大数据Spark集成Kafka
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark集成Kafka相关的知识,希望对你有一定的参考价值。
目录
1 整合Kafka 0.8.2
在实际项目中,无论使用Storm还是SparkStreaming与Flink,主要从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下:
技术栈: Flume/SDK/Kafka Producer API -> KafKa —> SparkStreaming/Flink/Storm(Hadoop YARN) -> Redis -> UI
1)、阿里工具Canal:监控mysql数据库binlog文件,将数据同步发送到Kafka Topic中
https://github.com/alibaba/canal
https://github.com/alibaba/canal/wiki/QuickStart
2)、Maxwell:实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、
Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。
http://maxwells-daemon.io/
https://github.com/zendesk/maxwell
扩展:Kafka 相关常见面试题:
1)、Kafka 集群大小(规模),Topic分区函数名及集群配置?
2)、Topic中数据如何管理?数据删除策略是什么?
3)、如何消费Kafka数据?
4)、发送数据Kafka Topic中时,如何保证数据发送成功?
Apache Kafka: 最原始功能【消息队列】,缓冲数据,具有发布订阅功能(类似微信公众号)。
1.1 回顾 Kafka 概念
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用与大数
据实时处理领域。
- 消息队列:Kafka 本质上是一个 MQ(Message Queue),使用消息队列的好处?(面试会问):
- 解耦:允许我们独立的扩展或修改队列两边的处理过程;
- 可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍可以在系统恢复后被处理;
- 缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况;
- 灵活性&峰值处理能力:不会因为突发的超负荷的请求而完全崩溃,消息队列能够使关键
组件顶住突发的访问压力; - 异步通信:消息队列允许用户把消息放入队列但不立即处理它;
- 发布/订阅模式:
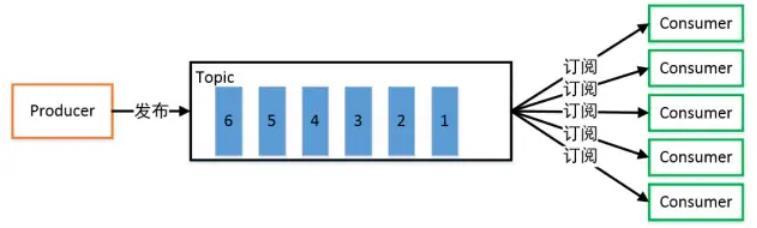
一对多,生产者将消息发布到 Topic 中,有多个消费者订阅该主题,发布到 Topic 的消息会被所有订阅者消费,被消费的数据不会立即从 Topic 清除。
Kafka 框架架构图如下所示: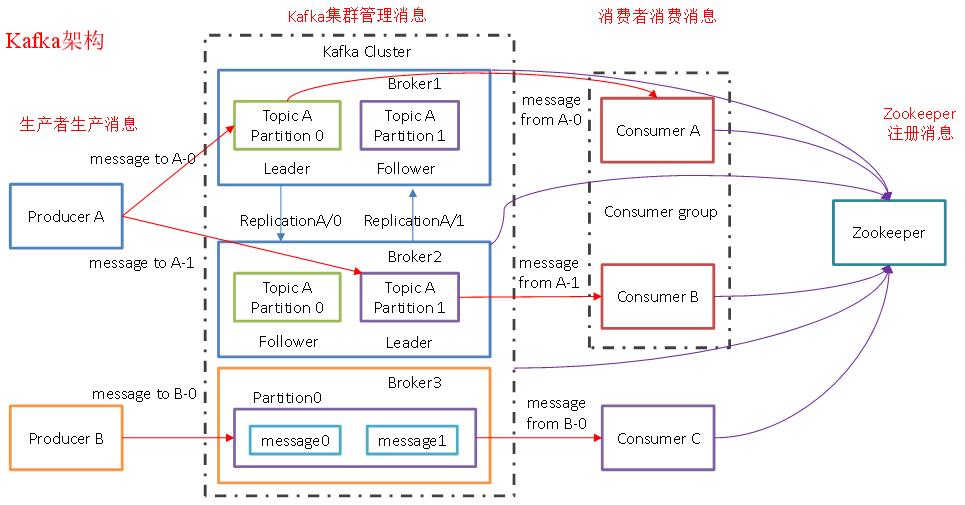
Kafka 存储的消息来自任意多被称为 Producer 生产者的进程,数据从而可以被发布到不同的Topic 主题下的不同 Partition 分区。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为 Consumer 消费者的进程可以从分区订阅消息。Kafka 运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。Kafka 一些重要概念: - 1)、Producer: 消息生产者,向 Kafka Broker 发消息的客户端;
- 2)、Consumer:消息消费者,从 Kafka Broker 取消息的客户端;
- 3)、Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,
提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者; - 4)、Broker:一台 Kafka 机器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker可以容纳多个 Topic;
- 5)、Topic:可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic;
- 6)、Partition:为了实现扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker(即服务器)上,一个 Topic 可以分为多个 Partition,每个 Partition 是一个 有序的队列;
- 7)、Replica:副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower;
- 8)、Leader:每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader;
- 9)、Follower:每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader;
- 10)、Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费;
- 11)、Zookeeper:Kafka 集群能够正常工作,需要依赖于 Zookeeper,Zookeeper 帮助 Kafka存储和管理集群信息;
1.2 集成方式
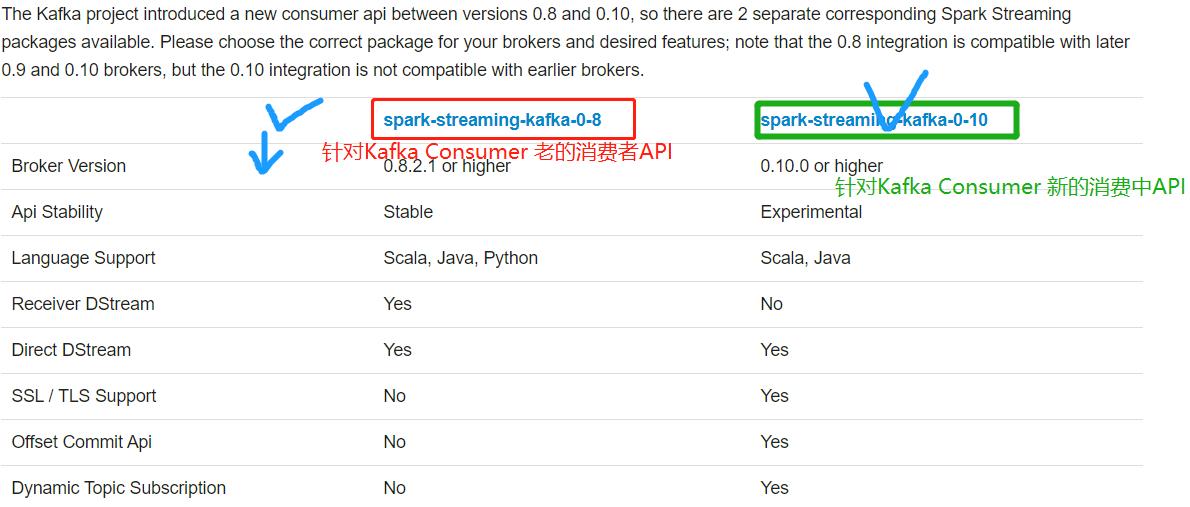
Spark Streaming与Kafka集成,有两套API,原因在于Kafka Consumer API有两套,文档:
http://spark.apache.org/docs/2.4.5/streaming-kafka-integration.html。
- 方式一:Kafka 0.8.x版本
- 老的Old Kafka Consumer API
- 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-8-integration.html
- 老的Old消费者API,有两种方式:
- 第一种:高级消费API(Consumer High Level API),Receiver接收器接收数据
- 第二种:简单消费者API(Consumer Simple Level API) ,Direct 直接拉取数据
- 方式二:Kafka 0.10.x版本
- 新的 New Kafka Consumer API
- 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html
- 核心API:KafkaConsumer、ConsumerRecorder
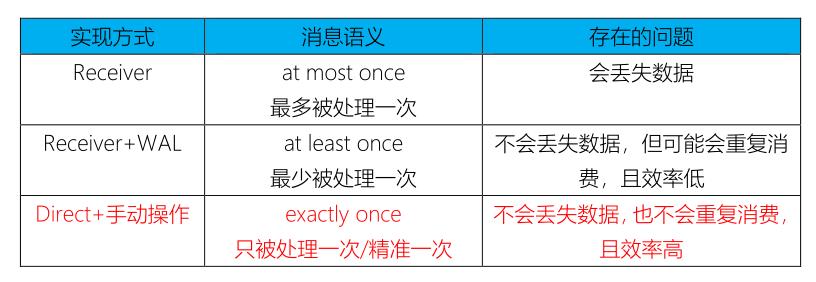
1.3 两种方式区别
使用Kafka Old Consumer API集成两种方式,虽然实际生产环境使用Direct方式获取数据,但
是在面试的时候常常问到两者区别。
文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-8-integration.html
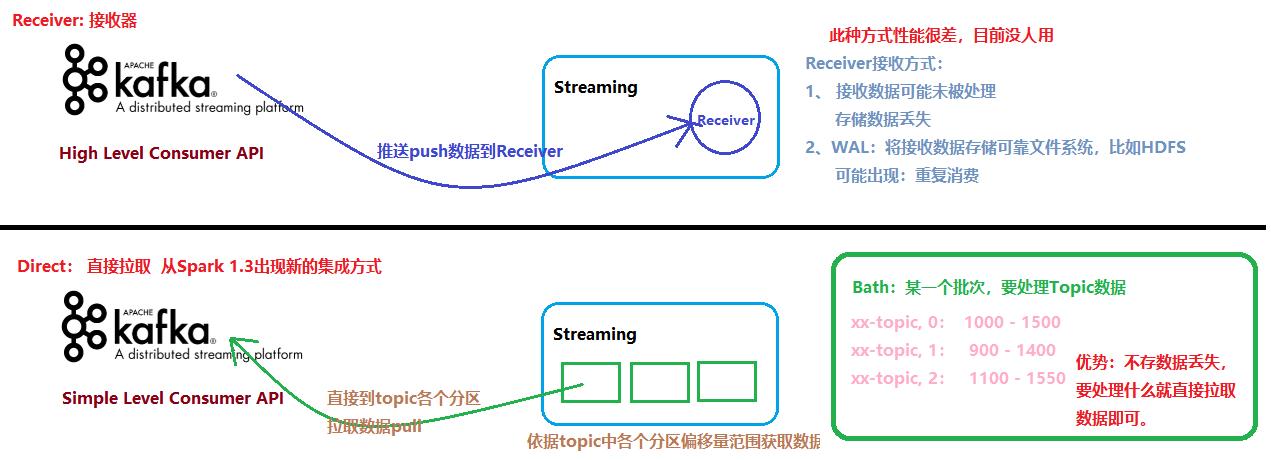
- Receiver-based Approach:
- 基于接收器方式,消费Kafka Topic数据,但是企业中基本上不再使用;
- Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启
多个,再手动合并数据(union),再进行处理,很麻烦;Receiver那台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低; - Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在
zookeeper,由Receiver维护; - Spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据
不一致;
- Direct Approach (No Receivers):
- 直接方式,Streaming中每批次的每个job直接调用Simple Consumer API获取对应Topic数据,此种方式使用最多,面试时被问的最多;
- Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高并行能力
- Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况;
- 当然也可以自己手动维护,把offset存在MySQL、Redis和Zookeeper中;
上述两种方式区别,如下图所示:
2 Direct 方式集成
使用Kafka Old Consumer API方式集成Streaming,采用Direct方式,调用Old Simple
Consumer API,文档:
http://spark.apache.org/docs/2.2.0/streaming-kafka-0-8-integration.html#approach-2-direct-approach-no-receivers
2.1 编码实现
Direct方式会定期地从Kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范
围,在每个batch里面处理数据,Spark通过调用kafka简单的消费者API读取一定范围的数据。
Direct方式没有receiver层,其会周期性的获取Kafka中每个topic的每个partition中的最新
offsets,再根据设定的maxRatePerPartition来处理每个batch。较于Receiver方式的优势:
- 其一、简化的并行:Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据;
- 其二、高效:no need for Write Ahead Logs;
- 其三、精确一次:直接使用simple Kafka API,Offsets则利用Spark Streaming的checkpoints进
行记录。
添加相关MAVEN依赖:
<!-- Spark Streaming 集成Kafka 0.8.2.1 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.4.5</version>
</dependency>
提供工具类KafkaUtils专门从Kafka消费数据,其中函数【createDirectStream】消费数据:

创建Topic及Console控制台发送数据,命令如下:
# 1. 启动Zookeeper 服务
zookeeper-daemon.sh start
# 2. 启动Kafka 服务
kafka-daemon.sh start
# 3. Create Topic
kafka-topics.sh --create --topic wc-topic \\
--partitions 3 --replication-factor 1 --zookeeper node1.itcast.cn:2181/kafka200
# List Topics
kafka-topics.sh --list --zookeeper node1.itcast.cn:2181/kafka200
# Producer
kafka-console-producer.sh --topic wc-topic --broker-list node1.itcast.cn:9092
# Consumer
kafka-console-consumer.sh --topic wc-topic \\
--bootstrap-server node1.itcast.cn:9092 --from-beginning
具体演示代码如下:
import java.util.Date
import kafka.serializer.StringDecoder
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 集成Kafka,采用Direct式读取数据,对每批次(时间为1秒)数据进行词频统计,将统计结果输出到控制台。
*/
object StreamingKafkaDirect {
def main(args: Array[String]): Unit = {
// 1、构建流式上下文实例对象StreamingContext,用于读取流式的数据和调度Batch Job执行
val ssc: StreamingContext = {
// a. 创建SparkConf实例对象,设置Application相关信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
//TODO: 设置每秒钟读取Kafka中Topic最大数据量
.set("spark.streaming.kafka.maxRatePerPartition", "10000")
// b. 创建StreamingContext实例,传递Batch Interval(时间间隔:划分流式数据)
val context: StreamingContext = new StreamingContext(sparkConf, Seconds(5))
// c. 返回上下文对象
context
}
// TODO: 2、从流式数据源读取数据
/*
def createDirectStream[
K: ClassTag, // Topic中Key数据类型
V: ClassTag,
KD <: Decoder[K]: ClassTag, // 表示Topic中Key数据解码(从文件中读取,反序列化)
VD <: Decoder[V]: ClassTag] (
ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Set[String]
): InputDStream[(K, V)]
*/
// 表示从Kafka Topic读取数据时相关参数设置
val kafkaParams: Map[String, String] = Map(
"bootstrap.servers" -> "node1.itcast.cn:9092",
// 表示从Topic的各个分区的哪个偏移量开始消费数据,设置为最大的偏移量开始消费数据
"auto.offset.reset" -> "largest"
)
// 从哪些Topic中读取数据
val topics: Set[String] = Set("wc-topic")
// 采用Direct方式从Kafka 的Topic中读取数据
val kafkaDStream: DStream[(String, String)] = KafkaUtils
.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, //
kafkaParams, //
topics
)
// 3、对接收每批次流式数据,进行词频统计WordCount
val resultDStream: DStream[(String, Int)] = kafkaDStream.transform(rdd => {
rdd
// 获取从Kafka读取数据的Message
.map(tuple => tuple._2)
// 过滤“脏数据”
.filter(line => null != line && line.trim.length > 0)
// 分割为单词
.flatMap(line => line.trim.split("\\\\s+"))
// 转换为二元组
.mapPartitions{iter => iter.map(word => (word, 1))}
// 聚合统计
.reduceByKey((a, b) => a + b)
})
// 4、将分析每批次结果数据输出,此处答应控制台
resultDStream.foreachRDD{ (rdd, time) =>
// 使用lang3包下FastDateFormat日期格式类,属于线程安全的
val batchTime = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO: 先判断RDD是否有数据,有数据在输出哦
if(!rdd.isEmpty()){
rdd
// 对于结果RDD输出,需要考虑降低分区数目
.coalesce(1)
// 对分区数据操作
.foreachPartition{iter =>iter.foreach(item => println(item))}
}
}
// 5、对于流式应用来说,需要启动应用,正常情况下启动以后一直运行,直到程序异常终止或者人为干涉
ssc.start() // 启动接收器Receivers,作为Long Running Task(线程) 运行在Executor
ssc.awaitTermination()
// 结束Streaming应用执行
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
从WEB UI监控页面可以看出如下信息:
2.2 底层原理
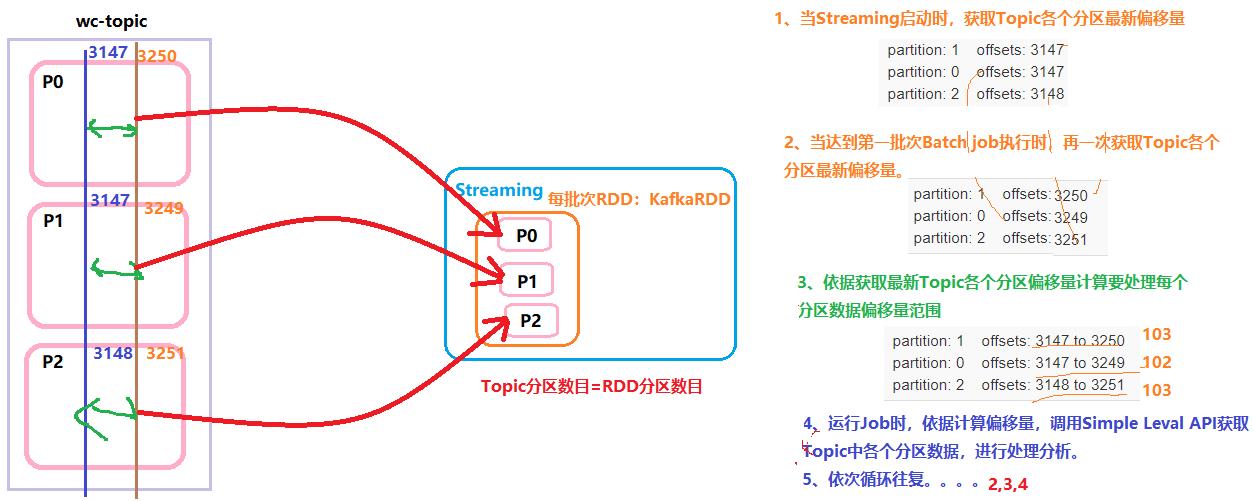
SparkStreaming集成Kafka采用Direct方式消费数据,如下三个方面优势:
- 第一、简单的并行度(Simplified Parallelism)
- 读取topics的总的分区数目 = 每批次RDD中分区数目;
- topic中每个分区数据 被读取到 RDD中每个分区进行处理

- 第二、高效(Efficiency)
- 处理数据比使用Receiver接收数据高效很多
- 使用Receiver接收数据的时候,要将数据存储到Executor、为了可靠性还需要将数据存储文件系统中WAL
- 第三、Exactly-once semantics
- 能保证一次性语义,从Kafka消费数据仅仅被消费一次,不会重复消费或者不消费
- 在Streaming数据处理分析中,需要考虑数据是否被处理及被处理次数,称为消费语义
- At most once:最多一次,比如从Kafka Topic读取数据最多消费一次,可能出现不消费,此时数据丢失;
- At least once:至少一次,比如从Kafka Topic读取数据至少消费一次,可能出现多次消费数据;
- Exactly once:精确一次,比如从Kafka topic读取数据当且仅当消费一次,不多不少,最好的状态
深入剖析SparkStreaming采用Direct方式消费Kafka数据,底层原理:
官方:this approach periodically queries Kafka for the latest offsets in each topic+partition, and accordingly
defines the offset ranges to process in each batch. When the jobs to process the data are launched, Kafka’s
simple consumer API is used to read the defined ranges of offsets from Kafka (similar to read files from
a file system).
采用Direct方式消费数据时,需要设置每批次处理数据的最大量,防止【波峰】时数据太多,
导致批次数据处理有性能问题:
- 参数:spark.streaming.kafka.maxRatePerPartition
- 含义:Topic中每个分区每秒中消费数据的最大值
- 举例说明:
- BatchInterval:5s、Topic-Partition:3、maxRatePerPartition: 10000
- 最大消费数据量:10000 * 3 * 5 = 150000 条
3 集成Kafka 0.10.x
使用Kafka 0.10.+提供新版本Consumer API集成Streaming,实时消费Topic数据,进行处理。
http://spark.apache.org/docs/2.2.0/streaming-kafka-0-10-integration.html
添加相关Maven依赖:
<!-- Spark Streaming 与Kafka 0.10.0 集成依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
目前企业中基本都使用New Consumer API集成,优势如下:
- 第一、类似 Old Consumer API中Direct方式
- 直接到Kafka Topic中依据偏移量范围获取数据,进行处理分析;
- The Spark Streaming integration for Kafka 0.10 is similar in design to the 0.8 Direct
Stream approach;
- 第二、简单并行度1:1
- 每批次中RDD的分区与Topic分区一对一关系;
- It provides simple parallelism, 1:1 correspondence between Kafka partitions and Spark
partitions, and access to offsets and metadata; - 获取Topic中数据的同时,还可以获取偏移量和元数据信息;
工具类KafkaUtils中createDirectStream函数API使用说明(函数声明):

具体演示案例代码如下:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Streaming通过Kafka New Consumer消费者API获取数据
*/
object StreamingSourceKafka {
def main(args: Array[String]): Unit = {
// 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// TODO: 2. 读取Kafka Topic中数据
/*
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]]
*/
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
/*
def Subscribe[K, V](
topics: ju.Collection[jl.String],
kafkaParams: ju.Map[String, Object]
): ConsumerStrategy[K, V]
*/
// ii.读取哪些Topic数据
val topics = Array("wc-topic")
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group_id_streaming_0001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v.采用新消费者API获取数据,类似于Direct方式
val kafkaDStream: DStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = kafkaDStream.transform(kafkaRDD => {
val resultRDD: RDD[(String, Int)] = kafkaRDD
.map(record => record.value()) // 获取Message数据
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD
})
// 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.foreachRDD{ (rdd, time) =>
val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO: 先判断RDD是否有数据,有数据在输出哦
if(!rdd.isEmpty()){
rdd
// 对于结果RDD输出,需要考虑降低分区数目
.coalesce(1)
// 对分区数据操作
.foreachPartition{iter =>iter.foreach(item => println(item))}
}
}
// 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
4 获取偏移量
当SparkStreaming集成Kafka时,无论是Old Consumer API中Direct方式还是New
Consumer API方式获取的数据,每批次的数据封装在KafkaRDD中,其中包含每条数据的
元数据信息。

文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html#obtaining-offsets
具体说明如下:
获取偏移量信息代码如下:
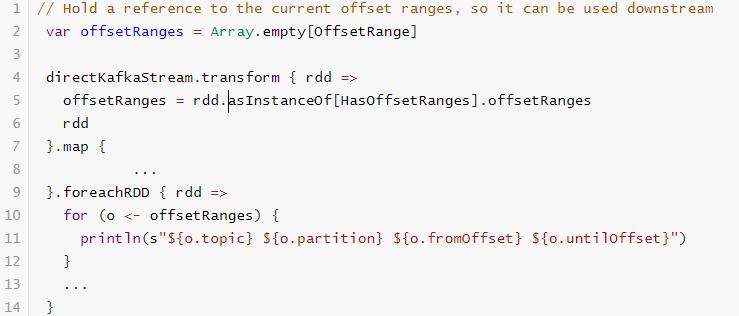
代码演示获取每批次RDD中对应Kafka分区中数据偏移量信息:
具体演示代码如下:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
/**
* 集成Kafka,实时消费Topic中数据,获取每批次数据对应Topic各个分区数据偏移量
*/
object StreamingKafkaOffset {
def main(args: Array[String]): Unit = {
// TODO: 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// 2. 读取Kafka Topic中数据
/*
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]]
*/
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
/*
def Subscribe[K, V](
topics: ju.Collection[jl.String],
kafkaParams: ju.Map[String, Object]
): ConsumerStrategy[K, V]
*/
// ii.读取哪些Topic数据
val topics = Array("wc-topic")
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group_id_streaming_0001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v.采用新消费者API获取数据,类似于Direct方式
val kafkaDStream: DStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// TODO:其一、定义数组存储每批次数据对应RDD中各个分区的Topic Partition中偏移量信息
var offsetRanges: Array[OffsetRange] = Array.empty
// 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = kafkaDStream.transform(kafkaRDD => {
// TODO:其二、直接从Kafka获取的每批次KafkaRDD中获取偏移量信息
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
val resultRDD: RDD[(String, Int)] = kafkaRDD
.map(record => record.value()) // 获取Message数据
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD
})
// 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.foreachRDD{ (rdd, time) =>
val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"Time: $batchTime以上是关于大数据Spark集成Kafka的主要内容,如果未能解决你的问题,请参考以下文章