❤️ 学会爬虫不用再收藏了,直接把网站拍照留念❤️
Posted 雷学委
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️ 学会爬虫不用再收藏了,直接把网站拍照留念❤️相关的知识,希望对你有一定的参考价值。
前一篇文章防止恶意刷接口 给网站加验证码很多人评论,说验证码可以智能识别。
学委震惊了! 我们搞系统设计和开发加入类似验证码等技术,主要防止恶意。 如果有人想要程序遍历穷举智能识别,通过社会工程加上一些黑客技术,估计就是时间问题。但是我们会了技术,必须正直有良心,不能啥都去干!!!
这次先分享一个截屏网站的。后面再写代码自动识别登录自己的网站。
本文主要讨论简短能入门的截屏代码,并配置把它跑起来!
举个例子:为了学习热榜,我把热榜截图保留下来以后学习
第一步安装selenium
selenium 是一个浏览器自动化框架,支持多语言。不多说直接安装:
pip install selenium
不清楚pip的朋友请看 快速学会并精通pip 并三连支持。有问题可以友善评论。
这是selenium官网: https://www.selenium.dev/
第二步直接写代码
把下面的代码保存为auto.py
'''
雷学委现写代码,只支持Python3。 其他版本请读者自行实现。
'''
from selenium import webdriver
from selenium.webdriver import Firefox,Chrome
from selenium.webdriver.common.by import By
def xuewei_open(driver, url):
driver.get(url)
driver.maximize_window()
driver.implicitly_wait(5)
print("max done")
def exit(driver):
driver.quit()
print("exit...")
#这里是本机的chromedriver路径
driver = Chrome("/Users/mac/webdriver/chromedriver")
driver.implicitly_wait(3)
img_path = "./code.png"
#可以用百度新闻
#url="http://news.baidu.com/"
#也可以把CSDN热榜截图保存,保持学习热榜文章
url = "https://blog.csdn.net/rank/list"
xuewei_open(driver, url)
chrome_size = driver.get_window_size()
print("win size %s " % str(chrome_size))
driver.get_screenshot_as_file(img_path)
print("save screen to path: %s"% img_path)
exit(driver)
运行上面的代码:python auto.py
下图就是上面代码截屏出来的:
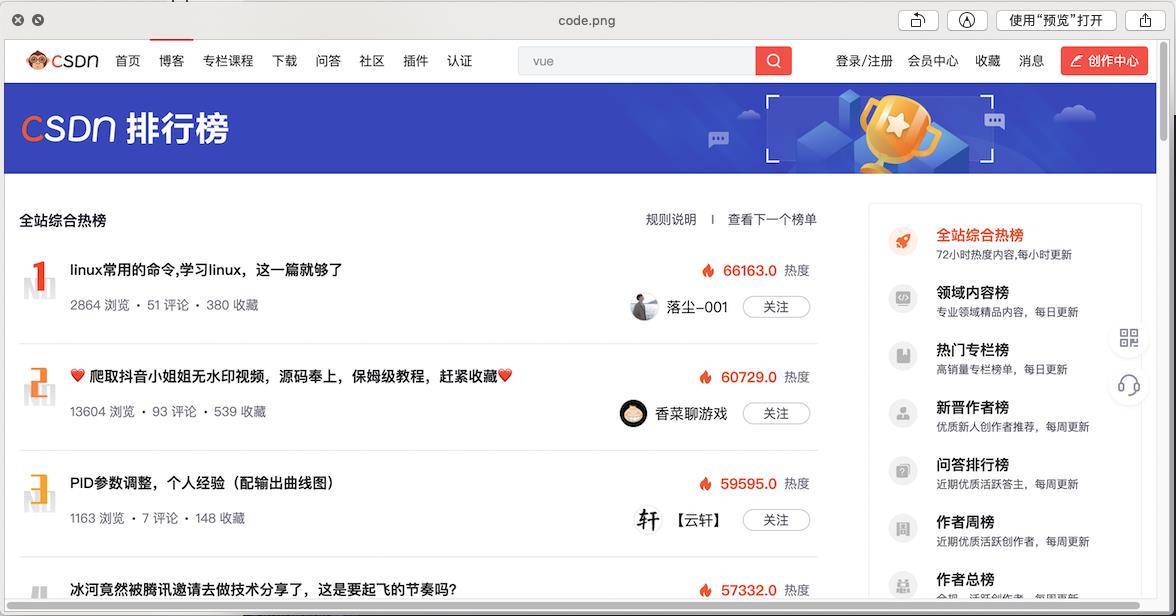
第三步,如果第二步发现因为chromedriver没有安装
请移步 chrome driver 版本下载, 从下面三个任意选一个:
http://npm.taobao.org/mirrors/chromedriver/
http://chromedriver.storage.googleapis.com/index.html
https://chromedriver.chromium.org/downloads
因为上面的代码直接硬编码了chromedriver的路径了。解压,配置到的PATH,但不是必要。
下载对应版本的报,解压安装到/Users/mac/webdriver/ 。
最终路径为:/Users/mac/webdriver/chromedriver
下面是验证安装效果,注意版本号跟当前主机安装的chrome浏览器一致!否则重新下载。
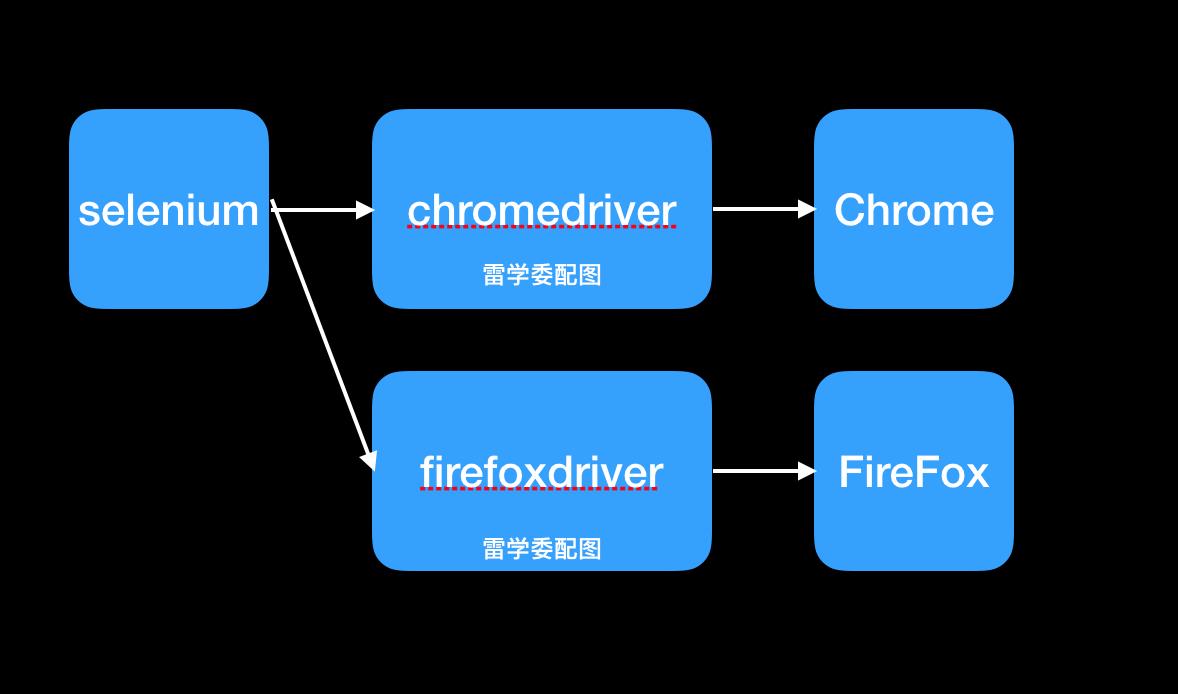
原理简化解析
如下图的组件交互过程:
selenium 内部驱动了chromedriver,我们调用driver的各种函数,背后其实就是chromedriver跟浏览器沟通。
比如driver.maximize_window 这个函数会通过 chromedriver 传递一个最大化窗口的指令给Chrome浏览器。
不止是Chrome浏览器,selenium 还支持多个浏览器的自动化,我们后面再看。
题外话
不是说智能识别验证码吗?小白请先把上面的代码学了。
智能识别验证的过程就是:
- 截屏带验证码的页面
- 局部提取图片
- 解析图片为文本(还有其他形式需要用其他的库)
- 使用selenium调用driver提交验证码带上(send_keys)。
会的朋友可以先试试看。
最后使用爬虫必须谨慎,不要当做儿戏去爬机构网站。你学习也不能拿严肃的网络来刷,这个行为迟早会让你吃上LAO饭!
本文仅作展示目的,对于演示网站有任何异议,请告知修改。
持续学习持续开发,我是雷学委!
编程很有趣,关键是把技术搞透彻讲明白。
创作不易,请多多支持,点赞收藏支持学委吧!
以上是关于❤️ 学会爬虫不用再收藏了,直接把网站拍照留念❤️的主要内容,如果未能解决你的问题,请参考以下文章
❤️不到100行把流式热榜截屏合成一张?爬虫终极秘诀建议收藏❤️
❤️不到100行把流式热榜截屏合成一张?爬虫终极秘诀建议收藏❤️
万字博文教你python爬虫必备XPath库,看完还不会我把我女朋友都给你❤️建议收藏系列❤️
❤️万字博文教你python爬虫必备XPath库,看完还不会我把我女朋友都给你❤️建议收藏系列