聊一聊对外API接口的存活检查可以怎么做
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊一聊对外API接口的存活检查可以怎么做相关的知识,希望对你有一定的参考价值。
背景
公司内部的API接口一般会分为两大类,一类是直接暴露在公网可以访问的,一类是只能在局域网内访问的。
暴露在公网的一般就是业务网关以及一些和第三方公司有着某些合作,从而进行数据交互的接口。
检查API接口是否存活,第一反应应该就是健康检查了。
在局域网环境内搭配 nginx 或注册中心之类的健康检查机制,一定程度的保证了只有健康的实例才会进行服务。
把这一块放到公网环境,判断一个API接口是否存活,情况就复杂很多了。
域名解析
SSL证书
响应情况
...
举个老黄待过的两个公司的实际例子,这两个公司遇到的都是SSL证书过期,没有及时更换的问题,直接就是最高级故障。
在这种情况下,其实接口在局域网内是能正常访问,可以理解成它是存活的,但是放到公网环境,用户就是不能访问到,这个时候对用户来说就是故障的。
所以涉及到对外服务API存活的检查,光一个简单的健康检查还是不够的,还需要站在用户的层面去考虑。
或许大家会说,这种事情不是运维负责的吗?怎么还要我们开发去操心?
这个很大程度是看团队的,有的团队都不一定有运维这个角色,都是开发搞定的。
另外,多丰富一点自己的技术栈和技术广度并不是什么坏事哈。
下面就简单介绍一下老黄的处理方案吧。
处理方案
老黄这边选择的处理方案是 【Prometheus + Blackbox + Grafana + Alertmanager + PrometheusAlert】
Prometheus,Grafana 和 Alertmanager 这三个就不过多的介绍了。
下面主要介绍一下 Blackbox 和 PrometheusAlert:
Blackbox 是 Prometheus 官方提供的一种黑盒监测方案,也是本文一个最关键的点。
下面是一些常见的应用场景
HTTP 测试,定义 Request Header 信息,判断 Http status / Http Respones Header / Http Body 内容
TCP 测试, 业务组件端口状态监听,应用层协议定义与监听
ICMP 测试,主机探活机制
POST 测试,接口联通性
SSL 证书过期时间
PrometheusAlert 是开源的运维告警中心消息转发系统,支持主流的监控系统Prometheus、Zabbix,日志系统Graylog2,Graylog3、数据可视化系统Grafana、SonarQube等支持WebHook接口的系统发出的预警消息,支持将收到的这些消息发送到钉钉,微信,飞书,腾讯短信,腾讯电话,阿里云短信,阿里云电话,华为短信,容联云电话等。
换句话就是说,把告警消息通过 PrometheusAlert 发送个体企业微信机器人或钉钉机器人。
整个链路大概是这样的:
BlackBox 负责探测
Prometheus 主动 pull 探测的结果并进行存储
Prometheus 根据告警规则进行评估,将告警扔到 AlertManager
AlertManager 收到 Prometheus 的消息后,通知给 PrometheusAlert
PrometheusAlert 收到 AlertManager 的消息后,通知到对应的端
实战
下面先用 docker 启动一个 blackbox-exporter 实例
docker run -d \\
-p 13002:9115 \\
--name=blackbox \\
--restart=always \\
prom/blackbox-exporter:v0.19.0
运行后看到的大概就是这个样子。
这一块的配置基本不用变更,用默认的即可,主要的配置还是在 Prometheus 那边。
可以点击上图的 Configuration 去看默认的配置。

下面就去调整 Prometheus 的配置。
这里只以 http 检测为例来说明。
global:
scrape_interval: 30s
evaluation_interval: 30s
alerting:
alertmanagers:
- static_configs:
- targets:
- xxx.xxx.xxx.xxx:13005
rule_files:
- "/prometheus/blackbox_rules/*.yml"
scrape_configs:
- job_name: 'outer'
metrics_path: "/probe"
params:
module: [http_2xx] # 模块对应 blackbox.yml
file_sd_configs:
- files: ['/prometheus/blackbox_configs/outer/*.yml']
refresh_interval: 10s
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: xxx.xxx.xxx.xxx:13002 # blackbox安装在哪台机器
其中 scrape_configs 里面是最为重要的,一个是 params ,一个是 relabel_configs, 一个是 file_sd_configs。
剩下的就是一些常规配置了。
然后是 file_sd_configs 里面一堆可以变化的 yml 文件,也就是那些对外的域名要进行 http 检测的。
- targets: [ 'https://xxx.xxxxx.com' ]
labels:
domain: xxxxxxxx
env: xx云-公网
service: 网关
ip: xxxxxxxx
配置里面的 labels 是一些辅助信息,可以按需添加,可以在 grafana 里面进行展示的。
到这里,关于 blackbox 的配置基本就差不多了。
接下来是在 grafana 里面展示,看一下结果。
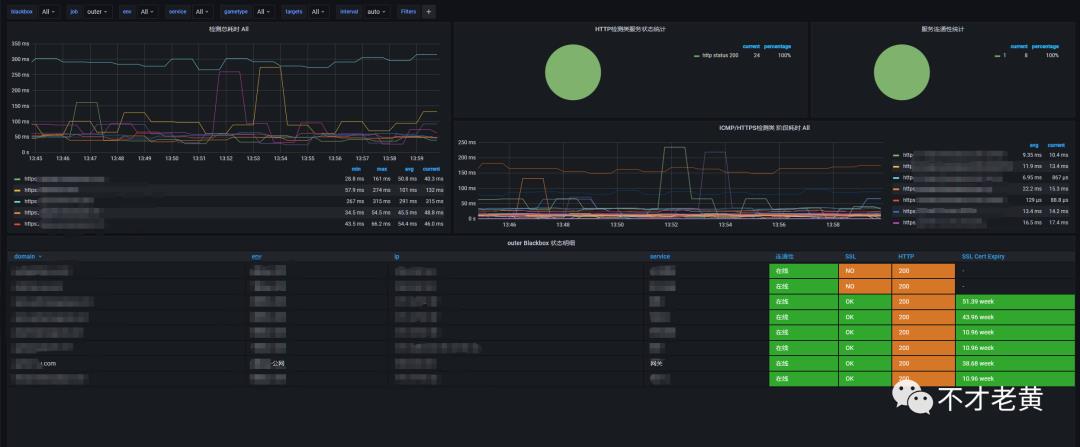
PS: 这里用的是 【9965】 这个模板。
面板虽然好看,但是我们不能每时每刻都在盯着这个面板的,所以还是离不开告警这一监控领域的大头。
下面是告警规则的配置
groups:
- name: 服务探测
rules:
- alert: BlackboxProbeFailed
expr: probe_success == 0
for: 0m
labels:
severity: critical
team: node
annotations:
summary: Blackbox probe failed (instance {{ $labels.instance }})
description: "服务在线检查失败\\n当前值= {{ $value }}\\nIp = {{ $labels.ip }}\\nDomain= {{ $labels.domain }}\\nEnv= {{ $labels.env }}\\n服务名= {{ $labels.service }}"
- alert: BlackboxProbeHttpFailure
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 0m
labels:
severity: critical
team: node
annotations:
summary: Blackbox probe HTTP failure (instance {{ $labels.instance }})
description: "HTTP状态码不在200-399\\n当前值= {{ $value }}\\nIp = {{ $labels.ip }}\\nDomain= {{ $labels.domain }}\\nEnv= {{ $labels.env }}\\n服务名= {{ $labels.service }}"
- alert: BlackboxSslCertificateWillExpireSoon
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 0m
labels:
severity: warning
annotations:
summary: Blackbox SSL certificate will expire soon (instance {{ $labels.instance }})
description: "SSL certificate expires in 30 days\\n VALUE = {{ $value }}\\n LABELS = {{ $labels }}"
上面这个主要是3个告警规则,看描述就知道它的作用的,也不用过多的说明了,这些告警表达式是参考 Awesome Prometheus alerts 调整的。
再下一步就到告警消息的配置了。
先用 docker 启动一个 prometheus-alert 的实例
docker run -d -p 13006:8080 \\
-v /data/prom-alert/conf:/app/conf \\
-v /data/prom-alert/db:/app/db \\
-v /data/prom-alert/logs:/app/logs \\
--name prom-alert \\
-e TZ=Asia/Shanghai \\
--restart=always \\
feiyu563/prometheus-alert:v-4.4.3
这里默认带了很多模板
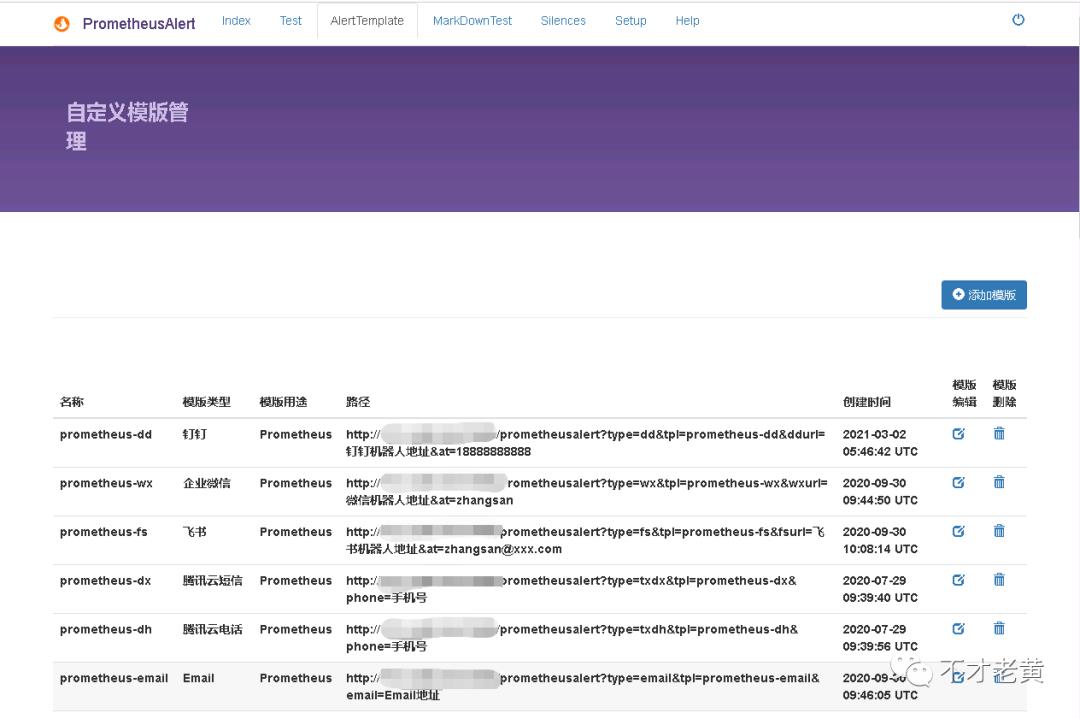
这里选择自己定义一个告警模板
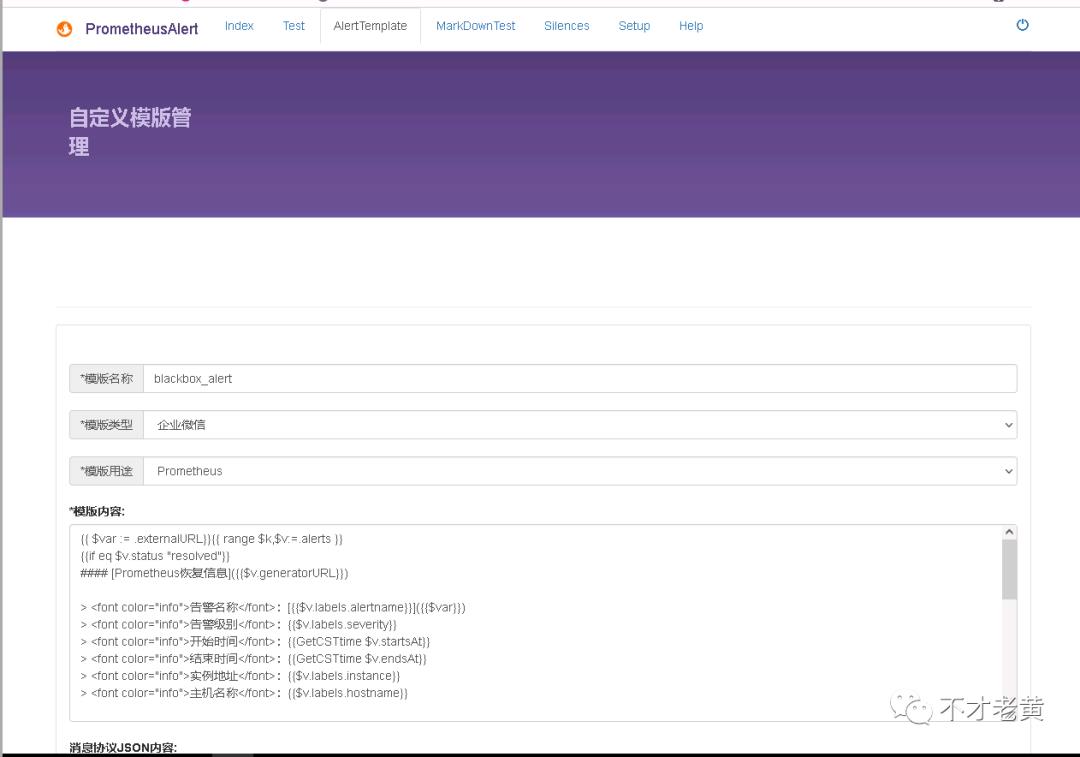
{{ $var := .externalURL}}{{ range $k,$v:=.alerts }}
{{if eq $v.status "resolved"}}
#### [Prometheus恢复信息]({{$v.generatorURL}})
> <font color="info">告警名称</font>:[{{$v.labels.alertname}}]({{$var}})
> <font color="info">告警级别</font>:{{$v.labels.severity}}
> <font color="info">开始时间</font>:{{GetCSTtime $v.startsAt}}
> <font color="info">结束时间</font>:{{GetCSTtime $v.endsAt}}
> <font color="info">实例地址</font>:{{$v.labels.instance}}
> <font color="info">主机名称</font>:{{$v.labels.hostname}}
**{{$v.annotations.description}}**
{{else}}
#### [Prometheus告警信息]({{$v.generatorURL}})
> <font color="#FF0000">告警名称</font>:[{{$v.labels.alertname}}]({{$var}})
> <font color="#FF0000">告警级别</font>:{{$v.labels.severity}}
> <font color="#FF0000">开始时间</font>:{{GetCSTtime $v.startsAt}}
> <font color="#FF0000">结束时间</font>:{{GetCSTtime $v.endsAt}}
> <font color="#FF0000">实例地址</font>:{{$v.labels.instance}}
> <font color="#FF0000">主机名称</font>:{{$v.labels.hostname}}
**{{$v.annotations.description}}**
{{end}}
{{ end }}
这里的模板是做了一个颜色的区分,告警的用红色,恢复的用绿色,由于 Prometheus 和 AlertManager 用的都是 UTC 时间,所以这里用 GetCSTtime 转化成北京时间。
最后是回到 alertmanager 里面去配置
global:
resolve_timeout: 5m
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 1m
repeat_interval: 5m
group_by: [alertname]
routes:
- receiver: 'blackbox-webhook-outer'
group_wait: 10s
continue: false
match_re:
job: outer
receivers:
- name: 'default-receiver'
webhook_configs:
- url: 'http://xxxxxx:13006/prometheusalert?type=wx&tpl=prometheus-wx&wxurl=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxx'
- name: 'blackbox-webhook-outer'
webhook_configs:
# 这里的url 是配置的 PrometheusAlert 自定义模板管理里面的路径
- url: 'http://xxxxxx:13006/prometheusalert?type=wx&tpl=blackbox_alert&wxurl=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxx'
最后来看一些实际告警和恢复的例子
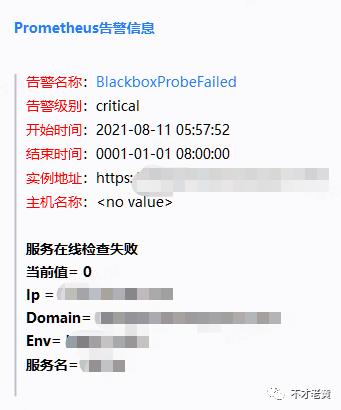
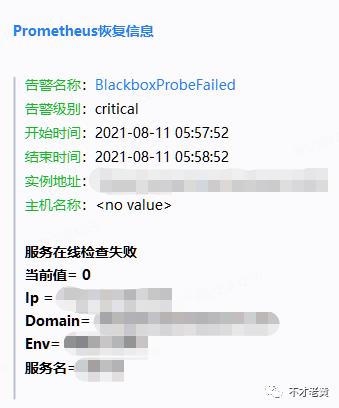

其他
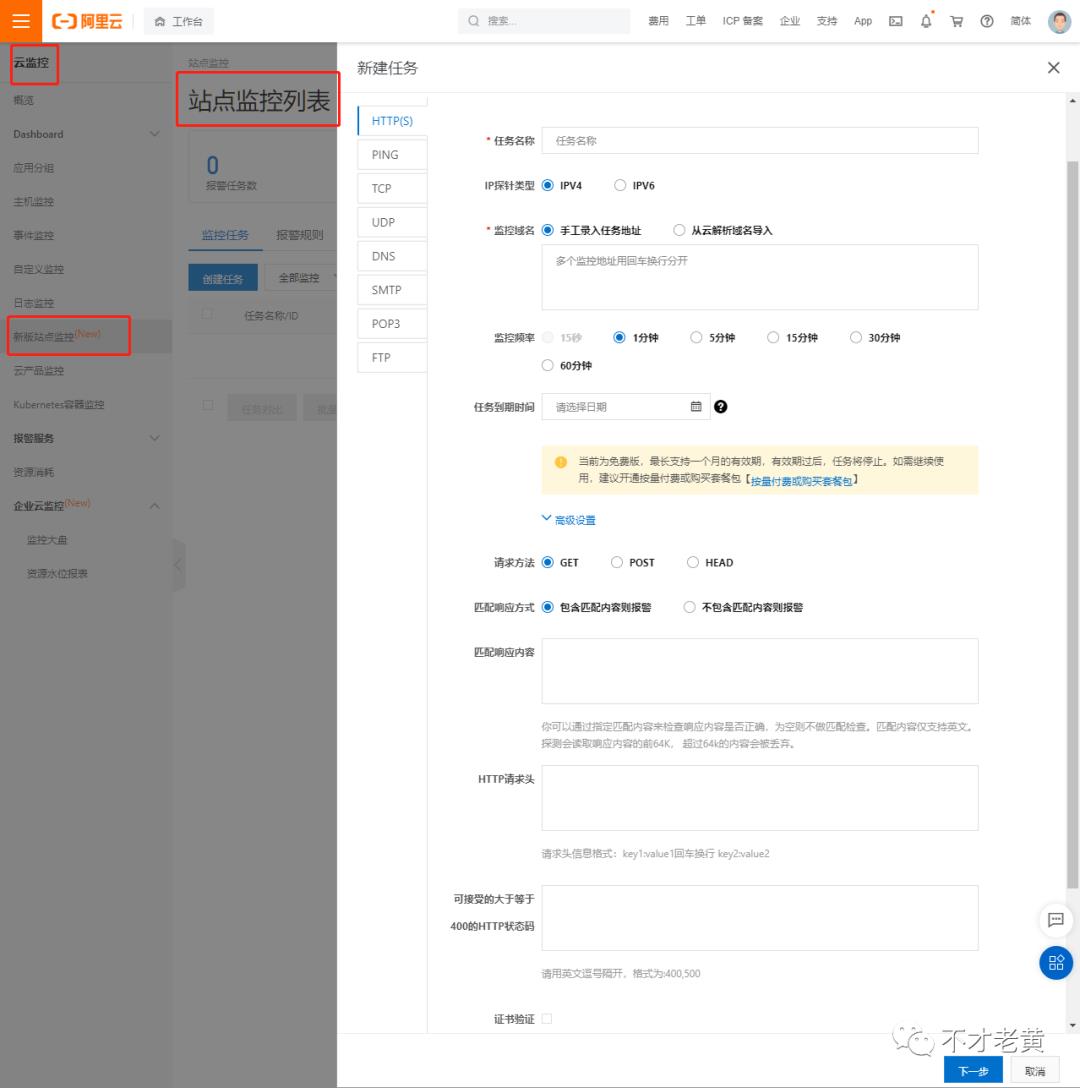
如果不想考虑自己搭建的话,不少云产商也有提供类似的功能,好比阿里云有一个叫站点监控的产品也可以帮我们搞定这个问题,不过只能免费一个月,超过还是需要购买的。
小结
API接口存活的检查其实也是一门不小的学问,考虑的内容还是不少的。经历过生产事故,所以对这一块会特别看重。
目前中小团队的监控体系应该是离不开事实标准的 Prometheus,所以在其基础上去拓展会有比较多成熟的可以借鉴的经验来落地。
相关阅读
https://github.com/prometheus/blackbox_exporter
https://grafana.com/grafana/dashboards/9965
https://awesome-prometheus-alerts.grep.to/rules
https://feiyu563.github.io
以上是关于聊一聊对外API接口的存活检查可以怎么做的主要内容,如果未能解决你的问题,请参考以下文章
# 聊一聊悟空编辑器 #Gin + Swagger快速生成API文档
聊一聊内存泄漏 ------在valgrind检查不出来时怎么办??