Spark部署在Yarn集群
Posted 杀智勇双全杀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark部署在Yarn集群相关的知识,希望对你有一定的参考价值。
Spark部署在Yarn集群
Spark博大精深,不是一朝一日能搞明白的。。。以后的稿子可能不会写的灰常详细了,相信需要参考的读者懂的都懂。。。
需要查看笔者之前的稿子。。。Spark依赖的东西太多了。。。本文依旧是基于之前搭建的虚拟机集群。
为了节省部署时间,对某些配置顺序做了修改。
上传及解压
cd /export/software/
rz #上传spark-2.4.5-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /export/server/ # 解压
cd /export/server/
ll # 查看是否解压成功
ln -s /export/server/spark-2.4.5-bin-hadoop2.7/ /export/server/spark # 创建软链接
ll # 查看是否有spark -> /export/server/spark-2.4.5-bin-hadoop2.7/
cd /export/server/spark/conf/
mv spark-env.sh.template spark-env.sh
单机部署
使用vim修改这个spark-env.sh:
JAVA_HOME=/export/server/jdk1.8.0_241/
SCALA_HOME=/export/server/scala
HADOOP_CONF_DIR=/export/server/hadoop-2.7.5/etc/hadoop/
保存,配置好后可以使用单机模式测试Spark自带的Pi案例:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master local[2] \\
--class org.apache.spark.examples.SparkPi \\
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \\
10
会看到类似Pi is roughly 3.1399231399231398的内容,说明单机模式成功。
配置Spark on Yarn
vim /export/server/spark/conf/spark-env.sh
YARN_CONF_DIR=/export/server/hadoop-2.7.5/etc/hadoop/ # 和HADOOP_CONF_DIR一致
保存。到此配置好了Spark on Yarn。
实现分布式
cd /export/server/spark/conf/
mv slaves.template slaves
vim slaves
修改内容为:
node1
node2
node3
保存后配置Master、Workers、HistoryServer:
vim spark-env.sh
后边插入:
SPARK_MASTER_HOST=node1
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/spark/eventLogs/
-Dspark.history.fs.cleaner.enabled=true"
保存后:
hdfs dfs -mkdir -p /spark/eventLogs/
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
末尾添加:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/spark/eventLogs/
spark.eventLog.compress true
spark.yarn.historyServer.address node1:18080
spark.yarn.jars hdfs://node1:8020/spark/apps/jars/*
保存后:
mv log4j.properties.template log4j.properties
vim log4j.properties
log4j.rootCategory=WARN, console # 只修改这一行
保存后分发:
scp -r spark-2.4.5-bin-hadoop2.7/ node2:$PWD
scp -r spark-2.4.5-bin-hadoop2.7/ node3:$PWD
到此成功配置好分布式。
配置历史服务
开发环境可配可不配,不影响程序运行的。为了能够查看运行历史记录,生产环境是一定要配置的。
cd /export/server/hadoop-2.7.5/etc/hadoop/
vim yarn-site.xml
插入:
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
保存后分发:
scp -r yarn-site.xml node2:$PWD
scp -r yarn-site.xml node3:$PWD
到此成功配置了历史服务。
配置SparkJar包路径
由于Spark2.4.0搭配Hadoop2.7.5使用,Hadoop是3冗余的,如果每次都是把所有依赖全部打Jar包,多个Spark程序的Jar包重复率不低,浪费硬盘。SparkJar包路径主要是为了节省硬盘空间,方便集中管理Jar包是次要功能。。。硬盘大可以随意。。。
hdfs dfs -mkdir -p /spark/apps/jars/
hdfs dfs -put /export/server/spark/jars/* /spark/apps/jars/
测试
使用Spark自带的submit测试下效果:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \\
--master yarn \\
--class org.apache.spark.examples.SparkPi \\
${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \\
10
出现:
21/08/19 17:46:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Pi is roughly 3.1407231407231406
浏览器访问node3:8088可以看到:
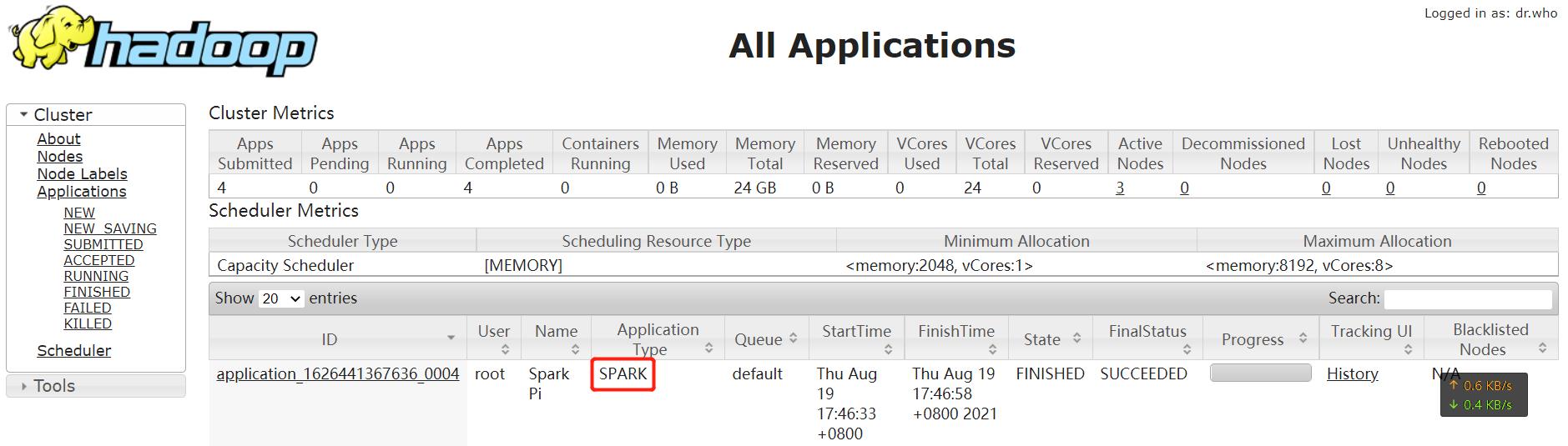
看到这个界面,Application Type是Spark,说明Spark on Yarn配置完毕。暂时可以愉快地使用了。
和Hive的集成之后再配。。。
以上是关于Spark部署在Yarn集群的主要内容,如果未能解决你的问题,请参考以下文章