在线进行分库分表中间件的平滑升级,正所谓艺高人胆大
Posted 架构摆渡人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在线进行分库分表中间件的平滑升级,正所谓艺高人胆大相关的知识,希望对你有一定的参考价值。
大家好,我是架构摆渡人。这是实践经验系列的第十篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。故事还要从N年前说起,那时业务发展的比较快,数据每天增长比较多。很快就经常出现慢SQL各种问题,拆库迫在眉睫。为了快速上线,直接在应用中进行拆分规则的处理,也就是将分库分表的逻辑在客户端进行处理,这样的方式简单,性能也不错。过了一年多,技术部加了好多人,细分的团队也更多了。老项目用的自研的客户端分库分表方式,有一些新团队内部用的开源的框架。随着技术部规模越来越大,我们也有了自己的中间件团队。CTO想统一技术栈,分库分表中间件是排在第一位要进行统一的,方便统一维护和升级。于是,中间件团队研发了一款分库分表中间件,类似于开源的Mycat之类的,是一个代理服务,这个服务就是mysql的协议,我们的应用程序可以直接把它当做一个数据库进行连接即可。对于这种中间件的替换,最简单的方式当然就是直接替换,然后发布即可。但是如果这个中间件没有经过长时间业务的考验,你会觉得它很稳定吗?如果不稳定,后面出问题了怎么办? 所以,在上线这个中间件切换的时候,大家讨论了很久,最终定了两种方案来实施。
方案一比较简单,实现成本较低。也就是单独切一个分支进行改造,改造完成后,不立马合入master分支,而是直接用这个功能分支进行发布,但是只发布一个节点。这样即使有问题,影响面也比较小。停止服务即可立马回滚,验证一段时间没有问题,就可以将代码合入master进行全量发布。如果,用了一段时间后,新的代理中间件不稳定,那么此时是没办法立马回滚的,变成了强依赖。此方案虽然成本低,但是稳定性考虑的一般。方案二,实现过程较为复杂,工作量也比较大,但是稳定可靠。下面来介绍下多数据源并存,在线灰度的方式。首先,目前我们的项目中用的还是之前自己写的一套方案,本地分库分表的。如果想要保证在出问题的时候能够及时切回来,所以就不能采取直接替换的方式,也就是之前的所有数据源都要保留。至于新的中间件,我们会配置一个新的数据源,所以项目中就有两套数据源。那么只需要在我们对数据库进行增删改查操作的时候,动态进行数据源切换,就可以实现在线灰度逻辑。
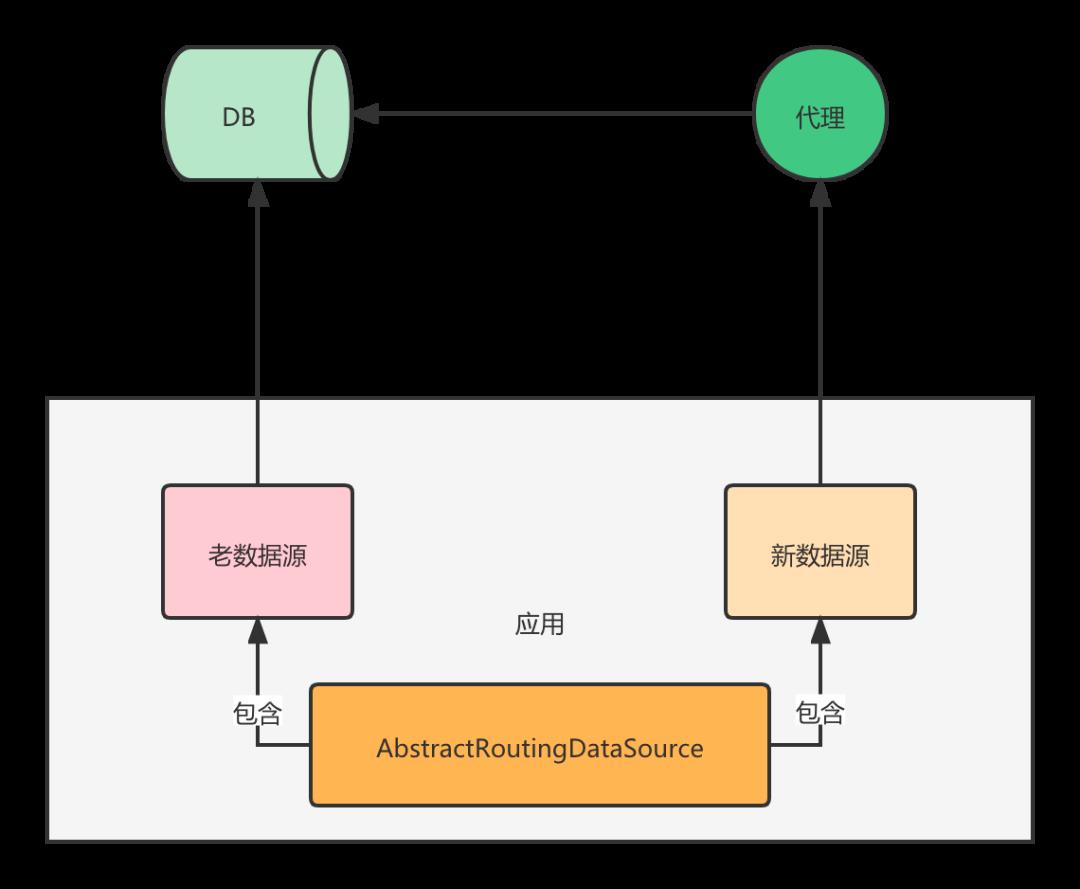
灰度可以直接在接口级别进行,这样即使出问题,也只影响某个接口。而且你可以从不重要的接口开始灰度。灰度的核心逻辑无非就是控制AbstractRoutingDataSource的返回值,返回哪个数据源,那么这次SQL的执行将由哪个数据源负责。我们是Spring Cloud架构,所有接口都是Http协议,所以写了一个Http Filter进行处理。通过配置灰度的规则,然后给要灰度的接口设置一个值,这个值保存到ThreadLocal中,在AbstractRoutingDataSource中使用,这样就完成了整个灰度的控制。另外,这里还需要注意的是,有一些异步的处理要关注,比如MQ的消费是不经过Http Filter,所以对于MQ的消费你需要单独进行灰度的控制。同时需要注意的是你的DB的连接数是否够用,因为采用本方案,连接数会翻倍,需要确认。通过这个方案,我们将灰度做到了最小粒度,接口级别。同时代码也可以合入master分支一起发布。发布的时候默认还是老的数据源,对现有业务不影响。发布完成后,通过配置开启灰度逻辑,慢慢灰度,灰度完成后所有SQL都会通过新的数据源,也就是代理的方式进行数据库的访问。假设跑了三个月,代理中间件出问题,我们还是可以秒级别将SQL的执行切到老的数据源上面来保证业务的稳定性。当然不是永远都要保留两套数据源,一般用个半年如果没问题,就可以把老数据源下掉了。同时要注意的是在这半年期间,如果加了新的分表规则,也需要在老代码中维护,因为要具备随时切回来的能力,所以必须同步,否则切回来没有对应的分表规则,还是会报错。
大家好,我是从古代穿越过来的美男子:架构摆渡人。我将把我的武功秘籍全部传授与你们,觉得有用请分享给身边的朋友。来个三连吧,感谢各位!另外我还在B站录制了《真实订单业务,亿级数据带你实战分库分表》的实战课程,记得去学习哦!
分库分表如何平滑过渡?
面试题
现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切换到分库分表上?
面试官心理分析
你看看,你现在已经明白为啥要分库分表了,你也知道常用的分库分表中间件了,你也设计好你们如何分库分表的方案了(水平拆分、垂直拆分、分表),那问题来了,你接下来该怎么把你那个单库单表的系统给迁移到分库分表上去?
所以这都是一环扣一环的,就是看你有没有全流程经历过这个过程。
面试题剖析
这个其实从 low 到高大上有好几种方案,我们都玩儿过,我都给你说一下。
停机迁移方案
我先给你说一个最 low 的方案,就是很简单,大家伙儿凌晨 12 点开始运维,网站或者 app 挂个公告,说 0 点到早上 6 点进行运维,无法访问。
接着到 0 点停机,系统停掉,没有流量写入了,此时老的单库单表数据库静止了。然后你之前得写好一个导数的一次性工具,此时直接跑起来,然后将单库单表的数据哗哗哗读出来,写到分库分表里面去。
导数完了之后,就 ok 了,修改系统的数据库连接配置啥的,包括可能代码和 SQL 也许有修改,那你就用最新的代码,然后直接启动连到新的分库分表上去。
验证一下,ok了,完美,大家伸个懒腰,看看看凌晨 4 点钟的北京夜景,打个滴滴回家吧。
但是这个方案比较 low,谁都能干,我们来看看高大上一点的方案。
双写迁移方案
这个是我们常用的一种迁移方案,比较靠谱一些,不用停机,不用看北京凌晨 4 点的风景。
简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改,这就是所谓的双写,同时写俩库,老库和新库。
然后系统部署之后,新库数据差太远,用之前说的导数工具,跑起来读老库数据写新库,写的时候要根据 gmt_modified 这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。简单来说,就是不允许用老数据覆盖新数据。
导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。
接着当数据完全一致了,就 ok 了,基于仅仅使用分库分表的最新代码,重新部署一次,不就仅仅基于分库分表在操作了么,还没有几个小时的停机时间,很稳。所以现在基本玩儿数据迁移之类的,都是这么干的。
以上是关于在线进行分库分表中间件的平滑升级,正所谓艺高人胆大的主要内容,如果未能解决你的问题,请参考以下文章
