再探epoll
Posted 看,未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了再探epoll相关的知识,希望对你有一定的参考价值。

文章目录
以前写的:
温故Linux后端编程(六):深入了解epoll模型
这里主要是对上一篇里的不足进行补齐,之后将两篇合一篇。
Q1:为什么select最大只允许1024?
以前从没想过select和poll,一出来关注的就是epoll,后来明白了,对于select,也是有很多细节在里面的。源码之前,了无秘密!!!
#define FD_SETSIZE 1024
#define NFDBITS (8 * sizeof(unsigned long))
#define __FDSET_LONGS (FD_SETSIZE/NFDBITS)
typedef struct {
unsigned long fds_bits[__FDSET_LONGS];
} fd_set;
Q2:select一定只能监听1024?
呐:
#define FD_SETSIZE 1024
#define NFDBITS (8 * sizeof(unsigned long))
#define __FDSET_LONGS (FD_SETSIZE/NFDBITS)
typedef struct {
unsigned long fds_bits[__FDSET_LONGS];
} fd_set;
改个宏,编译一下内核,如果会编的话。
select、epoll原理图
(图片来源:https://blog.csdn.net/nanxiaotao/article/details/90612404):
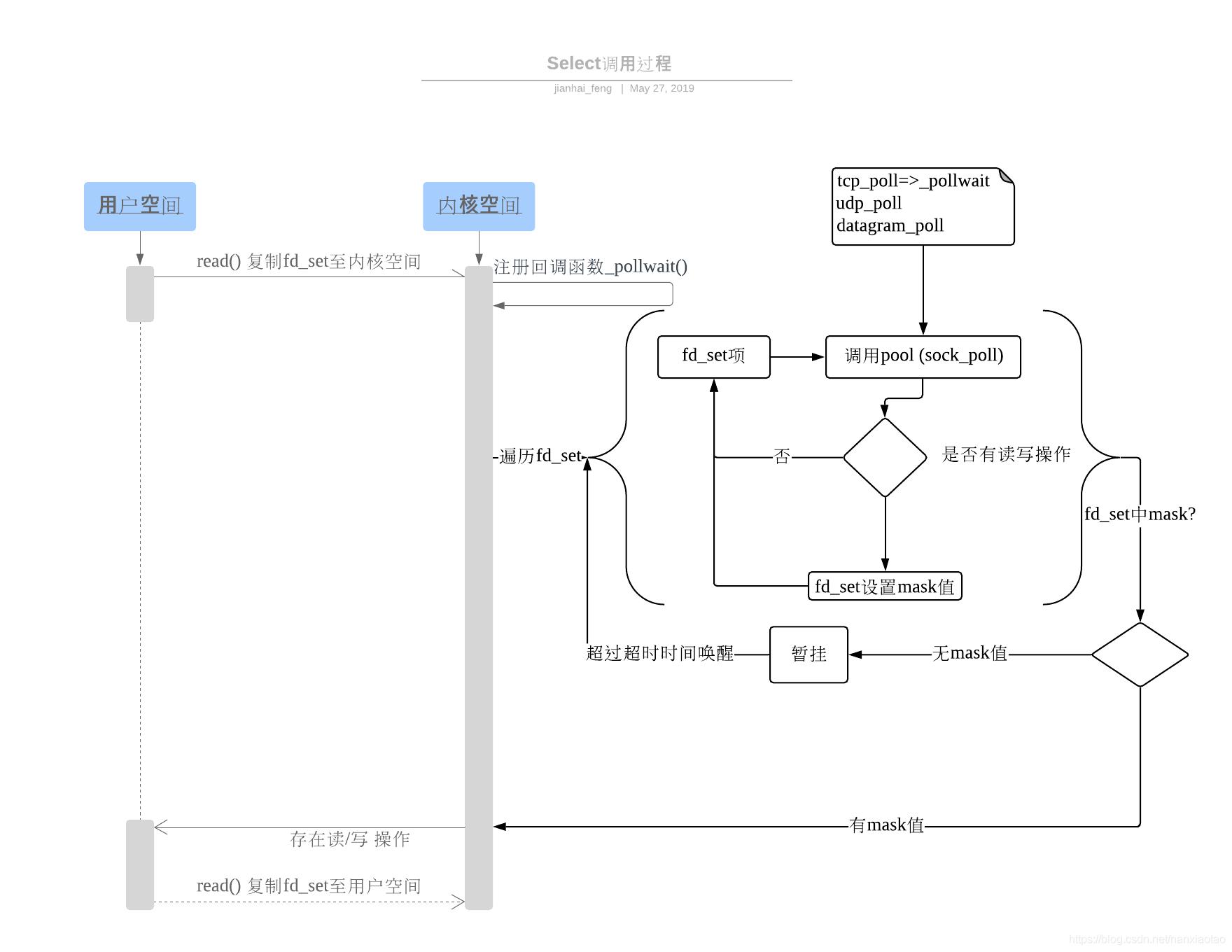
缺点:
(1)单进程可以打开fd有限制;
(2)对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低;
(3)用户空间和内核空间的复制非常消耗资源;
poll与select不同的地方:采用链表的方式替换原有fd_set数据结构,而使其没有连接数的限制。
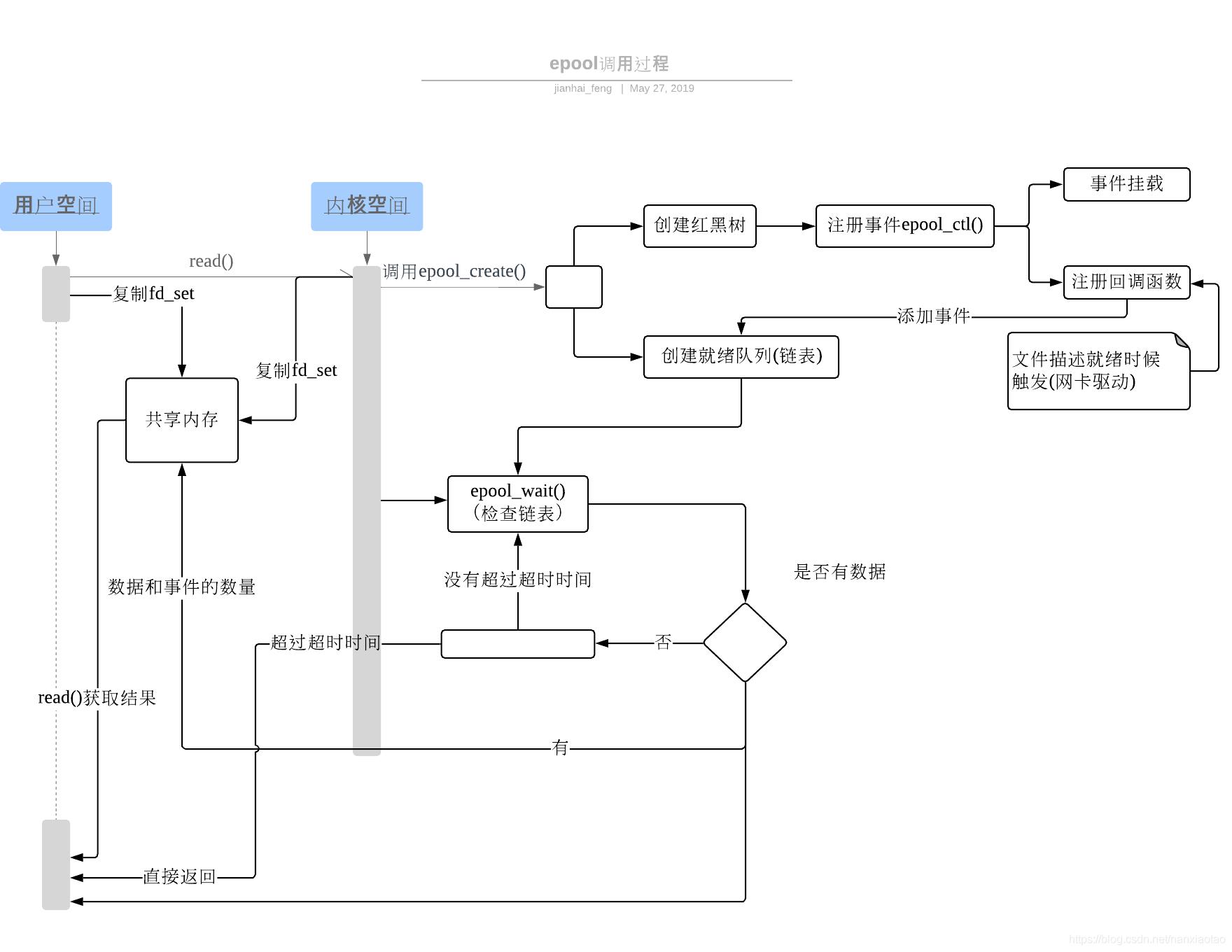
(一图胜千言)
-
epoll支持的最大链接数是进程最大可打开的文件的数目。
-
使用mmap加速内核与用户空间的传递。
Q3:epoll一定优于select吗?什么时候不是?
尽管如此,epoll 的性能并不必然比 select 高,对于 fd 数量较少并且 fd IO 都非常繁忙的情况 select 在性能上反而有优势。
本系列到后面手抄muduo库的时候我们就可以欣赏到大神是如何优雅的使用poll的。
Q4:听说把 epoll 和mmap扯上关系的都是骗子?
呃呃呃,其实源码翻一番也没看到mmap嘛,找不到源码的话这里:https://download.csdn.net/download/xumin330774233/10396875
其实我一开始也挺纳闷儿的,这是有多少个fd啊,要映射?
epoll的工作流程?
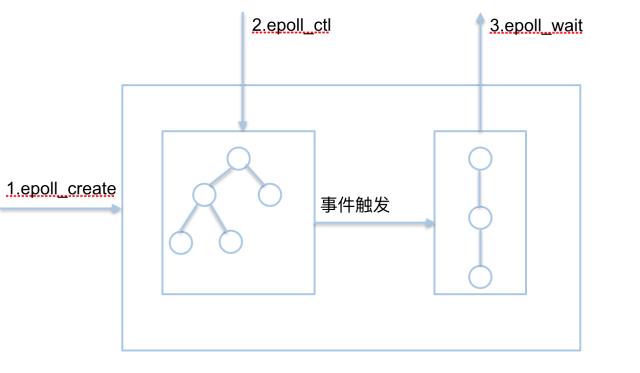
epol_create
在epoll文件系统建立了个file节点,并开辟epoll自己的内核高速cache区,建立红黑树,建立一个双向链表,用于存储准备就绪的事件。
epoll_create传入一个size参数,size参数只要>0即可,没有任何意义。epoll_create调用函数sys_epoll_create1实现eventpoll的初始化。sys_epoll_create1通过ep_alloc生成一个eventpoll对象,并初始化eventpoll的三个等待队列,wait,poll_wait以及rdlist (ready的fd list)。同时还会初始化被监视fs的rbtree 根节点。
1、首先创建一个struct eventpoll对象;
2、然后分配一个未使用的文件描述符;
3、然后创建一个struct file对象,将file中的struct file_operations *f_op设置为全局变量eventpoll_fops,将void *private指向刚创建的eventpoll对象ep;
4、然后设置eventpoll中的file指针;
5、最后将文件描述符添加到当前进程的文件描述符表中,并返回给用户
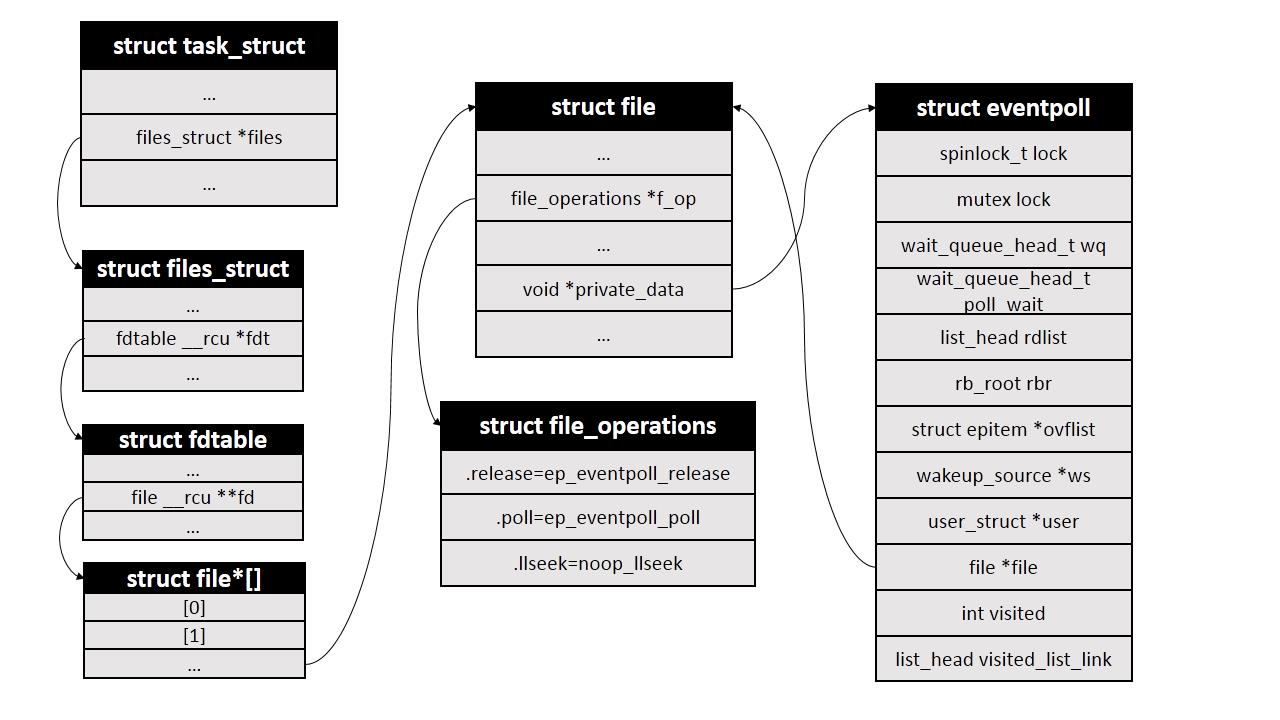
Q5:epoll_create返回的fd是什么?
这个模块在内核初始化时(操作系统启动)注册了一个新的文件系统,叫"eventpollfs"(在eventpoll_fs_type结构里),然后挂载此文件系统。另外还创建两个内核cache(在内核编程中,如果需要频繁分配小块内存,应该创建kmem_cahe来做“内存池”),分别用于存放struct epitem和eppoll_entry。这个内核高速cache区,就是建立连续的物理内存页,就是物理上分配好你想要的size的内存对象,每次使用时都是使用空闲的已分配好的内存。
现在想想epoll_create为什么会返回一个新的fd?
因为它就是在这个叫做"eventpollfs"的文件系统里创建了一个新文件!返回的就是这个文件的fd索引。完美地遵行了Linux一切皆文件的特色。
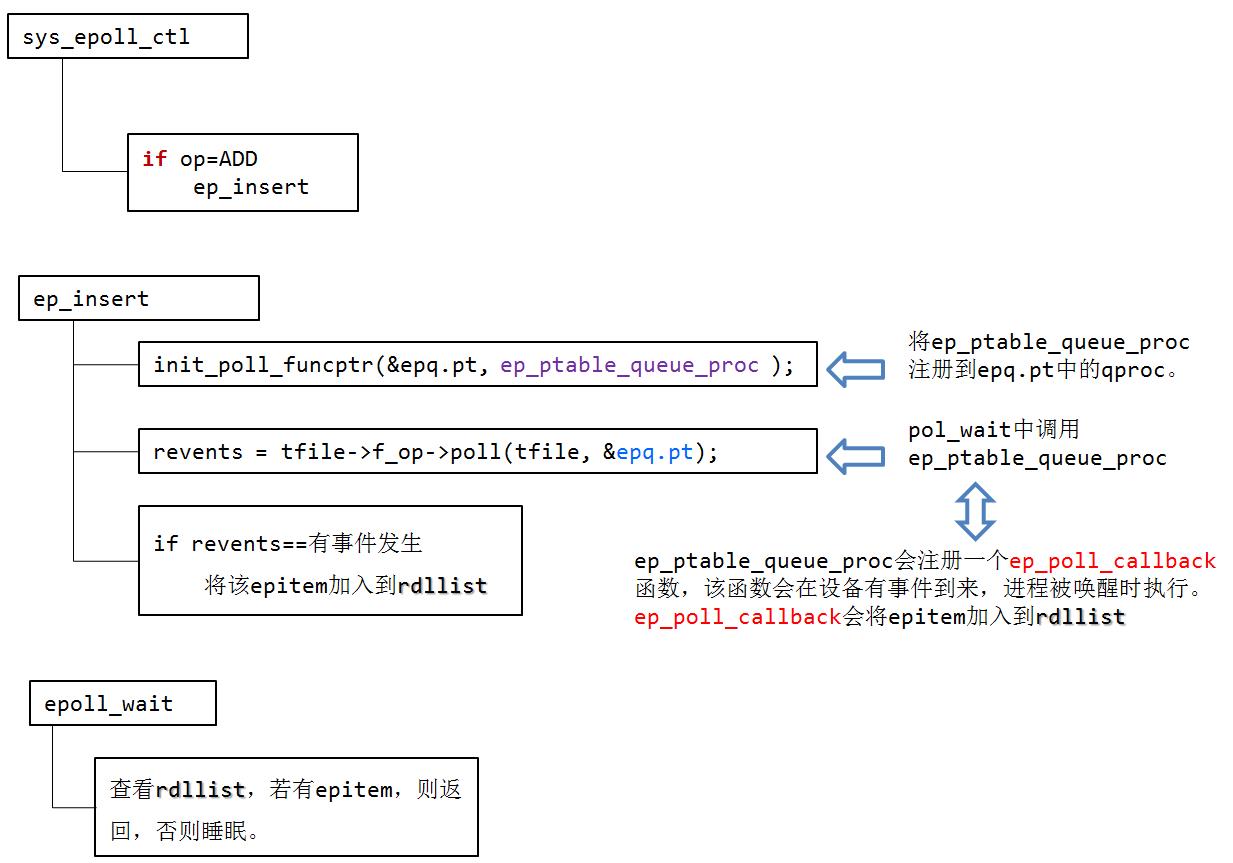
epoll_ctl
1、epoll_ctl()首先判断op是不是删除操作,如果不是则将event参数从用户空间拷贝到内核中。
2、接下来判断用户是否设置了EPOLLEXCLUSIVE标志,这个标志是4.5版本内核才有的,主要是为了解决同一个文件描述符同时被添加到多个epoll实例中造成的“惊群”问题,详细描述可以看这里。 这个标志的设置有一些限制条件,比如只能是在EPOLL_CTL_ADD操作中设置,而且对应的文件描述符本身不能是一个epoll实例,下面代码就是对这些限制的检查。
3、接下来从传入的文件描述符开始,一步步获得struct file对象,再从struct file中的private_data字段获得struct eventpoll对象。(那这个头那个头的都在这里面了)
4、如果要添加的文件描述符本身也代表一个epoll实例,那么有可能会造成死循环,内核对此情况做了检查,如果存在死循环则返回错误。
5、接下来会从epoll实例的红黑树里寻找和被监控文件对应的epollitem对象,如果不存在,也就是之前没有添加过该文件,返回的会是NULL。
6、ep_find()函数本质是一个红黑树查找过程,红黑树查找和插入使用的比较函数是ep_cmp_ffd(),先比较struct file对象的地址大小,相同的话再比较文件描述符大小。struct file对象地址相同的一种情况是通过dup()系统调用将不同的文件描述符指向同一个struct file对象。
7、接下来会根据操作符op的不同做不同的处理,这里我们只看op等于EPOLL_CTL_ADD时的添加操作。首先会判断上一步操作中返回的epollitem对象地址是否为NULL,不是NULL说明该文件已经添加过了,返回错误,否则调用ep_insert()函数进行真正的添加操作。在添加文件之前内核会自动为该文件增加POLLERR和POLLHUP事件。
8、ep_insert()函数中,首先判断epoll实例中监视的文件数量是否已超过限制,没问题则为待添加的文件创建一个epollitem对象。
9、接下来是比较重要的操作:将epollitem对象添加到被监视文件的等待队列上去。等待队列实际上就是一个回调函数链表,定义在/include/linux/wait.h文件中。因为不同文件系统的实现不同,无法直接通过struct file对象获取等待队列,因此这里通过struct file的poll操作,以回调的方式返回对象的等待队列,这里设置的回调函数是ep_ptable_queue_proc。
10、结构体ep_queue的作用是能够在poll的回调函数中取得对应的epollitem对象,这种做法在Linux内核里非常常见。
11、在回调函数ep_ptable_queue_proc中,内核会创建一个struct eppoll_entry对象,然后将等待队列中的回调函数设置为ep_poll_callback()。也就是说,当被监控文件有事件到来时,比如socker收到数据时,ep_poll_callback()会被回调。
12、ep_item_poll()调用完成之后,会将epitem中的fllink字段添加到struct file中的f_ep_links链表中,这样就可以通过struct file找到所有对应的struct epollitem对象。
13、然后就是将epollitem插入到红黑树中。
14、最后再更新下状态就返回了,插入操作也就完成了。
(在这个实现时,将用户空间epoll_event拷贝到内核中,后续可以将其转化为epitem作为节点存入红黑树中,从eventpoll的红黑树中查找fd所对应的epitem实例(二分搜索),根据传入的op参数行为进行switch判断,对红黑树进行不同的操作。对于ep_insert,首先设置了对应的回调函数,然后调用被监控文件的poll方法(每个支持poll的设备驱动程序都要调用),其实就是在poll里调用了回调函数,这个回调函数实际上不是真正的回调函数,真正的回调函数(ep_poll_callback)在该函数内调用,这个回调函数只是创建了struct eppoll_entry,将真正回调函数和epitem关联起来,之后将其加入设备等待队列。当设备就绪,唤醒等待队列上的等待者,调用对应的真正的回调函数,这个回调函数实际上就是将红黑树上收到event的epitem插入到它的就绪队列中并唤醒调用epoll_wait进程。在ep_insert中还将epitem插入到eventpoll中的红黑树上,然后还会去判断当前插入的event是否是刚好发生,如果是直接将其加入就绪队列,然后唤醒epoll_wait。)
epoll_wait
观察就绪列表里面有没有数据,并进行提取和清空就绪列表,非常高效。
ep_poll_callback函数主要的功能是将被监视文件的等待事件就绪时,将文件对应的epitem实例添加到就绪队列中,当用户调用epoll_wait()时,内核会将就绪队列中的事件报告给用户。
在epoll_wait主要是调用了ep_poll,在ep_poll里直接判断就绪链表有无数据,有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。当有数据时,还需要将内核就绪事件拷贝到传入参数的events中的用户空间,就绪链表中的数据一旦拷贝就没有了,所以这里要区分LT和ET,如果是LT有可能会将后续的重新放入就绪链表。
ps:我们在调用ep_send_events_proc()将就绪队列中的事件拷贝给用户的期间,新就绪的events被挂载到eventpoll.ovflist所以我们需要遍历eventpoll.ovflist将所有已就绪的epitem 重新挂载到就绪队列中,等待下一次epoll_wait()进行交付…
Q6:LT和ET实现的区别?
由epoll_wait进行实现,如果是LT模式,它发现soket上还有未处理的事件,则在清理就绪列表后,重新把句柄放回刚刚清空的就绪列表。
、
红黑树中每个成员由描述符值和所要监控的文件描述符指向的文件表项的引用等组成。
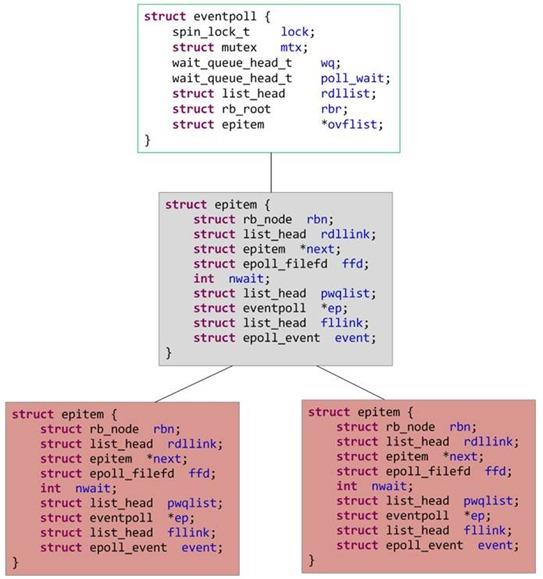
关键数据结构
// epoll的核心实现,对应于一个epoll描述符
struct eventpoll {
spinlock_t lock;
struct mutex mtx;
wait_queue_head_t wq; // sys_epoll_wait() 等待在这里
// f_op->poll() 使用的, 被其他事件通知机制利用的wait_address
wait_queue_head_t poll_wait;
//已就绪的需要检查的epitem 列表
struct list_head rdllist;
//保存所有加入到当前epoll的文件对应的epitem
struct rb_root rbr;
// 当正在向用户空间复制数据时, 产生的可用文件
struct epitem *ovflist;
/* The user that created the eventpoll descriptor */
struct user_struct *user;
struct file *file;
//优化循环检查,避免循环检查中重复的遍历
int visited;
struct list_head visited_list_link;
}
// 对应于一个加入到epoll的文件
struct epitem {
// 挂载到eventpoll 的红黑树节点
struct rb_node rbn;
// 挂载到eventpoll.rdllist 的节点
struct list_head rdllink;
// 连接到ovflist 的指针
struct epitem *next;
/* 文件描述符信息fd + file, 红黑树的key */
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
int nwait;
// 当前文件的等待队列(eppoll_entry)列表
// 同一个文件上可能会监视多种事件,
// 这些事件可能属于不同的wait_queue中
// (取决于对应文件类型的实现),
// 所以需要使用链表
struct list_head pwqlist;
// 当前epitem 的所有者
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct list_head fllink;
/* epoll_ctl 传入的用户数据 */
struct epoll_event event;
};
// 与一个文件上的一个wait_queue_head 相关联,因为同一文件可能有多个等待的事件,
//这些事件可能使用不同的等待队列
struct eppoll_entry {
// List struct epitem.pwqlist
struct list_head llink;
// 所有者
struct epitem *base;
// 添加到wait_queue 中的节点
wait_queue_t wait;
// 文件wait_queue 头
wait_queue_head_t *whead;
};
Q7:红黑树在epoll中的作用
其实我的本意是:为什么不直接返回 就绪fd列表,要返回结构体列表?不过现在既然在讲红黑树,那就先讲红黑树。
查找。接下来会从epoll实例的红黑树里寻找和被监控文件对应的epollitem对象,如果不存在,也就是之前没有添加过该文件,返回的会是NULL。
哈希表. 空间因素,可伸缩性.
(1)频繁增删. 哈希表需要预估空间大小, 这个场景下无法做到.
间接影响响应时间,假如要resize,原来的数据还得移动.即使用了一致性哈希算法,
也难以满足非阻塞的timeout时间限制.(时间不稳定)
(2) 百万级连接,哈希表有镂空的空间,太浪费内存.
跳表. 慢于红黑树. 空间也高.
红黑树. 经验判断,内核的其他地方如防火墙也使用红黑树,实践上看性能最优.
AVL树.平衡二叉树能够保证在最坏的情况下也能达到lgN,要实现这一目标,我们就要保证在插入完成后始终保持平衡状态。在一棵具有N个节点的树中,我们希望该树的高度能够维持在lgN左右,这样我们就能保证只需要lgN次比较操作就可以查找到想要的值。不幸的是,每次插入元素之后维持树的平衡状态太昂贵。所以就出现一些新的数据结构来保证在最坏的情况下插入和查找效率都能保证在对数的时间复杂度内完成。
Q8:为什么在ET模式下要设置非阻塞
如果多个连接同时到达,ET模式下就只会通知一次,为了处理剩余的连接数,必须要时刻accpet 句柄,直到出现errno为EAGAIN, 出于这样的目的的话,socket也要设置为非阻塞。
Q9:文件描述符是以什么方式挂载在红黑树的节点中?是int吗?
/* 文件描述符信息fd + file, 红黑树的key */
struct epoll_filefd ffd;
Q10:epoll惊群了解多少?
和虚假唤醒有点像。
考虑如下场景:
主进程创建socket, bind, listen之后,fork出多个子进程,每个子进程都开始循环处理(accept)这个socket。每个进程都阻塞在accpet上,当一个新的连接到来时,所有的进程都会被唤醒,但其中只有一个进程会accept成功,其余皆失败,重新休眠。这就是accept惊群。
那么这个问题真的存在吗?
事实上,历史上,Linux 的 accpet 确实存在惊群问题,但现在的内核都解决该问题了。即,当多个进程/线程都阻塞在对同一个 socket 的 accept 调用上时,当有一个新的连接到来,内核只会唤醒一个进程,其他进程保持休眠,压根就不会被唤醒。
如上所述,accept 已经不存在惊群问题,但 epoll 上还是存在惊群问题。即,如果多个进程/线程阻塞在监听同一个 listening socket fd 的 epoll_wait 上,当有一个新的连接到来时,所有的进程都会被唤醒。
accept 确实应该只能被一个进程调用成功,内核很清楚这一点。但 epoll 不一样,他监听的文件描述符,除了可能后续被 accept 调用外,还有可能是其他网络 IO 事件的,而其他 IO 事件是否只能由一个进程处理,是不一定的,内核不能保证这一点,这是一个由用户决定的事情,例如可能一个文件会由多个进程来读写。所以,对 epoll 的惊群,内核则不予处理。
更多了解可以翻到文章上面有链接。
以上是关于再探epoll的主要内容,如果未能解决你的问题,请参考以下文章