❤️万字博文教你python爬虫必备XPath库,看完还不会我把我女朋友都给你❤️建议收藏系列
Posted 孤寒者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️万字博文教你python爬虫必备XPath库,看完还不会我把我女朋友都给你❤️建议收藏系列相关的知识,希望对你有一定的参考价值。
👻相信不少小伙伴们通过我的两篇万字博文的轮番轰炸已经实现了从入坑到会完全学会requests库,并且可以独立开发出属于自己的小爬虫项目!!!——爬虫之路,永无止境~👻
💦第一篇爬虫入坑文;一篇万字博文带你入坑爬虫这条不归路 【万字图文】💦
💦第二篇爬虫库requests库详解。两万字博文教你python爬虫requests库【详解篇】💦
😬但是爬虫爬虫,重在爬取到我们想要的数据,那么我们该如何提取页面中我们所需要的信息呢?为了让小伙伴们更加深入的学习本文所讲的页面解析库,我先一步肝了一篇html万字详解,希望小伙伴们认认真真看完,看明白,看懂,多敲敲,日后你们自会感受到本博主的用意——HTML两万字王者笔记大总结【❤️熬夜整理&建议收藏❤️】(上篇)和HTML两万字王者笔记大总结【❤️熬夜整理&建议收藏❤️】(下篇)😬
👇
👉🚔直接跳到末尾🚔👈 ——>领取专属粉丝福利💖
☝️
😜爬取到我们想要的数据——专业点说就是进行页面解析!对于网页的节点来说,它可以定义id,class等多种属性。而且节点之间还有层次关系,在网页中可以通过XPath或CSS选择器来定位一个或多个节点。那么,在页面解析时,利用XPath或CSS选择器来提取某个节点,然后调用相应方法获取它的正文内容或者属性,不就可以提取我们想要的信息了吗!😜

我们伟大的Python已经为我们封装了很多实现上述操作的解析库,其中比较强大&&用的较多的有lxml,Beautiful Soup,pyquery等。本篇博文带领小伙伴们走入XPath(我们日后最常用/最实用的解析库之一)的世界!
| 学好解析库,网页数据任我取!!! |
❤️bs4&&XPath❤️

💎1.XPath(路径表达式)
🎉(1)简介:
XPath 是一门在 XML 文档中查找信息的语言,但它同样可用于HTML文档的搜索。(相比于BeautifulSoup,Xpath在提取数据时会更有效率)
| XPath功能十分强大,它提供了非常简单使用的路径选择表达式以及超过100个内建函数,用于字符串,数值,时间的匹配以及节点,序列的处理等!所以这也是诸多爬虫工程师进行页面解析时的首选!!! |
🎅(2)安装:
在python中很多库都提供XPath的功能,但是最流行的还是lxml这个库,效率最高。(直接pip install lxml 即可)
| 需要注意的是: |
| 1.python3.7导入etree的方法为from lxml import html; |
| 2.python3.6导入etree的方法为from lxml import etree; |
🎃(3)常用规则:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前接点选取子孙节点 |
| . | 选取当前接点 |
| … | 选取当前接点的父节点 |
| @ | 选取属性 |
🎈(2)实例引入:
(我们定义一个text字符串模拟爬取到的页面数据)
from lxml import etree
text = '''
<div class="navli "><span class="nav_tit"><a href="javascript:;">时政</a><i class="group"></i></span></div>
<div class="navli "><span class="nav_tit"><a href="https://news.cctv.com/">新闻</a></span></div>
<div class="navli "><span class="nav_tit"><a href="https://v.cctv.com/">视频</a></span></div>
<div class="navli "><span class="nav_tit"><a href="https://jingji.cctv.com/">经济</a></span></div>
<div class="navli "><span class="nav_tit"><a href="https://opinion.cctv.com/">评论</a></span></div>
<div class="navli "><span class="nav_tit"><a href="https://sports.cctv.com/">体育</a></span>
'''
html = etree.HTML(text) # 调用HTML类进行初始化,这样就成功构造了一个XPath解析对象。
result = etree.tostring(html)
print(result.decode('utf-8'))
注意上面HTML文本中的最后一个div节点是没有闭合的,但是etree模块可以自动补全HTML文本,为了观察被自动补全后的HTML文本,再调用tostring()方法,注意结果是bytes类型,所以需要decode()方法将其转为str类型!

观察上面结果可知——经过处理之后,div节点标签被补全,并且还自动添加了body,html节点!

👻(3)各种常用操作详解
战前准备第一步——自定义一个HTML文本模拟爬取到的页面数据!
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story" id="66">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">999</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
💝战前准备第二步——构造XPath解析对象!
from lxml import etree #原理和beautiful一样,都是将html字符串转换为我们易于处理的标签对象
page = etree.HTML(html_doc) #返回了html节点
print(type(page)) #输出为:<class 'lxml.etree._Element'>

🏄(1)常用规则详解:
XPath使用路径表达式在 XML/HTML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。(注意:所有选中的节点都包含在列表中!)
下面列出了最有用/最常用的路径表达式:
🎅①nodename表示根据标签名字选取标签,注意只会选择子标签!比如:如果是儿子的儿子则选取不到。

🍏②/表示从根节点选取 一级一级筛选(不能跳)
🍒③// 表示从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 注意:是所有符合条件的

🍓④ .表示选取当前标签
🍌⑤两个.表示选取当前标签的父节点

🍠⑥@表示获取标签的属性值

🎍上述常用规则测试代码(建议自己多敲多练多思考!):
# 1. 根据nodename(标签名字)选取标签的时候,只会选择子标签;比如:如果是儿子的儿子则选取不到。
print(page.xpath("body"))
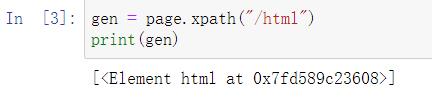
#2. /从根节点选取 一级一级筛选(不能跳)
gen = page.xpath("/html")
print(gen)
#3. 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 注意:是所有符合条件的
a = page.xpath("//a")
print(a)
#4. .选取当前标签
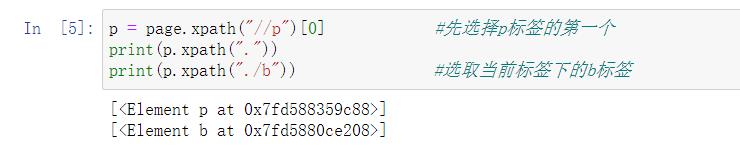
p = page.xpath("//p")[0] #先选择p标签的第一个
print(p.xpath("."))
print(p.xpath("./b")) #选取当前标签下的b标签
#5. ..选取当前标签的父节点
a = page.xpath("//a")[0]
print(a.xpath("..")) # a.xpath("parent::")也可获取父节点!
# 6.获取标签的属性值
bb = page.xpath('//p[@class="story"]/@id') #获取标签的id属性值
print(bb)

🐱(2)谓语讲解:
谓语:
谓语用来查找某个或某些特定的节点或者包含某个指定值的节点
谓语被嵌在方括号中。
下面列出了带有最常用/最有用的谓语的一些路径表达式,以及表达式的结果
🐹①选取所有拥有属性class的p标签:

🐸②选取所有p标签,且拥有属性class同时值为story的标签:

🚀③选取所有的p标签,且其中a标签的文本值大于889:

🐻④选取属于class为story的p标签 子元素的第一个a元素:

👑⑤选取属于class为story的p标签 子元素的最后一个a元素:

🐮⑥选取属于class为story的p标签 子元素的倒数第二个a元素:

🐒⑦选取最前面的两个属于class为story的p标签的子元素的a元素:

⚽️上述谓语讲解测试代码(建议自己多敲多练多思考!):
#1.选取所有拥有属性class的p标签
j = page.xpath('//p[@class]')
print("j:",j)
#选取所有p标签,且拥有属性class同时值为story的标签
b = page.xpath('//p[@class="story"]')
print("b",b)
#2.选取所有的p标签,且其中a标签的文本值大于889。
print(page.xpath('//p[a>889]'))
#3.选取属于class为story的p标签 子元素的第一个a元素。
dd = page.xpath('//p[@class="story"]/a[1]') #如果是在xpath里进行索引选择,是从1开始
ee = page.xpath('//p[@class="story"]/a')[0] #如果是从列表里进行索引选择,是从0开始
print("dd:",dd)
print("ee",ee)
# 选取属于class为story的p标签 子元素的最后一个a元素。
ss = page.xpath('//p[@class="story"]/a[last()]')
print("ss:",ss)
# 选取属于class为story的p标签 子元素的倒数第二个a元素。
rr = page.xpath('//p[@class="story"]/a[last()-1]')
print("rr",rr)
# 选取最前面的两个属于class为story的p标签的子元素的a元素。
gg = page.xpath('//p[@class="story"]/a[position()<3]')
print("gg:",gg)
📌(3)获取文本:
🐫①用text()获取某个节点下的文本:

💊②用string()获取某个节点下所有的文本:

🔆上述获取文本测试代码(建议自己多敲多练多思考!):
#1.用text()获取某个节点下的文本
contents=page.xpath("//p/a/text()") #获取文本数据 放在列表里
print(contents)
#2.用string()获取某个节点下所有的文本
con = page.xpath("string(//p)") #只拿到第一个标签下的所有文本
print(con)

🏃(4)XPath通配符:
用处:选取未知节点。即XPath通配符可用来选取未知节点
🔮①*表示匹配任何元素节点:

🐾②@* 匹配任何属性节点:

🌷上述XPath通配符测试代码(建议自己多敲多练多思考!):
# 1.* 匹配任何元素节点
s = page.xpath("//p/*") #选择p标签的所有子元素
print(s)
#2.@* 匹配任何属性节点
ss = page.xpath("//p/@*") #选取选中标签(所有p标签)的所有的属性值
print(ss)

🌻(5)使用|运算:
选取多个路径
通过在路径表达式中使用"|"运算符,可以实现选取若干个路径。
🍃①选取p元素的所有a和b元素:

🍄②选取文档中的所有a和b元素:

🐚上述使用|运算测试代码(建议自己多敲多练多思考!):
# 选取p元素的所有a和b元素
print(page.xpath('//p/a|//p/b'))
#选取文档中的所有a和b元素
print(page.xpath('//a|//b'))

🌖(4)拓展——骚操作:
🌜1.属性多值匹配(有些时候,有些节点的属性可能有多个值。)
from lxml import etree
text = '''
<div class="navli navli-first"><span class="nav_tit"><a href="javascript:;">时政</a><i class="group"></i></span></div>
'''
html = etree.HTML(text)
print(html.xpath('//div[@class="navli"]//a/text()'))
比如上述HTML文本中的div节点的class属性有两个值navli和navli-first,此时如果还想用之前的属性匹配获取,就无法匹配到了。上述代码的输出为[]。
两个解决方法:
①xpath语法写入完整的属性值:print(html.xpath(’//div[@class=“navli navli-first”]//a/text()’)),这样输出为:[‘时政’]
②使用contains()函数,不需要写入完整属性值,第一个参数传入属性名称,第二个参数传入属性值,只要此属性包含所传入的属性值,就可以完成匹配!如:print(html.xpath(’//div[contains(@class,“navli”)]//a/text()’)),这样输出也为:[‘时政’]
🌋2.多属性匹配:(有些时候,要根据多个属性确定一个节点,这时需要同时匹配多个属性,此时可以使用运算符and来连接!)
from lxml import etree
text = '''
<div class="navli navli-first" name="second"><span class="nav_tit"><a href="javascript:;">时政</a><i class="group"></i></span></div>
'''
html = etree.HTML(text)
print(html.xpath('//div[contains(@class,"navli") and @name="second"]//a/text()'))
| 输出为['时政'] |
一些常用的运算符:
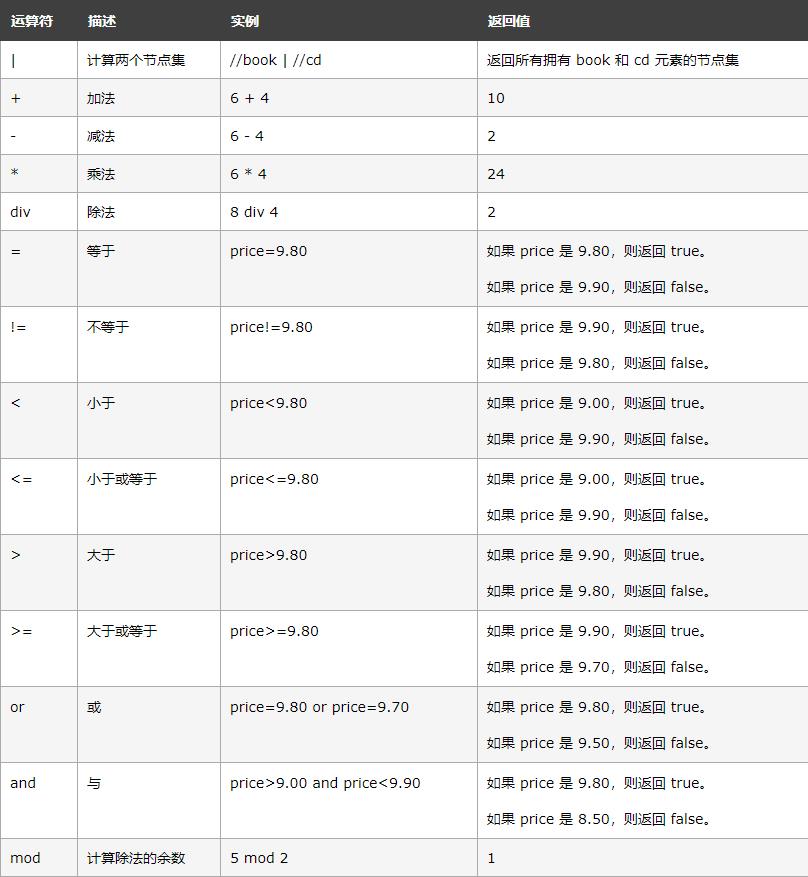 (此表引用自w3school)
(此表引用自w3school)
🌼3.节点轴选择:
⛅️①ancestor轴:
# 调用ancestor轴,获取所有祖先节点。其后需要跟两个冒号,然后是节点的选择器。返回结果:第一个li节点的所有祖先节点。
html.xpath('//li[1]/ancestor::*')
🎒②attribute轴:
# 调用了attribute轴,获取所有属性值。返回结果:li节点的所有属性值。
html.xpath('//li[1]/attribute::*')
💝③child轴:
# 调用了child轴,获取所有直接子节点。返回结果:选取href属性为link.html的a子节点。
html.xpath('//li[1]/child::a[@href="link1.html"]')
💝④descendant轴:
# 调用了descendant轴,获取所有子孙节点。同时加了限定条件。返回结果:选取li节点下的子孙节点里的span节点。
html.xpath('//li[1]/descendant::span')
☎️⑤following轴:
# 调用了following轴,获取当前节点之后的所有节点。
html.xpath('//li[1]/following::*[2]')
🔇⑥following-sibling轴:
# 调用了following-sibling轴,获取当前节点之后的所有同级节点。
html.xpath('//li[1]/following-sibling::*')
🔓2.实战之豆瓣Top250电影信息爬取
经过本次实战实用XPath库,你会发现进行页面解析,提取你需要的数据是十分方便快捷的——这也是广大爬虫工程师的感受,所以XPath小伙伴们必须要掌握的牢牢的哦!
💣3.In The End!

| 从现在做起,坚持下去,一天进步一小点,不久的将来,你会感谢曾经努力的你! |
本博主会持续更新爬虫基础分栏及爬虫实战分栏,认真仔细看完本文的小伙伴们,可以点赞收藏并评论出你们的读后感。并可关注本博主,在今后的日子里阅读更多爬虫文!
如有错误或者言语不恰当的地方可在评论区指出,谢谢!
如转载此文请联系我说明用以意并标注出处及本博主名,谢谢!
可通过点击下面——>添加私人VX号—>请标明来自CSDN,会拉你进入技术交流群(群内涉及各个领域大佬级人物,任何问题都可讨论~)—>互相学习&&共同进步(非诚勿扰):
以上是关于❤️万字博文教你python爬虫必备XPath库,看完还不会我把我女朋友都给你❤️建议收藏系列的主要内容,如果未能解决你的问题,请参考以下文章
万字博文教你python爬虫必备XPath库,看完还不会我把我女朋友都给你❤️建议收藏系列❤️
万字博文教你python爬虫必备Beautiful Soup库,看完还不会我把我女朋友都给你❤️建议收藏系列❤️
Python万字博文教你玩透Beautiful Soup库,不信你学不会❤️建议收藏系列❤️
两万字博文教你python爬虫requests库,看完还不会我把我女朋友都给你❤️熬夜整理&建议收藏❤️