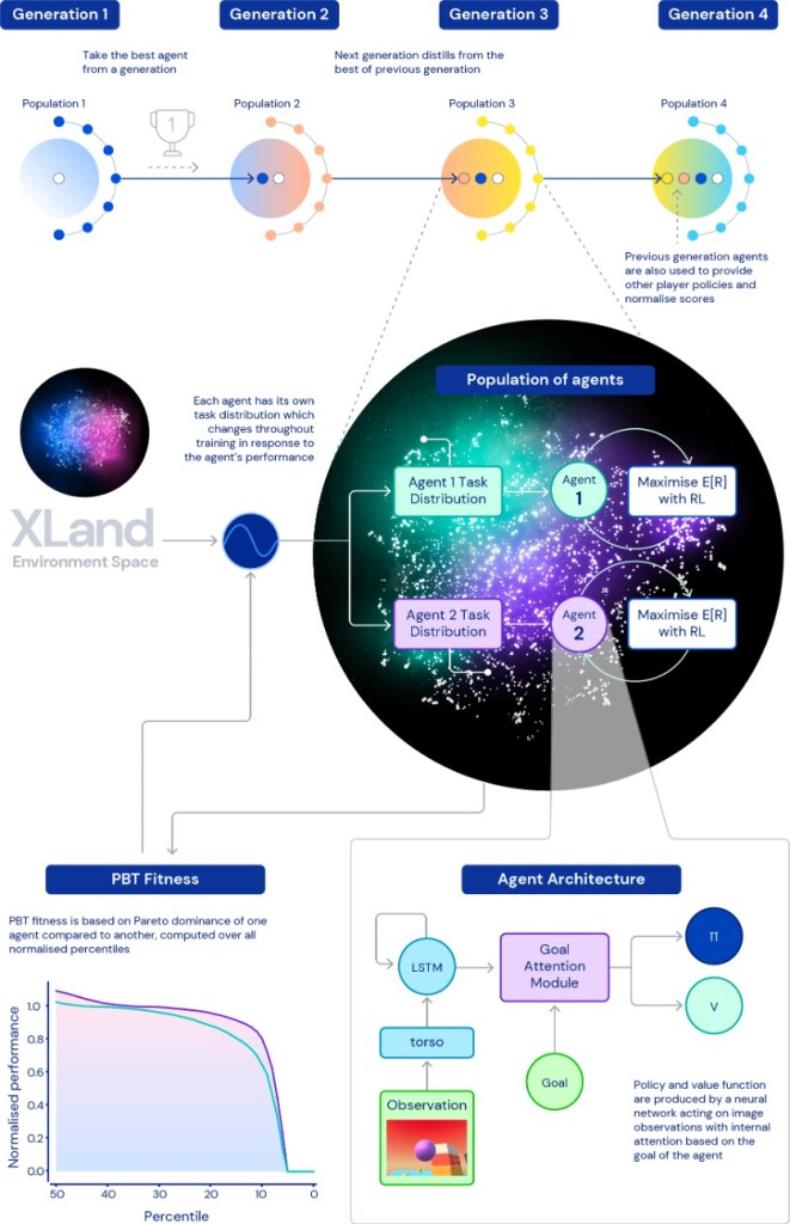
DeepMind 使用多步和基于群体的机制来训练许多强化学习智能体
强化学习智能体的性能是根据它们完成未经训练的各种任务的一般能力来评估的。一些测试任务包括大家熟知的挑战,例如“夺旗”和“捉迷藏”。
DeepMind 表示,每个智能体在 XLand 的 4,000 个独特世界中玩了大约 700,000 个独特的游戏,并在 340 万个独特任务中经历了 2,000 亿个训练步骤(研究人员在论文中写道, 1 亿个步骤相当于大约 30 分钟的训练) .
研究人员称:“目前,我们的智能体已经能够参与每一个程序生成的评估任务,除了少数即使是人类也无法完成的任务。而且我们所看到的结果清楚地展示了整个任务空间中普遍的零样本行为。”
零样本机器学习模型可以解决训练数据集中不存在的问题。在 XLand 等复杂空间中,零样本学习可能意味着智能体已经获得了有关其环境的基本知识,而不是记住特定任务和环境中的图像帧序列。
当研究人员试图为新任务进行调整时,强化学习智能体进一步表现出广义学习的迹象。根据他们的发现,对新任务进行 30 分钟的微调足以在使用新方法训练的强化学习智能体中产生令人印象深刻的改进。相比之下,在相同时间内从头开始训练的智能体在大多数任务上的性能接近于零。
高级行为

DeepMind 表示,强化学习智能体表现出“启发式行为”,例如工具使用、团队合作和多步计划。如果得到证实,这可能是一个重要的里程碑。深度学习系统经常因为学习统计相关性而不是因果关系而受到批评。如果神经网络能够开发出高级概念,例如使用物体来创建斜坡或造成遮挡,它可能会对机器人和自动驾驶汽车等领域产生重大影响,而目前在这些领域中深度学习正在苦苦挣扎。
但这些都是大胆的假设,DeepMind 的研究人员对根据他们的发现得出结论持谨慎态度。
他们在博文中写道:“鉴于环境的性质,很难准确地指出它们是有意为之的,我们看到的行为经常像是偶然的,但我们仍然看到它们不断发生。”
但是他们相信,他们研究的强化学习智能体能够“意识到它们自身的基础和时间的流逝,并且了解游戏的高层结构。”
这种基本的自学技能是人工智能领域备受追捧的另一个目标。
智力理论


DeepMind 的一些顶尖科学家最近发表了一篇论文,他们假设单一的奖励和强化学习足以最终实现通用人工智能( AGI )。科学家们认为,具有正确激励的智能体可以开发各种能力,例如感知和自然语言理解。
尽管 DeepMind 的新方法仍然需对强化学习智能体进行多项工程奖励的训练,但这与他们通过强化学习实现AGI的总体观点是一致的。
Pathmind 的首席执行官 Chris Nicholson 说:“ DeepMind 在这篇论文中表明,单个RL智能体可以发展其理解能力以实现多个目标,而不仅仅是一个目标” “它在完成一件事时学到的技能可以推广到其他目标。这与人类智能的应用方式非常相似。例如,我们学习抓取和操纵物体,这是实现从敲锤子到铺床等目标的基础。”
Nicholson 还认为,该论文发现的其他方面暗示了一般智力的进步,他说:“家长们会认识到,开放式探索正是他们的孩子学会在世界中成长的方式。他们从柜子里拿出一些东西,然后把它放回去,他们创造了自己的小目标(这对成年人来说可能毫无意义)然后他们掌握了这些目标,DeepMind 正在以编程方式为其智能体在这个世界上设定目标,而这些智能体正在学习如何一一掌握它们。”
Nicholson 认为,强化学习智能体也显示出在他们自己的虚拟世界中开发其自身智慧的迹象,就像人类一样。“这又一次表明,人们学习移动和操作的丰富和可塑的环境有利于一般智能的出现,智能的生物和物理类比可以指导人工智能的进一步工作”
南加州大学计算机科学副教授 Sathyanaraya Raghavachary 对 DeepMind 论文中的主张持怀疑态度,尤其是关于本体感知、时间意识以及对目标和环境的高级理解的结论。
Raghavachary 表示:“即使是人类也没有完全了解我们自身,更不用说那些 VR 智能体了。对自身的感知需要一个集成的大脑,它是为适当的自身意识和空间情境感知而共同设计的。对时间流逝的感知也是如此,也需要大脑具有对过去的记忆,以及与过去相关的时间感。论文作者的意思可能是智能体能够跟踪由它们的行为导致的环境渐进式变化(例如,由于移动紫色金字塔),底层物理模拟器将生成的状态变化。”
Raghavachary 还指出,如果智能体能够理解任务的高层结构,它们就不需要 2000 亿步的模拟训练来达到最佳结果。
Raghavachary 称:“文章作者在结论中指出,底层架构缺乏能够实现这三件事(自身意识、时间流逝、理解高级任务结构)所需的东西。总体而言, XLand 只是‘大同小异’。”
模拟与现实世界的差距

简而言之,这篇论文证明,如果你能够创建一个足够复杂的环境,设计正确的强化学习架构,并让你的模型获得足够的经验(并且有很多钱可以花在计算资源上),你将能够泛化到同一环境中的各种任务。这基本上就是自然进化赋予人类和动物智能的方式。
事实上, DeepMind 已经对 AlphaZero 做了类似的事情, AlphaZero 是一种强化学习模型,能够掌握多个两人回合制游戏。XLand 实验通过添加零样本学习元素将相同的概念扩展到更高的水平。
虽然来自 XLand 训练的智能体的经验最终会转移到现实世界的应用中,例如机器人和自动驾驶汽车,但这不会是一个突破。因为这仍然需要做出妥协(例如创建人为限制以降低现实世界的复杂性)或创建人为增强功能(例如将先验知识或额外传感器注入机器学习模型)。
DeepMind 的强化学习智能体可能已经成为虚拟 XLand 的主人,但是他们的模拟世界甚至连真实世界一小部分的复杂程度都没有。在很长一段时间内,这种差距仍将是一个挑战。
Reference:
https://bdtechtalks.com/2021/08/02/deepmind-xland-deep-reinforcement-learning/

 9月11日,面基技术大佬,相约腾讯北京总部,立即扫码报名
9月11日,面基技术大佬,相约腾讯北京总部,立即扫码报名
往
期
回
顾
资讯
技术
转载
资讯

分享

点收藏

点点赞

点在看
以上是关于DeepMind 的新强化学习系统,是迈向通用人工智能的一步吗?的主要内容,如果未能解决你的问题,请参考以下文章
收藏 | DeepMind&UCL新课《深度强化学习》2021版上线
炸场!通用人工智能最新突破:一个模型一套权重通吃600+视觉文本和决策任务,DeepMind两年研究一朝公开...
综合LSTMtransformer优势,DeepMind强化学习智能体提高数据效率
Win10 安装 PySC2 环境 -- DeepMind联合战网开发的《星际争霸 II》强化学习环境