为啥要用分库分表方案?如何平滑升级?看这篇!
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为啥要用分库分表方案?如何平滑升级?看这篇!相关的知识,希望对你有一定的参考价值。
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识

来源:https://juejin.im/post/6844903992909103117
数据库瓶颈
不管是IO瓶颈还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载的活跃连接数的阈值。在业务service来看,
就是可用数据库连接少甚至无连接可用,接下来就可以想象了(并发量、吞吐量、崩溃)。
IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询会产生大量的IO,降低查询速度->分库和垂直分表
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 ->分库
CPU瓶颈
第一种:SQl问题:如SQL中包含join,group by, order by,非索引字段条件查询等,增加CPU运算的操作->SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQl效率低,增加CPU运算的操作。->水平分表。
分库分表
水平分库

1、概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
2、结果:
每个库的结构都一样
每个库中的数据不一样,没有交集
所有库的数据并集是全量数据
3、场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库的情况下。
4、分析:库多了,io和cpu的压力自然可以成倍缓解
水平分表

1、概念:以字段为依据,按照一定策略(hash、range等),讲一个表中的数据拆分到多个表中。
2、结果:
每个表的结构都一样
每个表的数据不一样,没有交集,所有表的并集是全量数据。
3、场景:系统绝对并发量没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈,可以考虑水平分表。
4、分析:单表的数据量少了,单次执行SQL执行效率高了,自然减轻了CPU的负担。
垂直分库
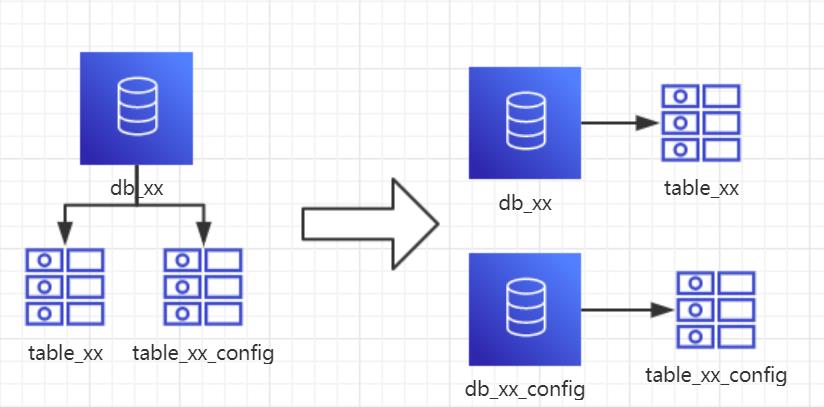
1、概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
2、结果:
每个库的结构都不一样
每个库的数据也不一样,没有交集
所有库的并集是全量数据
3、场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块的情况下。
4、分析:到这一步,基本上就可以服务化了。例如:随着业务的发展,一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再者,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
垂直分表

1、概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表中(主表和扩展表)。
2、结果:
每个表的结构不一样。
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据。
所有表的并集是全量数据。3、场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大,以至于数据库缓存的数据行减少,查询时回去读磁盘数据产生大量随机读IO,产生IO瓶颈。
4、分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能经常会查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表,这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获取全部数据就需要关联两个表来取数据。
但记住千万别用join,因为Join不仅会增加CPU负担并且会将两个表耦合在一起(必须在一个数据库实例上)。关联数据应该在service层进行,分别获取主表和扩展表的数据,然后用关联字段关联得到全部数据。
分库分表工具
sharding-jdbc(当当)
TSharding(蘑菇街)
Atlas(奇虎360)
Cobar(阿里巴巴)
MyCAT(基于Cobar)
Oceanus(58同城)
Vitess(谷歌) 各种工具的利弊自查
分库分表带来的问题
分库分表能有效缓解单机和单表带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,同时也带来一些问题,下面将描述这些问题和解决思路。
事务一致性问题
分布式事务
当更新内容同时存在于不同库找那个,不可避免会带来跨库事务问题。跨分片事务也是分布式事务,没有简单的方案,一般可使用“XA协议”和“两阶段提交”处理。
分布式事务能最大限度保证了数据库操作的原子性。但在提交事务时需要协调多个节点,推后了提交事务的时间点,延长了事务的执行时间,导致事务在访问共享资源时发生冲突或死锁的概率增高。随着数据库节点的增多,这种趋势会越来越严重,从而成为系统在数据库层面上水平扩展的枷锁。
最终一致性
对于那些性能要求很高,但对一致性要求不高的系统,往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。与事务在执行中发生错误立刻回滚的方式不同,事务补偿是一种事后检查补救的措施,一些常见的实现方法有:对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步等。
跨节点关联查询join问题
切分之前,系统中很多列表和详情表的数据可以通过join来完成,但是切分之后,数据可能分布在不同的节点上,此时join带来的问题就比较麻烦了,考虑到性能,尽量避免使用Join查询。解决的一些方法:
全局表
全局表,也可看做“数据字典表”,就是系统中所有模块都可能依赖的一些表,为了避免库join查询,可以将这类表在每个数据库中都保存一份。这些数据通常很少修改,所以不必担心一致性的问题。
字段冗余
一种典型的反范式设计,利用空间换时间,为了性能而避免join查询。例如,订单表在保存userId的时候,也将userName也冗余的保存一份,这样查询订单详情顺表就可以查到用户名userName,就不用查询买家user表了。但这种方法适用场景也有限,比较适用依赖字段比较少的情况,而冗余字段的一致性也较难保证。
数据组装
在系统service业务层面,分两次查询,第一次查询的结果集找出关联的数据id,然后根据id发起器二次请求得到关联数据,最后将获得的结果进行字段组装。这是比较常用的方法。
ER分片
关系型数据库中,如果已经确定了表之间的关联关系(如订单表和订单详情表),并且将那些存在关联关系的表记录存放在同一个分片上,那么就能较好地避免跨分片join的问题,可以在一个分片内进行join。在1:1或1:n的情况下,通常按照主表的ID进行主键切分。
跨节点分页、排序、函数问题
跨节点多库进行查询时,会出现limit分页、order by
排序等问题。分页需要按照指定字段进行排序,当排序字段就是分页字段时,通过分片规则就比较容易定位到指定的分片;当排序字段非分片字段时,就变得比较复杂.
需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户 如下图:
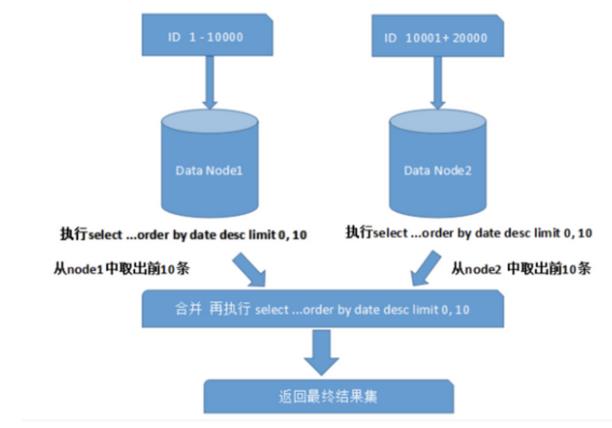
上图只是取第一页的数据,对性能影响还不是很大。但是如果取得页数很大,情况就变得复杂的多,因为各分片节点中的数据可能是随机的,为了排序的准确性,需要将所有节点的前N页数据都排序好做合并,最后再进行整体排序,这样的操作很耗费CPU和内存资源,所以页数越大,系统性能就会越差。
在使用Max、Min、Sum、Count之类的函数进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总再次计算。
全局主键避重问题
在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库自生成ID无法保证全局唯一。因此需要单独设计全局主键,避免跨库主键重复问题。这里有一些策略:
UUID
UUID标准形式是32个16进制数字,分为5段,形式是8-4-4-4-12的36个字符。
UUID是最简单的方案,本地生成,性能高,没有网络耗时,但是缺点明显,占用存储空间多,另外作为主键建立索引和基于索引进行查询都存在性能问题,尤其是InnoDb引擎下,UUID的无序性会导致索引位置频繁变动,导致分页。
结合数据库维护主键ID表
在数据库中建立sequence表:
CREATE TABLE `sequence` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`stub` char(1) NOT NULL default '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=MyISAM;
stub字段设置为唯一索引,同一stub值在sequence表中只有一条记录,可以同时为多张表生辰全局ID。使用MyISAM引擎而不是InnoDb,已获得更高的性能。MyISAM使用的是表锁,对表的读写是串行的,所以不用担心并发时两次读取同一个ID。当需要全局唯一的ID时,执行:
REPLACE INTO sequence (stub) VALUES ('a');
SELECT 1561439;
此方案较为简单,但缺点较为明显:存在单点问题,强依赖DB,当DB异常时,整个系统不可用。配置主从可以增加可用性。另外性能瓶颈限制在单台mysql的读写性能。
另有一种主键生成策略,类似sequence表方案,更好的解决了单点和性能瓶颈问题。这一方案的整体思想是:建立2个以上的全局ID生成的服务器,每个服务器上只部署一个数据库,每个库有一张sequence表用于记录当前全局ID。
表中增长的步长是库的数量,起始值依次错开,这样就能将ID的生成散列到各个数据库上
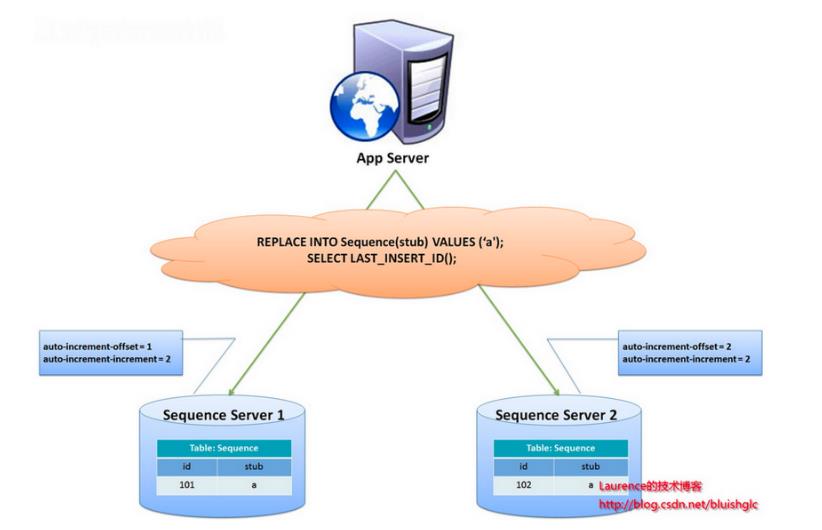
这种方案将生成ID的压力均匀分布在两台机器上,同时提供了系统容错,第一台出现了错误,可以自动切换到第二台获取ID。但有几个缺点:系统添加机器,水平扩展较复杂;每次获取ID都要读取一次DB,DB的压力还是很大,只能通过堆机器来提升性能。
Snowflake分布式自增ID算法

Twitter的snowfalke算法解决了分布式系统生成全局ID的需求,生成64位Long型数字,组成部分:
第一位未使用
接下来的41位是毫秒级时间,41位的长度可以表示69年的时间
5位datacenterId,5位workerId。10位长度最多支持部署1024个节点
最后12位是毫秒内计数,12位的计数顺序号支持每个节点每毫秒产生4096个ID序列。
数据迁移、扩容问题
当业务高速发展、面临性能和存储瓶颈时,才会考虑分片设计,此时就不可避免的需要考虑历史数据的迁移问题。一般做法是先读出历史数据,然后按照指定的分片规则再将数据写入到各分片节点中。此外还需要根据当前的数据量个QPS,以及业务发展速度,进行容量规划,推算出大概需要多少分片(一般建议单个分片的单表数据量不超过1000W)
什么时候考虑分库分表
能不分就不分
并不是所有表都需要切分,主要还是看数据的增长速度。切分后在某种程度上提升了业务的复杂程度。不到万不得已不要轻易使用分库分表这个“大招”,避免“过度设计”和“过早优化”。分库分表之前,先尽力做力所能及的优化:升级硬件、升级网络、读写分离、索引优化等。当数据量达到单表瓶颈后,在考虑分库分表。
数据量过大,正常运维影响业务访问
这里的运维是指:
对数据库备份,如果单表太大,备份时需要大量的磁盘IO和网络IO
对一个很大的表做DDL,MYSQL会锁住整个表,这个时间会很长,这段时间业务不能访问此表,影响很大。
大表经常访问和更新,就更有可能出现锁等待。
随着业务发展,需要对某些字段垂直拆分
这里就不举例了。在实际业务中都可能会碰到,有些不经常访问或者更新频率低的字段应该从大表中分离出去。
数据量快速增长
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。
参考链接:
https://www.cnblogs.com/butterfly100/p/9034281.html
https://www.cnblogs.com/littlecharacter/p/9342129.html
end
BAT等大厂Java面试经验总结 想获取 Java大厂面试题学习资料扫下方二维码回复「BAT」就好了回复 【加群】获取github掘金交流群回复 【电子书】获取2020电子书教程回复 【C】获取全套C语言学习知识手册回复 【Java】获取java相关的视频教程和资料回复 【爬虫】获取SpringCloud相关多的学习资料回复 【Python】即可获得Python基础到进阶的学习教程回复 【idea破解】即可获得intellij idea相关的破解教程关注我gitHub掘金,每天发掘一篇好项目,学习技术不迷路!
回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
为什么HTTPS是安全的
因为BitMap,白白搭进去8台服务器...
《某厂内部SQL大全 》.PDF
字节跳动一面:i++ 是线程安全的吗?
大家好,欢迎加我微信,很高兴认识你!
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
相信自己,没有做不到的,只有想不到的在这里获得的不仅仅是技术!
如果喜欢就给个“在看”
以上是关于为啥要用分库分表方案?如何平滑升级?看这篇!的主要内容,如果未能解决你的问题,请参考以下文章