Spark 内存管理详解
Posted <一蓑烟雨任平生>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 内存管理详解相关的知识,希望对你有一定的参考价值。
在执行Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 Spark 作业(Job),并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给 Driver,同时为需要持久化的 RDD 提供存储功能。由于 Driver 的内存管理相对来说较为简单,本节主要对 Executor 的内存管理进行分析,下文中的 Spark 内存均特指 Executor 的内存。
堆内和堆外内存规划
作为一个 JVM 进程,Executor 的内存管理建立在 JVM 的内存管理之上,Spark 对 JVM 的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
堆内内存受到JVM统一管理,堆外内存是直接向操作系统进行内存的申请和释放。
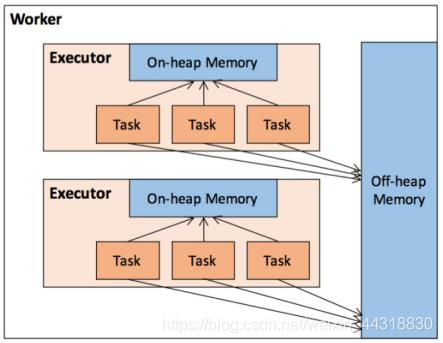
1.堆内内存
堆内内存的大小,由 Spark 应用程序启动时的 –executor-memory 或 spark.executor.memory 参数配置。Executor 内运行的并发任务共享 JVM 堆内内存,这些任务在缓存 RDD 数据和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行 Shuffle 时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些 Spark 内部的对象实例,或者用户定义的 Spark 应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同。
Spark 对堆内内存的管理是一种逻辑上的"规划式"的管理,因为对象实例占用内存的申请和释放都由 JVM 完成,Spark 只能在申请后和释放前记录这些内存,我们来看其具体流程:
申请内存流程如下:
- Spark 在代码中 new 一个对象实例;
- JVM 从堆内内存分配空间,创建对象并返回对象引用;
- Spark 保存该对象的引用,记录该对象占用的内存。
释放内存流程如下:
- Spark记录该对象释放的内存,删除该对象的引用;
- 等待JVM的垃圾回收机制释放该对象占用的堆内内存。
我们知道,JVM 的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需要进行序列化的逆过程——反序列化,将字节流转化为对象,序列化的方式可以节省存储空间,但增加了存储和读取时候的计算开销。
对于 Spark 中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算,而对于非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期。此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
虽然不能精准控制堆内内存的申请和释放,但 Spark 通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
2.堆外内存
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。
堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
利用 JDK Unsafe API(从 Spark 2.0 开始,在管理堆外的存储内存时不再基于 Tachyon,而是与堆外的执行内存一样,基于 JDK Unsafe API 实现),Spark 可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放(堆外内存之所以能够被精确的申请和释放,是由于内存的申请和释放不再通过JVM机制,而是直接向操作系统申请,JVM对于内存的清理是无法准确指定时间点的,因此无法实现精确的释放),而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled 参数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!
以上是关于Spark 内存管理详解的主要内容,如果未能解决你的问题,请参考以下文章