Python爬虫入门:HTTP协议和Chrome开发者工具的使用
Posted 编程界的小胖子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫入门:HTTP协议和Chrome开发者工具的使用相关的知识,希望对你有一定的参考价值。
我们学习知识就像盖房子一样,没有良好的地基,房子经不起风吹雨打。而如果房子的地基搭建的足够牢固,即使台风来了都是高高的耸立在那里。
我们没有上来就讲爬虫怎么用,而是讲了一些基础的内容,这些内容大家都掌握了,后面我们学习实操爬虫就会很顺利,很清晰了。
HTTP协议
提到爬虫我们不得不提起HTTP协议,那什么是HTTP协议呢?
HTTP协议(超文本传输协议HyperText Transfer Protocol),它是基于TCP协议的应用层传输协议,简单来说就是客户端和服务端进行数据传输的一种规则。
-
超文本:是指超过文本,不仅限于文本;还包括图片、音频、视频等文件
-
传输协议:是指使用共用约定的固定格式来传递转换成字符串的超文本内容
-
默认端口号:80
并且HTTP是一种无状态(stateless) 协议,HTTP协议本身不会对发送过的请求和相应的通信状态进行持久化处理。这样做的目的是为了保持HTTP协议的简单性,从而能够快速处理大量的事务,提高效率。
有时我们还会使用到https协议,其实他是HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协,默认端口号:443
-
SSL对传输的内容(超文本,也就是请求体或响应体)进行加密
请求
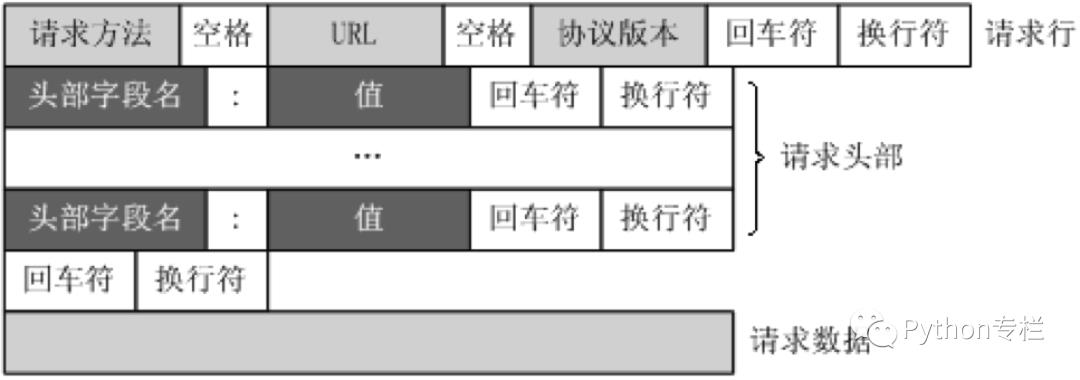
HTTP协议中每次请求都会携带下方的内容,比如有请求的方法、请求的路径、协议的版本等我们称作请求行。
还有符合字段名:值的这个方式的,我们称作请求头。
最后一部分是请求体。
大家来看一下,浏览器的开发者工具Network中的请求情况:

我们可以发现浏览器在发出请求的时候也是携带了请求行、请求头等内容。
请求行中最主要的就是url和请求方法method,有哪些请求方法呢?
HTTP协议的方法有:
GET:请求获取Request-URI所标识的资源
POST:在Request-URI所标识的资源后增加新的数据
HEAD:请求获取由Request-URI所标识的资源的响应消息报头
PUT:请求服务器存储或修改一个资源,并用Request-URI作为其标识
DELETE:请求服务器删除Request-URI所标识的资源
TRACE:请求服务器回送收到的请求信息,主要用于测试或诊断*
CONNECT:保留将来使用*
OPTIONS:请求查询服务器的性能,或者查询与资源相关的选项和需求
一般不声明默认使用的是GET请求,另外常用的是POST请求。对于上面写到的其他的请求大多数是API接口程序会涉及到的。所以大家主要记住两个就可以了:GET和POST。
爬虫中特别关注的请求头
无论是浏览器还是爬虫,在发出请求的时候要遵守HTTP协议,遵守HTTP协议就要携带请求头。
浏览器的请求头有哪些呢?同样在Network模式点击一个链接查看:

这么多请求头发出请求的时候都要加吗?不是的,因为每个网站的请求头也是不一样的,也不是统一的。所以爬虫特别关注以下几个请求头字段:
-
Host (主机和端口号)
-
Connection (链接类型)
-
Upgrade-Insecure-Requests (升级为HTTPS请求)
-
User-Agent (浏览器名称)
-
Referer (页面跳转处)
-
Cookie (Cookie)
-
Authorization(用于表示HTTP协议中需要认证资源的认证信息,如前边web课程中用于jwt认证)
加粗的请求头为常用请求头,在服务器被用来进行爬虫识别的频率最高,相较于其余的请求头更为重要,但是这里需要注意的是并不意味这其余的不重要,因为有的网站的运维或者开发人员可能剑走偏锋,会使用一些比较不常见的请求头来进行爬虫的甄别
响应
有请求再加上响应才是一个完整的 HTTP 协议过程。那返回的响应内容格式又是什么呢?

所以每一次响应都会包含上图中的内容,状态码、协议版本、响应头、响应实体等。
同样为了我们更加直观的来看响应我们还是通过浏览器的Network来看。可以看到有状态码、远程主机IP、响应头等内容。

还有一个主要内容是没有看到的,那就是响应体,需要点击一下Response,就会发现下面发生了变化,你所看到的就是响应体的内容。

大家也要学会查看状态码,因为并不是所有请求返回的状态码都是200,还有可能是304,500,404等。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息 - 表示请求已接收,继续处理2xx:成功 - 表示请求已被成功接收、理解、接受3xx:重定向 - 要完成请求必须进行更进一步的操作4xx:客户端错误 - 请求有语法错误或请求无法实现 *5xx:服务器端错误 - 服务器未能实现合法的请求。常见状态代码:
200: OK - 客户端请求成功*
400: Bad Request - 客户端请求有语法错误,不能被服务器所理解
401: Unauthorized - 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用*
403: Forbidden - 服务器收到请求,但是拒绝提供服务
404: Not Found - 请求资源不存在,eg:输入了错误的URL*
500: Internal Server Error - 服务器发生不可预期的错误 *
503: Server Unavailable - 服务器当前不能处理客户端的请求,一段时间后,可能恢复正常
所以浏览器在发出请求的时候,运行过程是:
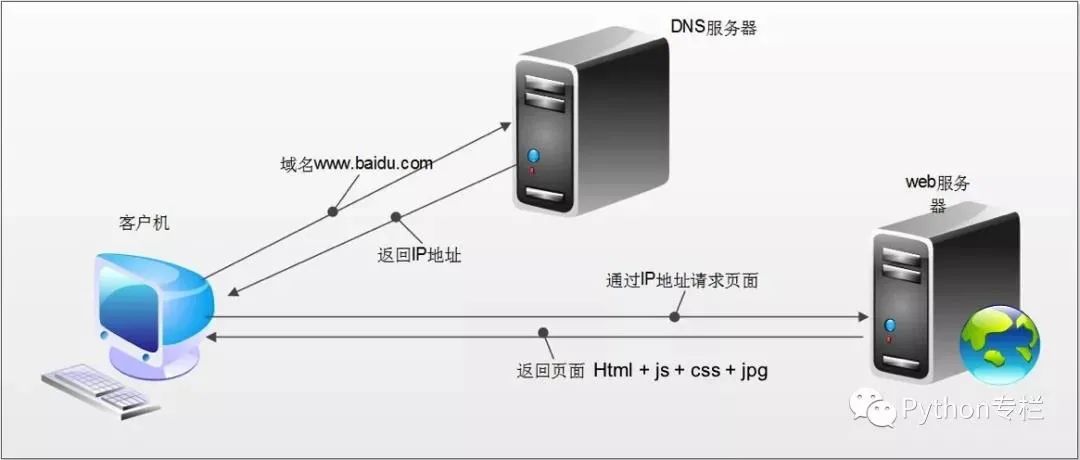
HTTP请求的过程:
1、我们无论访问任何网站都是在浏览器的地址栏上输入域名的,比如:http://www.baidu.com. 因为域名好记啊!我们从来不会记得百度的IP地址。但是识别的过程有DNS域名解析服务器完成了,它能够根据你输入的域名找到匹配的IP地址,然后将IP地址告诉你。
2、浏览器在拿到域名对应的ip后,开始发起请求,并获取响应。
3、在返回的响应内容(html)中,会带有css、js、图片等url地址,以及ajax代码,浏览器按照响应内容中的顺序依次发送其他的请求,并获取相应的响应。
4、浏览器每获取一个响应就对展示出的结果进行添加(加载),js,css等内容会修改页面的内容,js也可以重新发送请求,获取响应。
5、从获取第一个响应并在浏览器中展示,直到最终获取全部响应,——这个过程叫做浏览器的渲染。
那讲了这么多,到底HTTP跟我们即将要讲的爬虫有什么关系呢?请看下图:

这个是爬虫的步骤,而HTTP协议则是这个步骤中的一部分而且是最重要的一部分,即发送请求获取响应的那部分。
【说的明白些,就是【请求和响应】这段其实就是浏览器要干的活,我们通过写程序假装是浏览器在访问。】
!!!上图红色框起来的那部分就是假装浏览器在做事情~

以上是关于Python爬虫入门:HTTP协议和Chrome开发者工具的使用的主要内容,如果未能解决你的问题,请参考以下文章